Why Limit the Residual Stream to Layers and Not Tokens? Persistent Memory for Continuous Latent Reasoning
Pith reviewed 2026-06-27 21:52 UTC · model grok-4.3
The pith
AGCLR adds a gated concept stream with persistent memory to stop fact loss across latent reasoning steps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
AGCLR augments CoCoNuT with a Gated Concept Stream consisting of a persistent residual memory controlled by three learned gates: a write gate that commits intermediate facts, a read gate that retrieves relevant prior states, and a forget gate that prunes irrelevant context, thereby preventing the loss of critical facts as reasoning depth increases.
What carries the argument
The Gated Concept Stream: a persistent residual memory updated across all reasoning passes by three learned gates that write, read, and forget facts.
If this is right
- Consistent accuracy gains appear on mathematical, multi-hop QA, and planning tasks.
- The advantage over baselines grows as curriculum depth increases.
- The mechanism directly targets overwriting of intermediate hidden states.
- Residual memory is maintained across passes rather than being reset at each layer.
Where Pith is reading between the lines
- The same persistent memory could be added to other latent-space reasoning methods that currently reset states each step.
- If the gates prove robust, they suggest treating residual streams as token-level rather than layer-limited.
- Deeper curricula become viable once fact retention is decoupled from the main hidden state.
Load-bearing premise
The measured gains on GSM8K, HotpotQA, and ProsQA are produced by the gated memory rather than by any other unreported change in training or architecture.
What would settle it
An ablation that removes or freezes the three gates and the persistent memory while keeping every other detail identical to AGCLR, then shows no improvement over vanilla CoCoNuT, would falsify the central claim.
Figures


read the original abstract
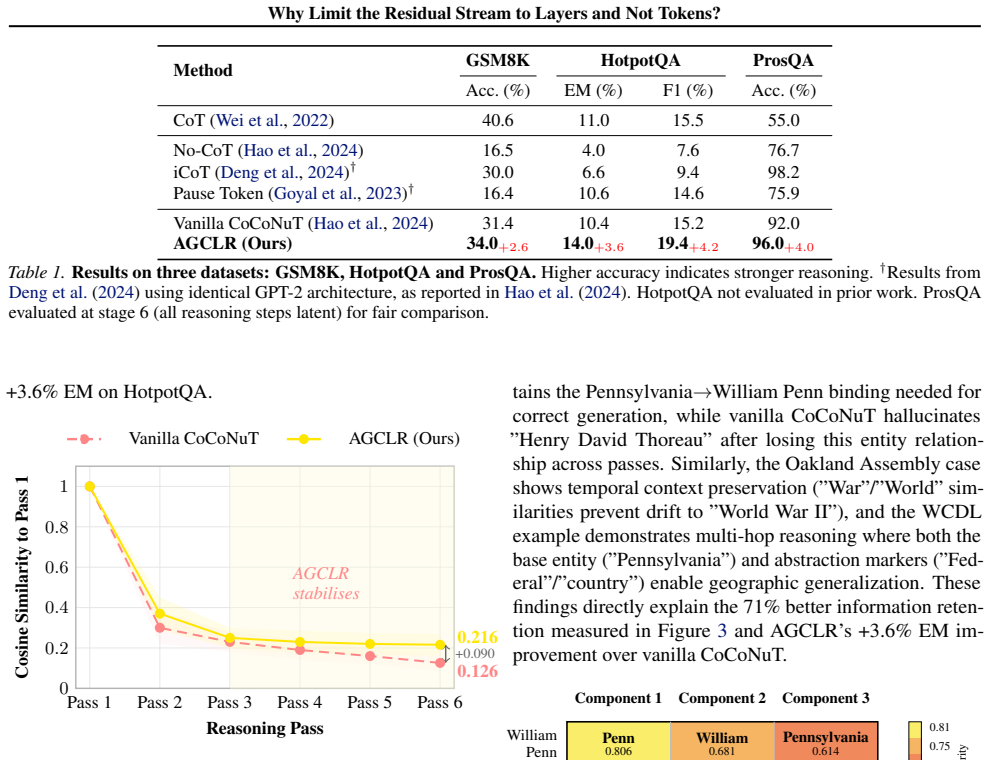
Large language models (LLMs) have demonstrated remarkable reasoning abilities on mathematical and multi-hop planning tasks. The CoCoNuT (Chain of Continuous Thought) paradigm~\cite{hao2024coconut} extends this by enabling models to reason in latent space, exploring multiple reasoning paths simultaneously rather than committing to a single chain early on. However, we identify a limitation we term the \textbf{concept bottleneck}. At each reasoning pass, intermediate hidden states are overwritten, causing the model to lose critical facts computed in earlier steps as reasoning depth increases. We observe this empirically. On HotpotQA, vanilla CoCoNuT (10.4\% EM) fails to improve over the CoT baseline (11.0\% EM), and performance degrades with curriculum depth on GSM8K. To address this, we propose \textbf{AGCLR} (Adaptive Gated Continuous Latent Reasoning), which augments CoCoNuT with a \textit{Gated Concept Stream}. A persistent residual memory maintained across all reasoning passes, controlled by three learned gates: a \textit{write} gate that commits intermediate facts to memory, a \textit{read} gate that retrieves relevant prior states, and a \textit{forget} gate that prunes irrelevant context. Evaluated on GSM8K, HotpotQA, and ProsQA using GPT-2 as our base model, AGCLR achieves consistent improvements across all types of datasets. With the performance gap compounding as curriculum depth increases, directly resolving the concept bottleneck. Code available at https://anonymous.4open.science/r/JJJJ/README.md
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper identifies a 'concept bottleneck' in CoCoNuT-style continuous latent reasoning, where intermediate hidden states are overwritten across passes, causing loss of facts as reasoning depth increases. It proposes AGCLR, which augments the architecture with a Gated Concept Stream (persistent residual memory controlled by learned write/read/forget gates) and claims this produces consistent gains over vanilla CoCoNuT and CoT baselines on GSM8K, HotpotQA, and ProsQA (e.g., HotpotQA 10.4% vs 11.0% EM), with the gap widening as curriculum depth increases; GPT-2 is the base model and code is released.
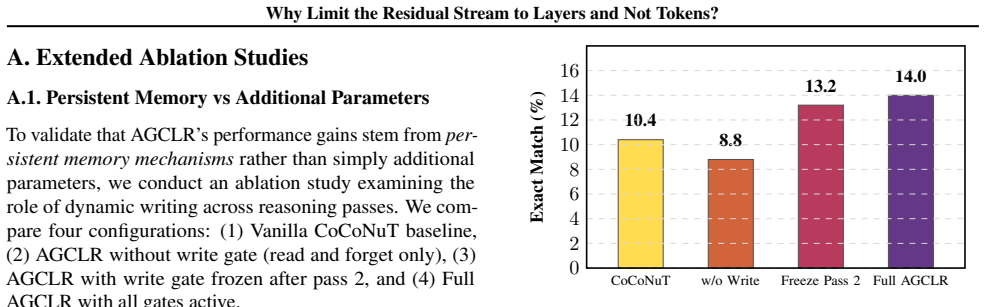
Significance. If the gains are shown to be caused by the gated memory rather than other unstated changes, the work could meaningfully extend latent-space reasoning by preserving information across passes. The release of code supports reproducibility, but the absence of any equations, ablations, or experimental details in the provided manuscript limits assessment of whether the central mechanism is load-bearing.
major comments (3)
- [Abstract] Abstract: the reported performance numbers (HotpotQA 10.4% EM for vanilla CoCoNuT vs 11.0% for baseline; compounding gains with depth on GSM8K) are presented without any methods description, ablation studies holding the base architecture fixed, error bars, or dataset statistics, so it is impossible to verify that the gated concept stream is the causal factor rather than other unmentioned modifications.
- [Abstract] No equations or formal definitions appear for the write/read/forget gates or their integration into the residual stream; without these, the claim that the Gated Concept Stream 'directly resolves the concept bottleneck' cannot be checked for correctness or distinguished from simply adding extra capacity.
- [Abstract] The central claim that 'the performance gap compounding as curriculum depth increases' directly resolves the bottleneck requires evidence (e.g., per-depth tables or gate-activation analysis) that the memory actually retains facts across steps; none is supplied, leaving the weakest assumption untested.
minor comments (1)
- [Abstract] The anonymous code link is given as a placeholder; a permanent repository should be provided for review.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We agree that the abstract as currently written is overly condensed and does not supply sufficient methodological context, formal definitions, or supporting evidence to allow verification of the central claims. We will revise the manuscript to address these points directly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the reported performance numbers (HotpotQA 10.4% EM for vanilla CoCoNuT vs 11.0% for baseline; compounding gains with depth on GSM8K) are presented without any methods description, ablation studies holding the base architecture fixed, error bars, or dataset statistics, so it is impossible to verify that the gated concept stream is the causal factor rather than other unmentioned modifications.
Authors: We agree that the abstract lacks the necessary context. The current version presents results without describing the experimental protocol, fixed-base ablations, error bars, or dataset statistics. In the revision we will expand the abstract to include a concise methods summary, explicitly state that ablations hold the base architecture fixed, and reference the presence of error bars and dataset details in the Experiments section. This will make it possible to assess whether the gated stream is the causal factor. revision: yes
-
Referee: [Abstract] No equations or formal definitions appear for the write/read/forget gates or their integration into the residual stream; without these, the claim that the Gated Concept Stream 'directly resolves the concept bottleneck' cannot be checked for correctness or distinguished from simply adding extra capacity.
Authors: This observation is correct. The abstract provides only a verbal description and contains no equations. The full manuscript defines the three gates and their residual-stream integration in Section 3; we will revise the abstract to include a compact formal statement of the gate equations (or an explicit pointer to them) so that readers can verify the mechanism and distinguish it from added capacity. revision: yes
-
Referee: [Abstract] The central claim that 'the performance gap compounding as curriculum depth increases' directly resolves the bottleneck requires evidence (e.g., per-depth tables or gate-activation analysis) that the memory actually retains facts across steps; none is supplied, leaving the weakest assumption untested.
Authors: We accept that the abstract supplies no supporting evidence for the retention claim. The manuscript reports the compounding gap but does not present per-depth tables or gate-activation analysis in the abstract itself. We will revise the abstract to reference the per-depth results and any gate-retention analysis contained in the Experiments section, and we will ensure those analyses are clearly highlighted so the retention assumption can be evaluated. revision: yes
Circularity Check
No circularity: architectural proposal without derivations
full rationale
The paper introduces AGCLR as an architectural augmentation to CoCoNuT (adding a Gated Concept Stream with write/read/forget gates) to address an empirically observed concept bottleneck. No equations, derivations, or parameter-fitting steps are present in the provided text. Performance claims rest on reported empirical results across datasets rather than any reduction of outputs to inputs by construction. The cited CoCoNuT work is external, and no self-citation chains or uniqueness theorems are invoked to force the design. This is a standard case of an honest non-finding for a purely architectural proposal.
Axiom & Free-Parameter Ledger
free parameters (1)
- write/read/forget gate parameters
invented entities (1)
-
Gated Concept Stream
no independent evidence
Reference graph
Works this paper leans on
-
[5]
Modular training of neural networks aids interpretability
Golechha, S., Chaudhary, M., Velja, J., Abate, A., and Schoots, N. Modular training of neural networks aids interpretability. arXiv e-prints, pp.\ arXiv--2502, 2025
2025
-
[8]
G., Grefenstette, E., Ramalho, T., Agapiou, J., et al
Graves, A., Wayne, G., Reynolds, M., Harley, T., Danihelka, I., Grabska-Barwinska, A., Colmenarejo, S. G., Grefenstette, E., Ramalho, T., Agapiou, J., et al. Hybrid computing using a neural network with dynamic external memory. Nature, 538 0 (7626): 0 471--476, 2016
2016
-
[10]
and Schmidhuber, J
Hochreiter, S. and Schmidhuber, J. Long short-term memory. Neural Computation, 9 0 (8): 0 1735--1780, 1997
1997
-
[13]
Efficient post-training refinement of latent reasoning in large language models
Wang, X., Wang, D., Ying, W., Bai, H., Gong, N., Dong, S., Liu, K., and Fu, Y. Efficient post-training refinement of latent reasoning in large language models. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 40, pp.\ 33692--33700, 2024
2024
-
[14]
Chain-of-thought prompting elicits reasoning in large language models
Wei, J., Wang, X., Schuurmans, D., Bosma, M., Ichter, B., Xia, F., Chi, E., Le, Q., and Zhou, D. Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems, 35, 2022
2022
-
[15]
W., Salakhutdinov, R., and Manning, C
Yang, Z., Qi, P., Zhang, S., Bengio, Y., Cohen, W. W., Salakhutdinov, R., and Manning, C. D. HotpotQA : A dataset for diverse, explainable multi-hop question answering. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, 2018
2018
-
[16]
Training Large Language Models to Reason in a Continuous Latent Space
Training Large Language Models to Reason in a Continuous Latent Space , author =. arXiv preprint arXiv:2412.06769 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Advances in Neural Information Processing Systems , volume =
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , author =. Advances in Neural Information Processing Systems , volume =
-
[18]
Implicit Chain of Thought Reasoning via Knowledge Distillation , author =. arXiv preprint arXiv:2311.01460 , year =
- [19]
-
[20]
Show Your Work: Scratchpads for Intermediate Computation with Language Models
Show Your Work: Scratchpads for Intermediate Computation with Language Models , author =. arXiv preprint arXiv:2112.00114 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Advances in Neural Information Processing Systems , volume =
Large Language Models are Zero-Shot Reasoners , author =. Advances in Neural Information Processing Systems , volume =
-
[22]
Training Verifiers to Solve Math Word Problems
Training Verifiers to Solve Math Word Problems , author =. arXiv preprint arXiv:2110.14168 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
and Salakhutdinov, Ruslan and Manning, Christopher D
Yang, Zhilin and Qi, Peng and Zhang, Saizheng and Bengio, Yoshua and Cohen, William W. and Salakhutdinov, Ruslan and Manning, Christopher D. , booktitle =
-
[24]
OpenAI Blog , volume =
Language Models are Unsupervised Multitask Learners , author =. OpenAI Blog , volume =
-
[25]
International Conference on Learning Representations , year =
Decoupled Weight Decay Regularization , author =. International Conference on Learning Representations , year =
-
[26]
Neural Turing Machines , author =. arXiv preprint arXiv:1410.5401 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Nature , volume =
Hybrid Computing using a Neural Network with Dynamic External Memory , author =. Nature , volume =
-
[28]
Transformer-
Dai, Zihang and Yang, Zhilin and Yang, Yiming and Carbonell, Jaime and Le, Quoc and Salakhutdinov, Ruslan , booktitle =. Transformer-
-
[29]
Neural Computation , volume =
Long short-term memory , author =. Neural Computation , volume =
-
[30]
Proceedings of the AAAI Conference on Artificial Intelligence , volume =
Efficient post-training refinement of latent reasoning in large language models , author =. Proceedings of the AAAI Conference on Artificial Intelligence , volume =
-
[31]
arXiv preprint arXiv:2509.18116 , year=
Amortized Latent Steering: Low-Cost Alternative to Test-Time Optimization , author=. arXiv preprint arXiv:2509.18116 , year=
-
[32]
arXiv preprint arXiv:2602.14444 , year=
Broken Chains: The Cost of Incomplete Reasoning in LLMs , author=. arXiv preprint arXiv:2602.14444 , year=
-
[33]
Frit: Using causal importance to improve chain-of-thought faithfulness , author=. arXiv preprint arXiv:2509.13334 , year=
-
[34]
arXiv e-prints , pages=
Modular Training of Neural Networks aids Interpretability , author=. arXiv e-prints , pages=
-
[35]
arXiv preprint arXiv:2409.04478 , year=
Evaluating open-source sparse autoencoders on disentangling factual knowledge in gpt-2 small , author=. arXiv preprint arXiv:2409.04478 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.