MilliVid: Hierarchical Latents for Long-Range Consistency in Video Generation
Pith reviewed 2026-06-27 17:00 UTC · model grok-4.3
The pith
A multi-scale token hierarchy with coarse-to-fine rollout preserves long-range consistency in generated videos.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
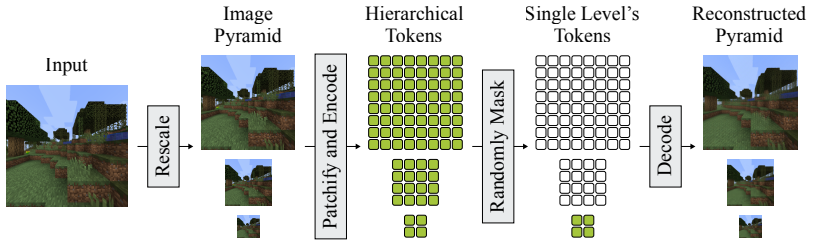
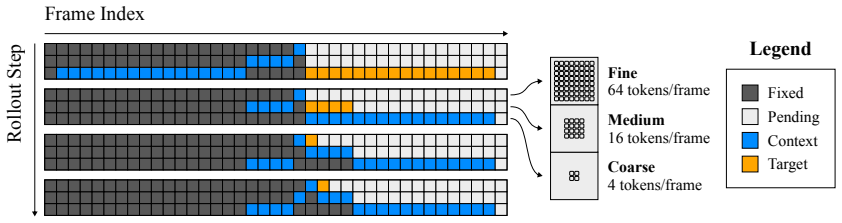
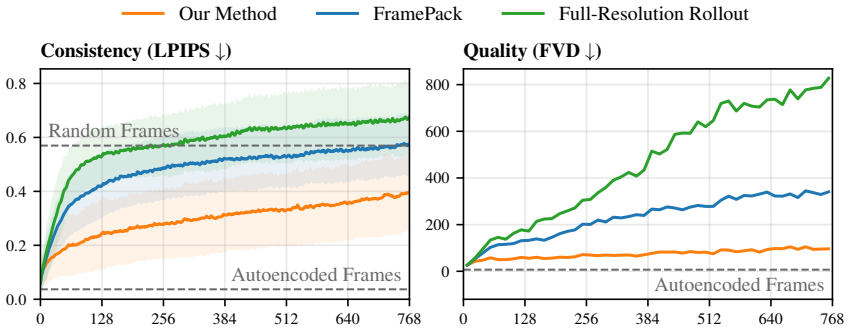
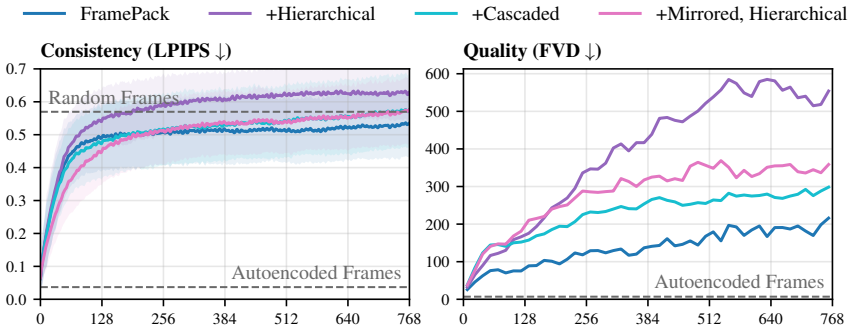
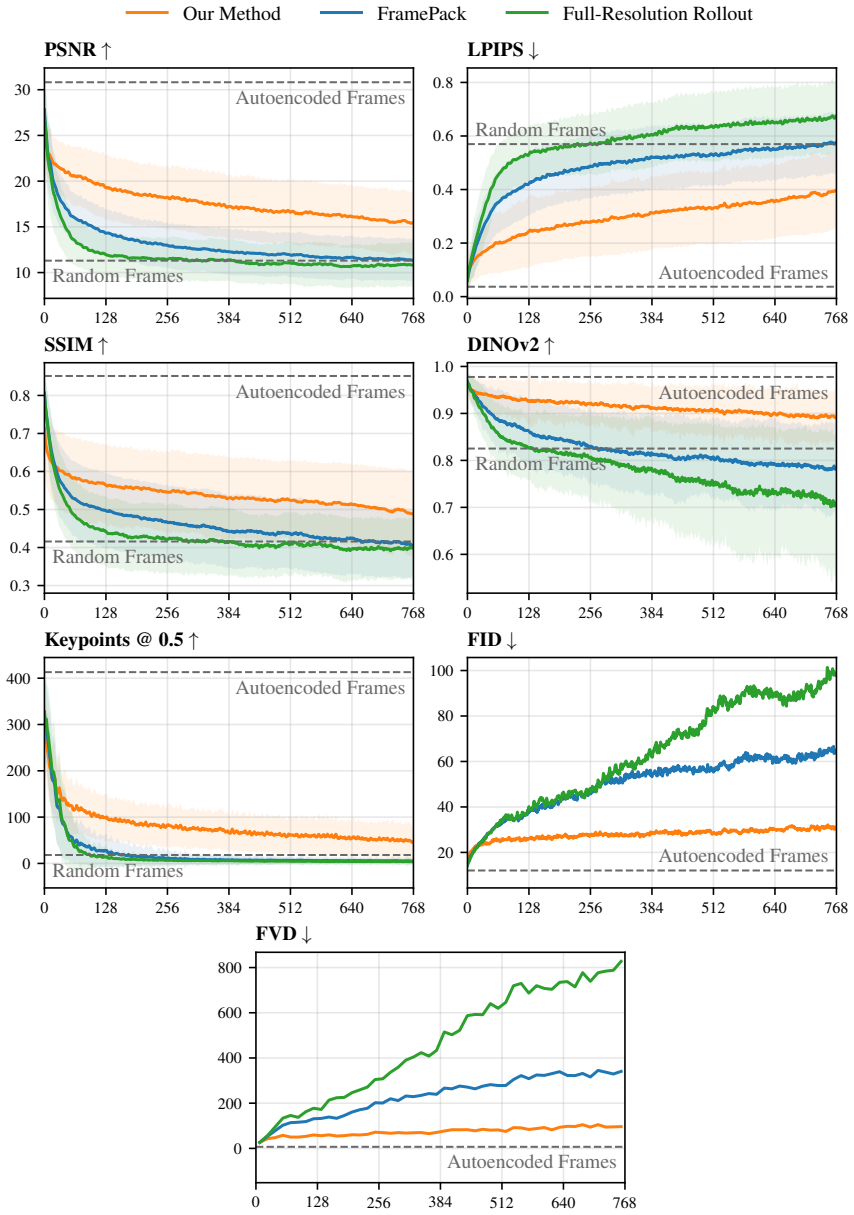
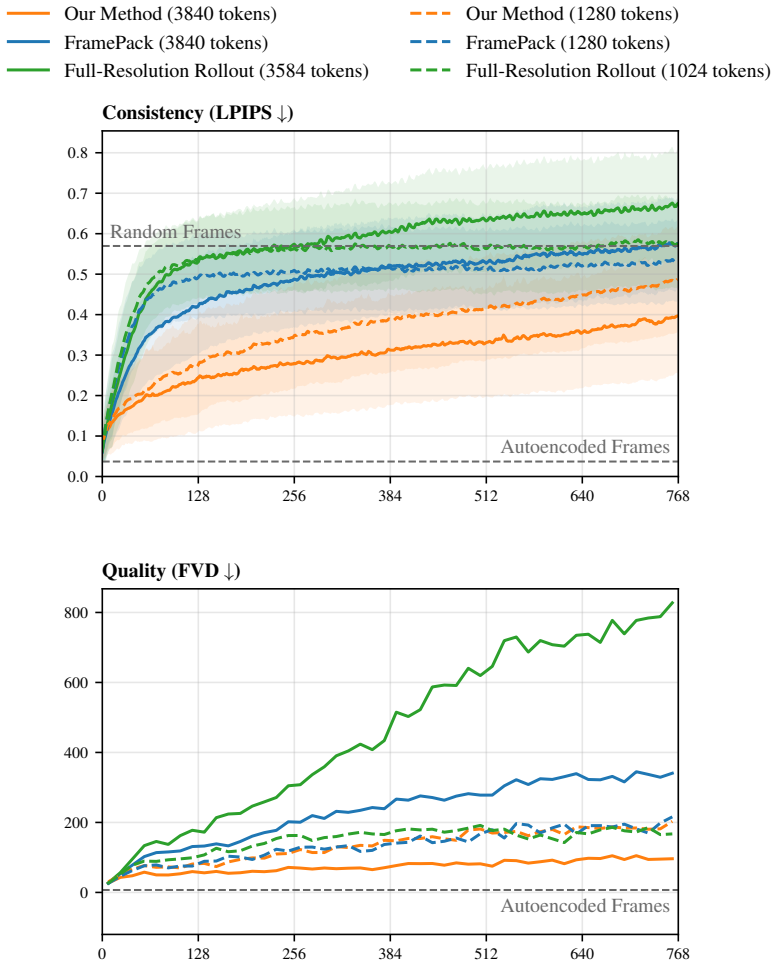
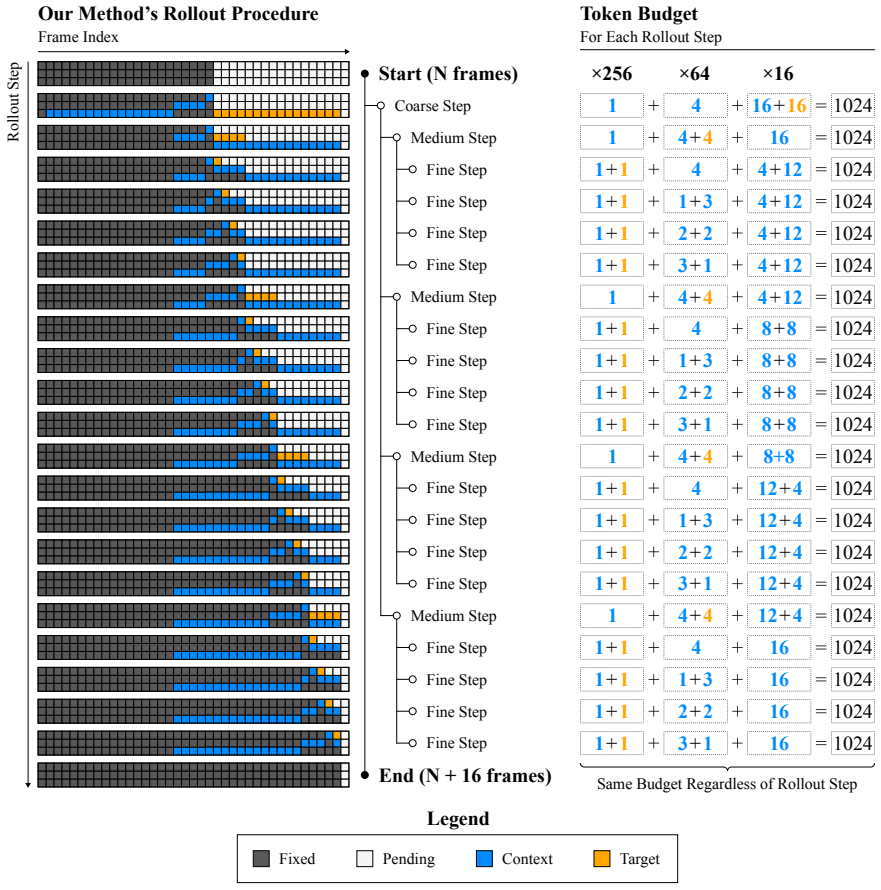
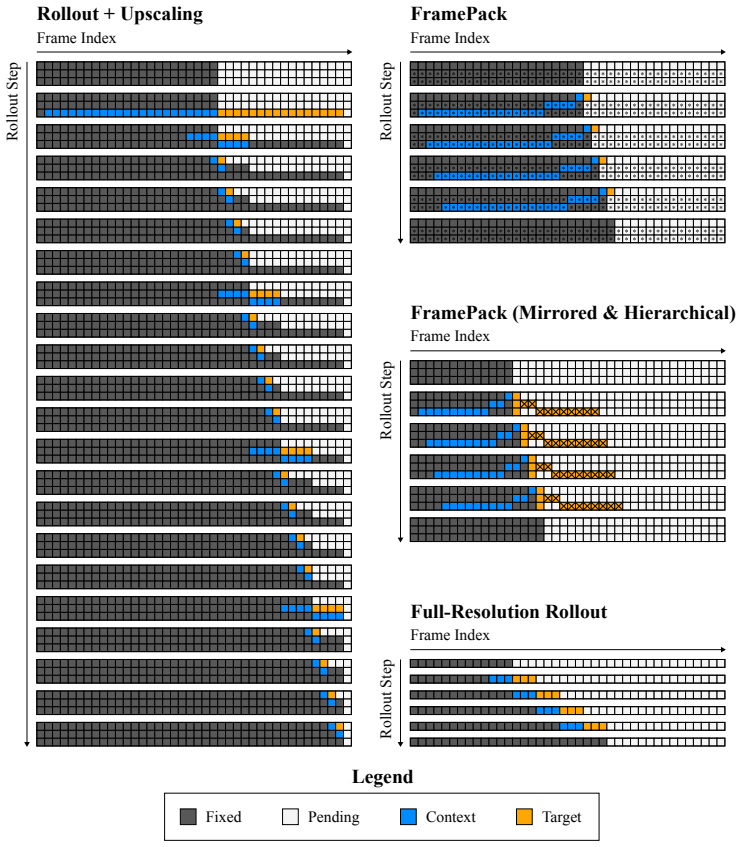
We pre-train an autoencoder that compresses each frame into a hierarchy of tokens ranging from typical latent resolution down to a handful per frame. The video diffusion model then generates these tokens via coarse-to-fine rollout, controlling the detail level for both generation and context to maintain consistency in geometry and object permanence while using less compute on less relevant details. On long Minecraft videos, this yields substantially more consistent rollouts than baselines.
What carries the argument
The hierarchy of tokens produced by the autoencoder, with coarsest levels capturing consequential scene information, and the coarse-to-fine rollout procedure in the diffusion model that selectively uses coarser context for long-range enforcement.
If this is right
- Longer video sequences become feasible without quadratic increases in sequence length.
- Geometry and object permanence remain stable over extended rollouts.
- Compute is allocated more efficiently by deferring fine details.
- Outperforms existing methods on custom long Minecraft video dataset.
Where Pith is reading between the lines
- The method could extend to other domains like long audio sequences or 3D model generation where multi-scale consistency is needed.
- Future work might explore adaptive selection of scale based on scene complexity rather than fixed rollout.
- Integration with existing video models could allow scaling to minute-long generations.
Load-bearing premise
That the coarsest token levels reliably capture the most consequential information like scene layout and that selectively using coarser context suffices to enforce long-range consistency without full-resolution context.
What would settle it
Train the model but replace the coarsest tokens with noise during rollout and measure if long-range consistency metrics degrade compared to the full method on the Minecraft dataset.
Figures


read the original abstract
Video generative models have become increasingly powerful, but long-range consistency remains challenging to achieve because even a few dozen frames require impractically long transformer sequence lengths. We show that this issue can be mitigated by generating video using coarse-to-fine rollout within a multi-scale token space. Our approach is simple: first, we pre-train an autoencoder that compresses each frame into a hierarchy of tokens, with levels ranging from the typical latent resolution to only a handful of tokens per frame. The coarsest levels capture the most consequential information, such as scene layout and semantics, while finer levels add high-frequency appearance and texture. Then, we train a video diffusion model to generate these tokens using coarse-to-fine rollout. By carefully controlling the level of detail at which frames are generated and used as context during each rollout step, we are able to preserve long-range consistency in geometry and object permanence while spending less compute on the long-range consistency of less perceptually relevant details. We validate this approach using a custom dataset of long Minecraft videos, where it produces substantially more consistent rollouts compared to existing baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents MilliVid, which pre-trains a hierarchical autoencoder to compress each video frame into a multi-scale token hierarchy (from standard latent resolution down to a handful of tokens) and then trains a video diffusion model to generate these tokens via coarse-to-fine rollout. By selectively using coarser token levels for long-range context while generating finer details only locally, the method aims to enforce consistency in geometry and object permanence over long sequences at reduced compute cost. Validation is performed on a custom dataset of long Minecraft videos, where the approach is claimed to produce substantially more consistent rollouts than existing baselines.
Significance. If the empirical claims hold, the hierarchical latent rollout provides a practical engineering solution to the transformer sequence-length barrier in video generation, allowing longer consistent outputs by allocating compute preferentially to perceptually salient details. The approach is notable for its simplicity and direct targeting of the consistency bottleneck rather than relying on architectural scaling alone.
major comments (3)
- [Abstract / Experiments] Abstract and Experiments: the central claim that the method 'produces substantially more consistent rollouts compared to existing baselines' is presented without any quantitative metrics, tables, error bars, or detailed comparison protocol; this absence makes the magnitude and reliability of the improvement impossible to assess and is load-bearing for the paper's contribution.
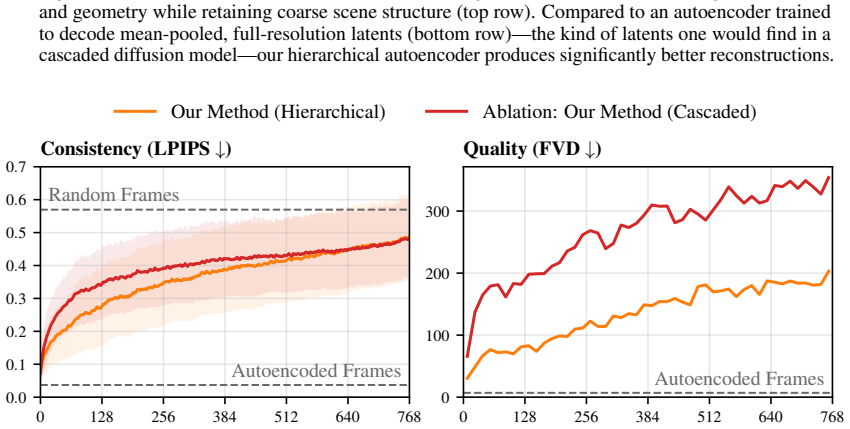
- [Method] Method (hierarchical autoencoder and rollout): the key assumption that coarsest token levels reliably encode scene layout and semantics (and that selective coarse context during rollout suffices to enforce long-range consistency) is asserted but not supported by any ablation, reconstruction analysis, or verification that coarser levels capture consequential information without full-resolution context over distance.
- [Validation / Experiments] Validation: reliance on an unspecified custom Minecraft dataset for all quantitative claims introduces unaddressed risks of selection bias or content-specific overfitting; no details on dataset size, diversity, construction criteria, or controls for Minecraft-style artifacts are provided, weakening the generalizability of the consistency results.
minor comments (1)
- [Abstract] The abstract would benefit from explicit mention of achieved sequence lengths (e.g., number of frames) to ground the term 'long-range'.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments identify key areas where additional empirical support and documentation will strengthen the manuscript. We respond point-by-point below and will revise the paper to address each concern.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments: the central claim that the method 'produces substantially more consistent rollouts compared to existing baselines' is presented without any quantitative metrics, tables, error bars, or detailed comparison protocol; this absence makes the magnitude and reliability of the improvement impossible to assess and is load-bearing for the paper's contribution.
Authors: We agree that the absence of quantitative metrics weakens the central claim. The current version relies primarily on qualitative descriptions of consistency. In the revised manuscript we will add quantitative consistency metrics (e.g., object permanence and geometric drift measures), comparison tables against baselines, error bars from repeated runs, and a clear protocol for the evaluation. revision: yes
-
Referee: [Method] Method (hierarchical autoencoder and rollout): the key assumption that coarsest token levels reliably encode scene layout and semantics (and that selective coarse context during rollout suffices to enforce long-range consistency) is asserted but not supported by any ablation, reconstruction analysis, or verification that coarser levels capture consequential information without full-resolution context over distance.
Authors: We acknowledge that the assumption requires explicit verification. The revised manuscript will include (i) reconstruction analyses comparing information preserved at each hierarchy level, (ii) ablations that isolate the contribution of coarse versus fine tokens to long-range consistency, and (iii) controlled experiments confirming that coarse context alone suffices for the targeted consistency properties. revision: yes
-
Referee: [Validation / Experiments] Validation: reliance on an unspecified custom Minecraft dataset for all quantitative claims introduces unaddressed risks of selection bias or content-specific overfitting; no details on dataset size, diversity, construction criteria, or controls for Minecraft-style artifacts are provided, weakening the generalizability of the consistency results.
Authors: We agree that full dataset documentation is necessary. The revision will provide the missing details: total number of videos and frames, diversity criteria, construction procedure, and any controls applied for Minecraft-specific artifacts. We will also add a limitations paragraph discussing potential overfitting and generalizability beyond the Minecraft domain. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper describes an empirical engineering approach: pre-training a hierarchical autoencoder to produce multi-scale tokens, followed by training a video diffusion model that uses a coarse-to-fine rollout strategy during generation. No equations, derivations, or parameter-fitting steps are presented that reduce by construction to the inputs (e.g., no fitted parameters renamed as predictions, no self-definitional claims, and no load-bearing self-citations or uniqueness theorems). The central claim is supported by validation on a custom Minecraft dataset rather than any internal reduction or ansatz smuggling. The method is a practical mitigation for sequence length limits, with the hierarchical property treated as an observed outcome of the autoencoder rather than a derived necessity.
Axiom & Free-Parameter Ledger
invented entities (1)
-
multi-scale token hierarchy
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Training agents inside of scalable world models, 2025
Danijar Hafner, Wilson Yan, and Timothy Lillicrap. Training agents inside of scalable world models, 2025. URLhttps://arxiv.org/abs/2509.24527. 1
Pith/arXiv arXiv 2025
-
[2]
Learning universal policies via text-guided video generation
Yilun Du, Sherry Yang, Bo Dai, Hanjun Dai, Ofir Nachum, Josh Tenenbaum, Dale Schuurmans, and Pieter Abbeel. Learning universal policies via text-guided video generation. InAdvances in Neural Information Processing Systems, volume 36, pages 9156–9172, 2023
2023
-
[3]
This&that: Language-gesture controlled video generation for robot planning
Boyang Wang, Nikhil Sridhar, Chao Feng, Mark Van der Merwe, Adam Fishman, Nima Fazeli, and Jeong Joon Park. This&that: Language-gesture controlled video generation for robot planning. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 12842–12849. IEEE, 2025
2025
-
[4]
World action models are zero-shot policies, 2026
Seonghyeon Ye, Yunhao Ge, Kaiyuan Zheng, Shenyuan Gao, Sihyun Yu, George Kurian, Suneel Indupuru, You Liang Tan, Chuning Zhu, Jiannan Xiang, Ayaan Malik, Kyungmin Lee, William Liang, Nadun Ranawaka, Jiasheng Gu, Yinzhen Xu, Guanzhi Wang, Fengyuan Hu, Avnish Narayan, Johan Bjorck, Jing Wang, Gwanghyun Kim, Dantong Niu, Ruijie Zheng, Yuqi Xie, Jimmy Wu, Qi ...
Pith/arXiv arXiv 2026
-
[5]
Freeman, Jitendra Malik, Pieter Abbeel, Russ Tedrake, Vincent Sitzmann, and Yilun Du
Boyuan Chen, Tianyuan Zhang, Haoran Geng, Kiwhan Song, Caiyi Zhang, Peihao Li, William T. Freeman, Jitendra Malik, Pieter Abbeel, Russ Tedrake, Vincent Sitzmann, and Yilun Du. Large video planner enables generalizable robot control, 2025. URLhttps://arxiv.org/abs/2512.15840
Pith/arXiv arXiv 2025
-
[6]
Ryan Po, David Junhao Zhang, Amir Hertz, Gordon Wetzstein, Neal Wadhwa, and Nataniel Ruiz. Multigen: Level-design for editable multiplayer worlds in diffusion game engines.arXiv preprint arXiv:2603.06679,
-
[7]
Frame context packing and drift prevention in next-frame-prediction video diffusion models
Lvmin Zhang, Shengqu Cai, Muyang Li, Gordon Wetzstein, and Maneesh Agrawala. Frame context packing and drift prevention in next-frame-prediction video diffusion models. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. 1, 3, 5, 6, 7, 15, 16
2025
-
[8]
Learning long-context diffusion policies via past-token prediction
Marcel Torne Villasevil, Andy Tang, Yuejiang Liu, and Chelsea Finn. Learning long-context diffusion policies via past-token prediction. In Joseph Lim, Shuran Song, and Hae-Won Park, editors,Proceedings of The 9th Conference on Robot Learning, volume 305 ofProceedings of Machine Learning Research, pages 1744–1755. PMLR, 2025. URLhttps://proceedings.mlr.pre...
2025
-
[9]
Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, page 02783649241273668, 2023
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, page 02783649241273668, 2023
2023
-
[10]
Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn
Tony Z. Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn. Learning fine-grained bimanual manipula- tion with low-cost hardware. InProceedings of Robotics: Science and Systems, Daegu, Republic of Korea, July 2023. doi: 10.15607/RSS.2023.XIX.016. 2
-
[11]
Flextok: Resampling images into 1d token sequences of flexible length
Roman Bachmann, Jesse Allardice, David Mizrahi, Enrico Fini, O ˘guzhan Fatih Kar, Elmira Amirloo, Alaaeldin El-Nouby, Amir Zamir, and Afshin Dehghan. Flextok: Resampling images into 1d token sequences of flexible length. InF orty-second International Conference on Machine Learning, 2025. 2
2025
-
[12]
Shivam Duggal, Phillip Isola, Antonio Torralba, and William T. Freeman. Adaptive length image tokeniza- tion via recurrent allocation. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net, 2025. URL https://openreview.net/ forum?id=mb2ryuZ3wz. 2 10
2025
-
[13]
Mixture of contexts for long video generation.arXiv preprint arXiv:2508.21058, 2025
Shengqu Cai, Ceyuan Yang, Lvmin Zhang, Yuwei Guo, Junfei Xiao, Ziyan Yang, Yinghao Xu, Zhenheng Yang, Alan Yuille, Leonidas Guibas, et al. Mixture of contexts for long video generation.arXiv preprint arXiv:2508.21058, 2025. 2
arXiv 2025
-
[14]
Context as memory: Scene-consistent interactive long video generation with memory retrieval
Jiwen Yu, Jianhong Bai, Yiran Qin, Quande Liu, Xintao Wang, Pengfei Wan, Di Zhang, and Xihui Liu. Context as memory: Scene-consistent interactive long video generation with memory retrieval. In Proceedings of the SIGGRAPH Asia 2025 Conference Papers, pages 1–11, 2025
2025
-
[15]
Worldmem: Long-term consistent world simulation with memory.arXiv preprint arXiv:2504.12369, 2025
Zeqi Xiao, Yushi Lan, Yifan Zhou, Wenqi Ouyang, Shuai Yang, Yanhong Zeng, and Xingang Pan. Worldmem: Long-term consistent world simulation with memory.arXiv preprint arXiv:2504.12369, 2025. 14
arXiv 2025
-
[16]
Matrix- game 3.0: Real-time and streaming interactive world model with long-horizon memory, 2026
Zile Wang, Zexiang Liu, Jiaxing Li, Kaichen Huang, Baixin Xu, Fei Kang, Mengyin An, Peiyu Wang, Biao Jiang, Yichen Wei, Yidan Xietian, Jiangbo Pei, Liang Hu, Boyi Jiang, Hua Xue, Zidong Wang, Haofeng Sun, Wei Li, Wanli Ouyang, Xianglong He, Yang Liu, Yangguang Li, and Yahui Zhou. Matrix- game 3.0: Real-time and streaming interactive world model with long-...
Pith/arXiv arXiv 2026
-
[17]
Generative view stitching.arXiv preprint arXiv:2510.24718, 2025
Chonghyuk Song, Michal Stary, Boyuan Chen, George Kopanas, and Vincent Sitzmann. Generative view stitching.arXiv preprint arXiv:2510.24718, 2025. 2, 14
Pith/arXiv arXiv 2025
-
[18]
Beyond pixel histories: World models with persistent 3d state.arXiv preprint arXiv:2603.03482, 2026
Samuel Garcin, Thomas Walker, Steven McDonagh, Tim Pearce, Hakan Bilen, Tianyu He, Kaixin Wang, and Jiang Bian. Beyond pixel histories: World models with persistent 3d state.arXiv preprint arXiv:2603.03482, 2026. 2
Pith/arXiv arXiv 2026
-
[19]
Junchao Huang, Xinting Hu, Boyao Han, Shaoshuai Shi, Zhuotao Tian, Tianyu He, and Li Jiang. Mem- ory forcing: Spatio-temporal memory for consistent scene generation on minecraft.arXiv preprint arXiv:2510.03198, 2025. 2
arXiv 2025
-
[20]
principal components
Xin Wen, Bingchen Zhao, Ismail Elezi, Jiankang Deng, and Xiaojuan Qi. " principal components" enable a new language of images. InICCV, pages 16641–16651, 2025. 2
2025
-
[21]
Detailflow: 1d coarse-to-fine autoregressive image generation via next-detail prediction
Yiheng Liu, Liao Qu, Huichao Zhang, Xu Wang, Yi Jiang, Yiming Gao, Hu Ye, Xian Li, Shuai Wang, Daniel K Du, et al. Detailflow: 1d coarse-to-fine autoregressive image generation via next-detail prediction. arXiv preprint arXiv:2505.21473, 2025
arXiv 2025
-
[22]
Elastictok: Adaptive tokenization for image and video
Wilson Yan, V olodymyr Mnih, Aleksandra Faust, Matei Zaharia, Pieter Abbeel, and Hao Liu. Elastictok: Adaptive tokenization for image and video. In Y . Yue, A. Garg, N. Peng, F. Sha, and R. Yu, editors,International Conference on Learning Representations, volume 2025, pages 38036–38056, 2025. URL https://proceedings.iclr.cc/paper_files/paper/2025/file/ 5e...
2025
-
[23]
Scenetok: A compressed, diffusable token space for 3d scenes.CVPR, 2026
Mohammad Asim, Christopher Wewer, and Jan Eric Lenssen. Scenetok: A compressed, diffusable token space for 3d scenes.CVPR, 2026. 2
2026
-
[24]
Devon Hjelm, David Griffiths, Peter Fu, Afshin Dehghan, and Amir Zamir
Andrei Atanov, Jesse Allardice, Roman Bachmann, O˘guzhan Fatih Kar, R. Devon Hjelm, David Griffiths, Peter Fu, Afshin Dehghan, and Amir Zamir. Videoflextok: Flexible-length coarse-to-fine video tokenization. arXiv preprint arXiv:2604.12887, 2026. 2
Pith/arXiv arXiv 2026
-
[25]
Tianwei Xiong, Jun Hao Liew, Zilong Huang, Zhijie Lin, Jiashi Feng, and Xihui Liu. Evatok: Adaptive length video tokenization for efficient visual autoregressive generation.arXiv preprint arXiv:2603.12267,
-
[26]
FlexTok: Resampling images into 1D token sequences of flexible length
Roman Bachmann, Jesse Allardice, David Mizrahi, Enrico Fini, O ˘guzhan Fatih Kar, Elmira Amirloo, Alaaeldin El-Nouby, Amir Zamir, and Afshin Dehghan. FlexTok: Resampling images into 1D token sequences of flexible length. In Aarti Singh, Maryam Fazel, Daniel Hsu, Simon Lacoste-Julien, Felix Berkenkamp, Tegan Maharaj, Kiri Wagstaff, and Jerry Zhu, editors,P...
-
[27]
URL https://proceedings.mlr.press/v267/bachmann25a.html
PMLR, 13–19 Jul 2025. URL https://proceedings.mlr.press/v267/bachmann25a.html. 2
2025
-
[28]
Matryoshka representation learning
Aditya Kusupati, Gantavya Bhatt, Aniket Rege, Matthew Wallingford, Aditya Sinha, Vivek Ramanu- jan, William Howard-Snyder, Kaifeng Chen, Sham Kakade, Prateek Jain, and Ali Farhadi. Matryoshka representation learning. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors,Advances in Neural Information Processing Systems, volume 35, ...
2022
-
[29]
Freeman, Antonio Torralba, and Phillip Isola
Shivam Duggal, Sanghyun Byun, William T. Freeman, Antonio Torralba, and Phillip Isola. Single-pass adaptive image tokenization for minimum program search. InThe Thirty-ninth Annual Conference on Neu- ral Information Processing Systems, 2026. URL https://openreview.net/forum?id=HkTOnCUQ1z. 2
2026
-
[30]
Nvae: A deep hierarchical variational autoencoder.Advances in neural information processing systems, 33:19667–19679, 2020
Arash Vahdat and Jan Kautz. Nvae: A deep hierarchical variational autoencoder.Advances in neural information processing systems, 33:19667–19679, 2020. 2
2020
-
[31]
Cascaded diffusion models for high fidelity image generation.Journal of Machine Learning Research, 23 (47):1–33, 2022
Jonathan Ho, Chitwan Saharia, William Chan, David J Fleet, Mohammad Norouzi, and Tim Salimans. Cascaded diffusion models for high fidelity image generation.Journal of Machine Learning Research, 23 (47):1–33, 2022. 2
2022
-
[32]
Scale space diffusion.arXiv preprint arXiv:2603.08709, 2026
Soumik Mukhopadhyay, Prateksha Udhayanan, and Abhinav Shrivastava. Scale space diffusion.arXiv preprint arXiv:2603.08709, 2026. 2
arXiv 2026
-
[33]
Yuval Atzmon, Maciej Bala, Yogesh Balaji, Tiffany Cai, Yin Cui, Jiaojiao Fan, Yunhao Ge, Siddharth Gururani, Jacob Huffman, Ronald Isaac, et al. Edify image: High-quality image generation with pixel space laplacian diffusion models.arXiv preprint arXiv:2411.07126, 2024. 2
arXiv 2024
-
[34]
Visual autoregressive modeling: Scalable image generation via next-scale prediction.Advances in neural information processing systems, 37:84839–84865, 2024
Keyu Tian, Yi Jiang, Zehuan Yuan, Bingyue Peng, and Liwei Wang. Visual autoregressive modeling: Scalable image generation via next-scale prediction.Advances in neural information processing systems, 37:84839–84865, 2024. 2
2024
-
[35]
Jonathan Ho, William Chan, Chitwan Saharia, Jay Whang, Ruiqi Gao, Alexey Gritsenko, Diederik P Kingma, Ben Poole, Mohammad Norouzi, David J Fleet, et al. Imagen video: High definition video generation with diffusion models.arXiv preprint arXiv:2210.02303, 2022. 3
Pith/arXiv arXiv 2022
-
[36]
I2vgen-xl: High-quality image-to-video synthesis via cascaded diffusion models
Shiwei* Zhang, Jiayu* Wang, Yingya* Zhang, Kang Zhao, Hangjie Yuan, Zhiwu Qing, Xiang Wang, Deli Zhao, and Jingren Zhou. I2vgen-xl: High-quality image-to-video synthesis via cascaded diffusion models. arXiv preprint arXiv:2311.04145, 2023. 3
Pith/arXiv arXiv 2023
-
[37]
Yang Jin, Zhicheng Sun, Ningyuan Li, Kun Xu, Hao Jiang, Nan Zhuang, Quzhe Huang, Yang Song, Yadong Mu, and Zhouchen Lin. Pyramidal flow matching for efficient video generative modeling.arXiv preprint arXiv:2410.05954, 2024. 3
arXiv 2024
-
[38]
Temporally consistent transformers for video generation, 2023
Wilson Yan, Danijar Hafner, Stephen James, and Pieter Abbeel. Temporally consistent transformers for video generation, 2023. URLhttps://arxiv.org/abs/2210.02396. 3, 6
arXiv 2023
-
[39]
Yuchao Gu, Weijia Mao, and Mike Zheng Shou. Long-context autoregressive video modeling with next-frame prediction.arXiv preprint arXiv:2503.19325, 2025. 3
Pith/arXiv arXiv 2025
-
[40]
The unreasonable effectiveness of deep networks as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep networks as a perceptual metric. InCVPR, 2018. 4, 6
2018
-
[41]
The kinetics human action video dataset.arXiv preprint arXiv:1705.06950, 2017
Will Kay, Joao Carreira, Karen Simonyan, Brian Zhang, Chloe Hillier, Sudheendra Vijayanarasimhan, Fabio Viola, Tim Green, Trevor Back, Paul Natsev, et al. The kinetics human action video dataset.arXiv preprint arXiv:1705.06950, 2017. 6
Pith/arXiv arXiv 2017
-
[42]
Stereo magnification: Learning view synthesis using multiplane images.ACM Trans
Tinghui Zhou, Richard Tucker, John Flynn, Graham Fyffe, and Noah Snavely. Stereo magnification: Learning view synthesis using multiplane images.ACM Trans. Graph. (Proc. SIGGRAPH), 37, 2018. URL https://arxiv.org/abs/1805.09817. 6
Pith/arXiv arXiv 2018
-
[43]
Infinite nature: Perpetual view generation of natural scenes from a single image
Andrew Liu, Richard Tucker, Varun Jampani, Ameesh Makadia, Noah Snavely, and Angjoo Kanazawa. Infinite nature: Perpetual view generation of natural scenes from a single image. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), October 2021. 6
2021
-
[44]
Dl3dv-10k: A large-scale scene dataset for deep learning-based 3d vision
Lu Ling, Yichen Sheng, Zhi Tu, Wentian Zhao, Cheng Xin, Kun Wan, Lantao Yu, Qianyu Guo, Zixun Yu, Yawen Lu, et al. Dl3dv-10k: A large-scale scene dataset for deep learning-based 3d vision. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22160–22169, 2024. 6
2024
-
[45]
Are we ready for autonomous driving? the kitti vision benchmark suite
Andreas Geiger, Philip Lenz, and Raquel Urtasun. Are we ready for autonomous driving? the kitti vision benchmark suite. InConference on Computer Vision and Pattern Recognition (CVPR), 2012. 6
2012
-
[46]
Sturm, N
J. Sturm, N. Engelhard, F. Endres, W. Burgard, and D. Cremers. A benchmark for the evaluation of rgb-d slam systems. InProc. of the International Conference on Intelligent Robot Systems (IROS), Oct. 2012. 6
2012
-
[47]
William H Guss, Cayden Codel, Katja Hofmann, Brandon Houghton, Noboru Kuno, Stephanie Milani, Sharada Mohanty, Diego Perez Liebana, Ruslan Salakhutdinov, Nicholay Topin, et al. The minerl competi- tion on sample efficient reinforcement learning using human priors.arXiv preprint arXiv:1904.10079, 2,
arXiv 1904
-
[48]
Jing Wang, Fengzhuo Zhang, Xiaoli Li, Vincent Y . F. Tan, Tianyu Pang, Chao Du, Aixin Sun, and Zhuoran Yang. Error analyses of auto-regressive video diffusion models: A unified framework, 2025. URL https://arxiv.org/abs/2503.10704. 6
arXiv 2025
-
[49]
Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing, 13(4):600–612, 2004
Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Simoncelli. Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing, 13(4):600–612, 2004. 6
2004
-
[50]
Maxime Oquab, Timothée Darcet, Theo Moutakanni, Huy V . V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Russell Howes, Po-Yao Huang, Hu Xu, Vasu Sharma, Shang-Wen Li, Wojciech Galuba, Mike Rabbat, Mido Assran, Nicolas Ballas, Gabriel Synnaeve, Ishan Misra, Herve Jegou, Julien Mairal, Patrick Laba...
2023
-
[51]
LightGlue: Local Feature Matching at Light Speed
Philipp Lindenberger, Paul-Edouard Sarlin, and Marc Pollefeys. LightGlue: Local Feature Matching at Light Speed. InICCV, 2023. 6
2023
-
[52]
Barron, Sofien Bouaziz, Dan B Goldman, Steven M
Keunhong Park, Utkarsh Sinha, Jonathan T. Barron, Sofien Bouaziz, Dan B Goldman, Steven M. Seitz, and Ricardo Martin-Brualla. Nerfies: Deformable neural radiance fields.ICCV, 2021. 6
2021
-
[53]
Wan: Open and advanced large-scale video generative models, 2025
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, Jianyuan Zeng, Jiayu Wang, Jingfeng Zhang, Jingren Zhou, Jinkai Wang, Jixuan Chen, Kai Zhu, Kang Zhao, Keyu Yan, Lianghua Huang, Mengyang Feng, Ningyi Zhang, Pandeng Li, Pingyu Wu, Ruihang Chu, Ruili Feng, Shiwei Zhang, Siyang Sun, Tao Fang, T...
Pith/arXiv arXiv 2025
-
[54]
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603, 2024. 9
Pith/arXiv arXiv 2024
-
[55]
Pytorch: An imperative style, high-performance deep learning library, 2019
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas Köpf, Edward Yang, Zach DeVito, Martin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. Pytorch: An imperative style, high-performa...
Pith/arXiv arXiv 2019
-
[56]
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020. 14
Pith/arXiv arXiv 2010
-
[57]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need.CoRR, abs/1706.03762, 2017. URL http: //arxiv.org/abs/1706.03762. 15
Pith/arXiv arXiv 2017
-
[58]
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross B. Girshick. Masked autoencoders are scalable vision learners.CoRR, abs/2111.06377, 2021. URL https://arxiv.org/ abs/2111.06377. 15
Pith/arXiv arXiv 2021
-
[59]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 4195–4205, 2023. 15
2023
-
[60]
Muon: An optimizer for hidden layers in neural networks, 2024
Keller Jordan, Yuchen Jin, Vlado Boza, Jiacheng You, Franz Cesista, Laker Newhouse, and Jeremy Bern- stein. Muon: An optimizer for hidden layers in neural networks, 2024. URL https://kellerjordan. github.io/posts/muon/. 15
2024
-
[62]
URLhttp://arxiv.org/abs/1711.05101. 15
-
[63]
Weiss, Niru Maheswaranathan, and Surya Ganguli
Jascha Sohl-Dickstein, Eric A. Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics.CoRR, abs/1503.03585, 2015. URL http://arxiv. org/abs/1503.03585. 15
Pith/arXiv arXiv 2015
-
[64]
Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020. 15 13
2020
-
[65]
Progressive distillation for fast sampling of diffusion models.CoRR, abs/2202.00512, 2022
Tim Salimans and Jonathan Ho. Progressive distillation for fast sampling of diffusion models.CoRR, abs/2202.00512, 2022. URLhttps://arxiv.org/abs/2202.00512. 15
Pith/arXiv arXiv 2022
-
[66]
simple diffusion: End-to-end diffusion for high resolution images
Emiel Hoogeboom, Jonathan Heek, and Tim Salimans. simple diffusion: End-to-end diffusion for high resolution images. InInternational Conference on Machine Learning, pages 13213–13232. PMLR, 2023. 15
2023
-
[67]
Classifier-free diffusion guidance, 2022
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance, 2022. URL https://arxiv.org/ abs/2207.12598. 15
Pith/arXiv arXiv 2022
-
[68]
Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502, 2020
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502, 2020. 15, 16
Pith/arXiv arXiv 2010
-
[69]
Diffusion forcing: Next-token prediction meets full-sequence diffusion.Advances in Neural Information Processing Systems, 2024
Boyuan Chen, Diego Marti Monso, Yilun Du, Max Simchowitz, Russ Tedrake, and Vincent Sitzmann. Diffusion forcing: Next-token prediction meets full-sequence diffusion.Advances in Neural Information Processing Systems, 2024. 15
2024
-
[70]
Haoxin Chen, Menghan Xia, Yingqing He, Yong Zhang, Xiaodong Cun, Shaoshu Yang, Jinbo Xing, Yaofang Liu, Qifeng Chen, Xintao Wang, et al. Videocrafter1: Open diffusion models for high-quality video generation.arXiv preprint arXiv:2310.19512, 2023. 15 A Appendix A.1 Test Set Generation Our test set consists of 1,000 videos whose trajectories feature high ov...
Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.