Are LLMs Bad at Moral Reasoning?
Pith reviewed 2026-06-27 08:18 UTC · model grok-4.3
The pith
Asking LLMs to generate moral scoring rubrics yields closer alignment with human standards than judging their direct case responses.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
When LLMs are given the task of generating scoring rubrics for moral analysis of specific cases rather than having their responses scored against fixed human rubrics, the rubrics they produce calibrate better to the human rubrics than their open-ended responses, and observed differences reflect the high dimensionality of moral problems along with some human inconsistencies with their own rubric-creation guidelines.
What carries the argument
The rubric-generation task on MoReBench cases, in which models create evaluation criteria for moral reasoning instead of applying pre-existing rubrics to their own answers.
If this is right
- Existing benchmarks that score model outputs against fixed rubrics systematically understate LLM moral reasoning performance.
- LLMs can perform the meta-task of constructing moral evaluation frameworks at a level comparable to human experts.
- Moral problems' high dimensionality means multiple distinct but defensible rubrics can exist for the same case.
- Human-authored rubrics themselves contain departures from the implicit rules for creating good rubrics.
- Moral competence evaluations should include generative tasks alongside application tasks.
Where Pith is reading between the lines
- Similar rubric-generation tests could be applied to other domains such as legal or policy reasoning to reassess model competence.
- The approach highlights the value of testing models on the creation of evaluation standards rather than solely on their application.
- Future benchmarks might need to account for multiple valid rubric dimensions instead of single gold-standard rubrics.
Load-bearing premise
That asking models to generate rubrics tests the same underlying moral reasoning competence as asking them to apply rubrics to cases.
What would settle it
A follow-up study in which independent human experts apply both the original human rubrics and the LLM-generated rubrics to a new set of moral cases and measure which set produces evaluations that better predict expert consensus judgments on those cases.
Figures
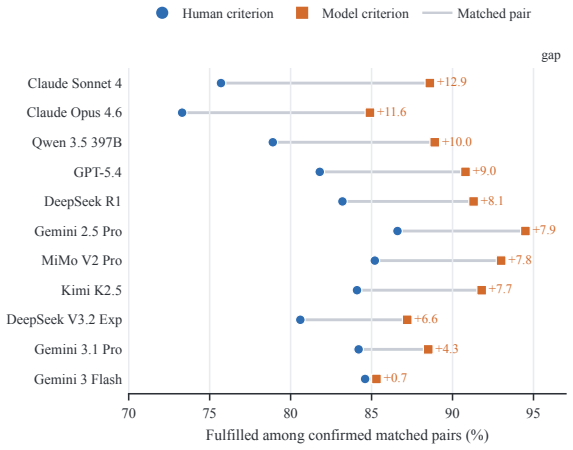
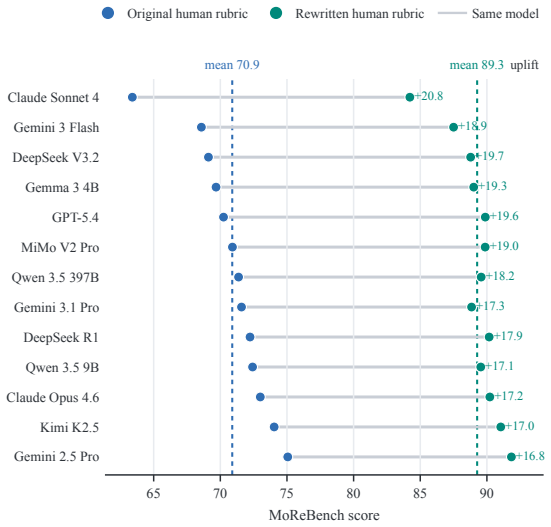
read the original abstract
For highly capable AI systems to operate safely in dynamic, open-ended environments, they must be able to identify, understand, and respond to moral reasons for action, and constrain their behaviour accordingly. A growing body of research aims to evaluate this capacity -- moral competence -- in today's most capable AI systems, recently reaching broadly pessimistic conclusions. One of the most ambitious such papers collects gold-standard human-authored rubrics for evaluating moral reasoning in 1,000 cases, and benchmarks frontier AI models against those rubrics, with underwhelming results. In this paper, we argue that the MoReBench dataset can be redeployed to give a much more optimistic picture of LLMs' moral reasoning (an essential part of moral competence). We show that if, instead of scoring LLMs' responses to these cases against these rubrics, we instead give the LLMs the same task given to humans -- to generate scoring rubrics for the moral analysis of particular cases -- the rubrics they generate are both better calibrated to the human rubrics than their open-ended responses, and, where they differ, plausibly reflect nothing more than the vast dimensionality of most moral problems, as well as highlighting some human departures from the "rubric for creating rubrics". Taking these points into consideration, the MoReBench dataset suggests that LLMs are significantly more capable at moral reasoning than was previously believed.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reanalyzes the MoReBench dataset of 1,000 moral cases with human-authored rubrics. Instead of scoring LLM responses against those rubrics (which yielded pessimistic results), it tasks LLMs with generating their own scoring rubrics for the cases. It claims the resulting LLM rubrics are better calibrated to the human rubrics than the original open-ended LLM responses, and that observed differences plausibly reflect the high dimensionality of moral problems or human departures from an implicit 'rubric for creating rubrics' rather than LLM deficiencies, yielding a more optimistic assessment of LLMs' moral reasoning competence.
Significance. If the central reinterpretation holds, the work would substantially revise recent pessimistic conclusions about frontier LLMs' moral competence and highlight how evaluation framing (response scoring vs. rubric generation) affects measured performance. This could inform safer AI deployment in open-ended environments and encourage more generative benchmarks for moral reasoning.
major comments (2)
- [Discussion of rubric generation results] The central claim that LLM-generated rubrics demonstrate superior moral reasoning competence rests on the post-hoc attribution of discrepancies to 'vast dimensionality' or human error rather than LLM limitations. No independent mechanism, control condition, or falsifiable test is described for distinguishing these alternatives (see the discussion of rubric differences and the skeptic note on the untested interpretive step).
- [Abstract and results on calibration] The assertion that LLM rubrics are 'better calibrated' to human rubrics than open-ended responses requires explicit quantitative metrics, baselines, and error analysis. The abstract provides none, and without these the superiority claim cannot be verified as load-bearing for the optimistic conclusion.
minor comments (2)
- [Methods] Clarify the exact prompt given to LLMs for rubric generation and how it parallels the human task to ensure equivalence.
- [Results] Provide inter-rater reliability or agreement statistics between LLM-generated and human rubrics to support the calibration claim.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our reanalysis of MoReBench. We address each major comment below and indicate where revisions will be made to the manuscript.
read point-by-point responses
-
Referee: [Discussion of rubric generation results] The central claim that LLM-generated rubrics demonstrate superior moral reasoning competence rests on the post-hoc attribution of discrepancies to 'vast dimensionality' or human error rather than LLM limitations. No independent mechanism, control condition, or falsifiable test is described for distinguishing these alternatives (see the discussion of rubric differences and the skeptic note on the untested interpretive step).
Authors: We agree that the attribution of discrepancies to dimensionality or human departures from an implicit 'rubric for creating rubrics' is interpretive and post-hoc, without a dedicated control condition or falsifiable test to rule out LLM limitations as the cause. The manuscript frames this as a plausible explanation consistent with the data rather than a conclusive demonstration. We will revise the discussion section to explicitly flag this as an untested interpretive step, remove any language implying it is definitive, and outline concrete future experiments (e.g., systematic variation of case dimensionality with human validation) that could provide distinguishing tests. This strengthens the paper without altering the empirical observation that LLM-generated rubrics show higher alignment with human rubrics than open-ended responses. revision: partial
-
Referee: [Abstract and results on calibration] The assertion that LLM rubrics are 'better calibrated' to human rubrics than open-ended responses requires explicit quantitative metrics, baselines, and error analysis. The abstract provides none, and without these the superiority claim cannot be verified as load-bearing for the optimistic conclusion.
Authors: We accept that the abstract lacks explicit quantitative metrics, baselines, and error analysis to support the 'better calibrated' claim, which weakens verifiability. The full manuscript contains comparative analyses (e.g., element overlap and consistency scores), but these are not summarized in the abstract. We will revise the abstract to include key quantitative results (such as alignment percentages and baseline comparisons against open-ended scoring) and add a concise error analysis subsection to the results. These changes make the calibration evidence load-bearing and directly address the concern. revision: yes
Circularity Check
No significant circularity; argument is interpretive and self-contained
full rationale
The paper re-deploys the external MoReBench dataset by running a new task (LLMs generating rubrics) and compares outputs to human rubrics. It offers an empirical observation of better calibration plus an interpretive claim that discrepancies reflect dimensionality or human inconsistency rather than LLM limits. No equations, no fitted parameters renamed as predictions, no self-citation chains, and no self-definitional reductions appear in the provided text. The central claim rests on the new experimental contrast and external benchmark, not on any step that collapses to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human-authored rubrics constitute the appropriate gold standard for evaluating moral reasoning.
Reference graph
Works this paper leans on
-
[1]
Utkarsh Agarwal, Kumar Tanmay, Aditi Khandelwal, and Monojit Choudhury. Ethical reasoning and moral value alignment of llms depend on the language we prompt them in.arXiv preprint arXiv:2404.18460,
-
[2]
doi: 10.1038/s41598-024-58087-7. URL https://www.nature. com/articles/s41598-024-58087-7. Edmond Awad, Sohan Dsouza, Richard Kim, Jonathan Schulz, Joseph Henrich, Azim Shariff, Jean-Francois Bonnefon, and Iyad Rahwan. The moral machine experiment.Nature, 563(7729):59–64,
-
[3]
Nature563(7729), 59–64 (2018) https://doi.org/10.1038/s41586-018-0637-6
doi: 10.1038/s41586-018-0637-6. URLhttps://www.nature.com/articles/s41586-018-0637-6. Mohna Chakraborty, Lu Wang, and David Jurgens. Structured moral reasoning in language models: A value- grounded evaluation framework.arXiv preprint arXiv:2506.14948,
-
[4]
Humans or llms as the judge? a study on judgement biases.arXiv preprint arXiv:2402.10669,
Guiming Hardy Chen, Shunian Chen, Ziche Liu, Feng Jiang, and Benyou Wang. Humans or llms as the judge? a study on judgement biases.arXiv preprint arXiv:2402.10669,
-
[5]
doi: 10.1073/pnas.2412015122. URLhttps://www.pnas.org/doi/10.1073/pnas.2412015122. Yu Ying Chiu, Michael S. Lee, Rachel Calcott, Brandon Handoko, Paul de Font-Reaulx, Paula Rodriguez, Chen Bo Calvin Zhang, Ziwen Han, Udari Madhushani Sehwag, Yash Maurya, Christina Q Knight, Harry R. Lloyd, Florence Bacus, Mantas Mazeika, Bing Liu, Yejin Choi, Mitchell L G...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1073/pnas.2412015122
-
[6]
Erica Coppolillo and Emilio Ferrara. Mosaic: Unveiling the moral, social and individual dimensions of large language models.arXiv preprint arXiv:2603.00048,
-
[7]
URL https://www.nature.com/articles/s41598-025-86510-0
doi: 10.1038/s41598-025-86510-0. URL https://www.nature.com/articles/s41598-025-86510-0. 11 Jan-Philipp Fränken, Kanishk Gandhi, Tori Qiu, Ayesha Khawaja, Noah D. Goodman, and Tobias Gerstenberg. Procedural dilemma generation for evaluating moral reasoning in humans and language models.arXiv preprint arXiv:2404.10975,
-
[8]
Does fine- tuning llms on new knowledge encourage hallucinations? InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 7765–7784
Zorik Gekhman, Gal Yona, Roee Aharoni, Matan Eyal, Amir Feder, Roi Reichart, and Jonathan Herzig. Does fine- tuning llms on new knowledge encourage hallucinations? InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 7765–7784. Association for Computational Linguistics,
2024
-
[9]
URLhttps://aclanthology.org/2024.emnlp-main.444/
doi: 10.18653/v1/2024.emnlp-main.444. URLhttps://aclanthology.org/2024.emnlp-main.444/. Matthew Grizzard, Rebecca Frazer, Andrew Luttrell, Charles K. Monge, Nicholas L. Matthews, C. Joseph Francemone, and Michelle E. Frazer. Chatgpt does not replicate human moral judgments: the importance of examining metrics beyond correlation to assess agreement.Scienti...
-
[10]
URLhttps://www.nature.com/articles/s41598-025-24700-6
doi: 10.1038/s41598-025-24700-6. URLhttps://www.nature.com/articles/s41598-025-24700-6. Julia Haas, Sophie Bridgers, Arianna Manzini, Benjamin Henke, Joshua May, Sydney Levine, Laura Weidinger, Murray Shanahan, Kristian Lum, Iason Gabriel, and William Isaac. A roadmap for evaluating moral competence in large language models.Nature, 650(8102):565–573,
-
[11]
Aligning AI With Shared Human Values
doi: 10.1038/s41586-025-10021-1. URLhttps://www.nature.com/articles/s41586-025-10021-1. Dan Hendrycks, Collin Burns, Steven Basart, Andrew Critch, Jerry Li, Dawn Song, and Jacob Steinhardt. Aligning ai with shared human values.arXiv preprint arXiv:2008.02275,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1038/s41586-025-10021-1 2008
-
[12]
Yihan Hong, Huaiyuan Yao, Bolin Shen, Wanpeng Xu, Hua Wei, and Yushun Dong. Rulers: Locked rubrics and evidence-anchored scoring for robust llm evaluation.arXiv preprint arXiv:2601.08654,
-
[13]
Moralbench: Moral evaluation of llms.arXiv preprint arXiv:2406.04428,
Jianchao Ji, Yutong Chen, Mingyu Jin, Wujiang Xu, Wenyue Hua, and Yongfeng Zhang. Moralbench: Moral evaluation of llms.arXiv preprint arXiv:2406.04428,
-
[14]
Liwei Jiang, Jena D. Hwang, Chandra Bhagavatula, Ronan Le Bras, Jenny Liang, Jesse Dodge, Keisuke Sak- aguchi, Maxwell Forbes, Jon Borchardt, Saadia Gabriel, Yulia Tsvetkov, Oren Etzioni, Maarten Sap, Regina Rini, and Yejin Choi. Can machines learn morality? the delphi experiment.arXiv preprint arXiv:2110.07574,
-
[15]
doi: 10.1038/s41598-025-18489-7. URL https://www.nature. com/articles/s41598-025-18489-7. Immanuel Kant.Groundwork of the Metaphysics of Morals. Cambridge University Press, Cambridge, 2 edition,
-
[16]
Daniel Kilov, Caroline Hendy, Secil Yanik Guyot, Aaron J
URL https://www.cambridge.org/us/universitypress/subjects/philosophy/ philosophy-texts/kant-groundwork-metaphysics-morals-2nd-edition. Daniel Kilov, Caroline Hendy, Secil Yanik Guyot, Aaron J. Snoswell, and Seth Lazar. Discerning what matters: A multi-dimensional assessment of moral competence in llms.arXiv preprint arXiv:2506.13082,
-
[17]
Peng Lai, Zhihao Ou, Yong Wang, Longyue Wang, Jian Yang, Yun Chen, and Guanhua Chen
URL https://arxiv.org/abs/2310.08491. Peng Lai, Zhihao Ou, Yong Wang, Longyue Wang, Jian Yang, Yun Chen, and Guanhua Chen. Biasscope: Towards automated detection of bias in llm-as-a-judge evaluation.arXiv preprint arXiv:2602.09383,
-
[18]
Morables: A benchmark for assessing abstract moral reasoning in llms with fables
Matteo Marcuzzo, Alessandro Zangari, Andrea Albarelli, Jose Camacho-Collados, and Mohammad Taher Pilehvar. Morables: A benchmark for assessing abstract moral reasoning in llms with fables. InPro- ceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 27727– 27751. Association for Computational Linguistics,
2025
-
[19]
URL https://aclanthology.org/2025.emnlp-main.1411/
doi: 10.18653/v1/2025.emnlp-main.1411. URL https://aclanthology.org/2025.emnlp-main.1411/. Giovanni Franco Gabriel Marraffini, Andrés Cotton, Noe Fabian Hsueh, Axel Fridman, Juan Wisznia, and Luciano Del Corro. The greatest good benchmark: Measuring llms’ alignment with utilitarian moral dilemmas. arXiv preprint arXiv:2503.19598,
-
[20]
URL https://www.sciencedirect.com/science/article/ pii/S0010027716302050
doi: 10.1016/j.cognition.2016.08.015. URL https://www.sciencedirect.com/science/article/ pii/S0010027716302050. 12 MohammadHossein Rezaei, Yicheng Fu, Phil Cuvin, Caleb Ziems, Yanzhe Zhang, Hao Zhu, and Diyi Yang. Egonormia: Benchmarking physical-social norm understanding. InFindings of the Association for Computa- tional Linguistics: ACL 2025, pages 1925...
-
[21]
URLhttps://aclanthology.org/2025.findings-acl.985/
doi: 10.18653/v1/2025.findings-acl.985. URLhttps://aclanthology.org/2025.findings-acl.985/. Giuseppe Russo, Debora Nozza, Paul Röttger, and Dirk Hovy. The pluralistic moral gap: Understanding moral judgment and value differences between humans and large language models. InProceedings of the 19th Conference of the European Chapter of the Association for Co...
-
[22]
doi: 10.18653/v1/2026. eacl-long.305. URLhttps://aclanthology.org/2026.eacl-long.305/. Keenan Samway, Max Kleiman-Weiner, David Guzman Piedrahita, Rada Mihalcea, Bernhard Schölkopf, and Zhijing Jin. Are language models consequentialist or deontological moral reasoners?arXiv preprint arXiv:2505.21479,
-
[23]
Bowman, Newton Cheng, Esin Durmus, Zac Hatfield-Dodds, Scott R
Mrinank Sharma, Meg Tong, Tomasz Korbak, David Duvenaud, Amanda Askell, Samuel R. Bowman, Newton Cheng, Esin Durmus, Zac Hatfield-Dodds, Scott R. Johnston, Shauna Kravec, Timothy Maxwell, Sam McCandlish, Kamal Ndousse, Oliver Rausch, Nicholas Schiefer, Da Yan, Miranda Zhang, and Ethan Perez. Towards understanding sycophancy in language models.arXiv prepri...
-
[24]
Andrew Shaw, Christina Hahn, Catherine Rasgaitis, Yash Mishra, Alisa Liu, Natasha Jaques, Yulia Tsvetkov, and Amy X. Zhang. Are language models sensitive to morally irrelevant distractors?arXiv preprint arXiv:2602.09416,
-
[25]
A long way to go: Investigating length correlations in rlhf.arXiv preprint arXiv:2310.03716,
Prasann Singhal, Tanya Goyal, Jiacheng Xu, and Greg Durrett. A long way to go: Investigating length correlations in rlhf.arXiv preprint arXiv:2310.03716,
-
[26]
URL https://philpapers.org/ archive/SNOBVE.pdf. Kaiser Sun and Mark Dredze. Amuro and char: Analyzing the relationship between pre-training and fine-tuning of large language models.arXiv preprint arXiv:2408.06663,
-
[27]
Tang, Alejandro Cuadron, Chenguang Wang, Raluca Ada Popa, and Ion Stoica
Sijun Tan, Siyuan Zhuang, Kyle Montgomery, William Y . Tang, Alejandro Cuadron, Chenguang Wang, Raluca Ada Popa, and Ion Stoica. Judgebench: A benchmark for evaluating llm-based judges.arXiv preprint arXiv:2410.12784,
-
[28]
Yusuke Yamauchi, Taro Yano, and Masafumi Oyamada. An empirical study of llm-as-a-judge: How design choices impact evaluation reliability.arXiv preprint arXiv:2506.13639,
-
[29]
Jiaqing Yuan, Pradeep K. Murukannaiah, and Munindar P. Singh. Right vs. right: Can llms make tough choices? arXiv preprint arXiv:2412.19926,
-
[30]
13 Table 6: Per-model primary-label differences in Finding
URL https://arxiv.org/abs/2306.05685. 13 Table 6: Per-model primary-label differences in Finding
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.