Self-Distillation Policy Optimization via Visual Feedback: Bridging Code and Visual Artifacts
Pith reviewed 2026-06-27 13:40 UTC · model grok-4.3
The pith
Visual feedback from rendered outputs lets code-generating LLMs self-distill corrections to defects via grounded credit weighting.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
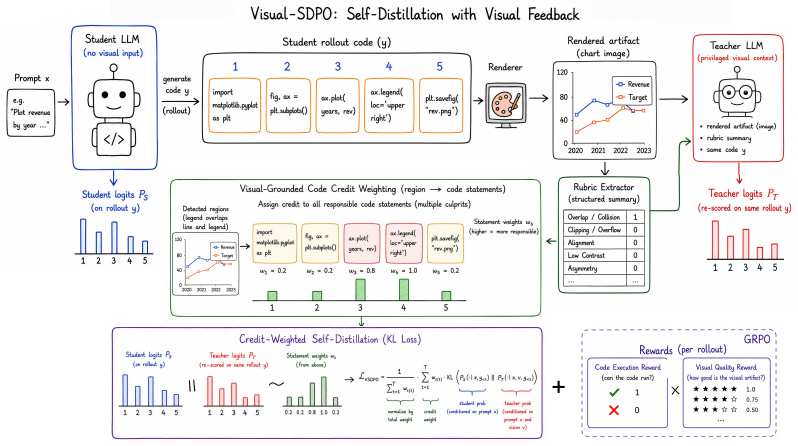
Visual-SDPO treats rendered visual feedback as privileged context for a weight-sharing teacher and distills this feedback into a coding student; Visual-Grounded Code Credit Weighting traces each detected defect back to the code statements responsible for the affected elements and amplifies the distillation signal on those statements; a sequence-level GRPO term complements the dense token-level objective by rewarding executable, visually high-quality rollouts, while failed executions remain learnable through the self-distillation path by passing execution errors as privileged context to the teacher.
What carries the argument
Visual-Grounded Code Credit Weighting traces each detected defect in the rendered output back to the responsible code statements and amplifies the distillation signal on those statements.
If this is right
- Gains exceed 10 absolute points over zero-shot baselines on the primary metric across ChartMimic, Design2Code, and AeSlides.
- Gains exceed 2.4 points over GRPO while requiring fewer training steps and adding no inference-time cost.
- The same framework applies without modification to chart-to-code, UI-to-code, and slide-generation tasks using one backbone model.
- Execution failures stay usable for learning because error messages are passed as privileged context to the teacher.
- The dense token-level distillation objective is complemented by a sequence-level GRPO reward on visual quality.
Where Pith is reading between the lines
- The tracing mechanism could be applied to other code-to-output pipelines where defects in a non-differentiable renderer need to be attributed to source statements.
- Self-distillation from visual feedback may reduce reliance on external reward models or human annotations for visual code generation tasks.
- The approach suggests that weight-sharing teacher-student setups can transfer information across the code-to-render boundary more efficiently than standard policy gradients alone.
Load-bearing premise
Visual defects detected in the rendered output can be reliably traced back to the responsible code statements so that the credit weighting produces a correct rather than noisy distillation signal.
What would settle it
An ablation that replaces the defect-tracing step with random or uniform credit assignment and still obtains the full reported gains on ChartMimic would show that accurate tracing is not required for the claimed improvement.
Figures
read the original abstract
Code-generating large language models (LLMs) increasingly produce visual artifacts such as charts, web pages, and slides by writing programs that are executed by non-differentiable renderers, committing to code before observing the render. As a result, otherwise executable code often yields artifacts with visually salient defects, including overlapping elements, clipped text, broken alignment, low contrast, and overflow. We study visual-feedback self-distillation for code-generated visual artifacts. We propose Visual-SDPO, a self-distillation policy-optimization framework that treats rendered visual feedback as privileged context for a weight-sharing teacher and distills this feedback into a coding student. To make supervision spatially targeted rather than uniform, we introduce Visual-Grounded Code Credit Weighting, which traces each detected defect back to the code statements responsible for the affected elements and amplifies the distillation signal on those statements. A sequence-level GRPO (Group Relative Policy Optimization) term complements the dense token-level objective by rewarding executable, visually high-quality rollouts, while failed executions remain learnable through the self-distillation path by passing execution errors as privileged context to the teacher. We instantiate Visual-SDPO for chart, web/UI, and slide generation with a unified Qwen3-VL-8B-Instruct backbone. Across chart-to-code, UI-to-code, and slide-generation benchmarks (ChartMimic, Design2Code, and AeSlides), Visual-SDPO improves over the zero-shot base by more than 10 absolute points in the primary metric and over GRPO by at least 2.4 points, with fewer training steps and no added inference-time cost.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Visual-SDPO, a self-distillation policy-optimization framework for code-generating LLMs that produces visual artifacts (charts, web pages, slides). Rendered visual feedback serves as privileged context for a weight-sharing teacher that distills into the student; Visual-Grounded Code Credit Weighting traces detected defects (overlap, clipping, etc.) back to responsible code statements to amplify the token-level distillation signal on those statements. A complementary sequence-level GRPO term rewards executable high-quality rollouts. The method is instantiated on a Qwen3-VL-8B backbone and is reported to yield >10 absolute-point gains over the zero-shot base and at least 2.4 points over GRPO on ChartMimic, Design2Code, and AeSlides, with fewer training steps and no inference-time overhead.
Significance. If the empirical gains and the correctness of the defect-to-code attribution hold, the work would demonstrate a practical route to improving visual quality of LLM-generated artifacts via self-distillation that exploits non-differentiable renderers without adding inference cost. The combination of dense token-level credit assignment with sequence-level GRPO is a potentially reusable pattern for other code-to-visual tasks.
major comments (2)
- [Method section on Visual-Grounded Code Credit Weighting] The section describing Visual-Grounded Code Credit Weighting provides no ablation, precision/recall metric on the tracing step, or human agreement study that quantifies how reliably visual defects are mapped back to the exact code statements that produced the affected elements. Because the central claim attributes the gains over GRPO to this targeted credit weighting, the absence of any direct validation of attribution accuracy leaves open the possibility that observed improvements arise from the sequence-level GRPO term or the self-distillation path alone.
- [Experiments and results section] The experimental section (and abstract) reports concrete numeric gains (>10 points over zero-shot, ≥2.4 over GRPO) but supplies no definition of the primary metric, baseline implementations, number of runs, statistical significance tests, or ablation results that isolate the contribution of Visual-Grounded Code Credit Weighting. Without these, the load-bearing empirical claim cannot be assessed.
minor comments (1)
- Clarify whether the tracing procedure is deterministic or involves any learned components, and state the exact failure modes (e.g., overlapping elements that cannot be unambiguously attributed) that are handled by the method.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below and will incorporate the suggested improvements in the revised manuscript.
read point-by-point responses
-
Referee: [Method section on Visual-Grounded Code Credit Weighting] The section describing Visual-Grounded Code Credit Weighting provides no ablation, precision/recall metric on the tracing step, or human agreement study that quantifies how reliably visual defects are mapped back to the exact code statements that produced the affected elements. Because the central claim attributes the gains over GRPO to this targeted credit weighting, the absence of any direct validation of attribution accuracy leaves open the possibility that observed improvements arise from the sequence-level GRPO term or the self-distillation path alone.
Authors: We acknowledge that the current manuscript lacks direct quantitative validation of the attribution accuracy in Visual-Grounded Code Credit Weighting. In the revision we will add an ablation that removes this component while retaining GRPO and self-distillation, precision/recall metrics computed against manually annotated defect-to-statement mappings on a held-out subset, and a human agreement study reporting inter-annotator agreement on the tracing step. revision: yes
-
Referee: [Experiments and results section] The experimental section (and abstract) reports concrete numeric gains (>10 points over zero-shot, ≥2.4 over GRPO) but supplies no definition of the primary metric, baseline implementations, number of runs, statistical significance tests, or ablation results that isolate the contribution of Visual-Grounded Code Credit Weighting. Without these, the load-bearing empirical claim cannot be assessed.
Authors: We agree the experimental reporting requires additional detail. The revision will explicitly define the primary metric, describe baseline implementations, report means and standard deviations over multiple random seeds together with statistical significance tests, and present ablations that isolate the contribution of Visual-Grounded Code Credit Weighting from the GRPO and self-distillation terms. revision: yes
Circularity Check
No circularity; empirical method with external benchmarks
full rationale
The paper describes Visual-SDPO and Visual-Grounded Code Credit Weighting as a new framework, then reports absolute improvements on ChartMimic, Design2Code, and AeSlides benchmarks. No equations, derivations, or self-referential reductions appear in the provided text; the central claims rest on benchmark comparisons rather than any fitted quantity or self-citation chain being renamed as a prediction. The derivation is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Rishabh Agarwal, Nino Vieillard, Yongchao Zhou, Piotr Stanczyk, Sabela Ramos, Matthieu Geist, and Olivier Bachem. On-policy distillation of language models: learning from self- generated mistakes. InInternational Conference on Learning Representations (ICLR), 2024. arXiv:2306.13649
-
[2]
pix2code: Generating Code from a Graphical User Interface Screenshot
Tony Beltramelli. pix2code: generating code from a graphical user interface screenshot. In Proceedings of the ACM SIGCHI Symposium on Engineering Interactive Computing Systems (EICS), 2018. arXiv:1705.07962
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[3]
Lei Chen, Xuanle Zhao, Zhixiong Zeng, Jing Huang, Liming Zheng, Yufeng Zhong, and Lin Ma. Breaking the SFT plateau: multimodal structured reinforcement learning for chart-to-code generation.arXiv preprint arXiv:2508.13587, 2025
-
[4]
Liangyu Chen, Yichen Xu, Jianzhe Ma, Yuqi Liu, Donglu Yang, Liang Zhang, Wenxuan Wang, and Qin Jin. ChartEditor: a reinforcement learning framework for robust chart editing.arXiv preprint arXiv:2511.15266, 2025
-
[5]
Yang Chen, Yufan Shen, Wenxuan Huang, Sheng Zhou, Qunshu Lin, Xinyu Cai, Zhi Yu, Jiajun Bu, Botian Shi, and Yu Qiao. Learning only with images: visual reinforcement learning with reasoning, rendering, and visual feedback.arXiv preprint arXiv:2507.20766, 2025
-
[6]
Yunnong Chen, Shixian Ding, YingYing Zhang, Wenkai Chen, Jinzhou Du, Lingyun Sun, and Liuqing Chen. DesignCoder: hierarchy-aware and self-correcting UI code generation with large language models.arXiv preprint arXiv:2506.13663, 2025
-
[7]
Ken Ding. HDPO: hybrid distillation policy optimization via privileged self-distillation.arXiv preprint arXiv:2603.23871, 2026
-
[8]
DW ARF debugging information format, version 5.https://dwarfstd.org, 2017
DW ARF Debugging Information Format Committee. DW ARF debugging information format, version 5.https://dwarfstd.org, 2017
2017
-
[9]
Yi Gui, Zhen Li, Yao Wan, Yemin Shi, Hongyu Zhang, Bohua Chen, Yi Su, Dongping Chen, Siyuan Wu, Xing Zhou, Wenbin Jiang, Hai Jin, and Xiangliang Zhang. WebCode2M: a real- world dataset for code generation from webpage designs. InProceedings of the ACM Web Conference (WWW), pages 1834–1845, 2025. arXiv:2404.06369
-
[10]
Visual debugging techniques for reactive data visualization.Computer Graphics Forum, 35(3):271–280, 2016
Jane Hoffswell, Arvind Satyanarayan, and Jeffrey Heer. Visual debugging techniques for reactive data visualization.Computer Graphics Forum, 35(3):271–280, 2016. EuroVis 2016
2016
-
[11]
Reinforcement Learning via Self-Distillation
Jonas Hübotter, Frederike Lübeck, Lejs Behric, Anton Baumann, Marco Bagatella, Daniel Marta, Ido Hakimi, Idan Shenfeld, Thomas Kleine Buening, Carlos Guestrin, and Andreas Krause. Reinforcement learning via self-distillation.arXiv preprint arXiv:2601.20802, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[12]
Ryan Li, Yanzhe Zhang, and Diyi Yang
Yilei Jiang, Yaozhi Zheng, Yuxuan Wan, Jiaming Han, Qunzhong Wang, Michael R. Lyu, and Xiangyu Yue. ScreenCoder: advancing visual-to-code generation for front-end automation via modular multimodal agents.arXiv preprint arXiv:2507.22827, 2025
-
[13]
Respecting Self-Uncertainty in On-Policy Self-Distillation for Efficient LLM Reasoning
Junlong Ke, Zichen Wen, Weijia Li, Conghui He, and Linfeng Zhang. Respecting self- uncertainty in on-policy self-distillation for efficient LLM reasoning.arXiv preprint arXiv:2605.13255, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[14]
Ko and Brad A
Andrew J. Ko and Brad A. Myers. Designing the Whyline: a debugging interface for asking questions about program behavior. InProceedings of the SIGCHI Conference on Human Factors in Computing Systems (CHI), pages 151–158, 2004
2004
-
[15]
Hugo Laurençon, Léo Tronchon, and Victor Sanh. Unlocking the conversion of web screenshots into HTML code with the WebSight dataset.arXiv preprint arXiv:2403.09029, 2024. 9
-
[16]
Pix2Struct: screenshot parsing as pretraining for visual language understanding
Kenton Lee, Mandar Joshi, Iulia Raluca Turc, Hexiang Hu, Fangyu Liu, Julian Martin Eisensch- los, Urvashi Khandelwal, Peter Shaw, Ming-Wei Chang, and Kristina Toutanova. Pix2Struct: screenshot parsing as pretraining for visual language understanding. InInternational Conference on Machine Learning (ICML), pages 18893–18912, 2023. arXiv:2210.03347
-
[17]
Yuhang Li, Chenchen Zhang, Ruilin Lv, Ao Liu, Ken Deng, Yuanxing Zhang, Jiaheng Liu, Wiggin Zhou, and Bo Zhou. ReLook: vision-grounded RL with a multimodal LLM critic for agentic web coding.arXiv preprint arXiv:2510.11498, 2025
-
[18]
Unifying distillation and privileged information
David Lopez-Paz, Léon Bottou, Bernhard Schölkopf, and Vladimir Vapnik. Unifying distillation and privileged information. InInternational Conference on Learning Representations (ICLR),
-
[19]
Nsight Graphics shader debugger
NVIDIA. Nsight Graphics shader debugger. https://developer.nvidia.com/ nsight-graphics, 2025
2025
-
[20]
AeSlides: Incentivizing Aesthetic Layout in LLM-Based Slide Generation via Verifiable Rewards
Yiming Pan, Chengwei Hu, Xuancheng Huang, Can Huang, Mingming Zhao, Yuean Bi, Xiaohan Zhang, Aohan Zeng, and Linmei Hu. AeSlides: incentivizing aesthetic layout in LLM-based slide generation via verifiable rewards.arXiv preprint arXiv:2604.22840, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[21]
Wei Pang, Kevin Qinghong Lin, Xiangru Jian, Xi He, and Philip Torr. Paper2Poster: towards multimodal poster automation from scientific papers.arXiv preprint arXiv:2505.21497, 2025
-
[22]
Privileged Information Distillation for Language Models
Emiliano Penaloza, Dheeraj Vattikonda, Nicolas Gontier, Alexandre Lacoste, Laurent Charlin, and Massimo Caccia. Privileged information distillation for language models.arXiv preprint arXiv:2602.04942, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[23]
Reed, Zachary DeVito, Horace He, Ansley Ussery, and Jason Ansel
James K. Reed, Zachary DeVito, Horace He, Ansley Ussery, and Jason Ansel. torch.fx: practical program capture and transformation for deep learning in Python. InProceedings of Machine Learning and Systems (MLSys), 2022. arXiv:2112.08429
-
[24]
How do I inspect a pixel value? https://renderdoc.org/docs/how/how_ inspect_pixel.html, 2025
RenderDoc. How do I inspect a pixel value? https://renderdoc.org/docs/how/how_ inspect_pixel.html, 2025
2025
-
[25]
Juan A. Rodriguez, Haotian Zhang, Abhay Puri, Aarash Feizi, Rishav Pramanik, Pascal Wich- mann, Arnab Mondal, Mohammad Reza Samsami, Rabiul Awal, Perouz Taslakian, Spandana Gella, Sai Rajeswar, David Vazquez, Christopher Pal, and Marco Pedersoli. Rendering-aware reinforcement learning for vector graphics generation.arXiv preprint arXiv:2505.20793, 2025
-
[26]
Anti-Self-Distillation for Reasoning RL via Pointwise Mutual Information
Guobin Shen, Xiang Cheng, Chenxiao Zhao, Lei Huang, Jindong Li, Dongcheng Zhao, and Xing Yu. Anti-self-distillation for reasoning RL via pointwise mutual information.arXiv preprint arXiv:2605.11609, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[27]
Chenglei Si, Yanzhe Zhang, Ryan Li, Zhengyuan Yang, Ruibo Liu, and Diyi Yang. Design2Code: benchmarking multimodal code generation for automated front-end engineering.arXiv preprint arXiv:2403.03163, 2024
-
[28]
A Survey of On-Policy Distillation for Large Language Models
Mingyang Song and Mao Zheng. A survey of on-policy distillation for large language models. arXiv preprint arXiv:2604.00626, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[29]
Alex Stein, Furong Huang, and Tom Goldstein. GATES: self-distillation under privileged context with consensus gating.arXiv preprint arXiv:2602.20574, 2026
-
[30]
Wentao Tan, Qiong Cao, Chao Xue, Yibing Zhan, Changxing Ding, and Xiaodong He. ChartMas- ter: advancing chart-to-code generation with real-world charts and chart similarity reinforcement learning.arXiv preprint arXiv:2508.17608, 2025
- [31]
-
[32]
Mark D. Weiser. Program slicing. InProceedings of the 5th International Conference on Software Engineering (ICSE), pages 439–449, 1981. 10
1981
-
[33]
arXiv preprint arXiv:2406.09961 , year=
Cheng Yang, Chufan Shi, Yaxin Liu, Bo Shui, Junjie Wang, Mohan Jing, Linran Xu, Xinyu Zhu, Siheng Li, Yuxiang Zhang, Gongye Liu, Xiaomei Nie, Deng Cai, and Yujiu Yang. Chart- Mimic: evaluating LMM’s cross-modal reasoning capability via chart-to-code generation. In International Conference on Learning Representations (ICLR), 2025. arXiv:2406.09961
-
[34]
UI2Code^N: UI-to-Code Generation as Interactive Visual Optimization
Zhen Yang, Wenyi Hong, Mingde Xu, Xinyue Fan, Weihan Wang, Jiale Cheng, Xiaotao Gu, and Jie Tang. UI2CodeN: UI-to-code generation as interactive visual optimization.arXiv preprint arXiv:2511.08195, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Xing, Xiaodan Liang, and Zhiqiang Shen
Sukmin Yun, Haokun Lin, Rusiru Thushara, Mohammad Qazim Bhat, Yongxin Wang, Zutao Jiang, Mingkai Deng, Jinhong Wang, Tianhua Tao, Junbo Li, Haonan Li, Preslav Nakov, Timothy Baldwin, Zhengzhong Liu, Eric P. Xing, Xiaodan Liang, and Zhiqiang Shen. Web2Code: a large-scale webpage-to-code dataset and evaluation framework for multimodal LLMs. In Advances in N...
-
[36]
Xuanle Zhao, Deyang Jiang, Zhixiong Zeng, Lei Chen, Haibo Qiu, Jing Huang, Yufeng Zhong, Liming Zheng, Yilin Cao, and Lin Ma. VinciCoder: unifying multimodal code generation via coarse-to-fine visual reinforcement learning.arXiv preprint arXiv:2511.00391, 2025
-
[37]
ChartCoder: advancing multimodal large language model for chart-to-code generation
Xuanle Zhao, Xianzhen Luo, Qi Shi, Chi Chen, Shuo Wang, Zhiyuan Liu, and Maosong Sun. ChartCoder: advancing multimodal large language model for chart-to-code generation. In Annual Meeting of the Association for Computational Linguistics (ACL), pages 7333–7348,
-
[38]
PPTAgent: generating and evaluating presentations beyond text-to-slides
Hao Zheng, Xinyan Guan, Hao Kong, Wenkai Zhang, Jia Zheng, Weixiang Zhou, Hongyu Lin, Yaojie Lu, Xianpei Han, and Le Sun. PPTAgent: generating and evaluating presentations beyond text-to-slides. InConference on Empirical Methods in Natural Language Processing (EMNLP), pages 14402–14418, 2025. 11
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.