ComplianceGate: Classifier-Gated Multi-Tier LLM Routing for Inference in Regulated Industries
Pith reviewed 2026-07-02 20:14 UTC · model grok-4.3
The pith
A pre-inference encoder classifier routes PII queries to local endpoints and simple queries to small models, making data residency violations impossible by design.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
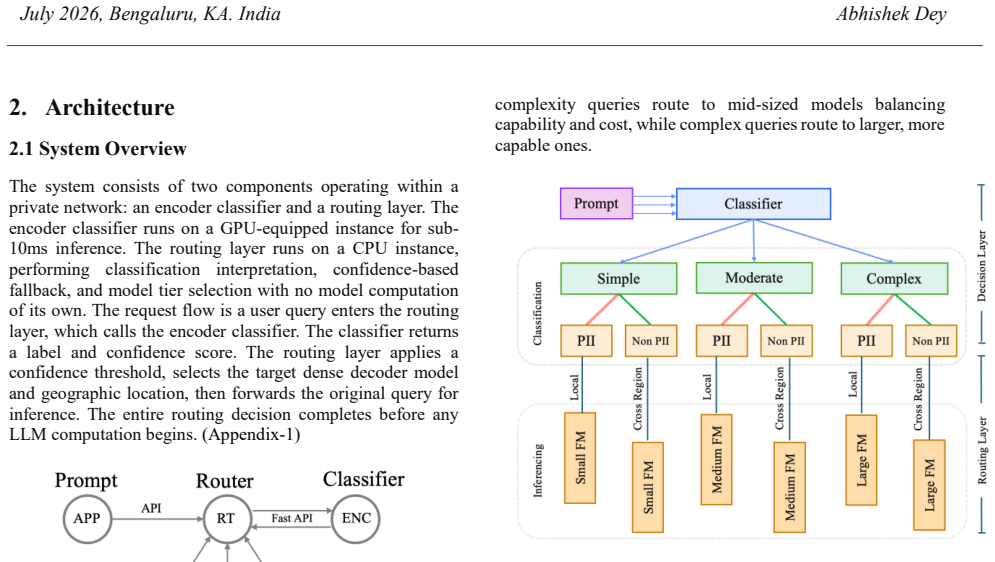
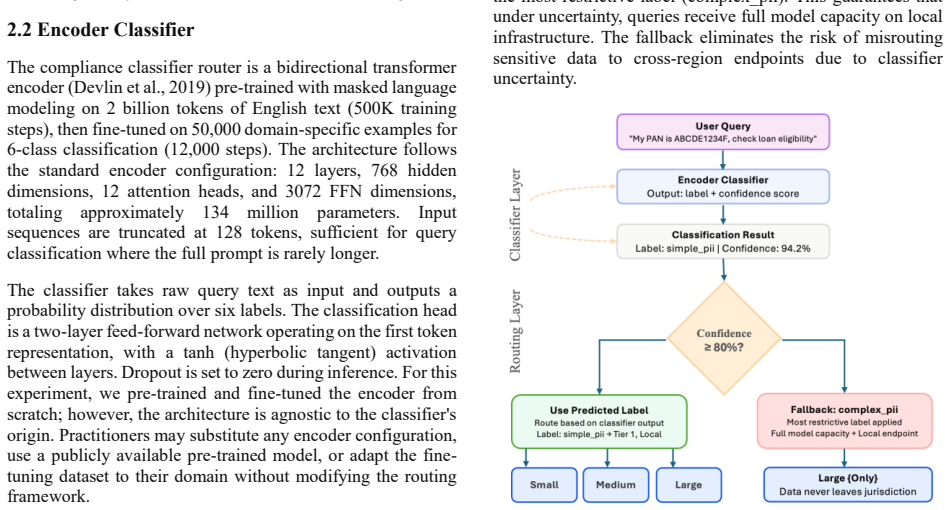
A classifier-gated routing architecture places a trained encoder ahead of all decoder inference. The encoder labels each query for data sensitivity and complexity, then routes PII-containing queries exclusively to local endpoints and simple queries to smaller dense models. This ordering ensures no LLM computation begins until the routing decision is complete, so data residency rules are satisfied structurally rather than through post-hoc checks.
What carries the argument
A trained encoder classifier that evaluates each query for complexity and data sensitivity before any decoder inference begins.
If this is right
- PII data never reaches non-local model endpoints because routing occurs before any LLM computation.
- Simple queries incur only the cost and latency of small dense models rather than full-size ones.
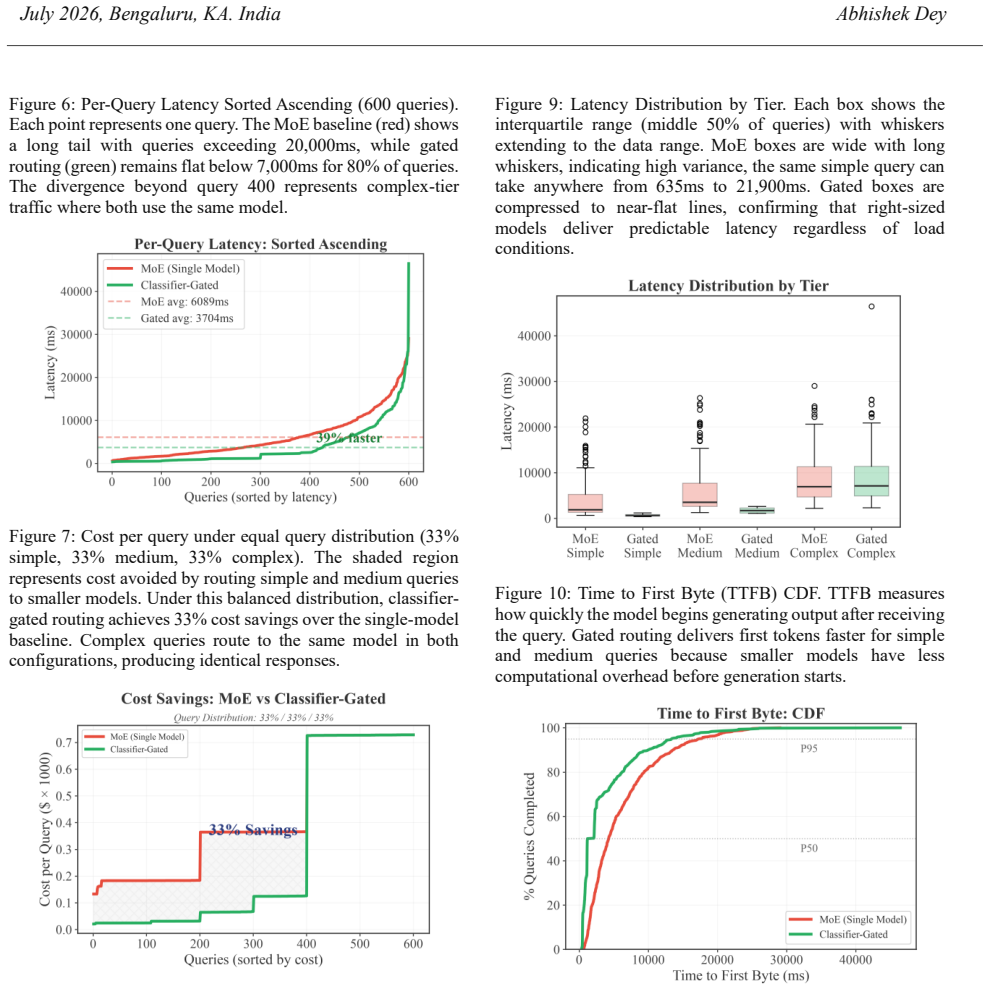
- Median latency falls 39 percent and generation throughput rises to 122-200 tokens per second.
- Cost savings range from 33 to 52 percent depending on the mix of query types.
- Compliance is enforced by the routing topology itself rather than by additional runtime verification.
Where Pith is reading between the lines
- The same pre-inference gate could be extended to additional constraints such as model capability matching or regulatory jurisdiction without changing the core ordering.
- If classifier errors occur mainly on edge cases, organizations could add a small human-review queue for low-confidence classifications.
- The approach separates compliance logic from model architecture, so it could be applied to existing dense or mixture-of-experts deployments.
Load-bearing premise
The encoder classifier can correctly identify PII and query complexity on unseen inputs with 99.2 percent accuracy and near-perfect recall.
What would settle it
A held-out set of queries containing previously unseen PII patterns where the classifier fails to flag them, allowing data to reach a non-local endpoint.
Figures

read the original abstract
Large language models deployed in regulated industries operate under two constraints: compliance enforcement and cost efficiency. Personally identifiable information (PII) in user queries can reach model endpoints before the system determines whether that data should leave its jurisdictional boundary. Serving all queries through a single large model consumes full GPU capacity regardless of query complexity while offering no mechanism for geographic routing. Mixture-of-Experts architectures do not address this routing occurs between expert layers within the model after data has already arrived at the endpoint, with all experts loaded in memory regardless of query complexity. We propose a classifier-gated routing architecture that enforces compliance by design. A trained encoder classifier sits before any decoder inference, evaluating each query for complexity and data sensitivity, then routing it to an appropriately sized dense model in the appropriate geographic location. PII-containing queries route to local endpoints before any LLM computation begins, making data residency violations structurally impossible. Simple queries reach small, fast models at a fraction of the cost. Our evaluation on 600 queries demonstrates 39% median latency reduction, 33-52% cost savings depending on query distribution, and generation throughput of 122-200 tokens/second versus 50-64 for the baseline. The encoder classifier achieves 99.2% accuracy with near-perfect PII recall at 7ms inference overhead, establishing pre-inference classification as a practical path to compliance-by-design LLM deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ComplianceGate, a classifier-gated multi-tier LLM routing architecture for regulated industries. A trained encoder classifier evaluates each incoming query for PII sensitivity and complexity before any decoder inference begins, routing PII queries exclusively to local endpoints and simple queries to smaller, cheaper models in appropriate geographic locations. The central claims are that this makes data-residency violations structurally impossible and yields 39% median latency reduction, 33-52% cost savings, and 122-200 tokens/s throughput on an evaluation of 600 queries, with the classifier achieving 99.2% accuracy and near-perfect PII recall at 7 ms overhead.
Significance. If the empirical results hold under broader testing, the pre-inference classification approach would offer a practical compliance-by-design mechanism that current single-model or MoE deployments lack, while delivering measurable efficiency gains. The work highlights a concrete engineering pattern for separating compliance enforcement from model inference.
major comments (2)
- [Abstract / Evaluation] Abstract and Evaluation section: the manuscript reports aggregate metrics (99.2% accuracy, near-perfect PII recall, 39% latency reduction, etc.) on 600 queries but supplies no information on query sources, labeling process for PII, baseline system details, statistical significance testing, or error analysis. This leaves the central performance and compliance claims without verifiable support.
- [Abstract] Abstract: the claim that PII-containing queries make data residency violations 'structurally impossible' holds only if the classifier has zero false negatives on every possible input. The reported 99.2% accuracy and near-perfect recall on 600 queries does not establish this guarantee; OOD robustness, adversarial or encoded PII, and formal error bounds are not addressed, and no runtime verification or fallback is described.
minor comments (1)
- [Introduction] The distinction between internal MoE routing and the proposed system-level routing could be stated more explicitly to avoid reader confusion.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on the manuscript. We address each of the major comments below and indicate the planned revisions.
read point-by-point responses
-
Referee: [Abstract / Evaluation] Abstract and Evaluation section: the manuscript reports aggregate metrics (99.2% accuracy, near-perfect PII recall, 39% latency reduction, etc.) on 600 queries but supplies no information on query sources, labeling process for PII, baseline system details, statistical significance testing, or error analysis. This leaves the central performance and compliance claims without verifiable support.
Authors: We agree that the current manuscript does not provide sufficient details on the query sources, PII labeling process, baseline system, statistical significance testing, or error analysis. These elements will be added to the Evaluation section and summarized in the abstract in the revised version to ensure the performance and compliance claims are fully supported and verifiable. revision: yes
-
Referee: [Abstract] Abstract: the claim that PII-containing queries make data residency violations 'structurally impossible' holds only if the classifier has zero false negatives on every possible input. The reported 99.2% accuracy and near-perfect recall on 600 queries does not establish this guarantee; OOD robustness, adversarial or encoded PII, and formal error bounds are not addressed, and no runtime verification or fallback is described.
Authors: We concur that the strong claim in the abstract requires qualification, as the classifier's performance is evaluated on a finite set of 600 queries and does not guarantee zero false negatives across all inputs. We will revise the abstract to clarify that data residency violations are rendered impossible for queries correctly classified as containing PII. Additionally, we will include a new Limitations subsection addressing OOD robustness, adversarial and encoded PII, the lack of formal error bounds, and the current absence of runtime verification or fallback mechanisms, framing these as important areas for future research. revision: yes
Circularity Check
No circularity: architecture proposal with empirical evaluation only
full rationale
The paper describes a classifier-gated routing architecture and reports measured performance (99.2% accuracy, latency/cost reductions) on a 600-query evaluation set. No equations, derivations, fitted parameters renamed as predictions, or self-citations appear in the provided text. The central claim that PII routing makes residency violations 'structurally impossible' is an architectural assertion whose validity rests on classifier behavior, not on any reduction of results to inputs by construction. This is a standard empirical systems paper with no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
free parameters (1)
- classifier decision thresholds for complexity and PII sensitivity
axioms (1)
- domain assumption A supervised classifier can be trained to achieve 99.2% accuracy and near-perfect PII recall on the target query distribution
Reference graph
Works this paper leans on
-
[1]
FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance
Chen, L., Zaharia, M., and Zou, J. "FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance." arXiv:2305.05176,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
RouteLLM: Learning to Route LLMs with Preference Data
Ong, I., Almahairi, A., Wu, V ., Chiang, W.-L., Wu, T., Gonzalez, J. E., Kadous, M. W., and Stoica, I. "RouteLLM: Learning to Route LLMs with Preference Data." arXiv:2406.18665,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
AutoMix: Automatically Mixing Language Models
Madaan, A., Tandon, N., Chen, L., Anantha, R., Cheng, P., and Bansal, M. "AutoMix: Automatically Mixing Language Models." arXiv:2310.12963,
-
[4]
Hybrid LLM: Cost-Efficient and Quality-Aware Query Routing
Ding, D., Mallick, A., Wang, C., Sim, R., Mukherjee, S., Ruhle, V ., Lakshmanan, L., and Awadallah, A. H. "Hybrid LLM: Cost-Efficient and Quality-Aware Query Routing." arXiv:2404.14618,
-
[5]
Jiang, A. Q., Sablayrolles, A., Roux, A., Mensch, A., et al. "Mixtral of Experts." arXiv:2401.04088,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Qwen Team. "Qwen3 Technical Report." arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Touvron, H., Martin, L., Stone, K., et al. "Llama 2: Open Foundation and Fine-Tuned Chat Models." arXiv:2307.09288,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
8 July 2026, Bengaluru, KA. India Abhishek Dey Appendix-1: System Architecture The following diagrams illustrate the system architecture, request flow, classification logic, and deployment topology described in Section
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.