HTMLCure: Turning Browser Experience into State Guided Repair for Interactive HTML
Pith reviewed 2026-06-29 15:53 UTC · model grok-4.3
The pith
Browser-executed interaction states guide repairs that turn LLM-generated HTML into reliably functional pages.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
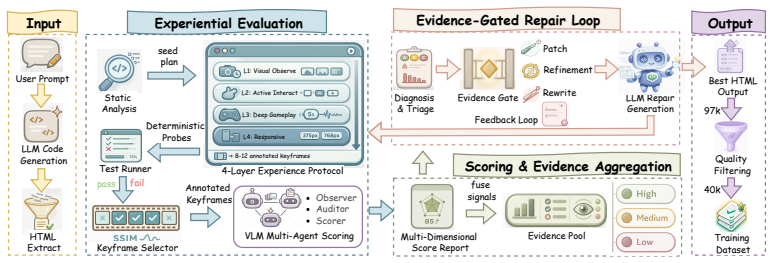
HTMLCure evaluates generated HTML after the browser has executed it across interaction states, records deterministic browser evidence, supplies the VLM with trajectory keyframes, and drives a closed-loop repair engine that chooses state-specific repair families; the quality-cleared pages produced this way expand the usable seed set and, when used for SFT, raise interactive-task performance to the level of much larger reference models.
What carries the argument
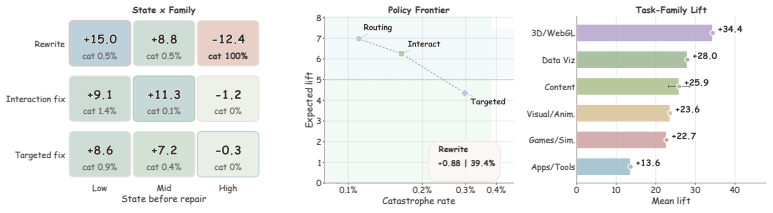
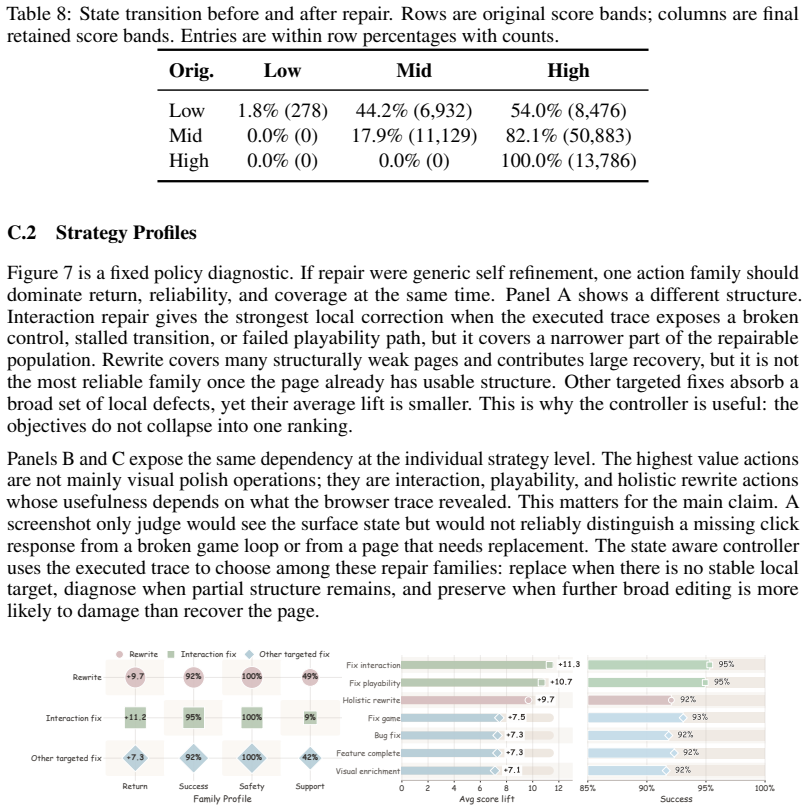
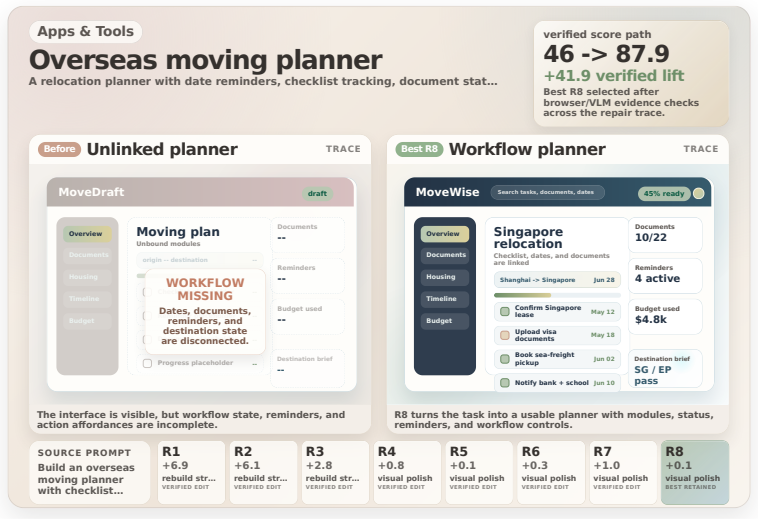
State-guided repair engine that diagnoses the current page from browser trajectory evidence and selects a state-specific repair family before re-testing.
If this is right
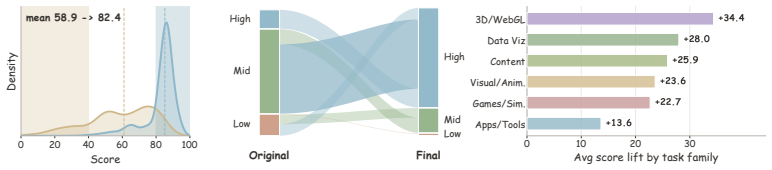
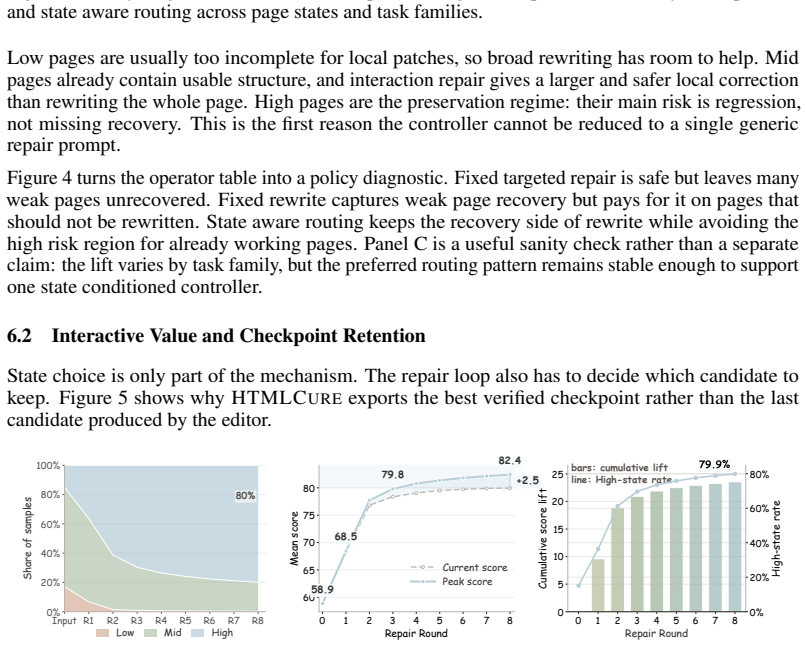
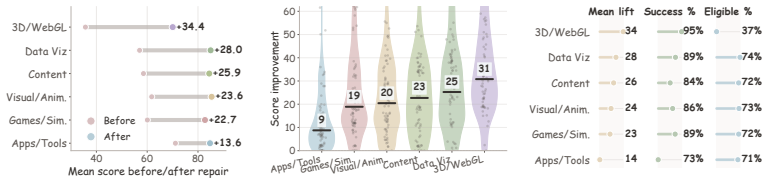
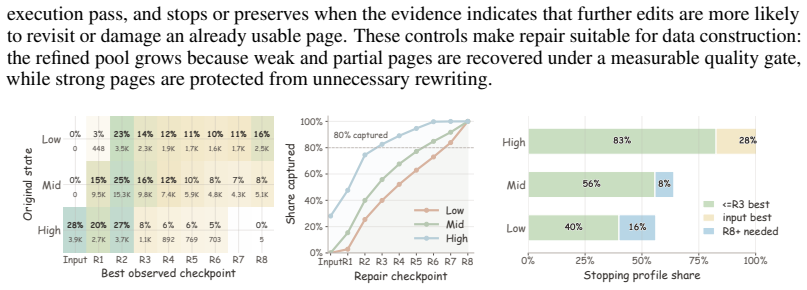
- The fraction of directly usable pages rises from the original seed to roughly two-thirds of the 97K corpus.
- Evaluation of HTML output must include executed trajectories rather than static screenshots alone.
- Repair can be iterated in a closed loop until the page passes the chosen state checks.
- The same state signal can be reused both for diagnosis and for selecting which repair family to apply.
Where Pith is reading between the lines
- The method may reduce reliance on aggressive filtering that discards repairable pages.
- Similar trajectory-based feedback could be applied to other stateful code generation settings such as game logic or UI component libraries.
- If the repair families are made public they could serve as a reusable library for post-generation HTML polishing.
Load-bearing premise
Browser trajectories and state-specific repairs produce training pages whose quality gains transfer to new interactive tasks rather than only matching the particular test suites used.
What would settle it
Train two 27B models on identical recipes except one uses the HTMLCure-refined 40K set and the other uses the raw seed set, then measure pass rates on a fresh interactive HTML benchmark whose test cases were never seen during repair or evaluation.
Figures


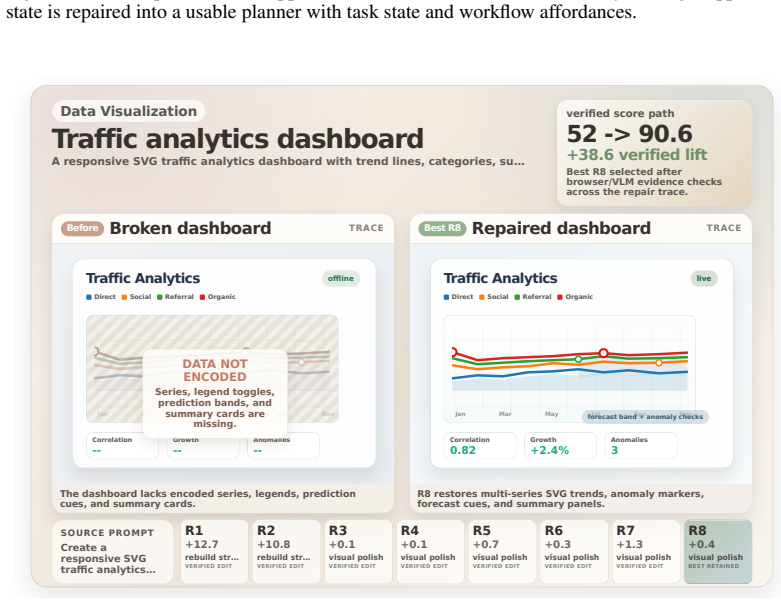
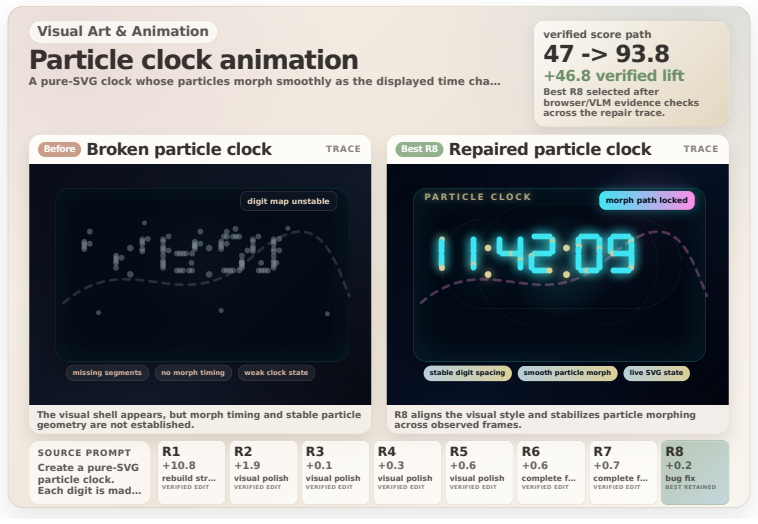

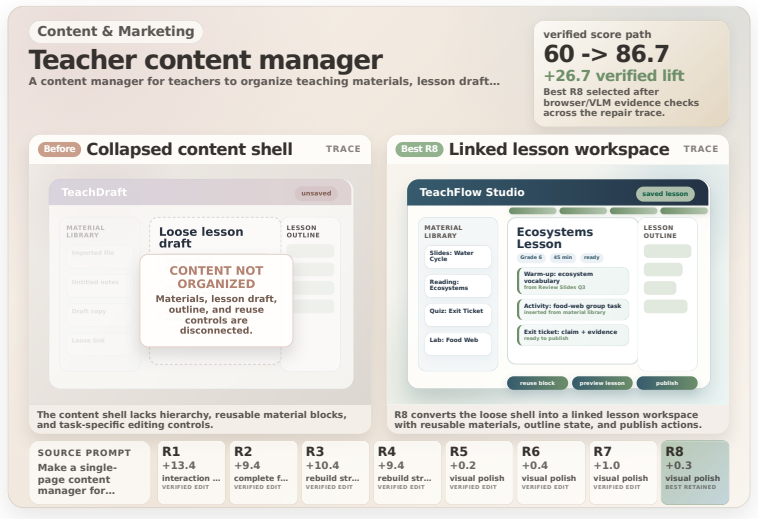
read the original abstract
LLMs can now produce full HTML pages, but many of those pages are only superficially correct: they render once, then fail under scroll, hover, click, resize, or gameplay. Evaluation from screenshots can miss these failures, and filtering discards many pages that are still repairable. We introduce HTMLCure, a browser experience framework that evaluates HTML after the system has interacted with it. The evaluator executes the page across viewports and interaction states, records deterministic browser evidence, and gives the VLM curated keyframes from the executed trajectory rather than isolated screenshots. The same state signal drives a closed loop repair engine: HTMLCure diagnoses the current page, chooses a state specific repair family, runs each candidate again, and exports quality cleared pages for SFT. On a 97K prompt corpus, this expands the directly usable seed into a candidate pool of 63703 quality cleared pages, from which we construct the final refined SFT set of 40K pages. Under the same backbone and training recipe, HTMLCure-27B-Refined reaches 50.6 on HTMLBench-400 with 45.2% deterministic test case pass, placing it in the same performance band as strong reference rows such as Kimi-K2.6 and GPT-5.4. On the released MiniAppBench validation split, it reaches 81.2 average, improving raw 27B SFT by 15.3 points and approaching the level of strong reference systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces HTMLCure, a browser-based framework for evaluating and repairing interactive HTML pages using executed trajectories and state-specific repair families. From a 97K prompt corpus, it generates a 40K refined SFT dataset, resulting in a 27B model that scores 50.6 on HTMLBench-400 (45.2% deterministic test case pass) and 81.2 on MiniAppBench validation, improving 15.3 points over raw SFT and matching strong baselines like Kimi-K2.6 and GPT-5.4.
Significance. If the benchmark gains reflect genuine improvements in interactive HTML generation rather than alignment to specific evaluation metrics, the approach could offer a practical method for curating higher-quality training data for LLMs in web development tasks by incorporating execution feedback.
major comments (2)
- [Abstract] Abstract: The central performance claims (50.6 on HTMLBench-400 with 45.2% pass rate; 81.2 on MiniAppBench) are presented without any description of how the 40K pages were selected from the 63703 candidates, the definition of deterministic test cases, presence of error bars, or controls for potential data leakage between the repair process and the benchmarks. This information is load-bearing for interpreting whether the gains support the claim of improved generalization.
- [Abstract] Abstract: The state-specific repair families are described as driven by browser evidence, but no details are given on how these families were chosen or whether their definition was independent of the viewport and interaction states used in the HTMLBench-400 and MiniAppBench evaluations. If the families were derived from the same interaction patterns, the reported improvements could represent metric-specific optimization rather than broader quality gains.
minor comments (1)
- The term 'quality cleared pages' could be clarified as 'quality-cleared pages' for readability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. We agree that additional methodological details are needed for proper interpretation of the results and will revise the abstract accordingly. Our responses to the major comments are below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central performance claims (50.6 on HTMLBench-400 with 45.2% pass rate; 81.2 on MiniAppBench) are presented without any description of how the 40K pages were selected from the 63703 candidates, the definition of deterministic test cases, presence of error bars, or controls for potential data leakage between the repair process and the benchmarks. This information is load-bearing for interpreting whether the gains support the claim of improved generalization.
Authors: We agree the abstract should summarize these elements. In revision we will add: the 40K set was obtained by further filtering the 63703 quality-cleared pages for interaction-state coverage and prompt diversity; deterministic test cases refer to fixed sequences of browser events with verifiable pass/fail outcomes; error bars are omitted because training used a single seed (computational cost); and benchmark prompts were excluded from the repair and SFT construction pipeline. These points are already elaborated in Sections 3–4; the abstract will now reference them concisely. revision: yes
-
Referee: [Abstract] Abstract: The state-specific repair families are described as driven by browser evidence, but no details are given on how these families were chosen or whether their definition was independent of the viewport and interaction states used in the HTMLBench-400 and MiniAppBench evaluations. If the families were derived from the same interaction patterns, the reported improvements could represent metric-specific optimization rather than broader quality gains.
Authors: The families were derived from a separate exploratory pass over failure modes observed in an initial 10K-page corpus unrelated to the benchmark viewports or interaction sequences. Categories (e.g., layout instability on resize, missing event handlers) are intentionally general. We will insert a clarifying clause in the revised abstract and expand the methods section to state the disjoint construction explicitly. revision: yes
Circularity Check
No significant circularity; derivation self-contained against external benchmarks
full rationale
The paper's chain starts from a 97K prompt corpus, applies browser trajectory evaluation and state-specific repair families to produce a 40K curated SFT set, then trains a 27B model and reports scores on separate held-out sets (HTMLBench-400 at 50.6, MiniAppBench validation at 81.2). These performance figures are post-training measurements on benchmarks not used to define the repair families or curation criteria. No equations, self-definitions, or load-bearing self-citations reduce the claimed gains to the inputs by construction. The central result remains an empirical comparison against a raw SFT baseline under identical training.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
VIBEPASS: Can vibe coders really pass the vibe check?, 2026
Srijan Bansal, Jiao Fangkai, Yilun Zhou, Austin Xu, Shafiq Joty, and Semih Yavuz. VIBEPASS: Can vibe coders really pass the vibe check?, 2026. arXiv preprint arXiv:2603.15921
-
[2]
Teaching Large Language Models to Self-Debug
Xinyun Chen, Maxwell Lin, Nathanael Schärli, and Denny Zhou. Teaching large language models to self-debug, 2023. arXiv preprint arXiv:2304.05128
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Mind2Web: Towards a Generalist Agent for the Web
Xiang Deng, Yu Gu, Boyuan Zheng, Shijie Chen, Samuel Stevens, Boshi Wang, Huan Sun, and Yu Su. Mind2Web: Towards a generalist agent for the web. InAdvances in Neural Information Processing Systems 36, Datasets and Benchmarks Track, 2023. NeurIPS 2023 Spotlight; arXiv preprint arXiv:2306.06070
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Suriya Gunasekar, Yi Zhang, Jyoti Aneja, Caio César Teodoro Mendes, Allie Del Giorno, Sivakanth Gopi, Mojan Javaheripi, Piero Kauffmann, Gustavo de Rosa, Olli Saarikivi, Adil Salim, Shital Shah, Harkirat Singh Behl, Xin Wang, Sébastien Bubeck, Ronen Eldan, Adam Tau- man Kalai, Yin Tat Lee, and Yuanzhi Li. Textbooks are all you need, 2023. arXiv preprint a...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
WebVoyager: Building an End-to-End Web Agent with Large Multimodal Models
Hongliang He, Wenlin Yao, Kaixin Ma, Wenhao Yu, Yong Dai, Hongming Zhang, Zhenzhong Lan, and Dong Yu. WebV oyager: Building an end-to-end web agent with large multimodal mod- els. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics, pages 6864–6890, Bangkok, Thailand, 2024. Association for Computational Linguistics. a...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Vision2Web: A hierarchical benchmark for visual website development with agent verification,
Zehai He, Wenyi Hong, Zhen Yang, Ziyang Pan, Mingdao Liu, Xiaotao Gu, and Jie Tang. Vision2Web: A hierarchical benchmark for visual website development with agent verification,
- [7]
-
[8]
CodeRL: Mastering code generation through pretrained models and deep reinforcement learning
Hung Le, Yue Wang, Akhilesh Deepak Gotmare, Silvio Savarese, and Steven Chu Hong Hoi. CodeRL: Mastering code generation through pretrained models and deep reinforcement learning. InAdvances in Neural Information Processing Systems 35, 2022. NeurIPS 2022; arXiv preprint arXiv:2207.01780
-
[9]
Chenxu Liu, Yingjie Fu, Wei Yang, Ying Zhang, and Tao Xie. WebCoderBench: Benchmarking web application generation with comprehensive and interpretable evaluation metrics, 2026. arXiv preprint arXiv:2601.02430
-
[10]
WebGen-Bench: Evaluating LLMs on generating interactive and functional websites from scratch, 2025
Zimu Lu, Yunqiao Yang, Houxing Ren, Haotian Hou, Han Xiao, Ke Wang, Weikang Shi, Aojun Zhou, Mingjie Zhan, and Hongsheng Li. WebGen-Bench: Evaluating LLMs on generating interactive and functional websites from scratch, 2025. arXiv preprint arXiv:2505.03733
-
[11]
Self- refine: Iterative refinement with self-feedback
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, Shashank Gupta, Bodhisattwa Prasad Majumder, Katherine Hermann, Sean Welleck, Amir Yazdanbakhsh, and Peter Clark. Self- refine: Iterative refinement with self-feedback. InAdvances in Neural Information Processing Sy...
2023
-
[12]
Olausson, Jeevana Priya Inala, Chenglong Wang, Jianfeng Gao, and Armando Solar- Lezama
Theo X. Olausson, Jeevana Priya Inala, Chenglong Wang, Jianfeng Gao, and Armando Solar- Lezama. Is self-repair a silver bullet for code generation? InThe Twelfth International Conference on Learning Representations, 2024. ICLR 2024; arXiv preprint arXiv:2306.09896
-
[13]
Explorer: Scaling exploration-driven web trajectory synthesis for multimodal web agents
Vardaan Pahuja, Yadong Lu, Corby Rosset, Boyu Gou, Arindam Mitra, Spencer Whitehead, Yu Su, and Ahmed Hassan Awadallah. Explorer: Scaling exploration-driven web trajectory synthesis for multimodal web agents. InFindings of the Association for Computational Linguistics: ACL 2025, pages 6300–6323, Vienna, Austria, 2025. Association for Computational Linguis...
-
[14]
Qwen. Qwen3.5. https://huggingface.co/collections/Qwen/qwen35 , 2026. Official Qwen3.5 model collection
2026
-
[15]
Image2Struct: Benchmarking structure extraction for vision-language models
Josselin Somerville Roberts, Tony Lee, Chi Heem Wong, Michihiro Yasunaga, Yifan Mai, and Percy Liang. Image2Struct: Benchmarking structure extraction for vision-language models. In Advances in Neural Information Processing Systems 37, Datasets and Benchmarks Track, 2024. 10
2024
-
[16]
Reflexion: Language Agents with Verbal Reinforcement Learning
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Re- flexion: Language agents with verbal reinforcement learning. InAdvances in Neural Information Processing Systems 36, 2023. NeurIPS 2023; arXiv preprint arXiv:2303.11366
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
De- sign2Code: Benchmarking multimodal code generation for automated front-end engineering
Chenglei Si, Yanzhe Zhang, Ryan Li, Zhengyuan Yang, Ruibo Liu, and Diyi Yang. De- sign2Code: Benchmarking multimodal code generation for automated front-end engineering. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (V olume 1: Long Papers), pages ...
-
[18]
FullFront: Benchmarking MLLMs across the full front-end engineering workflow, 2025
Haoyu Sun, Huichen Will Wang, Jiawei Gu, Linjie Li, and Yu Cheng. FullFront: Benchmarking MLLMs across the full front-end engineering workflow, 2025. arXiv preprint arXiv:2505.17399
-
[19]
Vibe Code Bench: Evaluating AI Models on End-to-End Web Application Development
Hung Tran, Langston Nashold, Rayan Krishnan, Antoine Bigeard, and Alex Gu. Vibe code bench: Evaluating AI models on end-to-end web application development, 2026. arXiv preprint arXiv:2603.04601
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [20]
-
[21]
From code foundation models to agents and applications: A comprehensive survey and practical guide to code intelligence, 2025
Jian Yang, Xianglong Liu, Weifeng Lv, Ken Deng, Shawn Guo, Lin Jing, Yizhi Li, Shark Liu, Xianzhen Luo, Yuyu Luo, Changzai Pan, Ensheng Shi, Yingshui Tan, Renshuai Tao, Jiajun Wu, Xianjie Wu, Zhenhe Wu, Daoguang Zan, Chenchen Zhang, Wei Zhang, He Zhu, Terry Yue Zhuo, Kerui Cao, Xianfu Cheng, Jun Dong, Shengjie Fang, Zhiwei Fei, Xiangyuan Guan, Qipeng Guo,...
2025
-
[22]
Ma, Yuyang Song, Siwei Wu, Yuwen Li, L
Jian Yang, Wei Zhang, Shawn Guo, Zhengmao Ye, Lin Jing, Shark Liu, Yizhi Li, Jiajun Wu, Cening Liu, X. Ma, Yuyang Song, Siwei Wu, Yuwen Li, L. Liao, T. Zheng, Ziling Huang, Zelong Huang, Che Liu, Yan Xing, Renyuan Li, Qingsong Cai, Hanxu Yan, Siyue Wang, Shikai Li, Jason Klein Liu, An Huang, Yongsheng Kang, Jinxing Zhang, Chuan Hao, Haowen Wang, Weicheng ...
2026
-
[23]
WebShop: Towards scalable real-world web interaction with grounded language agents, 2023
Shunyu Yao, Howard Chen, John Yang, and Karthik Narasimhan. WebShop: Towards scalable real-world web interaction with grounded language agents. InAdvances in Neural Information Processing Systems 35, 2022. NeurIPS 2022; arXiv preprint arXiv:2207.01206
-
[24]
ReAct: Synergizing Reasoning and Acting in Language Models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R. Narasimhan, and Yuan Cao. ReAct: Synergizing reasoning and acting in language models. InThe Eleventh International Conference on Learning Representations, 2023. ICLR 2023; arXiv preprint arXiv:2210.03629
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
MiniApp- Bench: Evaluating the shift from text to interactive HTML responses in LLM-powered assistants,
Zuhao Zhang, Chengyue Yu, Yuante Li, Chenyi Zhuang, Linjian Mo, and Shuai Li. MiniApp- Bench: Evaluating the shift from text to interactive HTML responses in LLM-powered assistants,
-
[26]
arXiv preprint arXiv:2603.09652
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
WebArena: A Realistic Web Environment for Building Autonomous Agents
Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig. WebArena: A realistic web environment for building autonomous agents. InThe Twelfth International Conference on Learning Representations, 2024. ICLR 2024; arXiv preprint arXiv:2307.13854. 11 A Limita...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
If a feature is not supported by the Analyst report or probe data, do not assume it exists
Evidence only. If a feature is not supported by the Analyst report or probe data, do not assume it exists
-
[29]
Done items raise the score; broken items penalize more than missing items because they indicate a failed implementation
Functionality is driven by the requirement checklist. Done items raise the score; broken items penalize more than missing items because they indicate a failed implementation
-
[30]
Unresponsive buttons, keyboard failure, gameplay with no state change, or timed-out actions cap interaction
Interaction is constrained by objective probes. Unresponsive buttons, keyboard failure, gameplay with no state change, or timed-out actions cap interaction
-
[31]
Polished but reusable templates should not receive top visual scores without prompt-specific design signals
Visual design is judged from the Analyst's visual evidence. Polished but reusable templates should not receive top visual scores without prompt-specific design signals
-
[32]
Code quality is independent of visual quality and depends on runtime cleanliness, maintainability, event wiring, and implementation organization
-
[33]
rendering
Score conservatively and cite evidence in every reason. Return JSON with the five dimensions and total: { "rendering": {"score": 0, "reason": "..."}, "visual_design": {"score": 0, "reason": "..."}, "functionality": {"score": 0, "reason": "..."}, "interaction": {"score": 0, "reason": "..."}, "code_quality": {"score": 0, "reason": "..."}, "total_score": 0, ...
-
[34]
Load the page and observe initial rendering
-
[35]
Activate entry points such as Start, Submit, Play, Enter, or OK
-
[36]
Test every feature mentioned in the task: - click buttons and interactive elements - fill and submit forms - test navigation, menus, tabs, pagination, and modes - observe and interact with animated or canvas-based content - navigate through multiple states or views
-
[37]
Complete at least one full user workflow
-
[38]
{interaction_guide} ## Report
Report unresponsive elements, visual glitches, broken layout, on-page errors, and missing content. {interaction_guide} ## Report
-
[39]
Rendering: initial page state and visible failures
-
[40]
Feature status: working, partial, broken, or missing
-
[41]
Bug list: what happened versus what should have happened
-
[42]
patches": [{
Overall quality: Excellent, Good, Fair, Poor, or Broken. D.6.3 State Aware Repair Agents The repair stage receives structured browser evidence collected from the current page. The controller selects the strategy, while the prompt exposes the current score, evidence, prior attempts, and preservation constraints to the code generating model. State aware rep...
-
[43]
canvas is not focusable or lacks tabindex
-
[44]
keydown/keyup listeners are attached to the wrong element
-
[45]
preventDefault is missing for arrow keys
-
[46]
key state is not read inside the game loop If {game_layer}=loop:
-
[47]
requestAnimationFrame is never called
-
[48]
loop starts only after a user action
-
[49]
update or draw throws and stops the loop If {game_layer}=canvas:
-
[50]
canvas width or height is zero
-
[51]
getContext is missing or called before the DOM is ready
-
[52]
clearRect runs without redraw
-
[53]
overlay or CSS hides the canvas If {game_layer}=overlay:
-
[54]
game-over or modal screen is visible on load
-
[55]
start screen cannot be dismissed
-
[56]
initial score, lives, or state incorrectly trigger a terminal state If {game_layer}=gameplay:
-
[57]
collision, scoring, state machine, timer, level progression, or physics is wrong
-
[58]
improved
input works but game state does not change correctly ## Current HTML ```html {html} ``` Return the requested patch or full HTML according to {output_mode}. Contrastive visual feedback prompt template.After a candidate is run again, HTMLCUREcan compare before/after keyframes and inject the result into the next repair prompt. This turns the loop from blind ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.