SafeVLA-Bench: A Benchmark for the Success-Safety Gap in Vision-Language-Action Models
Pith reviewed 2026-06-28 18:25 UTC · model grok-4.3
The pith
High task success in vision-language-action models often comes with unsafe behavior such as excessive contact or disturbing objects.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
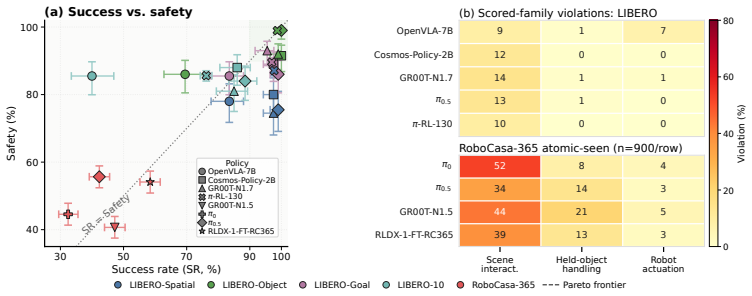
SafeVLA-Bench formalizes task-aware safety requirements as Signal Temporal Logic specifications and introduces two unsafe-success metrics: Succ-But-Unsafe, the fraction of successful rollouts that violate at least one safety clause, and Violation Severity Index, a bounded score of the worst violation depth. Evaluation of nine policy entries on LIBERO and RoboCasa-365 shows that high success rates do not imply safe execution, with unsafe-episode rates of 13 to 15 percent on tabletop tasks and 36 to 56 percent of successful kitchen rollouts violating safety clauses.
What carries the argument
Signal Temporal Logic specifications that encode safety constraints such as limits on contact force, avoidance of bystander objects, and prevention of self-collision, combined with Succ-But-Unsafe and Violation Severity Index to quantify the gap between task success and safety compliance.
If this is right
- Benchmarking of vision-language-action models must report both task success and safety violation rates rather than success alone.
- Policies trained only to maximize task success on current datasets will leave a measurable fraction of executions unsafe.
- Post-hoc safety evaluation can be applied to any existing simulator-based VLA benchmark without retraining the policies.
- Kitchen-scale tasks exhibit higher unsafe-success rates than tabletop tasks under the same evaluation framework.
Where Pith is reading between the lines
- Integrating the safety specifications directly into policy training objectives could close the observed gap rather than only measuring it after training.
- The same approach could be extended to real-robot data if sensor streams are logged at sufficient temporal resolution to support the temporal logic checks.
- Different task domains may require distinct STL templates, so the framework's value depends on developing reusable safety libraries per environment type.
Load-bearing premise
The chosen Signal Temporal Logic rules correctly and completely capture the safety requirements that matter for these manipulation tasks.
What would settle it
Re-evaluating the same policy rollouts with an alternative set of safety specifications or with human judgments of unsafe behavior that produces substantially different Succ-But-Unsafe percentages would indicate that the reported gap depends on the particular rules chosen.
Figures


read the original abstract
Vision-language-action (VLA) benchmarks measure whether a policy completes a requested manipulation task, but binary success can hide safety-relevant trajectory behavior: reaching the goal while applying excessive contact, disturbing bystander objects, destabilizing the held object, or entering robot self-contact. We present SafeVLA-Bench, a post-hoc safety-evaluation framework for existing simulator-based VLA benchmarks. It formalizes task-aware safety requirements as Signal Temporal Logic (STL) specifications and reports native success with two unsafe-success metrics: Succ-But-Unsafe (SBU), the fraction of rollouts that both succeed and violate safety, and Violation Severity Index (VSI), a bounded worst-violation depth score. We instantiate SafeVLA-Bench on LIBERO and RoboCasa-365, evaluating nine policy-benchmark entries across tabletop and kitchen manipulation tasks. High task success does not imply safe execution: high-SR tabletop baselines still leave 13 to 15 percent unsafe-episode rates,and 36 to 56 percent of successful RoboCasa-365 rollouts violate at least one active safety clause. Project page: https://safevla.org.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SafeVLA-Bench, a post-hoc framework that applies task-aware Signal Temporal Logic (STL) specifications to existing VLA benchmark rollouts (LIBERO and RoboCasa-365) to quantify the gap between task success and safety. It defines two metrics—Succ-But-Unsafe (SBU) and Violation Severity Index (VSI)—and evaluates nine policy-benchmark combinations, reporting that high success rates still yield 13–15% unsafe episodes on tabletop tasks and 36–56% safety violations among successful RoboCasa-365 rollouts.
Significance. If the STL specifications hold, the work provides concrete, reproducible evidence that binary success is an incomplete proxy for safe execution in VLA models. The approach is strengthened by its reliance on existing simulator rollouts and first-principles STL definitions rather than fitted parameters or new data collection, offering a practical tool for post-hoc auditing of published policies.
major comments (1)
- [Section 3] STL formalization (Section 3): the predicates and thresholds for contact force, bystander disturbance, object stability, and self-contact are presented without validation (human ratings, threshold sensitivity analysis, or alignment with real incident data). This directly affects the load-bearing claim that the reported 13–15% and 36–56% unsafe-success rates measure genuine safety gaps rather than specification artifacts.
minor comments (2)
- [Abstract] Abstract and §4: the nine evaluated policies are referenced only by aggregate results; a table listing each policy, benchmark, and success rate would improve traceability.
- [Section 3.3] Notation: the bounded worst-violation depth in VSI is described qualitatively; an explicit formula or pseudocode would clarify its computation from STL robustness.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for stronger justification of the STL predicates and thresholds. We agree this is an important point for ensuring the reported safety gaps reflect meaningful concerns rather than arbitrary choices, and we outline our response below.
read point-by-point responses
-
Referee: [Section 3] STL formalization (Section 3): the predicates and thresholds for contact force, bystander disturbance, object stability, and self-contact are presented without validation (human ratings, threshold sensitivity analysis, or alignment with real incident data). This directly affects the load-bearing claim that the reported 13–15% and 36–56% unsafe-success rates measure genuine safety gaps rather than specification artifacts.
Authors: We acknowledge that the manuscript presents the STL predicates and thresholds (e.g., force limits, stability margins) without empirical validation such as human ratings or direct alignment to real-world incident data. These choices are grounded in first-principles physical considerations and standard robotics references (e.g., manufacturer force limits for contact and common stability criteria from manipulation literature), rather than fitted parameters. However, the absence of sensitivity analysis or external validation does represent a limitation for interpreting the absolute SBU rates as definitive safety gaps. In revision we will expand Section 3 with: (1) explicit rationale and citations for each threshold, (2) a sensitivity analysis demonstrating how SBU and VSI change under reasonable threshold perturbations, and (3) a clearer statement that the framework is intended to support customizable specifications. This addition will not alter the core empirical observation that success and safety diverge under the chosen specs, but will better contextualize the results. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper defines SBU and VSI directly from STL predicates applied to existing benchmark rollouts (LIBERO, RoboCasa-365). These are computed quantities on fixed trajectories, not predictions fitted to or derived from the target statistics themselves. No equations reduce the reported unsafe-success rates to the input definitions by construction, no parameters are tuned then relabeled as predictions, and no self-citation chain supplies the load-bearing uniqueness or ansatz for the central empirical claim. The work is a measurement framework whose outputs are falsifiable against the same external rollouts.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Signal Temporal Logic specifications can be defined to capture safety requirements such as contact force limits and collision avoidance in a task-aware manner
Reference graph
Works this paper leans on
-
[1]
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone. LIBERO: Benchmarking knowledge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36:44776–44791, 2023
2023
-
[2]
RoboCasa: Large-Scale Simulation of Everyday Tasks for Generalist Robots
S. Nasiriany, A. Maddukuri, L. Zhang, A. Parikh, A. Lo, A. Joshi, A. Mandlekar, and Y . Zhu. RoboCasa: Large-scale simulation of everyday tasks for generalist robots.arXiv preprint arXiv:2406.02523, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [3]
-
[4]
Zitkovich, T
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahid, et al. RT-2: Vision-language-action models transfer web knowledge to robotic control. In Conference on Robot Learning, pages 2165–2183. PMLR, 2023
2023
-
[5]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, et al. OpenVLA: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, et al.π 0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
J. Bjorck, F. Casta ˜neda, N. Cherniadev, X. Da, R. Ding, L. Fan, Y . Fang, D. Fox, F. Hu, S. Huang, et al. GR00T N1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
M. J. Kim, Y . Gao, T.-Y . Lin, Y .-C. Lin, Y . Ge, G. Lam, P. Liang, S. Song, M.-Y . Liu, C. Finn, et al. Cosmos Policy: Fine-tuning video models for visuomotor control and planning.arXiv preprint arXiv:2601.16163, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[9]
X. Li, K. Hsu, J. Gu, K. Pertsch, O. Mees, H. R. Walke, C. Fu, I. Lunawat, I. Sieh, S. Kir- mani, et al. Evaluating real-world robot manipulation policies in simulation.arXiv preprint arXiv:2405.05941, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
O. Mees, L. Hermann, E. Rosete-Beas, and W. Burgard. CALVIN: A benchmark for language- conditioned policy learning for long-horizon robot manipulation tasks.IEEE Robotics and Automation Letters, 7(3):7327–7334, 2022
2022
-
[11]
Shukla, S
A. Shukla, S. Tao, and H. Su. ManiSkill-HAB: A benchmark for low-level manipulation in home rearrangement tasks. InInternational Conference on Learning Representations, volume 2025, pages 15288–15317, 2025
2025
-
[12]
Zhang, Y
B. Zhang, Y . Zhang, J. Ji, Y . Lei, J. Dai, Y . Chen, and Y . Yang. Safevla: Towards safety alignment of vision-language-action model via constrained learning.Advances in Neural In- formation Processing Systems, 38:153335–153373, 2026
2026
-
[13]
A. D. Ames, X. Xu, J. W. Grizzle, and P. Tabuada. Control barrier function based quadratic programs for safety critical systems.IEEE Transactions on Automatic Control, 62(8):3861– 3876, 2016
2016
-
[14]
G. E. Fainekos and G. J. Pappas. Robustness of temporal logic specifications for continuous- time signals.Theoretical Computer Science, 410(42):4262–4291, 2009
2009
-
[15]
Donz ´e and O
A. Donz ´e and O. Maler. Robust satisfaction of temporal logic over real-valued signals. In International Conference on Formal Modeling and Analysis of Timed Systems, pages 92–106. Springer, 2010. 9
2010
-
[16]
Leung, N
K. Leung, N. Ar ´echiga, and M. Pavone. Backpropagation through signal temporal logic speci- fications: Infusing logical structure into gradient-based methods.The International Journal of Robotics Research, 42(6):356–370, 2023
2023
-
[17]
D. Kim, H. Jang, M. Koo, S. Jang, T. Kim, B. Kim, B. Yoon, C. Jang, D. Choi, D. Han, et al. Rldx-1 technical report.arXiv preprint arXiv:2605.03269, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[18]
grasp-slip @2cm
M. J. Rosenstrauch and J. Kr ¨uger. Safe human-robot-collaboration-introduction and experi- ment using ISO/TS 15066. In2017 3rd International Conference on Control, Automation and Robotics (ICCAR), pages 740–744. IEEE, 2017. 10 Appendix Appendix contents A Additional Experimental Results 12 A.1 Qualitative Successful-but-Unsafe Examples . . . . . . . . . ...
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.