Deep sequence models tend to memorize geometrically; it is unclear why
Pith reviewed 2026-05-21 20:33 UTC · model grok-4.3
The pith
Deep sequence models synthesize embeddings that encode global relationships between all entities, even without direct co-occurrence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Deep sequence models synthesize embeddings encoding novel global relationships between all entities, including ones that do not co-occur in training. Such storage is powerful: for instance, it transforms a hard reasoning task involving an ℓ-fold composition into an easy-to-learn 1-step navigation task. The rise of such a geometry cannot be straightforwardly attributed to typical supervisory, architectural, or optimizational pressures. Instead, by analyzing a connection to Node2Vec, the geometry stems from a spectral bias that arises naturally despite the lack of various pressures.
What carries the argument
Geometric memory: embeddings that form a structure encoding global relationships, reducing multi-step composition to single-step navigation.
Load-bearing premise
The observed geometry stems from a spectral bias that arises naturally rather than from typical supervisory, architectural, or optimization pressures.
What would settle it
Training a sequence model on data where local co-occurrence statistics are preserved but global graph structure is removed, then checking whether the single-step navigation behavior disappears.
Figures













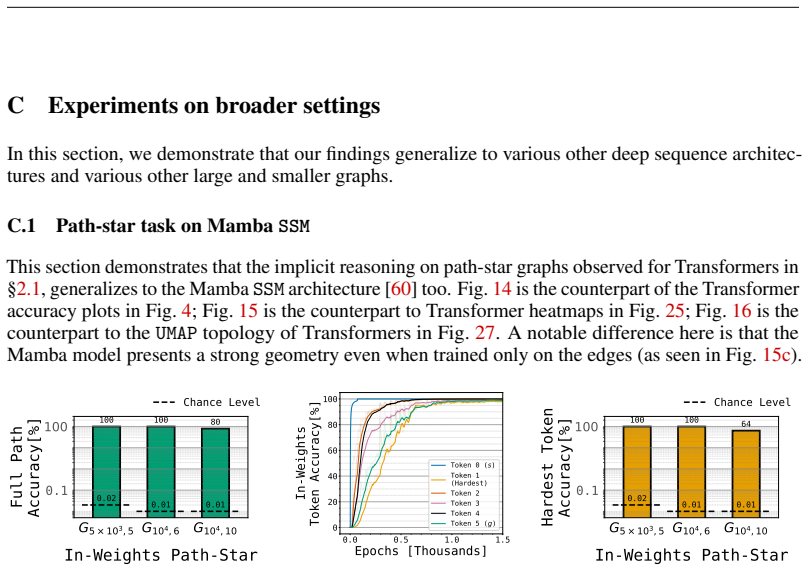





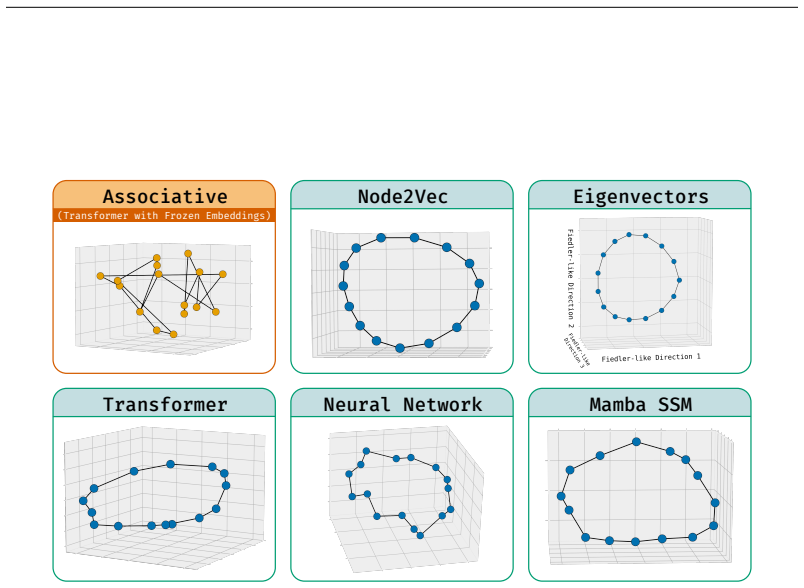
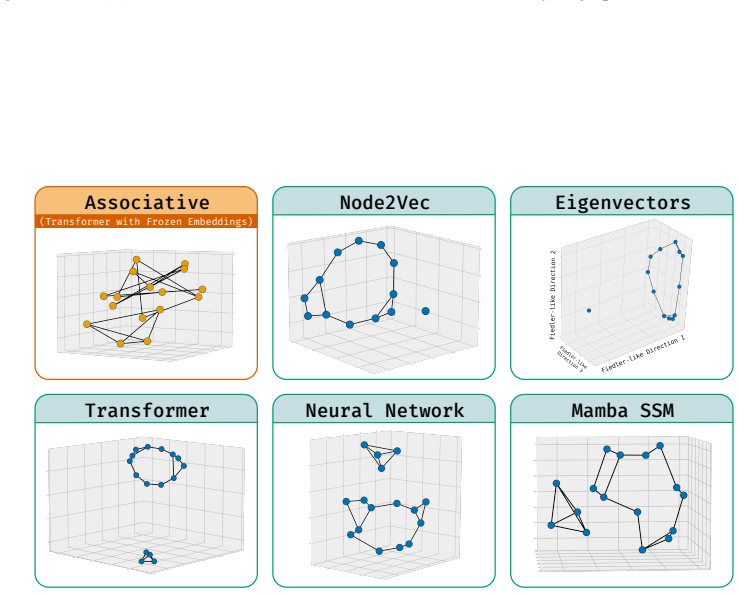














read the original abstract
Deep sequence models are said to store atomic facts predominantly in the form of associative memory: a brute-force lookup of co-occurring entities. We identify a dramatically different form of storage of atomic facts that we term as geometric memory. Here, the model has synthesized embeddings encoding novel global relationships between all entities, including ones that do not co-occur in training. Such storage is powerful: for instance, we show how it transforms a hard reasoning task involving an $\ell$-fold composition into an easy-to-learn $1$-step navigation task. From this phenomenon, we extract fundamental aspects of neural embedding geometries that are hard to explain. We argue that the rise of such a geometry, as against a lookup of local associations, cannot be straightforwardly attributed to typical supervisory, architectural, or optimizational pressures. Counterintuitively, a geometry is learned even when it is more complex than the brute-force lookup. Then, by analyzing a connection to Node2Vec, we demonstrate how the geometry stems from a spectral bias that -- in contrast to prevailing theories -- indeed arises naturally despite the lack of various pressures. This analysis also points out to practitioners a visible headroom to make Transformer memory more strongly geometric. We hope the geometric view of parametric memory encourages revisiting the default intuitions that guide researchers in areas like knowledge acquisition, capacity, discovery, and unlearning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that deep sequence models memorize atomic facts geometrically rather than via associative lookup of co-occurrences. Embeddings are synthesized to encode novel global relationships between all entities (including non-co-occurring ones), transforming an ℓ-fold composition reasoning task into an easy 1-step navigation task. The authors argue this geometry cannot be straightforwardly attributed to typical supervisory, architectural or optimizational pressures, is counterintuitively more complex than brute-force lookup, and instead arises from a spectral bias demonstrated via a connection to Node2Vec; they point to headroom for making Transformer memory more strongly geometric and implications for knowledge acquisition, capacity, discovery and unlearning.
Significance. If the empirical observations and the spectral-bias explanation hold, the work would be significant for offering a distinct geometric view of parametric memory that challenges prevailing intuitions about associative storage. The Node2Vec link could bridge empirical findings with spectral graph methods, while the practical suggestion for enhancing geometric properties in Transformers would be useful for practitioners working on reasoning and knowledge representation.
major comments (2)
- [Node2Vec analysis] Section on Node2Vec connection: the central claim that the observed global geometry 'stems from a spectral bias that arises naturally' rests on the Node2Vec analysis. This connection is presented as explanatory, yet remains analogical; the manuscript does not isolate whether random-walk co-occurrence statistics alone produce the reported eigenstructure independently of the sequence model's layered back-propagation and next-token loss. Without such isolation or controls, the argument that the geometry cannot be attributed to standard training dynamics is not yet secured.
- [Empirical observations] Empirical sections describing non-co-occurring pairs and ℓ-fold to 1-step transformation: the claim that embeddings encode novel global relationships (including for entities that never co-occur) is load-bearing for the 'geometric memory' phenomenon. Full methods, data-selection controls, and ablations are needed to rule out post-hoc artifacts, as the current presentation leaves open whether the geometry is a general tendency or specific to the chosen setups.
minor comments (2)
- [Abstract] Abstract: the term 'geometric memory' is introduced without a concise formal characterization on first use, which would help readers grasp the distinction from associative memory immediately.
- [Throughout] Notation: ensure consistent use of symbols for embeddings and entity relationships across sections to avoid ambiguity when discussing global vs. local associations.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight opportunities to clarify the Node2Vec analysis and strengthen the empirical controls. We address each point below and will incorporate revisions to improve the manuscript.
read point-by-point responses
-
Referee: [Node2Vec analysis] Section on Node2Vec connection: the central claim that the observed global geometry 'stems from a spectral bias that arises naturally' rests on the Node2Vec analysis. This connection is presented as explanatory, yet remains analogical; the manuscript does not isolate whether random-walk co-occurrence statistics alone produce the reported eigenstructure independently of the sequence model's layered back-propagation and next-token loss. Without such isolation or controls, the argument that the geometry cannot be attributed to standard training dynamics is not yet secured.
Authors: We appreciate the referee's emphasis on securing the isolation. The manuscript presents the Node2Vec link to show that the eigenstructure follows from the co-occurrence statistics generated by next-token prediction on sequences, which implicitly perform random walks on the entity graph; this is not merely analogical but follows because the training objective directly optimizes for those statistics. We agree that an explicit control would make the separation from layered back-propagation clearer. In the revision we will add a non-neural baseline that factorizes the empirical co-occurrence matrix derived from the same data and verifies that the reported spectral properties are recovered without any neural architecture or gradient-based training. revision: yes
-
Referee: [Empirical observations] Empirical sections describing non-co-occurring pairs and ℓ-fold to 1-step transformation: the claim that embeddings encode novel global relationships (including for entities that never co-occur) is load-bearing for the 'geometric memory' phenomenon. Full methods, data-selection controls, and ablations are needed to rule out post-hoc artifacts, as the current presentation leaves open whether the geometry is a general tendency or specific to the chosen setups.
Authors: We agree that additional documentation and controls are warranted to establish generality. The manuscript already specifies the synthetic data generation process and the criterion used to identify non-co-occurring pairs, but the presentation can be made more self-contained. In the revision we will expand the methods section with explicit data-selection rules, include supplementary ablations that vary the proportion of non-co-occurring pairs and the graph structure, and report results on an alternative synthetic task to demonstrate that the ℓ-fold to 1-step transformation and the global geometry persist beyond the primary experimental setups. revision: yes
Circularity Check
No significant circularity: derivation grounded in external Node2Vec connection and empirical observations
full rationale
The paper identifies geometric memory through direct empirical analysis of sequence model embeddings that encode non-co-occurring relations and simplify composition tasks. The explanation that this stems from a spectral bias is explicitly tied to an analysis of the connection with the independent Node2Vec algorithm, whose random-walk co-occurrence mechanism is external to the present work and does not rely on the paper's own fitted values or definitions. No step reduces the claimed geometry to a self-definition, a renamed prediction of the same data, or a load-bearing self-citation chain. The contrast with typical supervisory pressures is presented as an argument from the Node2Vec parallel rather than a tautological claim. The derivation therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The rise of geometric embeddings cannot be attributed to typical supervisory, architectural, or optimizational pressures.
invented entities (1)
-
geometric memory
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
the geometry stems from a spectral bias that—in contrast to prevailing theories—indeed arises naturally despite the lack of various pressures... the converged solution... columns of embedding matrix V span the graph’s Fiedler-like vectors
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
global information readily available i.e., f(u)[v] is proportional to multi-hop distance... low-rank factorization of adjacency matrix
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Geometric Factual Recall in Transformers
A single-layer transformer memorizes random subject-attribute bijections using logarithmic embedding dimension via linear superpositions in embeddings and ReLU-gated selection in the MLP, with zero-shot transfer to ne...
Reference graph
Works this paper leans on
-
[1]
On the non-universality of deep learning: quantifying the cost of symmetry
Emmanuel Abbe and Enric Boix-Adsera. On the non-universality of deep learning: quantifying the cost of symmetry. InAdvances in Neural Information Processing Systems, volume 35, pages 17188–17201. Curran Associates, Inc., 2022
work page 2022
-
[2]
Poly-time universality and limitations of deep learning
Emmanuel Abbe and Colin Sandon. Poly-time universality and limitations of deep learning. arXiv preprint arXiv:2001.02992, 2020
-
[3]
Emmanuel Abbe and Colin Sandon. On the universality of deep learning.Advances in Neural Information Processing Systems, 33:20061–20072, 2020
work page 2020
-
[4]
Emmanuel Abbe, Pritish Kamath, Eran Malach, Colin Sandon, and Nathan Srebro. On the power of differentiable learning versus pac and sq learning.Advances in Neural Information Processing Systems, 34:24340–24351, 2021
work page 2021
-
[5]
Emmanuel Abbe, Elisabetta Cornacchia, and Aryo Lotfi. Provable advantage of curriculum learning on parity targets with mixed inputs.Advances in Neural Information Processing Systems, 36:24291–24321, 2023
work page 2023
-
[6]
Learning high-degree parities: The crucial role of the initialization
Emmanuel Abbe, Elisabetta Cornacchia, Jan H ˛ azła, and Donald Kougang-Yombi. Learning high-degree parities: The crucial role of the initialization. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum? id=OuNIWgGGif
work page 2025
-
[7]
Carl Allen and Timothy M. Hospedales. Analogies explained: Towards understanding word embeddings. In Kamalika Chaudhuri and Ruslan Salakhutdinov, editors,Proceedings of the 36th International Conference on Machine Learning, ICML 2019, 9-15 June 2019, Long Beach, California, USA, volume 97 ofProceedings of Machine Learning Research, pages 223–231. PMLR, 20...
work page 2019
-
[8]
Carl Allen, Ivana Balazevic, and Timothy M. Hospedales. What the vec? towards probabilis- tically grounded embeddings. In Hanna M. Wallach, Hugo Larochelle, Alina Beygelzimer, Florence d’Alché-Buc, Emily B. Fox, and Roman Garnett, editors,Advances in Neural Infor- mation Processing Systems 32: Annual Conference on Neural Information Processing Systems 201...
work page 2019
-
[10]
Physics of language models: Part 3.3, knowledge capacity scaling laws
Zeyuan Allen-Zhu and Yuanzhi Li. Physics of language models: Part 3.3, knowledge capacity scaling laws. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net, 2025
work page 2025
-
[11]
Implicit regularization in deep matrix factorization
Sanjeev Arora, Nadav Cohen, Wei Hu, and Yuping Luo. Implicit regularization in deep matrix factorization. InAdvances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, December 8-14, 2019, Vancouver, BC, Canada, pages 7411–7422, 2019
work page 2019
-
[12]
Kanwal, Tegan Maharaj, Asja Fischer, Aaron Courville, Yoshua Bengio, and Simon Lacoste-Julien
Devansh Arpit, Stanisław Jastrz˛ ebski, Nicolas Ballas, David Krueger, Emmanuel Bengio, Maxinder S. Kanwal, Tegan Maharaj, Asja Fischer, Aaron Courville, Yoshua Bengio, and Simon Lacoste-Julien. A closer look at memorization in deep networks. In Doina Precup and Yee Whye Teh, editors,Proceedings of the 34th International Conference on Machine Learning, vo...
work page 2017
-
[13]
The pitfalls of next-token prediction
Gregor Bachmann and Vaishnavh Nagarajan. The pitfalls of next-token prediction. In Proceedings of the 41st International Conference on Machine Learning, volume 235 of Proceedings of Machine Learning Research, pages 2296–2318, 2024
work page 2024
-
[14]
Pierre Baldi and Kurt Hornik. Neural networks and principal component analysis: Learning from examples without local minima.Neural Networks, 2(1):53–58, 1989. doi: 10.1016/ 0893-6080(89)90014-2. URLhttps://doi.org/10.1016/0893-6080(89)90014-2
-
[15]
Robert J. N. Baldock, Hartmut Maennel, and Behnam Neyshabur. Deep learning through the lens of example difficulty. In Marc’Aurelio Ranzato, Alina Beygelzimer, Yann N. Dauphin, 29 Percy Liang, and Jennifer Wortman Vaughan, editors,Advances in Neural Information Pro- cessing Systems 34: Annual Conference on Neural Information Processing Systems 2021, NeurIP...
work page 2021
-
[16]
Lessons from studying two-hop latent reasoning, 2025
Mikita Balesni, Tomek Korbak, and Owain Evans. Lessons from studying two-hop latent reasoning, 2025. URLhttps://arxiv.org/abs/2411.16353
- [17]
-
[18]
Lukas Berglund, Meg Tong, Maximilian Kaufmann, Mikita Balesni, Asa Cooper Stickland, Tomasz Korbak, and Owain Evans. The reversal curse: Llms trained on "a is b" fail to learn "b is a". InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024. URL https://openreview.net/ forum?id=...
work page 2024
-
[19]
Alberto Bietti and Julien Mairal. On the inductive bias of neural tangent kernels.Advances in Neural Information Processing Systems, 32, 2019
work page 2019
-
[20]
Birth of a transformer: A memory viewpoint
Alberto Bietti, Vivien Cabannes, Diane Bouchacourt, Hervé Jégou, and Léon Bottou. Birth of a transformer: A memory viewpoint. InAdvances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023, 2023
work page 2023
-
[21]
Hopping too late: Exploring the limitations of large language models on multi-hop queries
Eden Biran, Daniela Gottesman, Sohee Yang, Mor Geva, and Amir Globerson. Hopping too late: Exploring the limitations of large language models on multi-hop queries. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors,Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, EMNLP 2024, Miami, FL, USA, November 12-16,...
work page 2024
-
[22]
Boden.The Creative Mind - Myths and Mechanisms (2
Margaret A. Boden.The Creative Mind - Myths and Mechanisms (2. ed.). Routledge, 2003
work page 2003
-
[23]
Reflections after refereeing papers for nips
Leo Breiman. Reflections after refereeing papers for nips. InThe Mathematics of Generaliza- tion, pages 11–15. CRC Press, 2018
work page 2018
-
[24]
A mechanistic analysis of a transformer trained on a symbolic multi-step reasoning task
Jannik Brinkmann, Abhay Sheshadri, Victor Levoso, Paul Swoboda, and Christian Bartelt. A mechanistic analysis of a transformer trained on a symbolic multi-step reasoning task. In Findings of the Association for Computational Linguistics, ACL 2024, Bangkok, Thailand and virtual meeting, August 11-16, 2024, pages 4082–4102. Association for Computational Lin...
work page 2024
-
[25]
Mikhail S Burtsev, Yuri Kuratov, Anton Peganov, and Grigory V Sapunov. Memory transformer. arXiv preprint arXiv:2006.11527, 2020
-
[26]
Scaling laws for associative memories
Vivien Cabannes, Elvis Dohmatob, and Alberto Bietti. Scaling laws for associative memories. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024. URL https://openreview.net/forum? id=Tzh6xAJSll
work page 2024
-
[27]
Learning associative memories with gradient descent
Vivien Cabannes, Berfin Simsek, and Alberto Bietti. Learning associative memories with gradient descent. InForty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024. OpenReview.net, 2024. URLhttps://openreview.net/ forum?id=A9fLbXLRTK
work page 2024
-
[29]
Stephanie C. Y . Chan, Adam Santoro, Andrew K. Lampinen, Jane X. Wang, Aaditya K. Singh, Pierre H. Richemond, James L. McClelland, and Felix Hill. Data distributional properties drive emergent in-context learning in transformers. InAdvances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIP...
work page 2022
-
[30]
Chang, Zhuowen Tu, and Benjamin K
Tyler A. Chang, Zhuowen Tu, and Benjamin K. Bergen. The geometry of multilingual language model representations. In Yoav Goldberg, Zornitsa Kozareva, and Yue Zhang, editors, Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, 30 EMNLP 2022, Abu Dhabi, United Arab Emirates, December 7-11, 2022, pages 119–136. Association...
-
[31]
Probing BERT in hyperbolic spaces
Boli Chen, Yao Fu, Guangwei Xu, Pengjun Xie, Chuanqi Tan, Mosha Chen, and Liping Jing. Probing BERT in hyperbolic spaces. In9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. OpenReview.net, 2021
work page 2021
-
[32]
Theoretical limitations of multi-layer transformer
Lijie Chen, Binghui Peng, and Hongxun Wu. Theoretical limitations of multi-layer transformer. arXiv preprint arXiv:2412.02975, 2024
-
[33]
Understand- ing the interplay between parametric and contextual knowledge for large language models,
Sitao Cheng, Liangming Pan, Xunjian Yin, Xinyi Wang, and William Yang Wang. Understand- ing the interplay between parametric and contextual knowledge for large language models,
- [34]
-
[35]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[37]
A mathematical model for curriculum learning for parities
Elisabetta Cornacchia and Elchanan Mossel. A mathematical model for curriculum learning for parities. InProceedings of the 40th International Conference on Machine Learning, volume 202 ofProceedings of Machine Learning Research, pages 6402–6423. PMLR, 23–29 Jul 2023. URLhttps://proceedings.mlr.press/v202/cornacchia23a.html
work page 2023
-
[38]
Xinnan Dai, Qihao Wen, Yifei Shen, Hongzhi Wen, Dongsheng Li, Jiliang Tang, and Caihua Shan. Revisiting the graph reasoning ability of large language models: Case studies in translation, connectivity and shortest path, 2025. URL https://arxiv.org/abs/2408. 09529
work page 2025
-
[39]
Andrew Davison, S. Carlyle Morgan, and Owen G. Ward. Community detection guarantees using embeddings learned by node2vec. InAdvances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10 - 15, 2024, 2024
work page 2024
-
[40]
Nouha Dziri, Ximing Lu, Melanie Sclar, Xiang Lorraine Li, Liwei Jiang, Bill Yuchen Lin, Sean Welleck, Peter West, Chandra Bhagavatula, Ronan Le Bras, et al. Faith and fate: Limits of transformers on compositionality.Advances in Neural Information Processing Systems, 36, 2024
work page 2024
-
[41]
Nelson Elhage, Tristan Hume, Catherine Olsson, Nicholas Schiefer, Tom Henighan, Shauna Kravec, Zac Hatfield-Dodds, Robert Lasenby, Dawn Drain, Carol Chen, Roger Grosse, Sam McCandlish, Jared Kaplan, Dario Amodei, Martin Wattenberg, and Christopher Olah. Toy models of superposition, 2022. URLhttps://arxiv.org/abs/2209.10652
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[42]
Towards understanding linear word analogies
Kawin Ethayarajh, David Duvenaud, and Graeme Hirst. Towards understanding linear word analogies. InProceedings of the 57th Conference of the Association for Computational Linguistics, ACL 2019, Florence, Italy, July 28- August 2, 2019, Volume 1: Long Papers, pages 3253–3262. Association for Computational Linguistics, 2019
work page 2019
-
[43]
Does learning require memorization? a short tale about a long tail
Vitaly Feldman. Does learning require memorization? a short tale about a long tail. In Proceedings of the 52nd Annual ACM SIGACT Symposium on Theory of Computing, STOC 2020, Chicago, IL, USA, June 22-26, 2020, pages 954–959. ACM, 2020
work page 2020
-
[44]
Jiahai Feng, Stuart Russell, and Jacob Steinhardt. Extractive structures learned in pretraining enable generalization on finetuned facts.arXiv preprint arXiv:2412.04614, 2024
-
[45]
Ferry, Joshua Ching, and Takashi Kawai
Quentin RV . Ferry, Joshua Ching, and Takashi Kawai. Emergence and function of abstract representations in self-supervised transformers, 2023. URL https://arxiv.org/abs/ 2312.05361
-
[46]
On the creativity of large language models.CoRR, abs/2304.00008, 2023
Giorgio Franceschelli and Mirco Musolesi. On the creativity of large language models.CoRR, abs/2304.00008, 2023. 31
-
[47]
The mystery of the pathological path-star task for language models
Arvid Frydenlund. The mystery of the pathological path-star task for language models. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, EMNLP 2024, Miami, FL, USA, November 12-16, 2024, pages 12493–12516. Association for Computational Linguistics, 2024
work page 2024
-
[48]
Arvid Frydenlund. Language models, graph searching, and supervision adulteration: When more supervision is less and how to make more more. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vienna, Austria, ...
work page 2025
-
[49]
Relational reasoning and inductive bias in transformers and large language models
Jesse Geerts, Stephanie Chan, Claudia Clopath, and Kimberly Stachenfeld. Relational rea- soning and inductive bias in transformers trained on a transitive inference task, 2025. URL https://arxiv.org/abs/2506.04289
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[50]
Transformer feed-forward layers are key-value memories
Mor Geva, Roei Schuster, Jonathan Berant, and Omer Levy. Transformer feed-forward layers are key-value memories. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, EMNLP 2021, Virtual Event / Punta Cana, Dominican Republic, 7-11 November, 2021, pages 5484–5495. Association for Computational Linguistics, 2021
work page 2021
-
[51]
Dissecting recall of factual associations in auto-regressive language models
Mor Geva, Jasmijn Bastings, Katja Filippova, and Amir Globerson. Dissecting recall of factual associations in auto-regressive language models. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, EMNLP 2023, Singapore, December 6-10, 2023, pages 12216–12235. Association for Computational Linguistics, 2023
work page 2023
-
[52]
Understanding finetuning for factual knowledge extraction
Gaurav Rohit Ghosal, Tatsunori Hashimoto, and Aditi Raghunathan. Understanding finetuning for factual knowledge extraction. InForty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024. OpenReview.net, 2024. URL https:// openreview.net/forum?id=cPsn9AcOYh
work page 2024
-
[53]
Learning dense representations for entity retrieval
Daniel Gillick, Sayali Kulkarni, Larry Lansing, Alessandro Presta, Jason Baldridge, Eugene Ie, and Diego Garcia-Olano. Learning dense representations for entity retrieval. In Mohit Bansal and Aline Villavicencio, editors,Proceedings of the 23rd Conference on Computational Natural Language Learning, CoNLL 2019, Hong Kong, China, November 3-4, 2019, pages 5...
work page 2019
-
[54]
Alex Gittens, Dimitris Achlioptas, and Michael W. Mahoney. Skip-gram - zipf + uniform = vector additivity. In Regina Barzilay and Min-Yen Kan, editors,Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, ACL 2017, Vancouver, Canada, July 30 - August 4, Volume 1: Long Papers, pages 69–76. Association for Computational Li...
work page 2017
-
[55]
Tobias Glasmachers. Limits of end-to-end learning. InProceedings of The 9th Asian Con- ference on Machine Learning, ACML 2017, volume 77 ofProceedings of Machine Learning Research, pages 17–32. PMLR, 2017
work page 2017
-
[57]
Graph embedding techniques, applications, and performance: A survey.Knowl
Palash Goyal and Emilio Ferrara. Graph embedding techniques, applications, and performance: A survey.Knowl. Based Syst., 151:78–94, 2018. doi: 10.1016/J.KNOSYS.2018.03.022. URL https://doi.org/10.1016/j.knosys.2018.03.022
-
[58]
Think before you speak: Training language models with pause tokens
Sachin Goyal, Ziwei Ji, Ankit Singh Rawat, Aditya Krishna Menon, Sanjiv Kumar, and Vaishnavh Nagarajan. Think before you speak: Training language models with pause tokens. The Twelfth International Conference on Learning Representations, ICLR 2024, 2024
work page 2024
-
[59]
word2vec, node2vec, graph2vec, x2vec: Towards a theory of vector embeddings of structured data
Martin Grohe. word2vec, node2vec, graph2vec, x2vec: Towards a theory of vector embeddings of structured data. In Dan Suciu, Yufei Tao, and Zhewei Wei, editors,Proceedings of the 39th ACM SIGMOD-SIGACT-SIGAI Symposium on Principles of Database Systems, PODS 2020, Portland, OR, USA, June 14-19, 2020, pages 1–16. ACM, 2020
work page 2020
-
[60]
Yufei Huang, Shengding Hu, Xu Han, Zhiyuan Liu, and Maosong Sun
Andrey Gromov. Grokking modular arithmetic, 2023. URL https://arxiv.org/abs/ 2301.02679. 32
-
[61]
Mamba: Linear-time sequence modeling with selective state spaces, 2023
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces, 2023
work page 2023
-
[62]
Knowledge matters: Importance of prior information for optimization.J
Çaglar Gülçehre and Yoshua Bengio. Knowledge matters: Importance of prior information for optimization.J. Mach. Learn. Res., 17:8:1–8:32, 2016
work page 2016
-
[63]
Woodworth, Srinadh Bhojanapalli, Behnam Neyshabur, and Nati Srebro
Suriya Gunasekar, Blake E. Woodworth, Srinadh Bhojanapalli, Behnam Neyshabur, and Nati Srebro. Implicit regularization in matrix factorization. InAdvances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4-9, 2017, Long Beach, CA, USA, pages 6151–6159, 2017
work page 2017
-
[64]
Jiayan Guo, Lun Du, Hengyu Liu, Mengyu Zhou, Xinyi He, and Shi Han. Gpt4graph: Can large language models understand graph structured data ? an empirical evaluation and benchmarking, 2023. URLhttps://arxiv.org/abs/2305.15066
-
[65]
Mitigat- ing reversal curse in large language models via semantic-aware permutation training
Qingyan Guo, Rui Wang, Junliang Guo, Xu Tan, Jiang Bian, and Yujiu Yang. Mitigat- ing reversal curse in large language models via semantic-aware permutation training. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,Findings of the Association for Computational Linguistics, ACL 2024, Bangkok, Thailand and virtual meeting, August 11-16, 2024, page...
-
[66]
Language models represent space and time
Wes Gurnee and Max Tegmark. Language models represent space and time. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11,
work page 2024
-
[67]
URLhttps://openreview.net/forum?id=jE8xbmvFin
OpenReview.net, 2024. URLhttps://openreview.net/forum?id=jE8xbmvFin
work page 2024
-
[68]
HaoChen, Colin Wei, Adrien Gaidon, and Tengyu Ma
Jeff Z. HaoChen, Colin Wei, Adrien Gaidon, and Tengyu Ma. Provable guarantees for self- supervised deep learning with spectral contrastive loss. InAdvances in Neural Information Processing Systems 34: Annual Conference on Neural Information Processing Systems 2021, NeurIPS 2021, December 6-14, 2021, virtual, pages 5000–5011, 2021
work page 2021
-
[69]
Convergence guarantees for the deepwalk embedding on block models
Christopher Harker and Aditya Bhaskara. Convergence guarantees for the deepwalk embedding on block models. InForty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024. OpenReview.net, 2024. URLhttps://openreview.net/ forum?id=xwxUbBHC1q
work page 2024
-
[70]
Lost in the Middle: How Language Models Use Long Contexts
Tatsunori B. Hashimoto, David Alvarez-Melis, and Tommi S. Jaakkola. Word embeddings as metric recovery in semantic spaces.Trans. Assoc. Comput. Linguistics, 4:273–286, 2016. doi: 10.1162/TACL\_A\_00098. URLhttps://doi.org/10.1162/tacl_a_00098
work page internal anchor Pith review doi:10.1162/tacl 2016
-
[71]
Benjamin Hoover, Yuchen Liang, Bao Pham, Rameswar Panda, Hendrik Strobelt, Duen Horng Chau, Mohammed Zaki, and Dmitry Krotov. Energy transformer. In A. Oh, T. Nau- mann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural Information Processing Systems, volume 36, pages 27532–27559. Curran Associates, Inc.,
-
[72]
URL https://proceedings.neurips.cc/paper_files/paper/2023/file/ 57a9b97477b67936298489e3c1417b0a-Paper-Conference.pdf
work page 2023
-
[73]
J J Hopfield. Neural networks and physical systems with emergent collective computational abilities.Proceedings of the National Academy of Sciences, 79(8):2554–2558, 1982. doi: 10.1073/pnas.79.8.2554. URL https://www.pnas.org/doi/abs/10.1073/pnas.79.8. 2554
-
[74]
Cheng-Yu Hsieh, Chun-Liang Li, Chih-Kuan Yeh, Hootan Nakhost, Yasuhisa Fujii, Alexander Ratner, Ranjay Krishna, Chen-Yu Lee, and Tomas Pfister. Distilling step-by-step! outperform- ing larger language models with less training data and smaller model sizes.arXiv preprint arXiv:2305.02301, 2023
work page internal anchor Pith review arXiv 2023
-
[75]
Edward S. Hu, Kwangjun Ahn, Qinghua Liu, Haoran Xu, Manan Tomar, Ada Langford, Dinesh Jayaraman, Alex Lamb, and John Langford. The belief state transformer. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net, 2025
work page 2025
-
[76]
Po-Sen Huang, Xiaodong He, Jianfeng Gao, Li Deng, Alex Acero, and Larry P. Heck. Learning deep structured semantic models for web search using clickthrough data. In Qi He, Arun Iyengar, Wolfgang Nejdl, Jian Pei, and Rajeev Rastogi, editors,22nd ACM International Conference on Information and Knowledge Management, CIKM’13, San Francisco, CA, USA, October 2...
work page 2013
-
[77]
Generalization or hallucination? understanding out-of-context reasoning in transformers
Yixiao Huang, Hanlin Zhu, Tianyu Guo, Jiantao Jiao, Somayeh Sojoudi, Michael I Jordan, Stuart Russell, and Song Mei. Generalization or hallucination? understanding out-of-context reasoning in transformers. InAdvances in Neural Information Processing Systems 39: Annual Conference on Neural Information Processing Systems 2025, NeurIPS 2025, 2025
work page 2025
-
[78]
Position: The platonic representation hypothesis
Minyoung Huh, Brian Cheung, Tongzhou Wang, and Phillip Isola. Position: The platonic representation hypothesis. InForty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024. OpenReview.net, 2024. URLhttps://openreview. net/forum?id=BH8TYy0r6u
work page 2024
-
[79]
The spectral underpinning of word2vec, 2020
Ariel Jaffe, Yuval Kluger, Ofir Lindenbaum, Jonathan Patsenker, Erez Peterfreund, and Stefan Steinerberger. The spectral underpinning of word2vec, 2020
work page 2020
-
[80]
Erik Jenner, Shreyas Kapur, Vasil Georgiev, Cameron Allen, Scott Emmons, and Stuart J. Russell. Evidence of learned look-ahead in a chess-playing neural network. InAdvances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10 - 15, 2024, 2024
work page 2024
-
[81]
Yibo Jiang, Goutham Rajendran, Pradeep Ravikumar, and Bryon Aragam. Do llms dream of elephants (when told not to)? latent concept association and associative memory in transform- ers. InAdvances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10 - 1...
work page 2024
-
[82]
On the origins of linear representations in large language models
Yibo Jiang, Goutham Rajendran, Pradeep Kumar Ravikumar, Bryon Aragam, and Victor Veitch. On the origins of linear representations in large language models. InForty-first International Conference on Machine Learning, ICML 2024, 2024
work page 2024
-
[83]
Tokio Kajitsuka and Issei Sato. Are transformers with one layer self-attention using low- rank weight matrices universal approximators? InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net,
work page 2024
-
[84]
URLhttps://openreview.net/forum?id=nJnky5K944
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.