MAGNIFIED: RL Fine-tuning of Multimodal Large Language Models for Motion Planning
Pith reviewed 2026-06-28 09:30 UTC · model grok-4.3
The pith
Reinforcement learning fine-tuning of multimodal language models produces driving plans with lower overlap and off-road rates than supervised fine-tuning alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
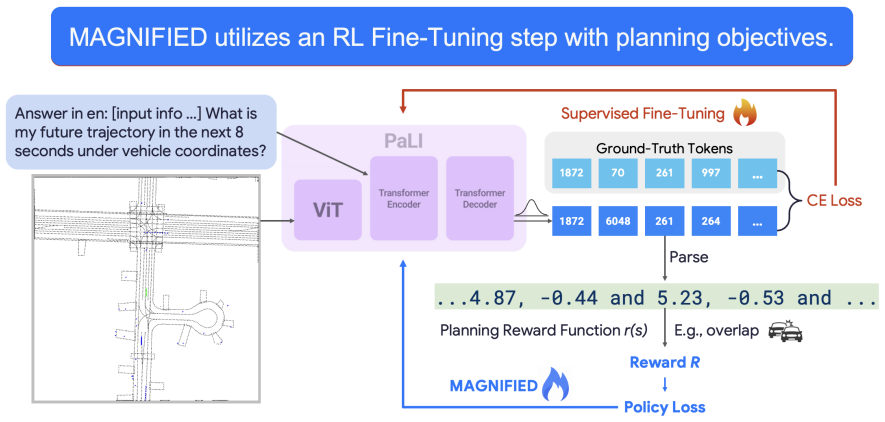
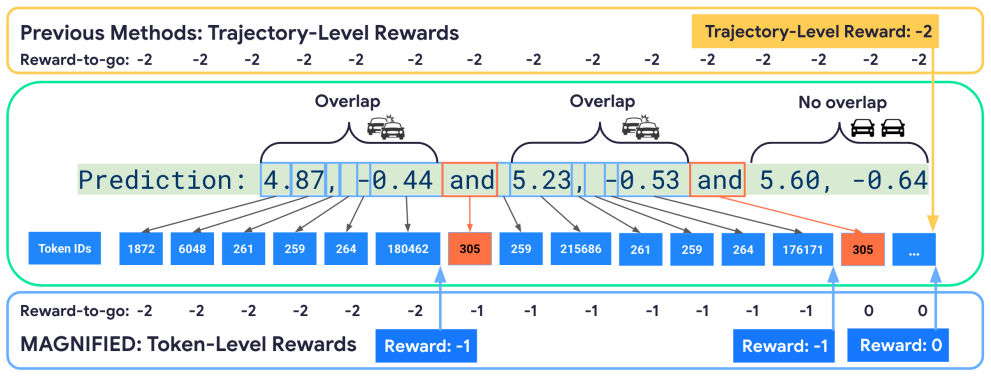
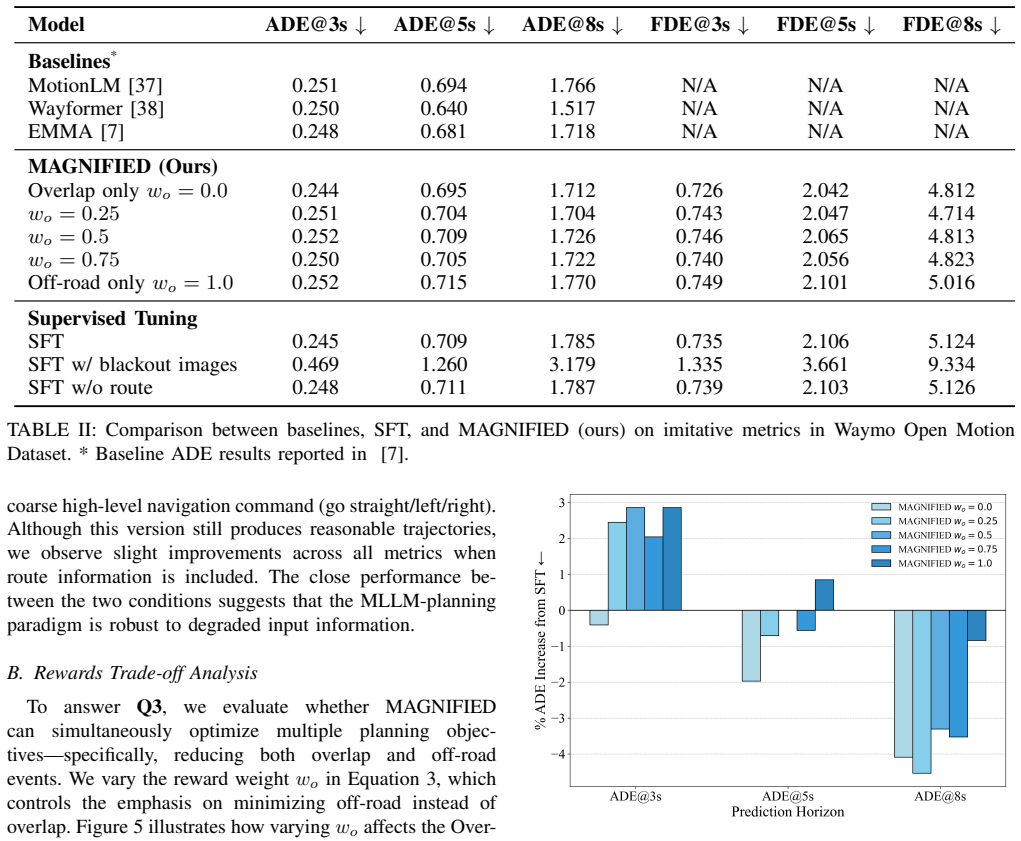
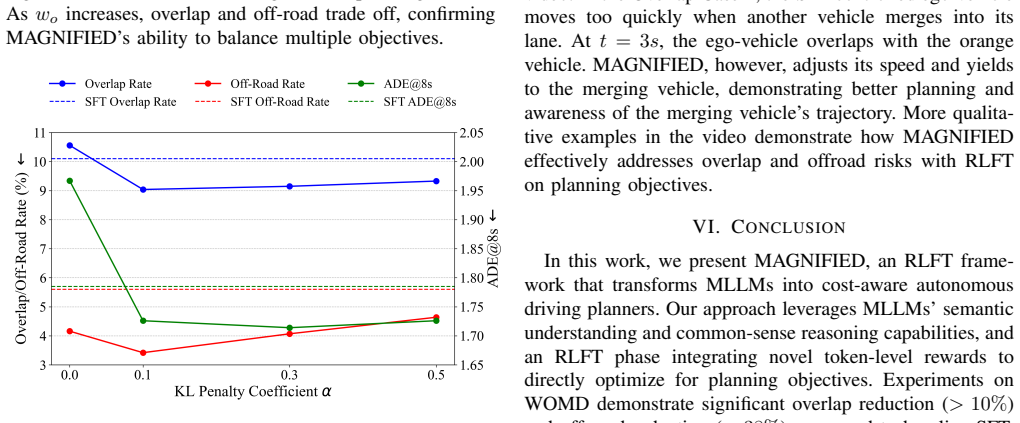
The authors establish that an initial supervised fine-tuning phase produces a baseline capable of emitting plan trajectories as text sequences of X-Y coordinates, after which reinforcement learning fine-tuning that maps those sequences to trajectories and optimizes token-level planning rewards yields over 10.5 percent lower overlap rate and 38.9 percent lower off-road rate on the Waymo dataset.
What carries the argument
MAGNIFIED, the reinforcement learning fine-tuning procedure that converts sequences of predicted tokens into vehicle trajectories and applies planning rewards to optimize the model beyond token-level imitation.
Load-bearing premise
That scoring predicted trajectories with planning metrics supplies a training signal that genuinely improves multi-step driving behavior rather than overfitting to the reward rules or dataset patterns.
What would settle it
Evaluating the RL-fine-tuned model on a held-out collection of driving scenarios and observing no reduction, or an increase, in overlap or off-road rates compared with the supervised fine-tuning baseline.
Figures

read the original abstract
Multi-modal Large Language Models (MLLMs) have demonstrated remarkable capabilities in semantic understanding and common sense reasoning, making them promising candidates for solving planning problems in autonomous driving. However, the next-token text prediction objectives traditionally used in pre-training and supervised fine-tuning (SFT) of MLLMs may fall short of fulfilling the planning objectives for autonomous vehicles. The next-token prediction objective merely encourages per-token imitation in text, often irrespective of multi-step consequences and the alignment with crucial planning considerations such as giving space to other road actors. To overcome these limitations, we propose a reinforcement learning fine-tuning (RLFT) approach, MAGNIFIED, that aligns the MLLM-based driving agent with planning objectives by learning from token-level rewards. By mapping a sequence of predicted tokens to corresponding vehicle trajectories and learning from planning rewards, MAGNIFIED optimizes for the true planning objectives rather than focusing solely on token prediction accuracy, enabling the model to refine its understanding of the planning task beyond simple imitation. We validate our approach on the Waymo Open Motion Dataset with a novel setup incorporating rasterized birds-eye views and tokenized trajectories as inputs and planning-oriented outputs. An initial SFT phase establishes a strong baseline in outputting plan trajectories as sequences of X-Y coordinates in text, while subsequent RL fine-tuning substantially enhances planning performance relative to the SFT baseline (demonstrating over a 10.5% reduction in overlap rate and a 38.9% reduction in off-road rate), underscoring the potential of RLFT on MLLMs to achieve vehicle planning that is better aligned with compliant, comfortable, and efficient driving.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MAGNIFIED, an RL fine-tuning approach for multimodal LLMs in autonomous driving motion planning. It argues that next-token prediction in SFT fails to capture multi-step planning objectives such as collision avoidance and road compliance. The method maps token sequences to trajectories, applies planning rewards (overlap, off-road), and performs RLFT after an initial SFT phase on rasterized BEV inputs and tokenized outputs. On the Waymo Open Motion Dataset, it reports >10.5% reduction in overlap rate and 38.9% reduction in off-road rate relative to the SFT baseline.
Significance. If the empirical gains prove robust, the work would indicate that token-level RL rewards derived from trajectory mapping can improve alignment of MLLM planners with safety and efficiency criteria beyond pure imitation, with potential implications for integrating language models into robotics planning pipelines.
major comments (3)
- [Abstract and §4] Abstract and §4 (Experiments): The headline performance deltas (10.5% overlap, 38.9% off-road) are stated without error bars, number of random seeds, statistical significance tests, or training curves, preventing assessment of whether the improvements are stable or sensitive to hyperparameter choices.
- [§3] §3 (Method): The description of how predicted token sequences are mapped to vehicle trajectories and how planning rewards are computed at the token level provides no explicit formulation or pseudocode; without this, it is impossible to verify whether the RL signal targets genuine multi-step consequences or merely fits the specific reward formulation on the Waymo dataset.
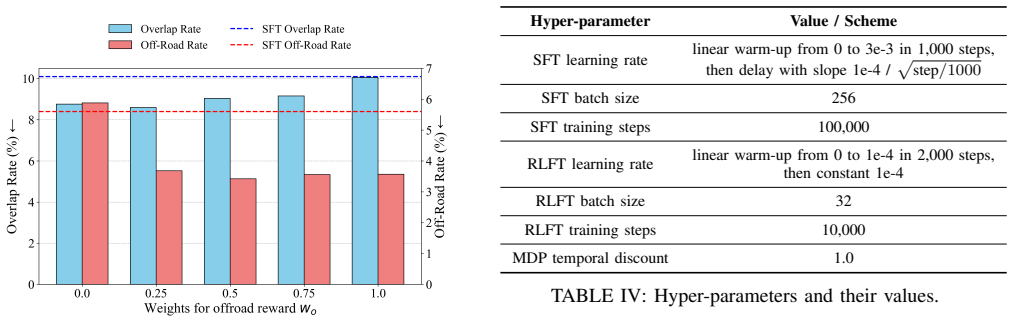
- [§4] §4 (Experiments): No ablation studies on individual reward components (overlap vs. off-road), alternative metrics, or out-of-distribution evaluation are reported, leaving open the possibility that gains arise from overfitting to dataset artifacts rather than improved planning behavior.
minor comments (1)
- [§3] The novel setup incorporating rasterized birds-eye views and tokenized trajectories is mentioned but lacks a figure or table illustrating the input-output tokenization scheme.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important aspects for improving the clarity and robustness of our work. We address each major comment point-by-point below and will revise the manuscript to incorporate the suggested additions.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): The headline performance deltas (10.5% overlap, 38.9% off-road) are stated without error bars, number of random seeds, statistical significance tests, or training curves, preventing assessment of whether the improvements are stable or sensitive to hyperparameter choices.
Authors: We agree that reporting variability is essential for assessing stability. The current manuscript reports point estimates from a single run. In the revision, we will rerun experiments with multiple random seeds (at least 3), include error bars (standard deviation), perform statistical significance tests (e.g., paired t-tests), and add training curves showing reward and metric progression during RLFT. revision: yes
-
Referee: [§3] §3 (Method): The description of how predicted token sequences are mapped to vehicle trajectories and how planning rewards are computed at the token level provides no explicit formulation or pseudocode; without this, it is impossible to verify whether the RL signal targets genuine multi-step consequences or merely fits the specific reward formulation on the Waymo dataset.
Authors: We acknowledge the need for greater precision in the method description. The manuscript currently describes the mapping and rewards at a high level. In the revision, we will add explicit mathematical formulations for the token-to-trajectory mapping function and the per-token reward computation (including how overlap and off-road penalties are assigned across the sequence), along with pseudocode for the full RLFT pipeline to demonstrate that the signal accounts for multi-step trajectory consequences. revision: yes
-
Referee: [§4] §4 (Experiments): No ablation studies on individual reward components (overlap vs. off-road), alternative metrics, or out-of-distribution evaluation are reported, leaving open the possibility that gains arise from overfitting to dataset artifacts rather than improved planning behavior.
Authors: We recognize that ablations would strengthen claims of genuine planning improvement. The current experiments focus on the combined reward. In the revision, we will add ablations isolating overlap versus off-road rewards, report additional metrics (e.g., comfort-related), and include out-of-distribution evaluation on held-out Waymo scenarios with different traffic densities or unseen map layouts to address potential overfitting concerns. revision: yes
Circularity Check
No circularity: empirical RL gains measured on held-out data
full rationale
The paper reports an empirical result: after SFT on tokenized trajectories from Waymo Open Motion, RL fine-tuning with planning rewards (overlap, off-road) yields measured reductions (10.5% overlap, 38.9% off-road) on held-out evaluation. No derivation chain, equations, or 'predictions' reduce to inputs by construction. No self-citations justify theorems or ansatzes. The performance delta is a standard held-out metric comparison, not a fitted quantity renamed as prediction. This matches the default case of a self-contained empirical paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Vision-language transformer for interpretable pathology visual question answering,
U. Naseem, M. Khushi, and J. Kim, “Vision-language transformer for interpretable pathology visual question answering,”IEEE Journal of Biomedical and Health Informatics, vol. 27, no. 4, pp. 1681–1690, 2022
2022
-
[2]
Vid2seq: Large-scale pretraining of a visual language model for dense video captioning,
A. Yang, A. Nagrani, P. H. Seo, A. Miech, J. Pont-Tuset, I. Laptev, J. Sivic, and C. Schmid, “Vid2seq: Large-scale pretraining of a visual language model for dense video captioning,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 10 714–10 726
2023
-
[3]
Vision– language model for visual question answering in medical imagery,
Y . Bazi, M. M. A. Rahhal, L. Bashmal, and M. Zuair, “Vision– language model for visual question answering in medical imagery,” Bioengineering, vol. 10, no. 3, p. 380, 2023
2023
-
[4]
Physically grounded vision-language models for robotic manipulation,
J. Gao, B. Sarkar, F. Xia, T. Xiao, J. Wu, B. Ichter, A. Majumdar, and D. Sadigh, “Physically grounded vision-language models for robotic manipulation,” in2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 12 462–12 469
2024
-
[5]
Vision and language navigation in the real world via online visual language mapping,
C. Xu, H. T. Nguyen, C. Amato, and L. L. Wong, “Vision and language navigation in the real world via online visual language mapping,”arXiv preprint arXiv:2310.10822, 2023
-
[6]
Vision language models in autonomous driving: A survey and outlook,
X. Zhou, M. Liu, E. Yurtsever, B. L. Zagar, W. Zimmer, H. Cao, and A. C. Knoll, “Vision language models in autonomous driving: A survey and outlook,”IEEE Transactions on Intelligent V ehicles, 2024
2024
-
[7]
EMMA: End-to-End Multimodal Model for Autonomous Driving
J.-J. Hwang, R. Xu, H. Lin, W.-C. Hung, J. Ji, K. Choi, D. Huang, T. He, P. Covington, B. Sapp,et al., “Emma: End-to-end multimodal model for autonomous driving,”arXiv preprint arXiv:2410.23262, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Stepcoder: Improve code gen- eration with reinforcement learning from compiler feedback,
S. Dou, Y . Liu, H. Jia, L. Xiong, E. Zhou, W. Shen, J. Shan, C. Huang, X. Wang, X. Fan,et al., “Stepcoder: Improve code gen- eration with reinforcement learning from compiler feedback,”arXiv preprint arXiv:2402.01391, 2024
-
[9]
Imitation is not enough: Robustifying imitation with reinforcement learning for challenging driving scenarios,
Y . Lu, J. Fu, G. Tucker, X. Pan, E. Bronstein, R. Roelofs, B. Sapp, B. White, A. Faust, S. Whiteson,et al., “Imitation is not enough: Robustifying imitation with reinforcement learning for challenging driving scenarios,” in2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2023, pp. 7553–7560
2023
-
[10]
Im- proving agent behaviors with rl fine-tuning for autonomous driving,
Z. Peng, W. Luo, Y . Lu, T. Shen, C. Gulino, A. Seff, and J. Fu, “Im- proving agent behaviors with rl fine-tuning for autonomous driving,” inEuropean Conference on Computer Vision. Springer, 2025, pp. 165–181
2025
-
[11]
Drivegpt4: Interpretable end-to-end autonomous driving via large language model,
Z. Xu, Y . Zhang, E. Xie, Z. Zhao, Y . Guo, K.-Y . K. Wong, Z. Li, and H. Zhao, “Drivegpt4: Interpretable end-to-end autonomous driving via large language model,”RA-L, 2024
2024
-
[12]
Lmdrive: Closed-loop end-to-end driving with large language models,
H. Shao, Y . Hu, L. Wang, G. Song, S. L. Waslander, Y . Liu, and H. Li, “Lmdrive: Closed-loop end-to-end driving with large language models,” inCVPR, 2024
2024
-
[13]
Drive anywhere: Generalizable end-to-end autonomous driving with multi-modal foundation models,
T.-H. Wang, A. Maalouf, W. Xiao, Y . Ban, A. Amini, G. Rosman, S. Karaman, and D. Rus, “Drive anywhere: Generalizable end-to-end autonomous driving with multi-modal foundation models,” inICRA, 2024
2024
-
[14]
S4-driver: Scalable self-supervised driving multimodal large language model with spatio-temporal visual representation,
Y . Xie, R. Xu, T. He, J.-J. Hwang, K. Luo, J. Ji, H. Lin, L. Chen, Y . Lu, Z. Leng,et al., “S4-driver: Scalable self-supervised driving multimodal large language model with spatio-temporal visual representation,” in Proceedings of the Computer Vision and Pattern Recognition Confer- ence, 2025, pp. 1622–1632
2025
-
[15]
S. Wang, Z. Yu, X. Jiang, S. Lan, M. Shi, N. Chang, J. Kautz, Y . Li, and J. M. Alvarez, “Omnidrive: A holistic llm-agent framework for autonomous driving with 3d perception, reasoning and planning,” arXiv preprint arXiv:2405.01533, 2024
-
[16]
Vlp: Vision language planning for autonomous driving,
C. Pan, B. Yaman, T. Nesti, A. Mallik, A. G. Allievi, S. Velipasalar, and L. Ren, “Vlp: Vision language planning for autonomous driving,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 14 760–14 769
2024
-
[17]
Drivevlm: The convergence of autonomous driving and large vision-language models,
X. Tian, J. Gu, B. Li, Y . Liu, C. Hu, Y . Wang, K. Zhan, P. Jia, X. Lang, and H. Zhao, “Drivevlm: The convergence of autonomous driving and large vision-language models,” inCoRL, 2024
2024
-
[18]
Drivecot: Integrating chain-of-thought reasoning with end-to-end driving,
T. Wang, E. Xie, R. Chu, Z. Li, and P. Luo, “Drivecot: Integrating chain-of-thought reasoning with end-to-end driving,”arXiv preprint arXiv:2403.16996, 2024
-
[19]
Look, remember and reason: Grounded reasoning in videos with language models,
A. Bhattacharyya, S. Panchal, M. Lee, R. Pourreza, P. Madan, and R. Memisevic, “Look, remember and reason: Grounded reasoning in videos with language models,” inICRA, 2023
2023
-
[20]
Toward fully autonomous driving: Ai, challenges, opportunities, and needs,
L. Ullrich, M. Buchholz, K. Dietmayer, and K. Graichen, “Toward fully autonomous driving: Ai, challenges, opportunities, and needs,” arXiv preprint arXiv:2601.22927, 2026
-
[21]
Deep reinforcement learning for autonomous driving: A survey,
B. R. Kiran, I. Sobh, V . Talpaert, P. Mannion, A. A. Al Sallab, S. Yo- gamani, and P. P ´erez, “Deep reinforcement learning for autonomous driving: A survey,”IEEE Transactions on Intelligent Transportation Systems, vol. 23, no. 6, pp. 4909–4926, 2021
2021
-
[22]
Efficient reinforcement learning for autonomous driving with parameterized skills and priors,
L. Wang, J. Liu, H. Shao, W. Wang, R. Chen, Y . Liu, and S. L. Waslan- der, “Efficient reinforcement learning for autonomous driving with parameterized skills and priors,”arXiv preprint arXiv:2305.04412, 2023
-
[23]
Efficient deep reinforcement learning with imitative expert priors for autonomous driving,
Z. Huang, J. Wu, and C. Lv, “Efficient deep reinforcement learning with imitative expert priors for autonomous driving,”IEEE Transac- tions on Neural Networks and Learning Systems, vol. 34, no. 10, pp. 7391–7403, 2022
2022
-
[24]
Fear-neuro-inspired reinforcement learning for safe au- tonomous driving,
X. He, J. Wu, Z. Huang, Z. Hu, J. Wang, A. Sangiovanni-Vincentelli, and C. Lv, “Fear-neuro-inspired reinforcement learning for safe au- tonomous driving,”IEEE transactions on pattern analysis and machine intelligence, 2023
2023
-
[25]
Learning to summarize with human feedback,
N. Stiennon, L. Ouyang, J. Wu, D. Ziegler, R. Lowe, C. V oss, A. Radford, D. Amodei, and P. F. Christiano, “Learning to summarize with human feedback,”Advances in Neural Information Processing Systems, vol. 33, pp. 3008–3021, 2020
2020
-
[26]
Aligning language models with human preferences via a bayesian approach,
J. Wang, H. Wang, S. Sun, and W. Li, “Aligning language models with human preferences via a bayesian approach,”Advances in Neural Information Processing Systems, vol. 36, 2024
2024
-
[27]
Fine-Tuning Language Models from Human Preferences
D. M. Ziegler, N. Stiennon, J. Wu, T. B. Brown, A. Radford, D. Amodei, P. Christiano, and G. Irving, “Fine-tuning language models from human preferences,”arXiv preprint arXiv:1909.08593, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[28]
Fine-tuning large vision-language models as decision-making agents via reinforcement learning,
S. Zhai, H. Bai, Z. Lin, J. Pan, P. Tong, Y . Zhou, A. Suhr, S. Xie, Y . LeCun, Y . Ma,et al., “Fine-tuning large vision-language models as decision-making agents via reinforcement learning,”Advances in neural information processing systems, vol. 37, pp. 110 935–110 971, 2024
2024
-
[29]
Rl-vlm-f: Reinforcement learning from vision language foundation model feedback,
Y . Wang, Z. Sun, J. Zhang, Z. Xian, E. Biyik, D. Held, and Z. Erickson, “Rl-vlm-f: Reinforcement learning from vision language foundation model feedback,”arXiv preprint arXiv:2402.03681, 2024
-
[30]
Simple statistical gradient-following algorithms for connectionist reinforcement learning,
R. J. Williams, “Simple statistical gradient-following algorithms for connectionist reinforcement learning,”Machine learning, vol. 8, pp. 229–256, 1992
1992
-
[31]
Back to Basics: Revisiting REINFORCE Style Optimization for Learning from Human Feedback in LLMs
A. Ahmadian, C. Cremer, M. Gall ´e, M. Fadaee, J. Kreutzer, O. Pietquin, A. ¨Ust¨un, and S. Hooker, “Back to basics: Revisiting reinforce style optimization for learning from human feedback in llms,”arXiv preprint arXiv:2402.14740, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
PaLI-X: On Scaling up a Multilingual Vision and Language Model
X. Chen, J. Djolonga, P. Padlewski, B. Mustafa, S. Changpinyo, J. Wu, C. R. Ruiz, S. Goodman, X. Wang, Y . Tay,et al., “Pali-x: On scaling up a multilingual vision and language model,”arXiv preprint arXiv:2305.18565, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
Pali- 3 vision language models: Smaller, faster, stronger,
X. Chen, X. Wang, L. Beyer, A. Kolesnikov, J. Wu, P. V oigtlaender, B. Mustafa, S. Goodman, I. Alabdulmohsin, P. Padlewski,et al., “Pali- 3 vision language models: Smaller, faster, stronger,”arXiv preprint arXiv:2310.09199, 2023
-
[34]
Sigmoid loss for language image pre-training,
X. Zhai, B. Mustafa, A. Kolesnikov, and L. Beyer, “Sigmoid loss for language image pre-training,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 11 975– 11 986
2023
-
[35]
Large scale interactive motion forecasting for autonomous driving: The waymo open motion dataset,
S. Ettinger, S. Cheng, B. Caine, C. Liu, H. Zhao, S. Pradhan, Y . Chai, B. Sapp, C. R. Qi, Y . Zhou,et al., “Large scale interactive motion forecasting for autonomous driving: The waymo open motion dataset,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 9710–9719
2021
-
[36]
Waymax: An accelerated, data- driven simulator for large-scale autonomous driving research,
C. Gulino, J. Fu, W. Luo, G. Tucker, E. Bronstein, Y . Lu, J. Harb, X. Pan, Y . Wang, X. Chen,et al., “Waymax: An accelerated, data- driven simulator for large-scale autonomous driving research,”Ad- vances in Neural Information Processing Systems, vol. 36, 2024
2024
-
[37]
Motionlm: Multi-agent motion forecasting as language modeling,
A. Seff, B. Cera, D. Chen, M. Ng, A. Zhou, N. Nayakanti, K. S. Refaat, R. Al-Rfou, and B. Sapp, “Motionlm: Multi-agent motion forecasting as language modeling,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 8579–8590
2023
-
[38]
Wayformer: Motion forecasting via simple & efficient atten- tion networks,
N. Nayakanti, R. Al-Rfou, A. Zhou, K. Goel, K. S. Refaat, and B. Sapp, “Wayformer: Motion forecasting via simple & efficient atten- tion networks,” in2023 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2023, pp. 2980–2987
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.