AnyMo: Geometry-Aware Setup-Agnostic Modeling of Human Motion in the Wild
Pith reviewed 2026-05-22 06:21 UTC · model grok-4.3
The pith
AnyMo learns setup-independent motion representations by simulating IMU signals from dense body placements and aligning them with language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
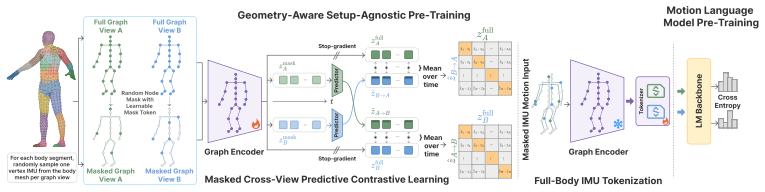
AnyMo is a geometry-aware framework that uses physics-grounded IMU simulation over dense body-surface placements to generate diverse and plausible synthetic signals, pre-trains a graph encoder from paired synthetic placement views and masked partial observations, tokenizes multi-position IMU into full-body motion tokens, and aligns these tokens with an LLM for motion-language understanding, yielding gains of 11.7%/11.6%/22.6% in Accuracy/F1/R@2 on HAR, 15.9% and 28.6% MRR lifts in zero-shot retrieval, and 18.8% BERT-F1 in zero-shot captioning across 14 unseen datasets.
What carries the argument
Physics-grounded IMU simulation over dense body-surface placements that generates diverse synthetic signals used to pre-train a graph encoder on paired placement views and masked observations before tokenization and LLM alignment.
If this is right
- Zero-shot activity recognition achieves 11.7% higher accuracy and 11.6% higher F1 across 14 previously unseen datasets.
- Zero-shot cross-modal retrieval reaches 15.9% higher MRR for IMU-to-text and 28.6% higher MRR for text-to-IMU.
- Zero-shot motion captioning from wearable IMU data improves by 18.8% in BERT-F1 score.
- The same pre-trained tokens support generalist motion-language tasks without dataset-specific fine-tuning.
Where Pith is reading between the lines
- The same dense-placement simulation strategy could be adapted to other wearable modalities such as pressure or temperature sensors.
- Combining the motion tokens with camera or audio streams might produce more robust real-time activity tracking systems.
- Long-term deployment on consumer devices could reveal whether the learned representations remain stable over weeks of continuous use.
Load-bearing premise
Physics-grounded IMU simulation over dense body-surface placements generates diverse and plausible synthetic signals that successfully transfer to real-world wearable data across varying body locations, mounting positions, and hardware.
What would settle it
Measuring whether performance gains vanish when the trained model is tested on IMU data from a new body location, mounting orientation, or sensor hardware whose signal statistics were never included in the simulation.
Figures







read the original abstract
As wearable and mobile devices become increasingly embedded in daily life, they offer a practical way to continuously sense human motion in the wild. But inertial signals are highly dependent on the sensing setup, including body location, mounting position, sensor orientation, device hardware, and sampling protocol. This setup dependence makes it difficult to learn motion representations that transfer across devices and datasets, and limits the broader use of wearable IMUs beyond closed-set recognition. We introduce AnyMo, a geometry-aware framework for setup-agnostic human motion modeling. AnyMo uses physics-grounded IMU simulation over dense body-surface placements to generate diverse and plausible synthetic signals, pre-trains a graph encoder from paired synthetic placement views and masked partial observations, tokenizes multi-position IMU into full-body motion tokens, and aligns these tokens with an LLM for motion-language understanding. We evaluate AnyMo on three complementary tasks: zero-shot activity recognition across 14 unseen downstream datasets, cross-modal retrieval, and wearable IMU motion captioning, where it improves average Accuracy/F1/R@2 by 11.7\%/11.6\%/22.6\% on HAR, increases zero-shot IMU-to-text and text-to-IMU retrieval MRR by 15.9\% and 28.6\%, respectively, and improves zero-shot captioning BERT-F1 by 18.8\%. These results support AnyMo as a generalist model for wearable motion understanding in the wild. Project page: https://baiyuchen.com/project/AnyMo.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AnyMo, a geometry-aware framework for setup-agnostic human motion modeling from wearable IMUs. It generates synthetic IMU signals via physics-grounded simulation over dense body-surface placements, pre-trains a graph encoder on paired synthetic views and masked observations, tokenizes multi-position IMU data into full-body motion tokens, and aligns these with an LLM for motion-language tasks. The work evaluates on zero-shot activity recognition across 14 unseen datasets, cross-modal retrieval, and IMU motion captioning, reporting average gains of 11.7%/11.6%/22.6% on HAR metrics, 15.9%/28.6% MRR improvements on retrieval, and 18.8% BERT-F1 on captioning.
Significance. If the simulation-to-real transfer holds and the gains are attributable to the proposed components rather than other factors, AnyMo could provide a practical path toward generalist models for wearable motion understanding that generalize across body locations, mounting positions, and hardware. The use of dense physics-based synthetic data for pre-training and the multi-task zero-shot evaluation on unseen datasets represent a strength in addressing setup dependence, which is a known barrier in the field.
major comments (2)
- [§3.1] §3.1 (Physics-Grounded IMU Simulation): The central claim that dense body-surface physics simulation produces diverse, plausible signals that successfully transfer to real-world wearable data across varying placements and hardware lacks direct quantitative fidelity validation. No metrics such as signal distribution distances, noise spectra comparisons, or domain discrepancy measures (e.g., MMD or Wasserstein distance) between simulated and real traces at matched positions are reported. This is load-bearing because the observed gains on the 14 unseen datasets could arise from the graph encoder, tokenization, or LLM alignment rather than the simulation itself.
- [§5] §5 (Evaluation and Baselines): The abstract and results claim substantial improvements (e.g., 11.7% Accuracy on HAR) but provide insufficient details on baseline implementations, statistical significance testing, dataset characteristics, or explicit controls for simulation-to-real gap. Without these, it is difficult to attribute gains specifically to the geometry-aware components versus other modeling choices.
minor comments (2)
- [§3.2] Notation for graph encoder inputs and tokenization could be clarified with an explicit diagram or equation set showing how partial observations map to full-body tokens.
- [Figure 4] Figure captions for qualitative results should include more detail on the specific body placements and hardware variations shown.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below, clarifying our approach and outlining planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3.1] §3.1 (Physics-Grounded IMU Simulation): The central claim that dense body-surface physics simulation produces diverse, plausible signals that successfully transfer to real-world wearable data across varying placements and hardware lacks direct quantitative fidelity validation. No metrics such as signal distribution distances, noise spectra comparisons, or domain discrepancy measures (e.g., MMD or Wasserstein distance) between simulated and real traces at matched positions are reported. This is load-bearing because the observed gains on the 14 unseen datasets could arise from the graph encoder, tokenization, or LLM alignment rather than the simulation itself.
Authors: We acknowledge that the manuscript does not include direct quantitative fidelity metrics such as MMD or Wasserstein distance between simulated and real IMU traces at matched positions. Our validation of the simulation relied primarily on the strong zero-shot generalization across 14 unseen real-world datasets, which we interpret as indirect evidence of successful transfer given the physics-grounded modeling. To directly address this concern and better isolate the simulation's contribution, we will add quantitative domain discrepancy analyses (including MMD and Wasserstein distances) as well as noise spectra comparisons for representative positions in the revised version. revision: yes
-
Referee: [§5] §5 (Evaluation and Baselines): The abstract and results claim substantial improvements (e.g., 11.7% Accuracy on HAR) but provide insufficient details on baseline implementations, statistical significance testing, dataset characteristics, or explicit controls for simulation-to-real gap. Without these, it is difficult to attribute gains specifically to the geometry-aware components versus other modeling choices.
Authors: We agree that additional experimental details would improve clarity and help attribute gains more precisely. In the revision, we will expand the evaluation section and supplementary material to provide: explicit descriptions of baseline implementations and adaptations, results of statistical significance testing (e.g., p-values across multiple runs), summary characteristics for all 14 datasets, and further controls/ablation studies that isolate the contribution of the geometry-aware simulation and pre-training from other modeling choices such as tokenization or LLM alignment. revision: yes
Circularity Check
No circularity: empirical framework with independent evaluation
full rationale
The paper presents AnyMo as a framework that generates synthetic IMU signals via physics-grounded simulation over dense placements, pre-trains a graph encoder on paired views and masked observations, tokenizes multi-position data into motion tokens, and aligns them with an LLM. All reported gains (e.g., +11.7% Accuracy on HAR across 14 unseen datasets, improved retrieval MRR and captioning BERT-F1) are stated as outcomes of empirical evaluation on downstream tasks rather than any mathematical derivation, fitted parameter renamed as prediction, or self-citation chain. No equations appear in the provided text, and the central claims rest on external dataset performance instead of reducing to inputs by construction. This is a standard self-contained empirical contribution with no load-bearing circular steps.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.