Training-Free Semantic Correction for Autoregressive Visual Models
Pith reviewed 2026-06-26 11:17 UTC · model grok-4.3
The pith
Gazer integrates MLLM feedback to diagnose and correct semantic errors during autoregressive visual model generation without training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
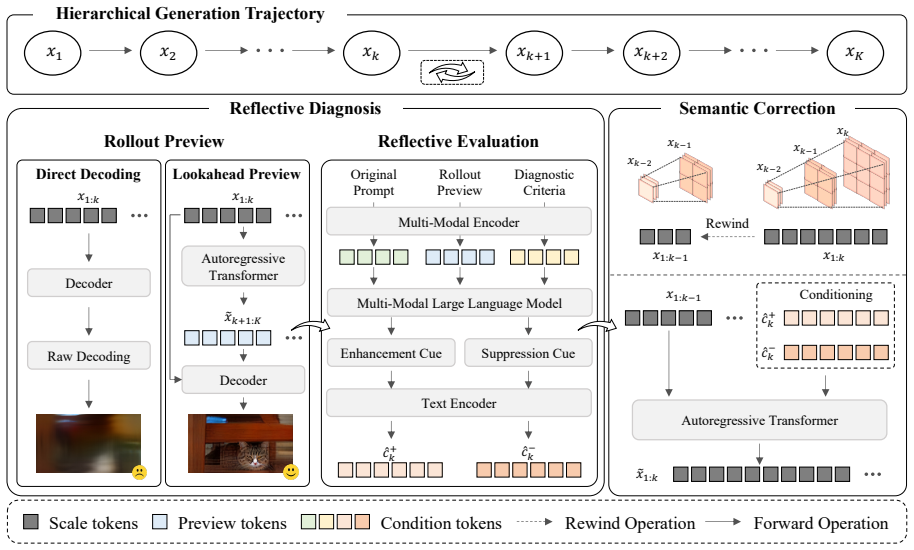
Gazer operates via two cooperating stages: the Reflective Diagnosis stage diagnoses semantic errors from intermediate states, while the Semantic Correction stage rewinds and rectifies the generation trajectory to realign with the target prompt.
What carries the argument
Reflective Diagnosis and Semantic Correction stages that insert multimodal LLM feedback into the AVM sampling loop to identify and fix semantic mistakes before final output.
If this is right
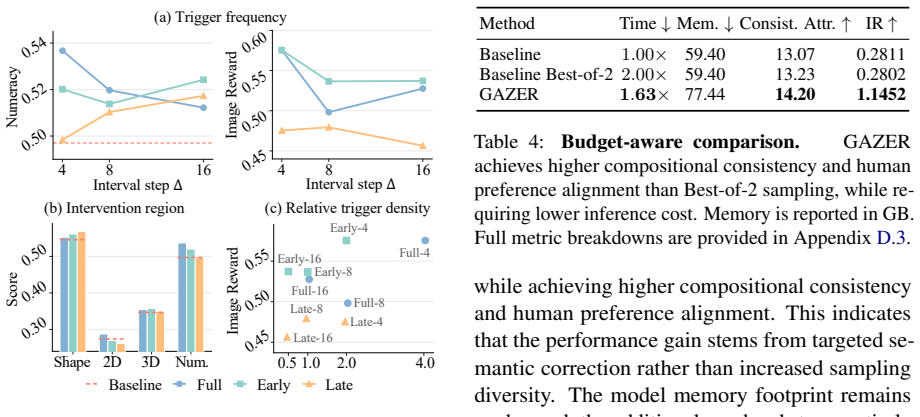
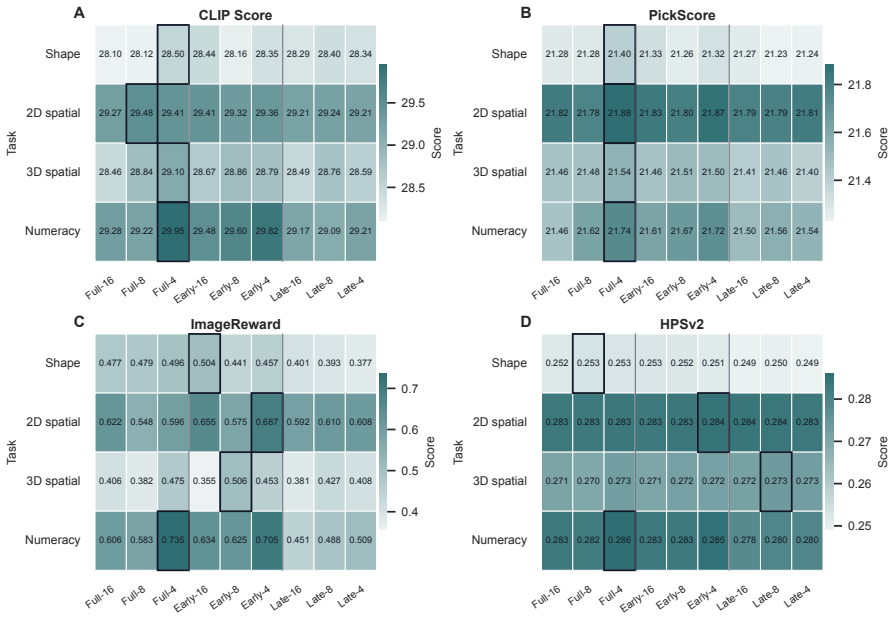
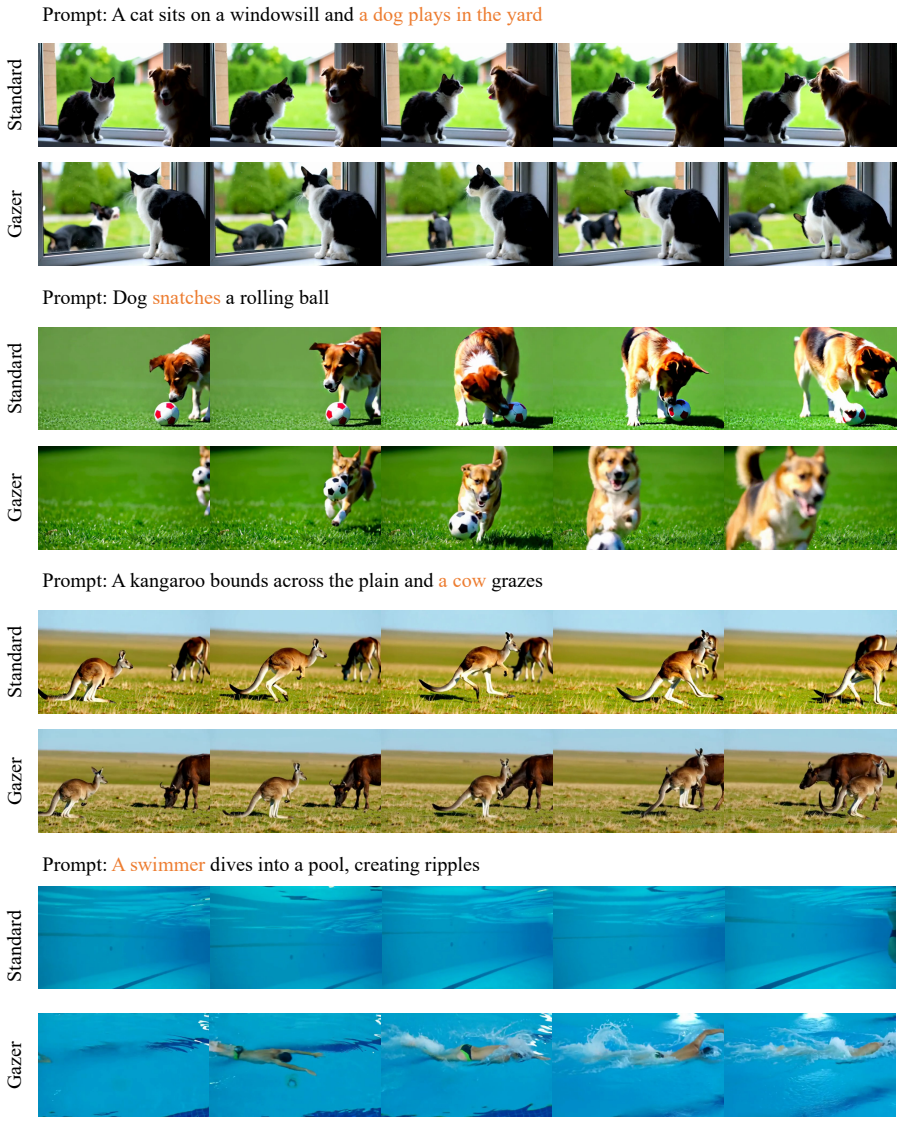
- Gazer improves semantic alignment and compositional accuracy across multiple AVMs without additional training.
- The approach applies to both compositional image and video synthesis benchmarks.
- Semantic errors can be addressed during generation rather than after the full output is produced.
Where Pith is reading between the lines
- If the diagnosis step proves reliable on more models, the rewind mechanism could be adapted to other iterative generation processes that expose intermediate states.
- Efficiency gains might appear in applications where prompt adherence matters more than raw speed, provided the LLM calls do not dominate runtime.
Load-bearing premise
Multimodal large language models can accurately and reliably diagnose semantic errors from the intermediate generation states of autoregressive visual models without requiring additional training or fine-tuning.
What would settle it
A controlled test set where the multimodal LLM fails to detect or mislabels semantic errors in intermediate AVM states, producing final outputs with no measurable gain in prompt alignment over the unmodified baseline.
Figures







read the original abstract
Autoregressive visual models (AVMs) based on next-scale prediction have emerged as a prominent paradigm for image and video synthesis. However, decomposing the generation process into discrete scales with varying granularities in AVM makes semantic errors difficult to identify and correct, thereby undermining the quality of the final output. Prior efforts to enhance AVM can be categorized into training-based and training-free approaches. Although training-based efforts to enhance AVM generation quality come at substantial computational cost, existing training-free methods neglect intermediate generation states, leaving semantic errors undiagnosed and allowing them to accumulate into the final output. In this paper, we focus on training-free paradigms and propose Gazer, a framework that integrates multimodal large language model feedback into the AVM sampling loop for in-generation semantic correction. Concretely, Gazer operates via two cooperating stages: the Reflective Diagnosis stage diagnoses semantic errors from intermediate states, while the Semantic Correction stage rewinds and rectifies the generation trajectory to realign with the target prompt. Experiments on compositional image and video benchmarks demonstrate that Gazer improves semantic alignment and compositional accuracy across multiple AVMs without additional training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Gazer, a training-free framework that integrates off-the-shelf multimodal large language model (MLLM) feedback into the sampling loop of autoregressive visual models (AVMs) based on next-scale prediction. Gazer consists of two stages: Reflective Diagnosis, which identifies semantic errors from intermediate generation states, and Semantic Correction, which rewinds the generation trajectory and rectifies it to better align with the input prompt. The authors report that this approach improves semantic alignment and compositional accuracy on image and video benchmarks across multiple AVMs without any additional training.
Significance. If the MLLM-based diagnosis proves reliable on coarse intermediate states, Gazer would address a clear gap in existing training-free AVM methods by preventing error accumulation during multi-scale generation. The training-free property and applicability to both images and video are strengths; however, the significance hinges entirely on whether the untested diagnostic premise holds.
major comments (3)
- [Abstract and §3] The central claim depends on the Reflective Diagnosis stage (described in the abstract and §3) accurately identifying semantic errors from partial next-scale states using an off-the-shelf MLLM. No quantitative evaluation of diagnosis precision, recall, or agreement with human judgments is provided, nor is there an ablation that isolates diagnosis accuracy from the correction mechanism. This is load-bearing: if diagnosis fails, the rewind-and-correct stage has no reliable signal.
- [Experiments] Experiments section reports gains on compositional benchmarks but supplies no failure-case analysis, no measurement of how often the MLLM misdiagnoses intermediate states, and no comparison against a version that applies correction without diagnosis. These omissions prevent assessment of whether the claimed improvements are attributable to the proposed two-stage process.
- [§3] The Semantic Correction stage (abstract and §3) assumes that rewinding to an earlier scale and re-generating with corrected guidance is feasible and effective, yet no implementation details, pseudocode, or analysis of the computational overhead or success rate of rewinding are given. This detail is necessary to evaluate reproducibility and practicality.
minor comments (2)
- [§3] Notation for the intermediate states and the rewind operation should be formalized with equations or a clear algorithm box to improve clarity.
- [Abstract] The abstract states improvements 'across multiple AVMs' but does not list the specific models or benchmarks in the provided text; adding these would strengthen the summary.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments correctly identify that the paper's central claims would be strengthened by direct evidence on the Reflective Diagnosis stage and additional implementation details. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract and §3] The central claim depends on the Reflective Diagnosis stage (described in the abstract and §3) accurately identifying semantic errors from partial next-scale states using an off-the-shelf MLLM. No quantitative evaluation of diagnosis precision, recall, or agreement with human judgments is provided, nor is there an ablation that isolates diagnosis accuracy from the correction mechanism. This is load-bearing: if diagnosis fails, the rewind-and-correct stage has no reliable signal.
Authors: We agree that quantitative evaluation of the Reflective Diagnosis stage is important for validating the load-bearing premise. The reported gains on compositional benchmarks provide indirect support, but do not isolate the diagnosis component. In the revision we will add (i) a small-scale human agreement study on diagnosis accuracy for intermediate states and (ii) an ablation comparing full Gazer against a correction-only baseline that bypasses diagnosis. revision: yes
-
Referee: [Experiments] Experiments section reports gains on compositional benchmarks but supplies no failure-case analysis, no measurement of how often the MLLM misdiagnoses intermediate states, and no comparison against a version that applies correction without diagnosis. These omissions prevent assessment of whether the claimed improvements are attributable to the proposed two-stage process.
Authors: We will incorporate the requested analyses in the revised Experiments section: failure-case breakdowns, quantitative measurement of MLLM misdiagnosis frequency on intermediate states, and the ablation against a correction-without-diagnosis baseline. These additions will clarify the contribution of the two-stage process. revision: yes
-
Referee: [§3] The Semantic Correction stage (abstract and §3) assumes that rewinding to an earlier scale and re-generating with corrected guidance is feasible and effective, yet no implementation details, pseudocode, or analysis of the computational overhead or success rate of rewinding are given. This detail is necessary to evaluate reproducibility and practicality.
Authors: We acknowledge the need for greater detail on the Semantic Correction stage. The revision will expand §3 with pseudocode for the rewind-and-rectify procedure, explicit implementation parameters, and reported measurements of computational overhead together with the empirical success rate of rewinding operations across the evaluated AVMs. revision: yes
Circularity Check
No circularity: framework description with no equations or self-referential derivations
full rationale
The paper introduces Gazer as a two-stage training-free framework relying on off-the-shelf MLLM feedback for diagnosis and correction in AVM sampling. No equations, parameters, or derivations are present in the provided text. The central claims rest on experimental improvements on compositional benchmarks rather than any mathematical reduction to inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems, and the method does not rename known results or smuggle ansatzes. The approach is self-contained as an empirical proposal whose validity hinges on external MLLM performance, not internal definitional loops.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2022 , eprint=
Scaling Autoregressive Models for Content-Rich Text-to-Image Generation , author=. 2022 , eprint=
2022
-
[2]
2024 , eprint=
Autoregressive Model Beats Diffusion: Llama for Scalable Image Generation , author=. 2024 , eprint=
2024
-
[3]
, booktitle=
Chang, Huiwen and Zhang, Han and Jiang, Lu and Liu, Ce and Freeman, William T. , booktitle=. MaskGIT: Masked Generative Image Transformer , year=
-
[4]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Li, Tianhong and Chang, Huiwen and Mishra, Shlok and Zhang, Han and Katabi, Dina and Krishnan, Dilip , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2023 , pages =
2023
-
[5]
Autoregressive Image Generation without Vector Quantization , url =
Li, Tianhong and Tian, Yonglong and Li, He and Deng, Mingyang and He, Kaiming , booktitle =. Autoregressive Image Generation without Vector Quantization , url =. doi:10.52202/079017-1797 , editor =
-
[6]
Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction , url =
Tian, Keyu and Jiang, Yi and Yuan, Zehuan and Peng, Bingyue and Wang, Liwei , booktitle =. Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction , url =. doi:10.52202/079017-2694 , editor =
-
[7]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Han, Jian and Liu, Jinlai and Jiang, Yi and Yan, Bin and Zhang, Yuqi and Yuan, Zehuan and Peng, Bingyue and Liu, Xiaobing , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2025 , pages =
2025
-
[8]
2025 , eprint=
InfinityStar: Unified Spacetime AutoRegressive Modeling for Visual Generation , author=. 2025 , eprint=
2025
-
[9]
2024 , eprint=
HART: Efficient Visual Generation with Hybrid Autoregressive Transformer , author=. 2024 , eprint=
2024
-
[10]
2025 , eprint=
STAR: Scale-wise Text-conditioned AutoRegressive image generation , author=. 2025 , eprint=
2025
-
[11]
Optimizing Prompts for Text-to-Image Generation , url =
Hao, Yaru and Chi, Zewen and Dong, Li and Wei, Furu , booktitle =. Optimizing Prompts for Text-to-Image Generation , url =
-
[12]
2024 , eprint=
Improving Text-to-Image Consistency via Automatic Prompt Optimization , author=. 2024 , eprint=
2024
-
[13]
2025 , eprint=
T2I-R1: Reinforcing Image Generation with Collaborative Semantic-level and Token-level CoT , author=. 2025 , eprint=
2025
-
[14]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Wallace, Bram and Dang, Meihua and Rafailov, Rafael and Zhou, Linqi and Lou, Aaron and Purushwalkam, Senthil and Ermon, Stefano and Xiong, Caiming and Joty, Shafiq and Naik, Nikhil , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2024 , pages =
2024
-
[15]
2024 , eprint=
Training Diffusion Models with Reinforcement Learning , author=. 2024 , eprint=
2024
-
[16]
ImageReward: Learning and Evaluating Human Preferences for Text-to-Image Generation , url =
Xu, Jiazheng and Liu, Xiao and Wu, Yuchen and Tong, Yuxuan and Li, Qinkai and Ding, Ming and Tang, Jie and Dong, Yuxiao , booktitle =. ImageReward: Learning and Evaluating Human Preferences for Text-to-Image Generation , url =
-
[17]
2023 , eprint=
Human Preference Score v2: A Solid Benchmark for Evaluating Human Preferences of Text-to-Image Synthesis , author=. 2023 , eprint=
2023
-
[18]
2025 , eprint=
Can We Generate Images with CoT? Let's Verify and Reinforce Image Generation Step by Step , author=. 2025 , eprint=
2025
-
[19]
ReNO: Enhancing One-step Text-to-Image Models through Reward-based Noise Optimization , url =
Eyring, Luca and Karthik, Shyamgopal and Roth, Karsten and Dosovitskiy, Alexey and Akata, Zeynep , booktitle =. ReNO: Enhancing One-step Text-to-Image Models through Reward-based Noise Optimization , url =. doi:10.52202/079017-3987 , editor =
-
[20]
Chefer, Hila and Alaluf, Yuval and Vinker, Yael and Wolf, Lior and Cohen-Or, Daniel , title =. ACM Trans. Graph. , month = jul, articleno =. 2023 , issue_date =. doi:10.1145/3592116 , abstract =
-
[21]
2023 , eprint=
Training-Free Structured Diffusion Guidance for Compositional Text-to-Image Synthesis , author=. 2023 , eprint=
2023
-
[22]
Linguistic Binding in Diffusion Models: Enhancing Attribute Correspondence through Attention Map Alignment , url =
Rassin, Royi and Hirsch, Eran and Glickman, Daniel and Ravfogel, Shauli and Goldberg, Yoav and Chechik, Gal , booktitle =. Linguistic Binding in Diffusion Models: Enhancing Attribute Correspondence through Attention Map Alignment , url =
-
[23]
Self-Refine: Iterative Refinement with Self-Feedback , url =
Madaan, Aman and Tandon, Niket and Gupta, Prakhar and Hallinan, Skyler and Gao, Luyu and Wiegreffe, Sarah and Alon, Uri and Dziri, Nouha and Prabhumoye, Shrimai and Yang, Yiming and Gupta, Shashank and Majumder, Bodhisattwa Prasad and Hermann, Katherine and Welleck, Sean and Yazdanbakhsh, Amir and Clark, Peter , booktitle =. Self-Refine: Iterative Refinem...
-
[24]
Reflexion: language agents with verbal reinforcement learning , url =
Shinn, Noah and Cassano, Federico and Gopinath, Ashwin and Narasimhan, Karthik and Yao, Shunyu , booktitle =. Reflexion: language agents with verbal reinforcement learning , url =
-
[25]
Pick-a-Pic: An Open Dataset of User Preferences for Text-to-Image Generation , url =
Kirstain, Yuval and Polyak, Adam and Singer, Uriel and Matiana, Shahbuland and Penna, Joe and Levy, Omer , booktitle =. Pick-a-Pic: An Open Dataset of User Preferences for Text-to-Image Generation , url =
-
[26]
Evaluating Text-to-Visual Generation with Image-to-Text Generation
Lin, Zhiqiu and Pathak, Deepak and Li, Baiqi and Li, Jiayao and Xia, Xide and Neubig, Graham and Zhang, Pengchuan and Ramanan, Deva. Evaluating Text-to-Visual Generation with Image-to-Text Generation. Computer Vision -- ECCV 2024. 2025
2024
-
[27]
2025 , eprint=
Multimodal LLM-Guided Semantic Correction in Text-to-Image Diffusion , author=. 2025 , eprint=
2025
-
[28]
2026 , eprint=
MILR: Improving Multimodal Image Generation via Test-Time Latent Reasoning , author=. 2026 , eprint=
2026
-
[29]
2022 , eprint=
Classifier-Free Diffusion Guidance , author=. 2022 , eprint=
2022
-
[30]
Proceedings of the 38th International Conference on Machine Learning , pages =
Zero-Shot Text-to-Image Generation , author =. Proceedings of the 38th International Conference on Machine Learning , pages =. 2021 , editor =
2021
-
[31]
Proceedings of the 37th International Conference on Machine Learning , pages =
Generative Pretraining From Pixels , author =. Proceedings of the 37th International Conference on Machine Learning , pages =. 2020 , editor =
2020
-
[32]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Lee, Doyup and Kim, Chiheon and Kim, Saehoon and Cho, Minsu and Han, Wook-Shin , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2022 , pages =
2022
-
[33]
arXiv preprint arXiv:2206.10789 , volume=
Scaling autoregressive models for content-rich text-to-image generation , author=. arXiv preprint arXiv:2206.10789 , volume=
-
[34]
arXiv preprint arXiv:2104.10157 , year=
Videogpt: Video generation using vq-vae and transformers , author=. arXiv preprint arXiv:2104.10157 , year=
-
[35]
2021 , eprint=
N\"UWA: Visual Synthesis Pre-training for Neural visUal World creAtion , author=. 2021 , eprint=
2021
-
[36]
2022 , eprint=
Phenaki: Variable Length Video Generation From Open Domain Textual Description , author=. 2022 , eprint=
2022
-
[37]
2024 , eprint=
VideoPoet: A Large Language Model for Zero-Shot Video Generation , author=. 2024 , eprint=
2024
-
[38]
2022 , eprint=
NUWA-Infinity: Autoregressive over Autoregressive Generation for Infinite Visual Synthesis , author=. 2022 , eprint=
2022
-
[39]
T2I-CompBench++: An Enhanced and Comprehensive Benchmark for Compositional Text-to-Image Generation , year=
Huang, Kaiyi and Duan, Chengqi and Sun, Kaiyue and Xie, Enze and Li, Zhenguo and Liu, Xihui , journal=. T2I-CompBench++: An Enhanced and Comprehensive Benchmark for Compositional Text-to-Image Generation , year=
-
[40]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Sun, Kaiyue and Huang, Kaiyi and Liu, Xian and Wu, Yue and Xu, Zihan and Li, Zhenguo and Liu, Xihui , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2025 , pages =
2025
-
[41]
arXiv preprint arXiv:2511.21631 , year=
Qwen3-vl technical report , author=. arXiv preprint arXiv:2511.21631 , year=
-
[42]
Proceedings of the 38th International Conference on Machine Learning , pages =
Learning Transferable Visual Models From Natural Language Supervision , author =. Proceedings of the 38th International Conference on Machine Learning , pages =. 2021 , editor =
2021
-
[43]
2026 , eprint=
Helios: Real Real-Time Long Video Generation Model , author=. 2026 , eprint=
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.