Elmes*: Automated Construction of Fine-Grained Evaluation Rubrics for Large Language Models in Long-Tail Educational Scenarios
Pith reviewed 2026-06-28 02:45 UTC · model grok-4.3
The pith
Elmes* automates fine-grained rubrics to reveal that LLM educational capability is multidimensional.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
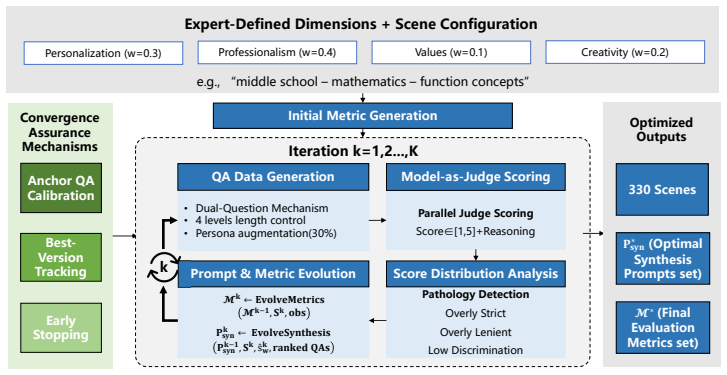
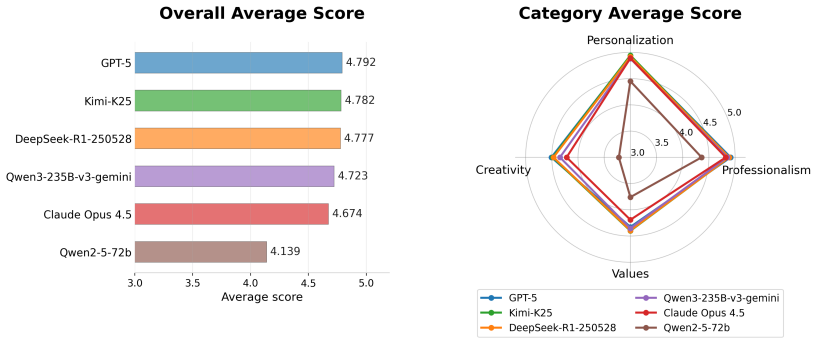
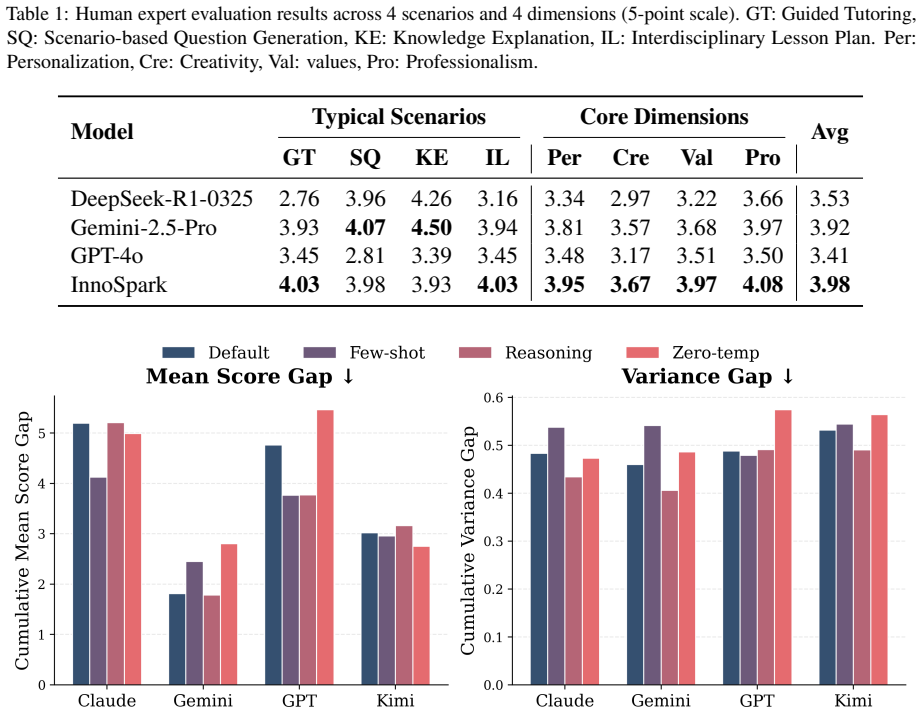
Using Elmes*, the authors construct Edu-330 covering 330 scenarios across subjects, grades, and task types with over 1,000 indicators. The framework shows educational capability is multidimensional: top-tier LLMs differ mainly in creativity and values integration, knowledge-strong models may fail at Socratic scaffolding, and the education-specialized InnoSpark achieves the best human-evaluated average score. LLM judges preserve human-comparable rankings with much lower scoring variance but exhibit judge-specific biases such as self-preference. Ablations confirm that expert-scored few-shot anchoring improves alignment while other techniques are model-dependent.
What carries the argument
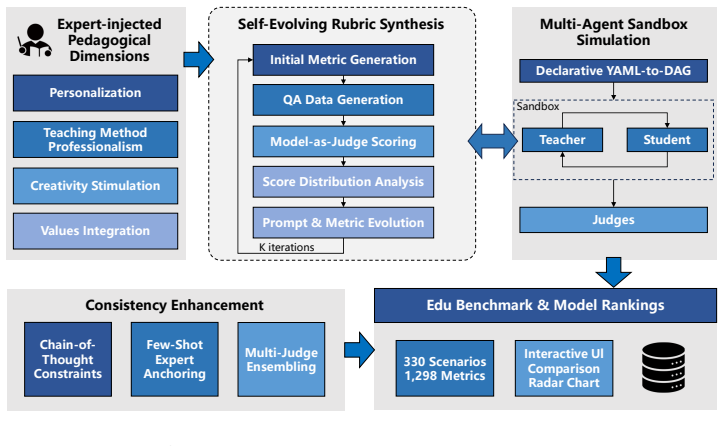
Elmes* end-to-end framework consisting of a declarative multi-agent engine for teacher-student-judge interactions and the SceneGen self-evolving module that co-optimizes evaluation criteria and test data.
If this is right
- Educational capability must be measured along multiple pedagogical dimensions instead of general correctness.
- Specialized education models can outperform general top-tier LLMs on teaching tasks.
- Automated rubric generation makes evaluation feasible for long-tail scenarios that manual design cannot reach.
- LLM judges deliver consistent rankings with lower variance than humans but carry model-specific biases.
- Expert-scored few-shot anchoring measurably improves human-LLM score alignment.
Where Pith is reading between the lines
- The separation of dimensions implies that training objectives for educational LLMs should target scaffolding or creativity independently rather than through generic instruction tuning.
- The co-optimization approach in SceneGen could be tested in adjacent domains such as medical consultation or legal advising where context-specific rubrics are also needed.
- Lower variance from LLM judges suggests they could serve as first-pass filters before human review in large-scale benchmark maintenance.
- Self-preference bias in judges points to the value of testing judge-model combinations that avoid using the same family as the evaluated model.
Load-bearing premise
The declarative multi-agent engine and SceneGen module can reliably co-optimize evaluation criteria and test data from expert-defined pedagogical dimensions without introducing systematic biases that invalidate the multidimensional capability claims or the human-LLM alignment results.
What would settle it
A replication in which independent human experts create rubrics for the same scenarios and models and obtain capability rankings or dimensional separations that differ from those produced by Elmes*.
Figures



read the original abstract
Evaluating large language models (LLMs) for education requires measuring how models teach, not only what they know. Existing benchmarks emphasize domain-general correctness or depend on manually designed rubrics that scale poorly to long-tail pedagogical scenarios. We introduce Elmes*, an end-to-end framework for constructing, refining, and applying fine-grained scenario-specific rubrics. Elmes* combines a declarative multi-agent engine for teacher--student--judge interactions with SceneGen, a self-evolving module that co-optimizes evaluation criteria and test data from expert-defined pedagogical dimensions. Using Elmes*, we build Edu-330, covering 330 scenarios across 11 subjects, 3 grade bands, and 10 task types, with over 1{,}000 second-level indicators. Experiments on Edu-330 and four expert-authored gold-standard scenarios show that educational capability is multidimensional: top-tier LLMs differ mainly in creativity and values integration, knowledge-strong models may fail at Socratic scaffolding, and the education-specialized InnoSpark achieves the best human-evaluated average score. LLM judges preserve human-comparable rankings with much lower scoring variance, but exhibit judge-specific biases such as self-preference. Ablations show that expert-scored few-shot anchoring improves human--LLM alignment, while reasoning enforcement and greedy decoding are model-dependent. Elmes* thus provides scalable diagnostic infrastructure for pedagogically grounded LLM evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Elmes*, an end-to-end framework combining a declarative multi-agent engine for teacher-student-judge interactions with the SceneGen self-evolving module to co-optimize evaluation criteria and test data from expert-defined pedagogical dimensions. It constructs the Edu-330 dataset covering 330 scenarios across 11 subjects, 3 grade bands, and 10 task types with over 1,000 second-level indicators, then reports experiments on Edu-330 plus four expert-authored gold-standard scenarios showing that educational capability is multidimensional (top-tier LLMs differ in creativity and values integration; knowledge-strong models may fail at Socratic scaffolding; education-specialized InnoSpark scores highest on human evaluation). LLM judges preserve human-comparable rankings with lower variance but show judge-specific biases such as self-preference; ablations indicate expert-scored few-shot anchoring improves alignment while reasoning enforcement and greedy decoding are model-dependent.
Significance. If the human-LLM alignment and multidimensional findings hold after proper validation, the work supplies scalable diagnostic infrastructure for pedagogically grounded LLM evaluation that moves beyond domain-general correctness benchmarks to long-tail scenarios; the automated rubric construction and identification of capability dimensions would be a substantive contribution to educational AI assessment.
major comments (1)
- [Abstract] Abstract: the abstract states experimental outcomes and ablations but provides no details on how rubrics were validated against human experts, how data exclusion or sampling was performed, or error bars on the reported rankings and bias observations, leaving the central multidimensional claim unsupported by visible evidence.
minor comments (1)
- [Abstract] Abstract: the notation '1{,}000' is a formatting artifact and should read '1,000'.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for greater clarity in the abstract regarding validation, sampling, and statistical details. We address this point below and will revise the abstract accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the abstract states experimental outcomes and ablations but provides no details on how rubrics were validated against human experts, how data exclusion or sampling was performed, or error bars on the reported rankings and bias observations, leaving the central multidimensional claim unsupported by visible evidence.
Authors: We agree the abstract is too terse on these points. The manuscript validates rubrics via four expert-authored gold-standard scenarios that receive direct human expert scoring for comparison against LLM outputs; sampling draws from the expert-defined pedagogical dimensions (11 subjects, 3 grade bands, 10 task types) without post-hoc exclusion. Variance is reported for LLM judges, and the multidimensional claim rests on dimension-specific differences observed in the gold-standard human evaluations. We will revise the abstract to explicitly reference the expert gold-standard validation, the dimension-guided sampling, and the reported variance, while directing readers to the full experimental sections for detailed statistics. This change will make the supporting evidence visible at the abstract level without altering the manuscript's core claims. revision: yes
Circularity Check
No significant circularity
full rationale
The paper presents Elmes* as an end-to-end framework combining a declarative multi-agent engine with a self-evolving SceneGen module to co-optimize rubrics and test data from expert-defined pedagogical dimensions. No equations, fitted parameters, or derivation steps are described in the abstract or context that would reduce reported performance differences, multidimensional claims, or human-LLM alignment results to internal definitions or self-citations. The central results rest on external human evaluations and expert-authored gold-standard scenarios, rendering the argument self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Learning and individual differences , volume=
ChatGPT for good? On opportunities and challenges of large language models for education , author=. Learning and individual differences , volume=. 2023 , publisher=
2023
-
[2]
British Journal of Educational Technology , volume=
Practical and ethical challenges of large language models in education: A systematic scoping review , author=. British Journal of Educational Technology , volume=. 2024 , publisher=
2024
-
[3]
IEEE Signal Processing Magazine , volume=
Large language models for education: A survey and outlook , author=. IEEE Signal Processing Magazine , volume=. 2026 , publisher=
2026
-
[4]
Advances in Neural Information Processing Systems , volume=
Mmlu-pro: A more robust and challenging multi-task language understanding benchmark , author=. Advances in Neural Information Processing Systems , volume=
-
[5]
Advances in neural information processing systems , volume=
C-eval: A multi-level multi-discipline chinese evaluation suite for foundation models , author=. Advances in neural information processing systems , volume=
-
[6]
Training Verifiers to Solve Math Word Problems
Training verifiers to solve math word problems , author=. arXiv preprint arXiv:2110.14168 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Measuring Massive Multitask Language Understanding
Measuring massive multitask language understanding , author=. arXiv preprint arXiv:2009.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[8]
Measuring Mathematical Problem Solving With the MATH Dataset
Measuring mathematical problem solving with the math dataset , author=. arXiv preprint arXiv:2103.03874 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Advances in neural information processing systems , volume=
Judging llm-as-a-judge with mt-bench and chatbot arena , author=. Advances in neural information processing systems , volume=
-
[10]
Chatbot Arena: An Open Platform for Evaluating LLMs by Human Preference
Chatbot arena: An open platform for evaluating llms by human preference , author=. arXiv preprint arXiv:2403.04132 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
International Conference on Learning Representations , volume=
Generative judge for evaluating alignment , author=. International Conference on Learning Representations , volume=
-
[12]
arXiv preprint arXiv:2308.02773 , year=
Educhat: A large-scale language model-based chatbot system for intelligent education , author=. arXiv preprint arXiv:2308.02773 , year=
-
[13]
arXiv preprint arXiv:2505.16160 , year=
Edubench: A comprehensive benchmarking dataset for evaluating large language models in diverse educational scenarios , author=. arXiv preprint arXiv:2505.16160 , year=
-
[14]
arXiv preprint arXiv:2508.10005 , year=
From Answers to Questions: EQGBench for Evaluating LLMs' Educational Question Generation , author=. arXiv preprint arXiv:2508.10005 , year=
-
[15]
arXiv preprint arXiv:2510.02663 , year=
TutorBench: A benchmark to assess tutoring capabilities of large language models , author=. arXiv preprint arXiv:2510.02663 , year=
-
[16]
Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
Mathdial: A dialogue tutoring dataset with rich pedagogical properties grounded in math reasoning problems , author=. Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
2023
-
[17]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Large language models are not fair evaluators , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[18]
arXiv preprint arXiv:2402.14865 , year=
Dynamic evaluation of large language models by meta probing agents , author=. arXiv preprint arXiv:2402.14865 , year=
-
[19]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
International Conference on Learning Representations , volume=
Prometheus: Inducing fine-grained evaluation capability in language models , author=. International Conference on Learning Representations , volume=
-
[21]
DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines
Dspy: Compiling declarative language model calls into self-improving pipelines , author=. arXiv preprint arXiv:2310.03714 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
1978 , publisher=
Mind in society: The development of higher psychological processes , author=. 1978 , publisher=
1978
-
[23]
Teachers college record , volume=
Technological pedagogical content knowledge: A framework for teacher knowledge , author=. Teachers college record , volume=. 2006 , publisher=
2006
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.