Reclaim Evaluation: A Lossy Memory Is Worse Than an Empty One
Pith reviewed 2026-06-25 21:04 UTC · model grok-4.3
The pith
A language model's lossy memory produces confident wrong answers where an empty memory would abstain.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Brittle memory is the consistent behavioral pattern in which keeping a wrong conclusion after dropping its source is worse than keeping nothing at all; across seven models the direction never reverses. Reclaim evaluation measures this by applying fixed-budget compression to a drifted interaction, then testing whether a correction recovers the known answer, with exact scoring against ground truth and no judge. Correctability depends on whether the answer-determining source survives compression rather than on model capability. A one-line source-first policy restores correctability where the source is compact and identifiable, and this replicates across three deployed memory systems and on real
What carries the argument
Reclaim evaluation: a fixed-budget compression followed by a correction test that scores recovery of a known answer against ground truth without a judge.
If this is right
- Chained memory loops turn one dropped-source error into an uncorrectable corruption that grows across downstream steps.
- Source-first compression holds error span to a bounded budget horizon while length-matched random compression does not.
- Past the point where the source no longer fits the budget, the source-first fix fails unless the note explicitly records that it is incomplete.
- The effect appears in real dialogue data and in three different deployed memory systems.
Where Pith is reading between the lines
- The same source-survival requirement would apply to any retrieval-augmented system that must later revise earlier steps.
- A completeness flag in memory notes would let downstream steps detect and handle truncated sources before they propagate.
- Exact-match scoring against a pre-known answer could be adapted to other tasks where the correct final state is defined in advance.
Load-bearing premise
The test treats the known answer as unambiguous ground truth and assumes the compression-plus-correction setup isolates source loss without other confounding effects from model capability or prompt wording.
What would settle it
A single model and task combination in which a lossy memory that retains the wrong conclusion but drops the source produces a higher rate of correctable answers than an empty memory under the same compression budget.
Figures
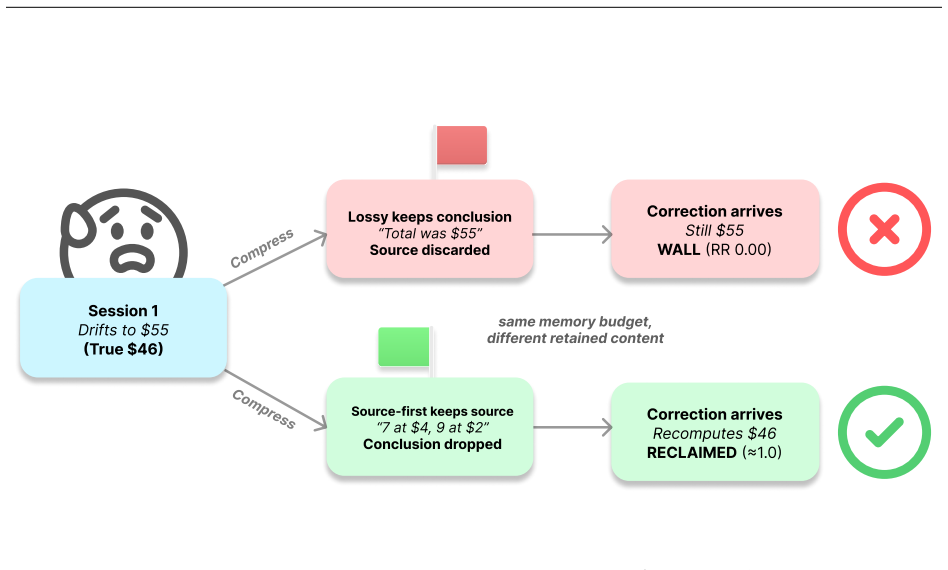
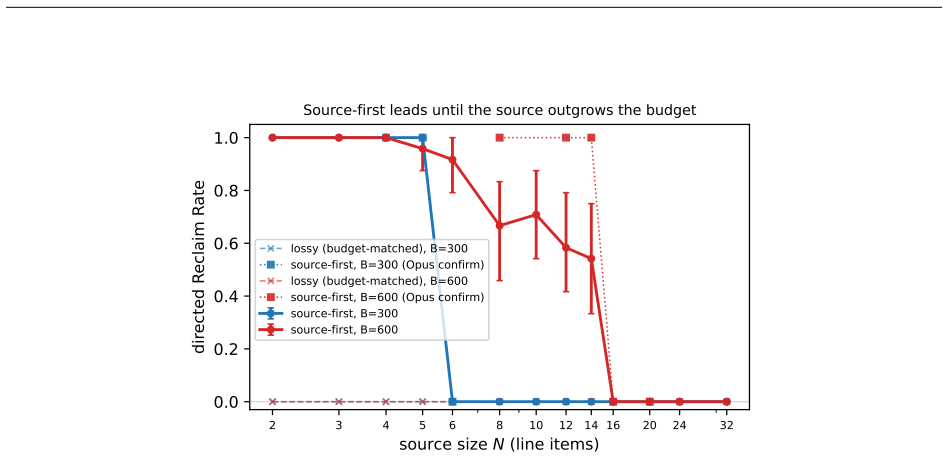
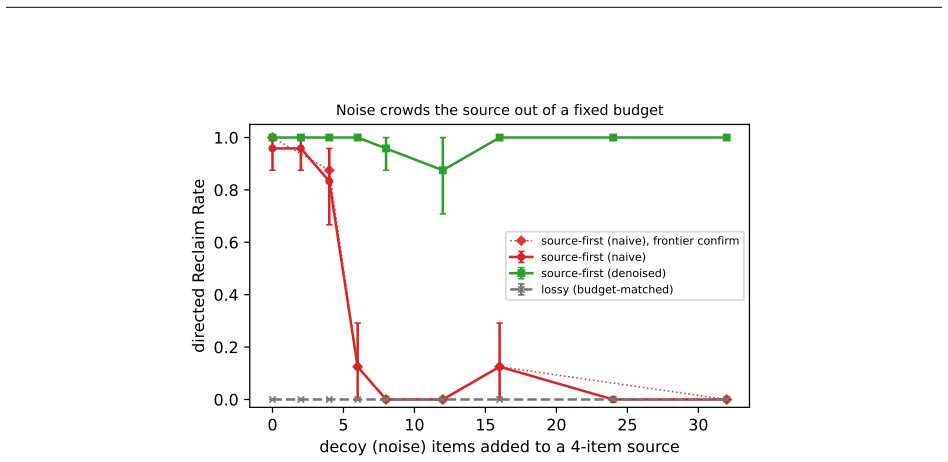
read the original abstract
A language model's memory can be worse than having no memory at all. Give a model a memory that kept a wrong conclusion but dropped the work behind it, and it emits that stale value as a confident answer; give the same model an empty memory and it abstains. Across seven models this direction never reverses, a clean kill condition that none breaks. We call this brittle memory: behavioral, not the near-immediate information bound beneath it; only its magnitude is disposition- and task-dependent, not its direction. We measure it with reclaim evaluation: compress a drifted interaction at a fixed budget, then test whether a correction recovers the known answer, scored against ground truth with no judge. Correctability is bottlenecked by whether the answer-determining source survives, not by capability. A one-line source-first policy (keep the recomputable source, drop the re-derivable conclusion) restores correctability at equal budget where that source is compact and identifiable; a length-matched control rules out added text as the cause. The hand-built oracle reaches 1.00; a one-prompt deployable version reclaims 0.49-0.88. The stake compounds: chained through a memory loop, a single dropped-source error corrupts a growing span of downstream steps and stays uncorrectable, while source-first holds to a bounded budget horizon. The wall and fix replicate across three deployed memory systems and on real dialogue (MultiWOZ), and past the budget where the source no longer fits, the fix fails silently unless the note records completeness. This is a controlled study of a mechanism, not a benchmark: judge-free exact scoring, matched-budget controls, and validators built to come out false. We release the harness, conditions, and validators.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that lossy memory in LLMs—retaining a drifted conclusion while dropping its source—produces confident incorrect answers, whereas empty memory leads to abstention. This 'brittle memory' effect holds in the same direction across seven models. Reclaim evaluation measures it via fixed-budget compression of drifted interactions followed by a correction test, scored by exact match to known ground truth with no judge. A source-first policy (keep recomputable source, drop re-derivable conclusion) restores correctability at matched budget; an oracle reaches 1.00 and a one-prompt version reaches 0.49-0.88. The effect and fix replicate on three deployed memory systems and MultiWOZ; a length-matched control rules out added text. The harness, conditions, and validators are released.
Significance. If the central claim holds, the work identifies a concrete mechanism by which partial memory can actively degrade performance below the no-memory baseline in memory-augmented systems, with a simple, deployable mitigation. The release of the evaluation harness, conditions, and validators is a clear strength, enabling direct reproduction and extension. The judge-free exact-match scoring and matched-budget controls further support falsifiability of the proposed mechanism.
major comments (2)
- [Abstract] Abstract: the headline claim that 'this direction never reverses' across seven models is load-bearing for the brittle-memory thesis, yet the design does not report a control that holds source presence fixed while varying only the correction prompt or model-family prompt handling; without this, uniformity could reflect harness artifacts rather than a general behavioral property.
- [Abstract] Abstract (reclaim evaluation description): the fixed-budget compression plus correction test is asserted to isolate whether the answer-determining source survives, but no quantitative check is described that the correction prompt's effectiveness is independent of model capability or disposition when source presence is controlled; this assumption underpins the 'correctability is bottlenecked by source survival' conclusion.
minor comments (2)
- [Abstract] Abstract: the seven models and three deployed memory systems are not named; listing them would improve reproducibility.
- [Abstract] Abstract: 'brittle memory' is defined behaviorally but could usefully contrast it with existing terms such as 'hallucination' or 'catastrophic forgetting' to clarify novelty.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments on the abstract claims. We address each point below and will revise the manuscript to incorporate additional controls and clarifications as indicated.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim that 'this direction never reverses' across seven models is load-bearing for the brittle-memory thesis, yet the design does not report a control that holds source presence fixed while varying only the correction prompt or model-family prompt handling; without this, uniformity could reflect harness artifacts rather than a general behavioral property.
Authors: We agree that an explicit control holding source presence fixed while varying only the correction prompt (or model-family prompt handling) would more rigorously exclude the possibility of harness artifacts. The current experiments vary models across families but apply a fixed correction prompt. While the consistency of direction across architecturally diverse models provides supporting evidence that the effect is not prompt- or harness-specific, we acknowledge the gap. In revision we will add a dedicated control experiment (and corresponding discussion) that fixes source presence and systematically varies prompt elements and model families. revision: yes
-
Referee: [Abstract] Abstract (reclaim evaluation description): the fixed-budget compression plus correction test is asserted to isolate whether the answer-determining source survives, but no quantitative check is described that the correction prompt's effectiveness is independent of model capability or disposition when source presence is controlled; this assumption underpins the 'correctability is bottlenecked by source survival' conclusion.
Authors: We agree that a direct quantitative check of correction-prompt effectiveness (with source presence controlled) would strengthen the isolation of source survival as the bottleneck. The manuscript reports that an oracle providing the source reaches 1.00 and that the source-first policy improves correctability at matched budget, but does not include the requested cross-model measurement with source fixed. In the revision we will add this quantitative check, reporting correction success rates across the seven models when source presence is assured. revision: yes
Circularity Check
No circularity: empirical measurements with released controls
full rationale
The paper reports direct experimental measurements of model behavior under fixed-budget compression and correction prompts, using exact-match scoring against a known ground-truth answer, length-matched controls, and a released harness. No equations, fitted parameters, or derivations are presented that reduce by construction to their own inputs. Claims such as 'direction never reverses across seven models' are stated as observed outcomes of the evaluation protocol rather than predictions derived from prior fits or self-citations. The design is self-contained against external benchmarks and does not rely on load-bearing self-citation chains or ansatzes smuggled via prior work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Great, Now Write an Article About That: The Crescendo Multi-Turn
Russinovich, Mark and Salem, Ahmed and Eldan, Ronen , booktitle=. Great, Now Write an Article About That: The Crescendo Multi-Turn
-
[3]
International Conference on Learning Representations (ICLR) , year=
Towards Understanding Sycophancy in Language Models , author=. International Conference on Learning Representations (ICLR) , year=
-
[4]
International Conference on Learning Representations (ICLR) , year=
Large Language Models Cannot Self-Correct Reasoning Yet , author=. International Conference on Learning Representations (ICLR) , year=
-
[5]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Self-Refine: Iterative Refinement with Self-Feedback , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[6]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Reflexion: Language Agents with Verbal Reinforcement Learning , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[7]
and Stoica, Ion and Gonzalez, Joseph E
Packer, Charles and Wooders, Sarah and Lin, Kevin and Fang, Vivian and Patil, Shishir G. and Stoica, Ion and Gonzalez, Joseph E. , journal=
-
[8]
Retrieval-Augmented Generation for Knowledge-Intensive
Lewis, Patrick and Perez, Ethan and Piktus, Aleksandra and others , booktitle=. Retrieval-Augmented Generation for Knowledge-Intensive
-
[9]
Locating and Editing Factual Associations in
Meng, Kevin and Bau, David and Andonian, Alex and Belinkov, Yonatan , booktitle=. Locating and Editing Factual Associations in
-
[10]
Transactions of the Association for Computational Linguistics , volume=
Lost in the Middle: How Language Models Use Long Contexts , author=. Transactions of the Association for Computational Linguistics , volume=
-
[11]
, booktitle=
Pennington, Jeffrey and Socher, Richard and Manning, Christopher D. , booktitle=
-
[12]
Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages=
Budzianowski, Pawe. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages=
2018
-
[13]
2024 , howpublished =
Introducing. 2024 , howpublished =
2024
-
[14]
2026 , howpublished =
2026
-
[15]
2024 , howpublished =
mem0: The Memory Layer for. 2024 , howpublished =
2024
-
[16]
2022 , howpublished =
2022
-
[17]
Xiao, Shitao and Liu, Zheng and Zhang, Peitian and Muennighoff, Niklas , journal =
-
[18]
Zeng, Aohan and Liu, Mingdao and Lu, Rui and Wang, Bowen and Liu, Xiao and Dong, Yuxiao and Tang, Jie , journal =
-
[19]
glaive-function-calling-v2 , year =
-
[20]
Claude Opus 4.8
Anthropic . Claude Opus 4.8. https://www.anthropic.com/news/claude-opus-4-8, 2026 a . Model announcement
2026
-
[21]
Claude Sonnet 4.6
Anthropic . Claude Sonnet 4.6. https://www.anthropic.com/news/claude-sonnet-4-6, 2026 b . Model announcement
2026
-
[22]
MultiWOZ -- a large-scale multi-domain W izard-of- O z dataset for task-oriented dialogue modelling
Pawe Budzianowski, Tsung-Hsien Wen, Bo-Hsiang Tseng, I \ n igo Casanueva, Stefan Ultes, Osman Ramadan, and Milica Ga s i \'c . MultiWOZ -- a large-scale multi-domain W izard-of- O z dataset for task-oriented dialogue modelling. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp.\ 5016--5026, 2018
2018
-
[23]
When context flips, safety breaks: Diagnosing brittle safety in aligned language models
Dasol Choi and Alex Kwon. When context flips, safety breaks: Diagnosing brittle safety in aligned language models. arXiv preprint arXiv:2605.27851, 2026
Pith/arXiv arXiv 2026
-
[24]
glaive-function-calling-v2
Glaive AI . glaive-function-calling-v2. https://huggingface.co/datasets/glaiveai/glaive-function-calling-v2, 2023. Dataset
2023
-
[25]
Large language models cannot self-correct reasoning yet
Jie Huang, Xinyun Chen, Swaroop Mishra, Huaixiu Steven Zheng, Adams Wei Yu, Xinying Song, and Denny Zhou. Large language models cannot self-correct reasoning yet. In International Conference on Learning Representations (ICLR), 2024
2024
-
[26]
No robots
Hugging Face H4 . No robots. https://huggingface.co/datasets/HuggingFaceH4/no_robots, 2023. Dataset
2023
-
[27]
LangChain
LangChain . LangChain . https://github.com/langchain-ai/langchain, 2022. Software
2022
-
[28]
Retrieval-augmented generation for knowledge-intensive NLP tasks
Patrick Lewis, Ethan Perez, Aleksandra Piktus, et al. Retrieval-augmented generation for knowledge-intensive NLP tasks. In Advances in Neural Information Processing Systems (NeurIPS), 2020
2020
-
[29]
Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang
Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts. Transactions of the Association for Computational Linguistics, 12: 0 157--173, 2024
2024
-
[30]
Self-refine: Iterative refinement with self-feedback
Aman Madaan, Niket Tandon, Prakhar Gupta, et al. Self-refine: Iterative refinement with self-feedback. In Advances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[31]
mem0: The memory layer for AI agents
Mem0 AI . mem0: The memory layer for AI agents. https://github.com/mem0ai/mem0, 2024. Software
2024
-
[32]
Locating and editing factual associations in GPT
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. Locating and editing factual associations in GPT . In Advances in Neural Information Processing Systems (NeurIPS), 2022
2022
-
[33]
Introducing Llama 3.1
Meta AI . Introducing Llama 3.1. https://ai.meta.com/blog/meta-llama-3-1/, 2024. Model announcement
2024
-
[34]
Patil, Ion Stoica, and Joseph E
Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G. Patil, Ion Stoica, and Joseph E. Gonzalez. MemGPT : Towards LLMs as operating systems. arXiv preprint arXiv:2310.08560, 2023
Pith/arXiv arXiv 2023
-
[35]
Great, now write an article about that: The crescendo multi-turn LLM jailbreak attack
Mark Russinovich, Ahmed Salem, and Ronen Eldan. Great, now write an article about that: The crescendo multi-turn LLM jailbreak attack. In 34th USENIX Security Symposium, 2025
2025
-
[36]
Towards understanding sycophancy in language models
Mrinank Sharma, Meg Tong, Tomasz Korbak, David Duvenaud, et al. Towards understanding sycophancy in language models. In International Conference on Learning Representations (ICLR), 2024
2024
-
[37]
Reflexion: Language agents with verbal reinforcement learning
Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning. In Advances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[38]
Grok 4.3
xAI . Grok 4.3. https://docs.x.ai/developers/models/grok-4.3, 2026. Model card
2026
-
[39]
C-Pack : Packed resources for general C hinese embeddings
Shitao Xiao, Zheng Liu, Peitian Zhang, and Niklas Muennighoff. C-Pack : Packed resources for general C hinese embeddings. arXiv preprint arXiv:2309.07597, 2023
Pith/arXiv arXiv 2023
-
[40]
AgentTuning : Enabling generalized agent abilities for LLMs
Aohan Zeng, Mingdao Liu, Rui Lu, Bowen Wang, Xiao Liu, Yuxiao Dong, and Jie Tang. AgentTuning : Enabling generalized agent abilities for LLMs . arXiv preprint arXiv:2310.12823, 2023
arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.