Data Selection Through Iterative Self-Filtering for Vision-Language Settings
Pith reviewed 2026-06-26 09:20 UTC · model grok-4.3
The pith
A vision-language model can iteratively filter its own noisy training data to raise downstream performance without extra data or pre-trained models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
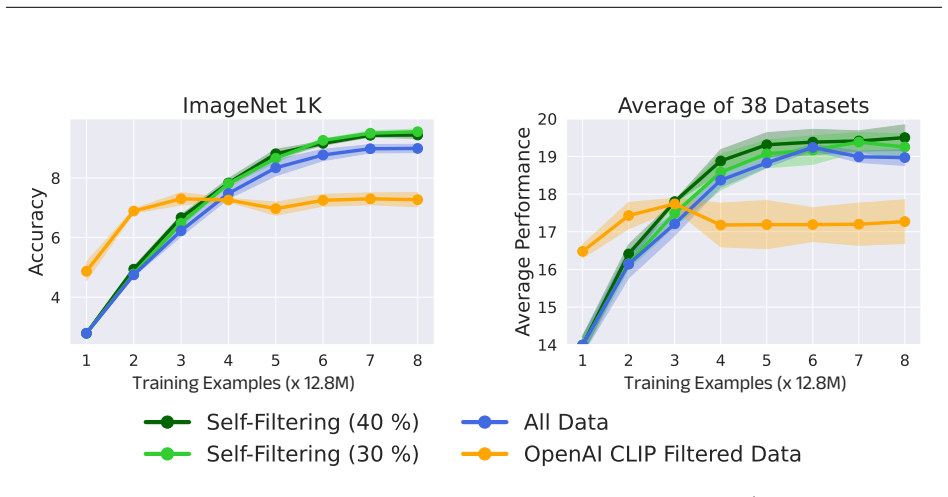
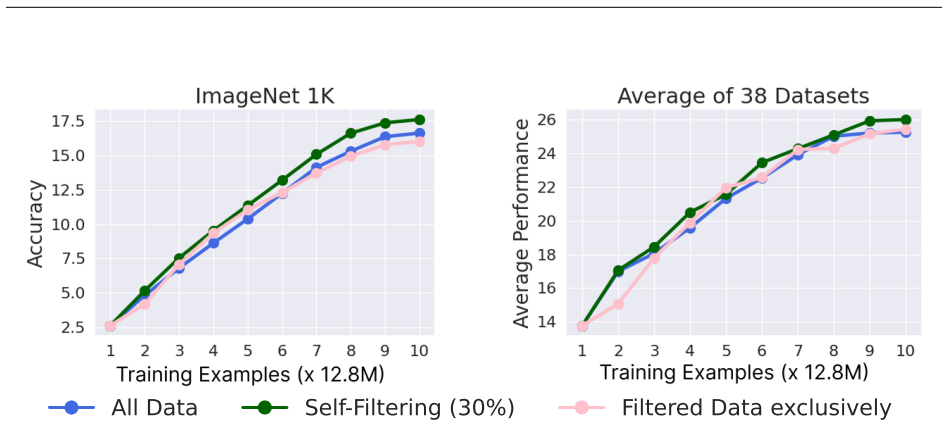
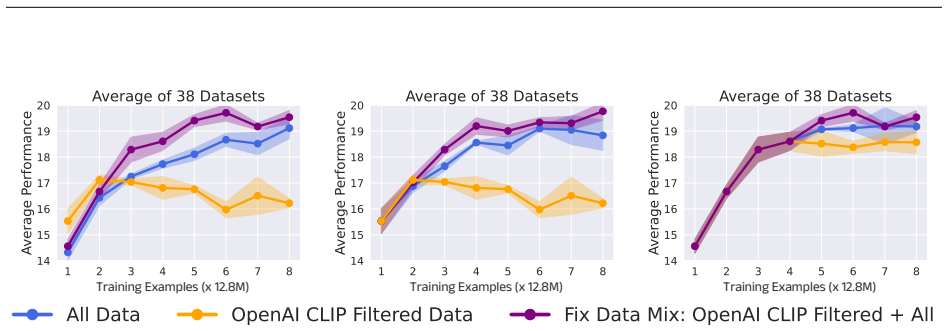
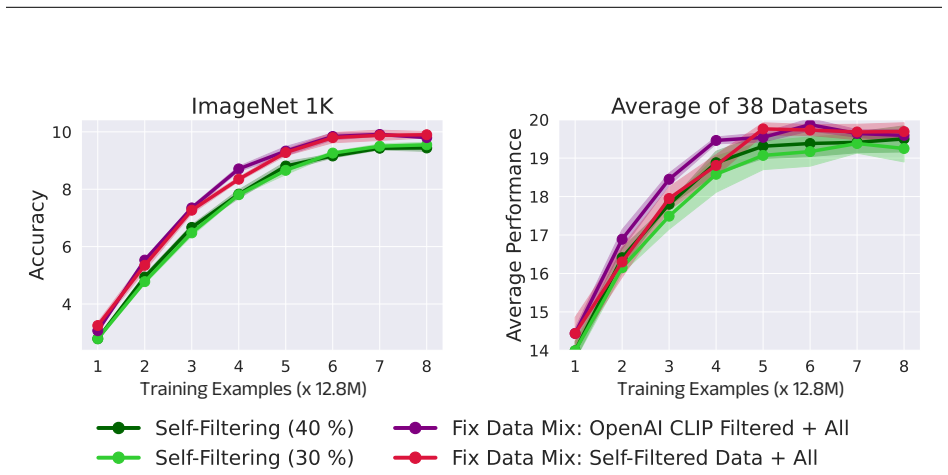
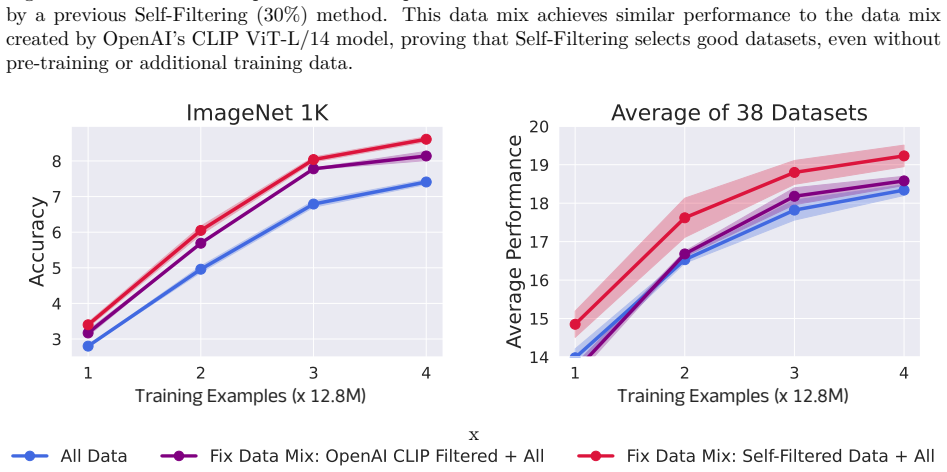
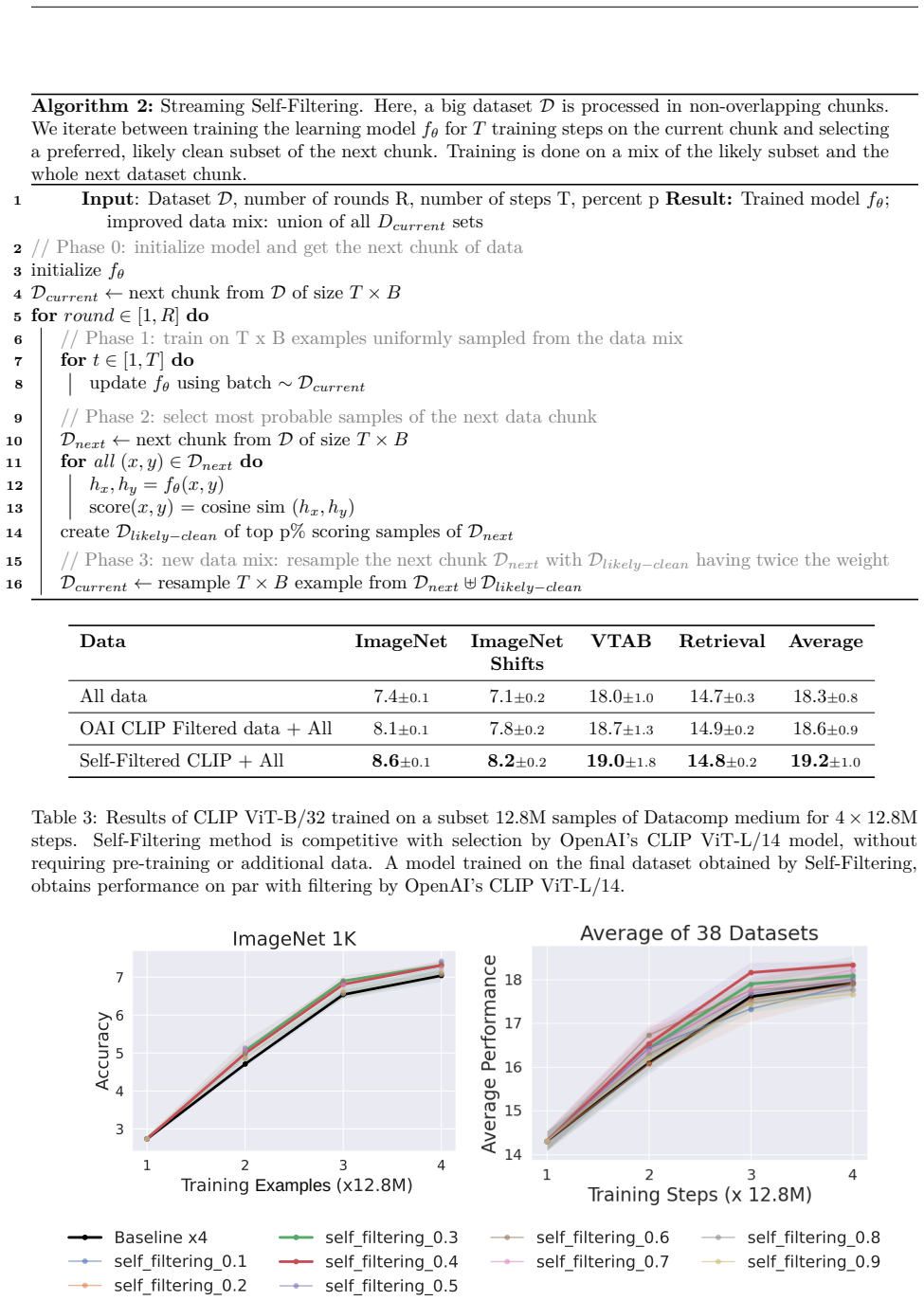
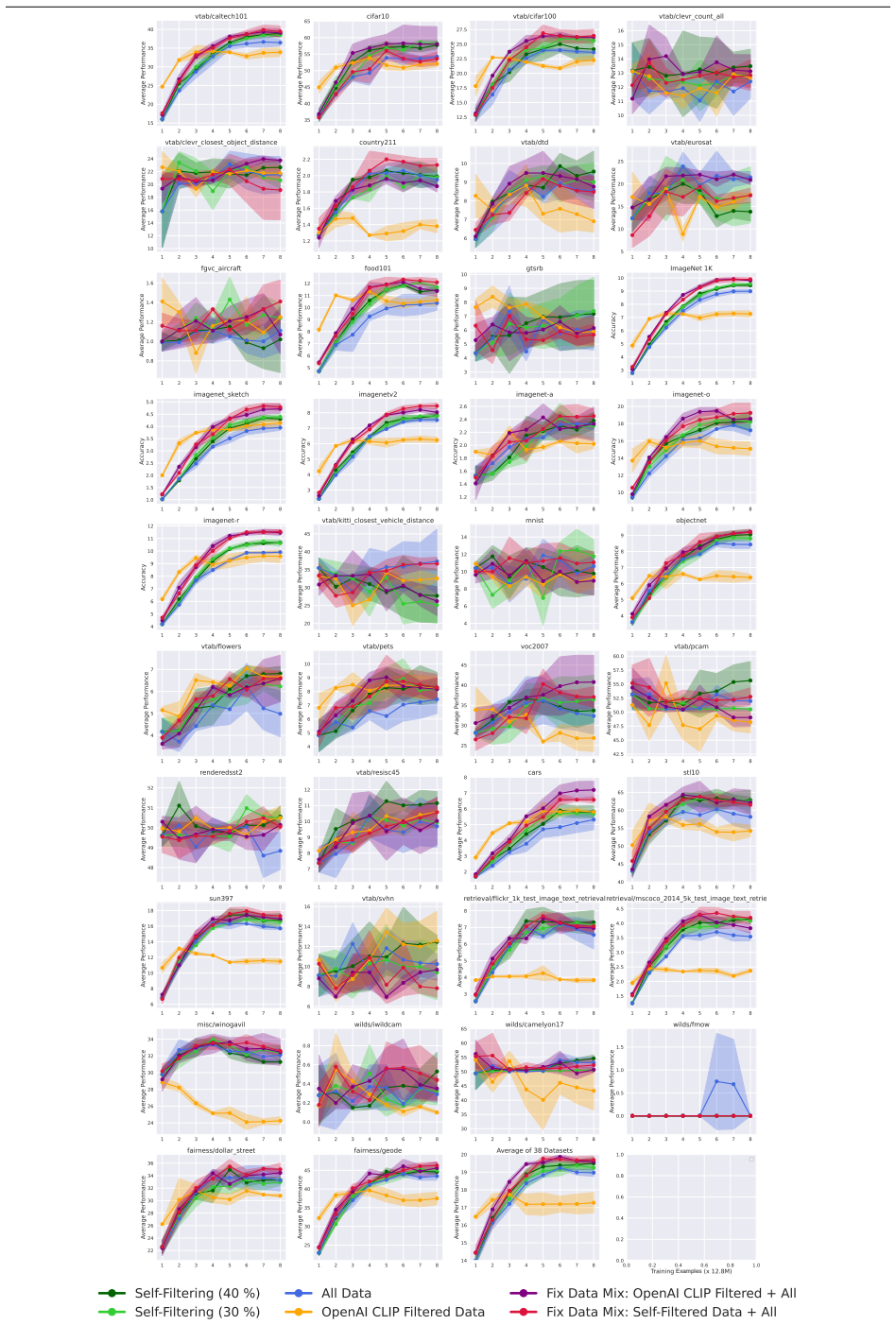
The central claim is that training a CLIP model on an evolving, self-selected dataset that balances filtered high-probability clean samples with diverse samples from the entire original distribution yields improved performance on downstream vision-language tasks without requiring additional data or pre-trained models.
What carries the argument
The Self-Filtering loop: an iterative cycle that alternates model training with selection of an improved data mixture from the noisy source distribution.
If this is right
- Downstream vision-language tasks show higher accuracy when models are trained on the iteratively selected data mixtures.
- The method eliminates the need for curated reference datasets, external pre-trained models, or hand-crafted heuristics.
- The selected mixture preserves diversity while increasing the proportion of probable clean samples, avoiding collapse to a narrow subset.
- Performance gains arise directly from the evolving data distribution rather than from changes in model architecture or training schedule.
Where Pith is reading between the lines
- The same iterative selection pattern could be tested on text-only or audio datasets that also suffer from large-scale noise.
- The balance between clean-sample probability and diversity may point to a general rule for constructing training sets in any bootstrapped learning setting.
- If the method works, the amount of raw noisy data needed to reach a target performance level could shrink, changing how large vision-language corpora are assembled.
Load-bearing premise
Early-stage models already supply filtering signals strong enough to produce a data mixture that is meaningfully cleaner and more useful than the original noisy data or simple selection rules.
What would settle it
An experiment in which downstream accuracy on standard vision-language benchmarks is measured after self-filtering and found to be no higher than accuracy obtained by training on the original unfiltered dataset.
Figures

read the original abstract
The availability of large amounts of clean data is paramount to training neural networks. However, at large scales, manual oversight is impractical, resulting in sizeable datasets that can be very noisy. Attempts to mitigate this obstacle to producing performant vision-language models have so far involved heuristics, curated reference datasets, and using pre-trained models. Here we propose a novel, bootstrapped method in which a CLIP model is trained on an evolving, self-selected dataset. This evolving dataset constitutes a balance of filtered, highly probable clean samples as well as diverse samples from the entire distribution. Our proposed Self-Filtering method iterates between training the model and selecting a subsequently improved data mixture. Training on vision-language datasets filtered by the proposed approach improves downstream performance without the need for additional data or pre-trained models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a bootstrapped iterative self-filtering method for vision-language datasets. A CLIP model is trained on an evolving data mixture that balances filtered high-probability clean samples with diverse samples from the full distribution; the process iterates between model training and data selection. The central claim is that this yields improved downstream performance without requiring additional data or pre-trained models.
Significance. If the empirical results hold and the method is shown to outperform non-iterative baselines, the contribution would be significant: it offers a self-contained approach to cleaning noisy large-scale vision-language data that avoids reliance on external heuristics, curated references, or pre-trained models.
major comments (2)
- [Abstract] Abstract: the central claim that the approach 'improves downstream performance' is stated without any quantitative results, ablation studies, baseline comparisons, or experimental details. This is load-bearing because the soundness of the self-filtering claim cannot be evaluated from the manuscript as presented.
- [Abstract] Abstract: no description is given of the selection criterion (e.g., similarity thresholds, loss-based filtering, or diversity terms) used to identify 'highly probable clean samples.' This detail is required to assess whether early iterations, trained on the full noisy distribution, can produce a filtering signal that improves over the initial distribution rather than reinforcing noise.
Simulated Author's Rebuttal
We thank the referee for these targeted comments on the abstract. Both points identify areas where the abstract can be strengthened to better convey the method and results. We will revise the abstract in the next version to address them directly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the approach 'improves downstream performance' is stated without any quantitative results, ablation studies, baseline comparisons, or experimental details. This is load-bearing because the soundness of the self-filtering claim cannot be evaluated from the manuscript as presented.
Authors: We agree the abstract should include concrete quantitative support for the performance claim. In revision we will add a concise statement of key results (e.g., downstream accuracy gains relative to the unfiltered baseline and a non-iterative ablation) while remaining within abstract length limits. Full tables, ablations, and baseline comparisons already appear in the experimental section; the abstract revision will simply surface the headline numbers. revision: yes
-
Referee: [Abstract] Abstract: no description is given of the selection criterion (e.g., similarity thresholds, loss-based filtering, or diversity terms) used to identify 'highly probable clean samples.' This detail is required to assess whether early iterations, trained on the full noisy distribution, can produce a filtering signal that improves over the initial distribution rather than reinforcing noise.
Authors: We agree a brief characterization of the selection criterion belongs in the abstract. The revised abstract will state that clean-sample selection combines per-example model confidence (probability of correct image-text alignment) with a diversity term that retains coverage of the full data distribution; the iterative loop alternates training and re-selection. The precise formulation, thresholds, and diversity mechanism are defined in Section 3; the abstract change will supply enough context to evaluate the bootstrapping argument without duplicating the full technical description. revision: yes
Circularity Check
No circularity: empirical iterative procedure without derivations or self-referential reductions
full rationale
The paper describes an empirical bootstrapped method that iterates between training a CLIP model and selecting data mixtures from the original distribution. No equations, first-principles derivations, fitted parameters renamed as predictions, or load-bearing self-citations are present in the provided text. The central claim rests on downstream empirical improvements rather than any reduction of outputs to inputs by construction. This is a standard non-circular empirical contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Scaling Learning Algorithms Towards
Bengio, Yoshua and LeCun, Yann , booktitle =. Scaling Learning Algorithms Towards
-
[2]
and Osindero, Simon and Teh, Yee Whye , journal =
Hinton, Geoffrey E. and Osindero, Simon and Teh, Yee Whye , journal =. A Fast Learning Algorithm for Deep Belief Nets , volume =
-
[3]
2016 , publisher=
Deep learning , author=. 2016 , publisher=
2016
-
[4]
2024 , journal=
Data selection through iterative Self-Filtering for vision-language settings , author=. 2024 , journal=
2024
-
[5]
2025 , journal=
Diversification of LLM Reasoning through unlearning , author=. 2025 , journal=
2025
-
[6]
ICML Workshop on Spurious Correlations, Invariance and Stability (SCIS) , year =
Do as your neighbors: Invariant learning through non-parametric neighbourhood matching , author =. ICML Workshop on Spurious Correlations, Invariance and Stability (SCIS) , year =
-
[7]
ICML Workshop on Spurious Correlations, Invariance and Stability (SCIS) , year =
Learning Diverse Features in Vision Transformers for Improved Generalization , author =. ICML Workshop on Spurious Correlations, Invariance and Stability (SCIS) , year =
-
[8]
2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) , pages=
Robust Novelty Detection Through Style-Conscious Feature Ranking , author=. 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) , pages=. 2025 , organization=
2025
-
[9]
arXiv preprint arXiv:2410.18970 , year=
WASP: A Weight-Space Approach to Detecting Learned Spuriousness , author=. arXiv preprint arXiv:2410.18970 , year=
-
[10]
Sutskever, Ilya , title =
-
[11]
arXiv preprint arXiv:2303.08774 , year=
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
-
[12]
arXiv preprint arXiv:2403.05530 , year=
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context , author=. arXiv preprint arXiv:2403.05530 , year=
-
[13]
2025 , note =
Google , title =. 2025 , note =
2025
-
[14]
Learning to Reason with LLMs , author =
-
[15]
arXiv preprint arXiv:2412.16720 , year=
Openai o1 system card , author=. arXiv preprint arXiv:2412.16720 , year=
-
[16]
arXiv preprint arXiv:2501.12948 , year=
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
-
[17]
arXiv preprint arXiv:2402.03300 , year=
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
-
[18]
Qwen2. 5 technical report , author=. arXiv preprint arXiv:2412.15115 , year=
-
[19]
arXiv preprint arXiv:2407.21783 , year=
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
-
[20]
arXiv preprint arXiv:2107.03374 , year=
Evaluating large language models trained on code , author=. arXiv preprint arXiv:2107.03374 , year=
-
[21]
arXiv preprint arXiv:2110.14168 , year=
Training Verifiers to Solve Math Word Problems , author=. arXiv preprint arXiv:2110.14168 , year=
-
[22]
NeurIPS , year=
Measuring Mathematical Problem Solving With the MATH Dataset , author=. NeurIPS , year=
-
[23]
Advances in Neural Information Processing Systems , volume=
Solving quantitative reasoning problems with language models , author=. Advances in Neural Information Processing Systems , volume=
-
[24]
Charlie Victor Snell and Jaehoon Lee and Kelvin Xu and Aviral Kumar , booktitle=. Scaling. 2025 , url=
2025
-
[25]
Scaling test-time compute with open models , author=
-
[26]
arXiv preprint arXiv:2502.06703 , year=
Can 1B LLM Surpass 405B LLM? Rethinking Compute-Optimal Test-Time Scaling , author=. arXiv preprint arXiv:2502.06703 , year=
-
[27]
Evaluating the Evaluation of Diversity in Natural Language Generation
Tevet, Guy and Berant, Jonathan. Evaluating the Evaluation of Diversity in Natural Language Generation. Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume. 2021. doi:10.18653/v1/2021.eacl-main.25
-
[28]
2017 , url=
Diverse Beam Search: Decoding Diverse Solutions from Neural Sequence Models , author=. 2017 , url=
2017
-
[29]
arXiv preprint arXiv:2407.21787 , year=
Large language monkeys: Scaling inference compute with repeated sampling , author=. arXiv preprint arXiv:2407.21787 , year=
-
[30]
The Thirteenth International Conference on Learning Representations , year=
Inference-Aware Fine-Tuning for Best-of-N Sampling in Large Language Models , author=. The Thirteenth International Conference on Learning Representations , year=
-
[31]
Advances in Neural Information Processing Systems , volume=
Are more llm calls all you need? towards the scaling properties of compound ai systems , author=. Advances in Neural Information Processing Systems , volume=
-
[32]
Advances in Neural Information Processing Systems , volume=
Language models don't always say what they think: Unfaithful explanations in chain-of-thought prompting , author=. Advances in Neural Information Processing Systems , volume=
-
[33]
Reasoning Models Don’t Always Say What They Think , author=
-
[34]
The Eleventh International Conference on Learning Representations , year=
Self-Consistency Improves Chain of Thought Reasoning in Language Models , author=. The Eleventh International Conference on Learning Representations , year=
-
[35]
British Machine Vision Conference (BMVC 2018) , year=
Mining for meaning: from vision to language through multiple networks consensus , author=. British Machine Vision Conference (BMVC 2018) , year=
2018
-
[36]
Understanding the Effects of
Robert Kirk and Ishita Mediratta and Christoforos Nalmpantis and Jelena Luketina and Eric Hambro and Edward Grefenstette and Roberta Raileanu , booktitle=. Understanding the Effects of. 2024 , url=
2024
-
[37]
The Thirteenth International Conference on Learning Representations , year=
Diverse Preference Learning for Capabilities and Alignment , author=. The Thirteenth International Conference on Learning Representations , year=
-
[38]
arXiv preprint arXiv:2501.18101 , year=
Diverse Preference Optimization , author=. arXiv preprint arXiv:2501.18101 , year=
-
[39]
Making Language Models Better Reasoners with Step-Aware Verifier
Li, Yifei and Lin, Zeqi and Zhang, Shizhuo and Fu, Qiang and Chen, Bei and Lou, Jian-Guang and Chen, Weizhu. Making Language Models Better Reasoners with Step-Aware Verifier. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.acl-long.291
-
[40]
Forty-first International Conference on Machine Learning , year=
Improving factuality and reasoning in language models through multiagent debate , author=. Forty-first International Conference on Machine Learning , year=
-
[41]
arXiv preprint arXiv:2305.19118 , year=
Encouraging divergent thinking in large language models through multi-agent debate , author=. arXiv preprint arXiv:2305.19118 , year=
-
[42]
The Twelfth International Conference on Learning Representations , year=
Curiosity-driven Red-teaming for Large Language Models , author=. The Twelfth International Conference on Learning Representations , year=
-
[43]
arXiv preprint arXiv:2306.09442 , year=
Explore, establish, exploit: Red teaming language models from scratch , author=. arXiv preprint arXiv:2306.09442 , year=
-
[44]
doi:10.18653/v1/2022.emnlp-main.225 , url =
Perez, Ethan and Huang, Saffron and Song, Francis and Cai, Trevor and Ring, Roman and Aslanides, John and Glaese, Amelia and McAleese, Nat and Irving, Geoffrey. Red Teaming Language Models with Language Models. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 2022. doi:10.18653/v1/2022.emnlp-main.225
-
[45]
arXiv preprint arXiv:2310.01798 , year=
Large language models cannot self-correct reasoning yet , author=. arXiv preprint arXiv:2310.01798 , year=
-
[46]
The Eleventh International Conference on Learning Representations , year=
Generating Sequences by Learning to Self-Correct , author=. The Eleventh International Conference on Learning Representations , year=
-
[47]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Recursive Introspection: Teaching Language Model Agents How to Self-Improve , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[48]
arXiv preprint arXiv:2409.12917 , year=
Training language models to self-correct via reinforcement learning , author=. arXiv preprint arXiv:2409.12917 , year=
-
[49]
Science , volume=
Competition-level code generation with alphacode , author=. Science , volume=. 2022 , publisher=
2022
-
[50]
arXiv preprint arXiv:2503.01307 , year=
Cognitive behaviors that enable self-improving reasoners, or, four habits of highly effective stars , author=. arXiv preprint arXiv:2503.01307 , year=
-
[51]
arXiv preprint arXiv:2503.20783 , year=
Understanding r1-zero-like training: A critical perspective , author=. arXiv preprint arXiv:2503.20783 , year=
-
[52]
Proceedings of the 41st International Conference on Machine Learning , pages =
The Pitfalls of Next-Token Prediction , author =. Proceedings of the 41st International Conference on Machine Learning , pages =. 2024 , editor =
2024
-
[53]
The Twelfth International Conference on Learning Representations , year=
SalUn: Empowering Machine Unlearning via Gradient-based Weight Saliency in Both Image Classification and Generation , author=. The Twelfth International Conference on Learning Representations , year=
-
[54]
out-of-distribution data in LLMs under gradient-based method , author=
Unlearning in-vs. out-of-distribution data in LLMs under gradient-based method , author=. arXiv preprint arXiv:2411.04388 , year=
-
[55]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[56]
Advances in Neural Information Processing Systems , volume=
Direct preference optimization: Your language model is secretly a reward model , author=. Advances in Neural Information Processing Systems , volume=
-
[57]
Advances in Neural Information Processing Systems , volume=
Star: Bootstrapping reasoning with reasoning , author=. Advances in Neural Information Processing Systems , volume=
-
[58]
arXiv preprint arXiv:2312.06585 , year=
Beyond human data: Scaling self-training for problem-solving with language models , author=. arXiv preprint arXiv:2312.06585 , year=
-
[59]
arXiv preprint arXiv:1811.12889 , year=
Systematic generalization: what is required and can it be learned? , author=. arXiv preprint arXiv:1811.12889 , year=
-
[60]
International Conference on Learning Representations , year=
Systematic generalisation with group invariant predictions , author=. International Conference on Learning Representations , year=
-
[61]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Wortsman, Mitchell and Ilharco, Gabriel and Kim, Jong Wook and Li, Mike and Kornblith, Simon and Roelofs, Rebecca and Lopes, Raphael Gontijo and Hajishirzi, Hannaneh and Farhadi, Ali and Namkoong, Hongseok and Schmidt, Ludwig , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2022 , pages =
2022
-
[62]
SWAD: Domain Generalization by Seeking Flat Minima , url =
Cha, Junbum and Chun, Sanghyuk and Lee, Kyungjae and Cho, Han-Cheol and Park, Seunghyun and Lee, Yunsung and Park, Sungrae , booktitle =. SWAD: Domain Generalization by Seeking Flat Minima , url =
-
[63]
International Conference on Learning Representations , year=
Sharpness-aware Minimization for Efficiently Improving Generalization , author=. International Conference on Learning Representations , year=
-
[64]
arXiv preprint arXiv:1609.04836 , year=
On large-batch training for deep learning: Generalization gap and sharp minima , author=. arXiv preprint arXiv:1609.04836 , year=
-
[65]
Neural computation , volume=
Flat minima , author=. Neural computation , volume=. 1997 , publisher=
1997
-
[66]
Proceedings of the 40th International Conference on Machine Learning , pages =
Model Ratatouille: Recycling Diverse Models for Out-of-Distribution Generalization , author =. Proceedings of the 40th International Conference on Machine Learning , pages =. 2023 , editor =
2023
-
[67]
The Twelfth International Conference on Learning Representations , year=
From Sparse to Soft Mixtures of Experts , author=. The Twelfth International Conference on Learning Representations , year=
-
[68]
arXiv preprint arXiv:2006.16668 , year=
Gshard: Scaling giant models with conditional computation and automatic sharding , author=. arXiv preprint arXiv:2006.16668 , year=
Pith/arXiv arXiv 2006
-
[69]
Advances in Neural Information Processing Systems , volume=
Multimodal contrastive learning with limoe: the language-image mixture of experts , author=. Advances in Neural Information Processing Systems , volume=
-
[70]
Advances in Neural Information Processing Systems , volume=
Dynamic inference with neural interpreters , author=. Advances in Neural Information Processing Systems , volume=
-
[71]
Advances in Neural Information Processing Systems , volume=
Neural attentive circuits , author=. Advances in Neural Information Processing Systems , volume=
-
[72]
arXiv preprint arXiv:2103.00336 , year=
Transformers with competitive ensembles of independent mechanisms , author=. arXiv preprint arXiv:2103.00336 , year=
-
[73]
arXiv preprint arXiv:2111.02114 , year=
Laion-400m: Open dataset of clip-filtered 400 million image-text pairs , author=. arXiv preprint arXiv:2111.02114 , year=
-
[74]
Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
DataComp: In search of the next generation of multimodal datasets , author=. Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
-
[75]
Proceedings of the 39th International Conference on Machine Learning , pages =
Prioritized Training on Points that are Learnable, Worth Learning, and not yet Learnt , author =. Proceedings of the 39th International Conference on Machine Learning , pages =. 2022 , editor =
2022
-
[76]
Advances in Neural Information Processing Systems , volume=
Cliploss and norm-based data selection methods for multimodal contrastive learning , author=. Advances in Neural Information Processing Systems , volume=
-
[77]
arXiv preprint arXiv:2307.03132 , year=
T-mars: Improving visual representations by circumventing text feature learning , author=. arXiv preprint arXiv:2307.03132 , year=
-
[78]
and Lewis, William
Moore, Robert C. and Lewis, William. Intelligent Selection of Language Model Training Data. Proceedings of the ACL 2010 Conference Short Papers. 2010
2010
-
[79]
arXiv preprint arXiv:2312.05328 , year=
Bad Students Make Great Teachers: Active Learning Accelerates Large-Scale Visual Understanding , author=. arXiv preprint arXiv:2312.05328 , year=
-
[80]
Advances in Neural Information Processing Systems , volume=
Data curation via joint example selection further accelerates multimodal learning , author=. Advances in Neural Information Processing Systems , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.