Benchmark AUC Is Not Deployable Reliability: A Cross-Dataset Audit of Off-the-Shelf Features for Surveillance Video Anomaly Detection
Pith reviewed 2026-06-30 07:26 UTC · model grok-4.3
The pith
A detector trained on one surveillance scene performs at chance on another.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
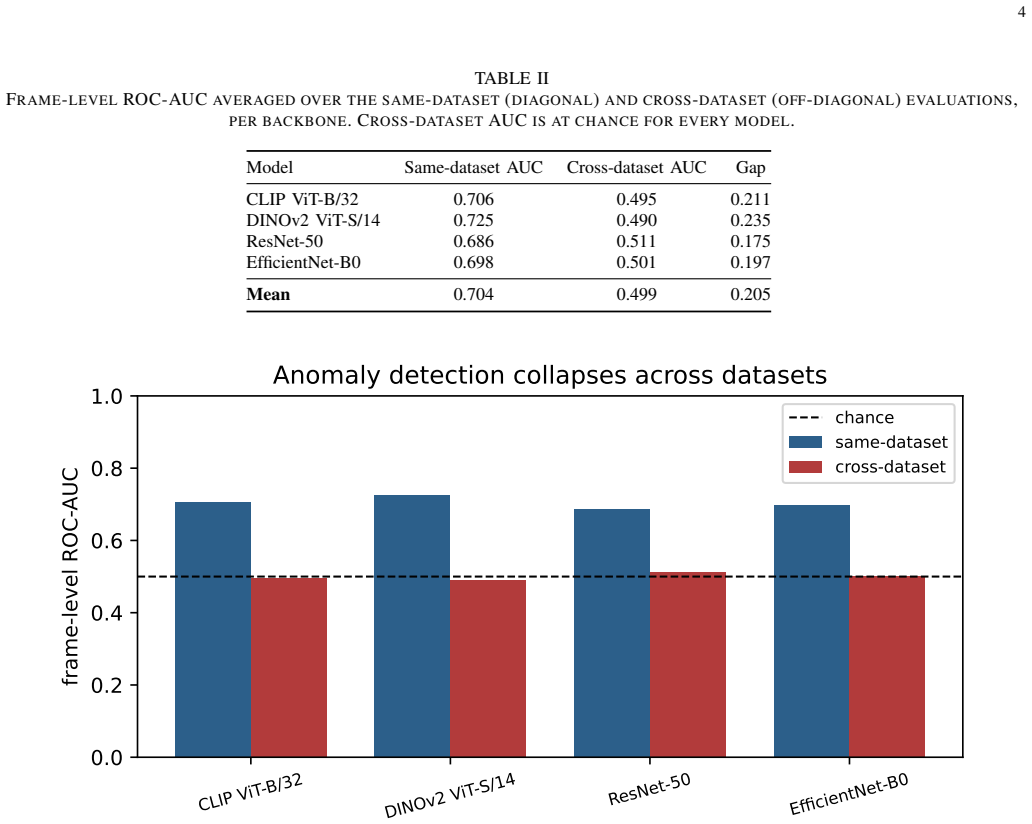
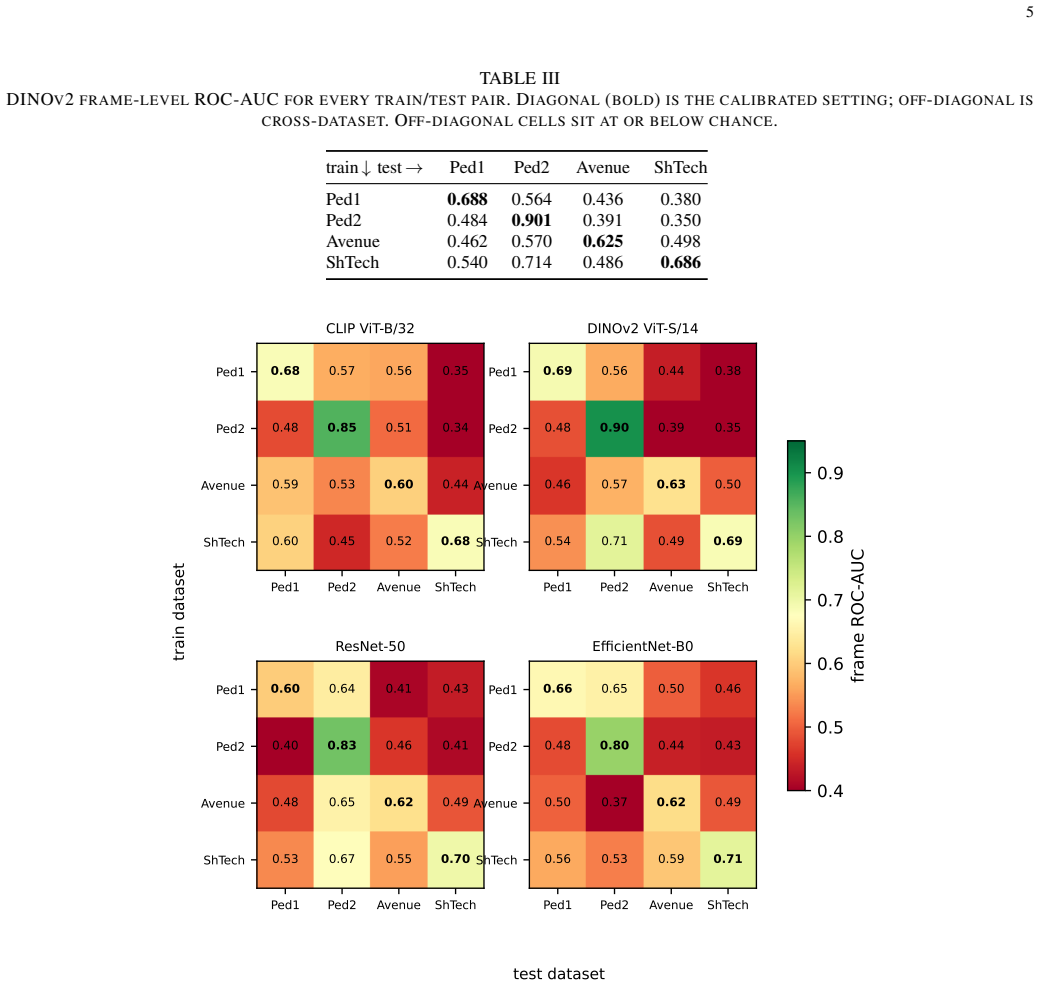
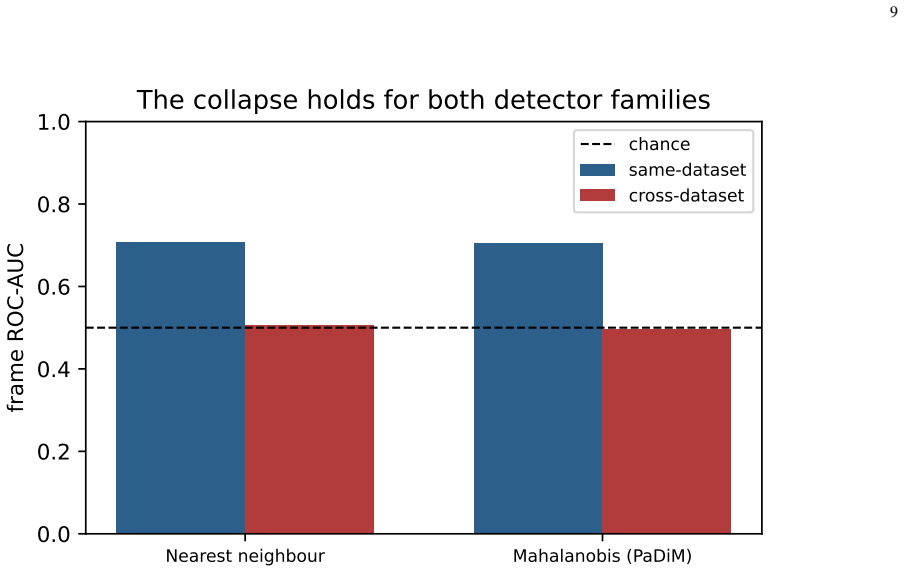
We build an unsupervised normality model from the all-normal training frames of one dataset using frozen off-the-shelf embeddings and a nearest-neighbour distance, then score the test frames of the same and of other datasets. Across four real datasets and four backbones, same-dataset AUC averages 0.704 but cross-dataset AUC averages 0.499. The collapse is reproduced with a PaDiM-style Mahalanobis detector, and the strongest backbone exhibits the largest drop.
What carries the argument
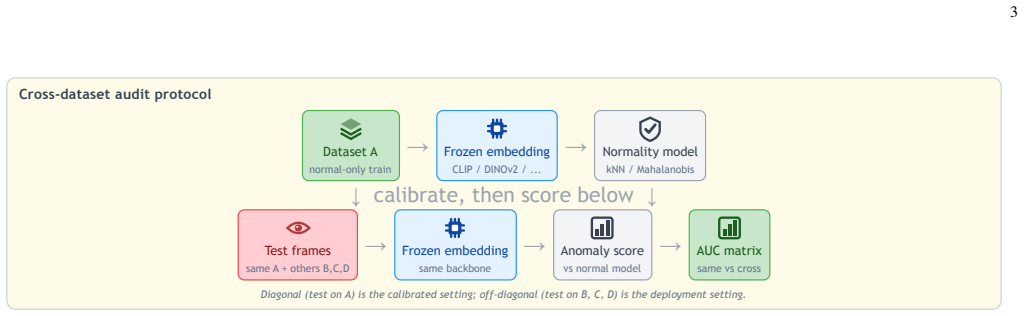
Cross-dataset protocol that trains a nearest-neighbour normality model on one dataset's normal frames and evaluates it on test frames from other datasets.
If this is right
- A detector calibrated on one scene is no better than a coin flip on another scene.
- Stronger backbones such as DINOv2 produce the largest cross-dataset drops.
- The gap remains essentially unchanged when nearest-neighbour scoring is replaced by Mahalanobis distance.
- Even at a favourable operating point the false-alarm rate reaches tens of thousands per hour.
Where Pith is reading between the lines
- Practical surveillance systems may require per-camera or per-scene calibration rather than reliance on a single pre-trained model.
- Benchmark suites for anomaly detection would benefit from mandatory cross-scene test splits to better reflect deployment conditions.
- The observed generalization failure may stem from the static nature of frame-level embeddings without temporal or domain-adaptation components.
- Similar cross-dataset audits could be applied to other unsupervised detection tasks that currently report only in-distribution metrics.
Load-bearing premise
That performance measured by training a normality model on one dataset's normal frames and testing on another dataset's frames is a valid proxy for real-world deployment across different cameras and scenes.
What would settle it
A replication using the same four datasets, same backbones, and same scoring rules that obtains average cross-dataset AUC materially above 0.5 would falsify the reported collapse to chance.
Figures
read the original abstract
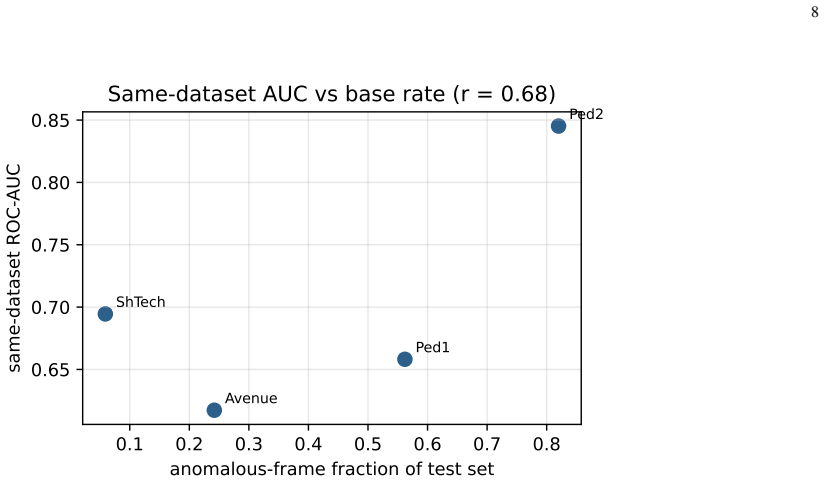
Automated "suspicious behavior" flagging is a headline promise of AI surveillance, and the field reports high frame-level ROC-AUC on standard video anomaly detection benchmarks. Those numbers are measured by training and testing on the same camera and scene. We audit what happens when that assumption is dropped. We build an unsupervised normality model from the all-normal training frames of one dataset, using frozen off-the-shelf embeddings (CLIP, DINOv2, ResNet-50, EfficientNet-B0) and a nearest-neighbour distance, and score the test frames of the same and of other datasets. Across 4 real datasets (UCSD Ped1, UCSD Ped2, CUHK Avenue, ShanghaiTech) and 4 backbones, same-dataset AUC averages 0.704 but cross-dataset AUC averages 0.499, which is chance: a detector calibrated on one scene is no better than a coin flip on another, and in several pairs it is below chance. The strongest backbone makes this worse, not better: DINOv2 has the best same-dataset AUC (up to 0.901 on Ped2) and the largest cross-dataset drop. The collapse is not an artefact of the scoring rule: replacing the nearest-neighbour detector with a PaDiM-style Mahalanobis detector reproduces it almost exactly (cross-dataset gap 0.202 versus 0.208). Even at a favourable operating point the false-alarm rate is on the order of 31,931 per hour. We conclude that the benchmark numbers quoted for surveillance anomaly detection describe a calibrated laboratory setting and overstate deployable reliability by a wide margin, and we release the code that reproduces every number.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates unsupervised video anomaly detection using frozen off-the-shelf embeddings (CLIP, DINOv2, ResNet-50, EfficientNet-B0) and nearest-neighbor or Mahalanobis scoring on four public datasets (UCSD Ped1/2, CUHK Avenue, ShanghaiTech). It reports average same-dataset frame-level ROC-AUC of 0.704 versus cross-dataset AUC of 0.499 (chance level), with the gap reproduced across backbones and detectors; it concludes that same-scene benchmark numbers overstate deployable reliability for surveillance across cameras and scenes, and releases code for all reported numbers.
Significance. If the cross-dataset protocol is accepted as a valid proxy for deployment without per-scene adaptation, the result identifies a substantial evaluation gap in current VAD benchmarks. Strengths include the multi-dataset, multi-backbone consistency, reproduction of the gap with an alternative (PaDiM-style) detector, and the public code release that enables direct verification of every reported AUC.
major comments (2)
- [Abstract] Abstract (paragraph on cross-dataset protocol) and conclusion: the central claim that same-dataset AUCs 'overstate deployable reliability' treats the observed cross-dataset collapse as the relevant deployment regime. This interpretation requires that real-world systems cannot or do not collect a modest set of normal frames from the target camera/scene to build the reference model; the manuscript supplies no citation, argument, or empirical support for the infeasibility of such per-scene collection, which is the load-bearing step linking the reported numbers to the deployment conclusion.
- [Abstract] Abstract and methods description: the reported same-dataset average of 0.704 and cross-dataset average of 0.499 are presented as robust, yet the text does not specify the exact train/test splits used for each dataset pair, the precise definition of 'all-normal training frames,' or any controls for scene-specific statistics that might differ systematically between datasets; without these details the numerical gap cannot be fully audited even with the released code.
minor comments (1)
- [Abstract] The false-alarm-rate claim of ~31,931 per hour at a favourable operating point should cite the exact threshold and frame rate assumptions used to derive it.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. Below we respond point-by-point to the major comments and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract (paragraph on cross-dataset protocol) and conclusion: the central claim that same-dataset AUCs 'overstate deployable reliability' treats the observed cross-dataset collapse as the relevant deployment regime. This interpretation requires that real-world systems cannot or do not collect a modest set of normal frames from the target camera/scene to build the reference model; the manuscript supplies no citation, argument, or empirical support for the infeasibility of such per-scene collection, which is the load-bearing step linking the reported numbers to the deployment conclusion.
Authors: We agree the manuscript does not supply citations or empirical evidence on the feasibility of per-scene normal-frame collection. The cross-dataset protocol is presented as a proxy for deployment to unseen scenes without scene-specific adaptation. We will revise the abstract and conclusion to state this assumption explicitly and add a short discussion paragraph noting that while per-scene collection is possible in controlled settings, many surveillance deployments involve new cameras, changing conditions, or resource constraints where such adaptation is not performed. This clarifies the scope of the claim without overstating it. revision: yes
-
Referee: [Abstract] Abstract and methods description: the reported same-dataset average of 0.704 and cross-dataset average of 0.499 are presented as robust, yet the text does not specify the exact train/test splits used for each dataset pair, the precise definition of 'all-normal training frames,' or any controls for scene-specific statistics that might differ systematically between datasets; without these details the numerical gap cannot be fully audited even with the released code.
Authors: The released code contains the exact splits and frame selections used for every reported number. To improve readability and auditability from the text, we will expand the methods section with a table or explicit list of the train/test splits for each dataset pair, the precise definition of all-normal training frames, and any scene-statistic controls applied. This addresses the concern directly. revision: yes
Circularity Check
No circularity: purely empirical cross-dataset audit
full rationale
The manuscript reports direct computation of frame-level AUC using frozen off-the-shelf embeddings (CLIP, DINOv2, etc.) and two detectors (nearest-neighbour, Mahalanobis) on four public datasets. Same-dataset vs. cross-dataset AUC values are obtained by training on one dataset's normal frames and testing on another's test frames. No equations, fitted parameters renamed as predictions, self-citations, or ansatzes appear in the derivation chain; the central numbers are produced by running the described protocol on the data. The paper is self-contained against external benchmarks and contains no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math ROC-AUC is an appropriate scalar summary for ranking-based anomaly detection performance
- domain assumption The four chosen datasets (UCSD Ped1/2, CUHK Avenue, ShanghaiTech) represent meaningfully distinct scenes and camera conditions
Reference graph
Works this paper leans on
-
[1]
Anomaly detection in crowded scenes,
V . Mahadevan, W.-X. Li, V . Bhalodia, and N. Vasconcelos, “Anomaly detection in crowded scenes,” inIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2010, pp. 1975–1981
2010
-
[2]
Abnormal event detection at 150 FPS in MATLAB,
C. Lu, J. Shi, and J. Jia, “Abnormal event detection at 150 FPS in MATLAB,” inIEEE International Conference on Computer Vision (ICCV), 2013, pp. 2720–2727
2013
-
[3]
Future Frame Prediction for Anomaly Detection -- A New Baseline
W. Liu, W. Luo, D. Lian, and S. Gao, “Future frame prediction for anomaly detection: A new baseline,” inIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018, pp. 6536–6545, arXiv:1712.09867
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[4]
A survey of single-scene video anomaly detection,
B. Ramachandra, M. J. Jones, and R. R. Vatsavai, “A survey of single-scene video anomaly detection,”IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), vol. 44, no. 5, pp. 2293–2312, 2022, arXiv:2004.05993
-
[5]
Deep learning for anomaly detection: A review,
G. Pang, C. Shen, L. Cao, and A. van den Hengel, “Deep learning for anomaly detection: A review,”ACM Computing Surveys, vol. 54, no. 2, pp. 1–38, 2022, arXiv:2007.02500
-
[6]
D. Gong, L. Liu, V . Le, B. Saha, M. R. Mansour, S. Venkatesh, and A. van den Hengel, “Memorizing normality to detect anomaly: Memory-augmented deep autoencoder for unsupervised anomaly detection,” inIEEE/CVF International Conference on Computer Vision (ICCV), 2019, memAE; arXiv:1904.02639
-
[7]
Learning memory-guided normality for anomaly detection,
H. Park, J. Noh, and B. Ham, “Learning memory-guided normality for anomaly detection,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 14 372–14 381, mNAD
2020
-
[8]
Towards total recall in industrial anomaly detection,
K. Roth, L. Pemula, J. Zepeda, B. Sch ¨olkopf, T. Brox, and P. Gehler, “Towards total recall in industrial anomaly detection,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022, patchCore; arXiv:2106.08265
-
[9]
A Baseline for Detecting Misclassified and Out-of-Distribution Examples in Neural Networks
D. Hendrycks and K. Gimpel, “A baseline for detecting misclassified and out-of-distribution examples in neural networks,” in International Conference on Learning Representations (ICLR), 2017, arXiv:1610.02136
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[10]
Real-world Anomaly Detection in Surveillance Videos
W. Sultani, C. Chen, and M. Shah, “Real-world anomaly detection in surveillance videos,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2018, pp. 6479–6488, arXiv:1801.04264
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[11]
Learning Transferable Visual Models From Natural Language Supervision
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever, “Learning transferable visual models from natural language supervision,” inInternational Conference on Machine Learning (ICML), 2021, arXiv:2103.00020
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[12]
Reproducible scaling laws for contrastive language-image learning,
M. Cherti, R. Beaumont, R. Wightman, M. Wortsman, G. Ilharco, C. Gordon, C. Schuhmann, L. Schmidt, and J. Jitsev, “Reproducible scaling laws for contrastive language-image learning,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023, openCLIP; arXiv:2212.07143
-
[13]
DINOv2: Learning Robust Visual Features without Supervision
M. Oquab, T. Darcet, T. Moutakanni, H. V o, M. Szafraniec, V . Khalidov, P. Fernandez, D. Haziza, F. Massa, A. El-Nouby et al., “DINOv2: Learning robust visual features without supervision,”Transactions on Machine Learning Research (TMLR), 2024, arXiv:2304.07193
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Deep Residual Learning for Image Recognition
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 770–778, arXiv:1512.03385
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[15]
EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
M. Tan and Q. V . Le, “EfficientNet: Rethinking model scaling for convolutional neural networks,” inInternational Conference on Machine Learning (ICML), 2019, arXiv:1905.11946
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[16]
PyTorch image models (timm),
R. Wightman, “PyTorch image models (timm),” https://github.com/huggingface/pytorch-image-models, 2019, accessed 2026-06-15
2019
-
[17]
PyTorch: An imperative style, high-performance deep learning library,
A. Paszke, S. Gross, F. Massa, A. Lereret al., “PyTorch: An imperative style, high-performance deep learning library,”Advances in Neural Information Processing Systems (NeurIPS), 2019
2019
-
[18]
PaDiM: A patch distribution modeling framework for anomaly detection and localization,
T. Defard, A. Setkov, A. Loesch, and R. Audigier, “PaDiM: A patch distribution modeling framework for anomaly detection and localization,” inInternational Conference on Pattern Recognition (ICPR) Workshops, 2021, arXiv:2011.08785
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.