Qwen-Image-2.0-RL Technical Report
Pith reviewed 2026-06-29 01:08 UTC · model grok-4.3
The pith
Qwen-Image-2.0-RL applies RLHF and on-policy distillation to raise a diffusion model's scores on text-to-image and editing benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
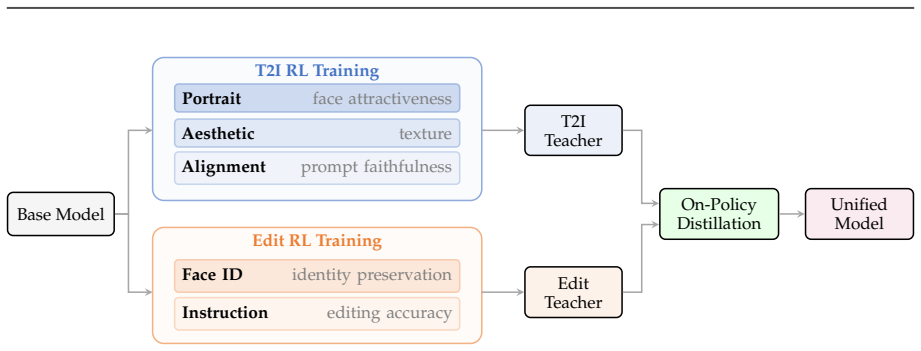
Qwen-Image-2.0-RL is a post-training pipeline that applies reinforcement learning from human feedback and on-policy distillation to the Qwen-Image-2.0 diffusion model. Task-specific composite reward models are built by fine-tuning vision-language models with pointwise scoring and chain-of-thought reasoning; these cover alignment, aesthetics, and portrait fidelity for text-to-image generation and instruction accuracy plus face preservation for editing. A scalable GRPO-based RL framework incorporates hybrid CFG, intra-group reward filtering, and per-category weight calibration, followed by on-policy distillation that consolidates multiple teachers via trajectory-level velocity matching.
What carries the argument
GRPO-based RL training framework driven by composite reward models and completed by on-policy distillation that merges specialized policies through velocity matching.
If this is right
- Text-to-image outputs show higher alignment with prompts and improved aesthetics and portrait fidelity.
- Image editing outputs follow instructions more accurately while preserving face identity.
- The single distilled model matches or exceeds the performance of the separately trained task policies.
- Hybrid CFG and reward-range filtering allow RL updates without catastrophic forgetting of pre-trained capabilities.
Where Pith is reading between the lines
- The same reward-construction approach could be applied to other base diffusion models without retraining the entire stack from scratch.
- Per-category reward calibration suggests that further specialization by image style or content domain could yield additional targeted gains.
- Trajectory-level velocity matching in distillation may transfer to other multi-task merging scenarios beyond image generation.
Load-bearing premise
The fine-tuned vision-language reward models supply reliable, unbiased signals that correctly guide the RL updates without introducing systematic errors.
What would settle it
A controlled human preference study in which raters consistently choose outputs from the base Qwen-Image-2.0 model over the RL-trained version on the same prompts would falsify the reported gains.
Figures




read the original abstract
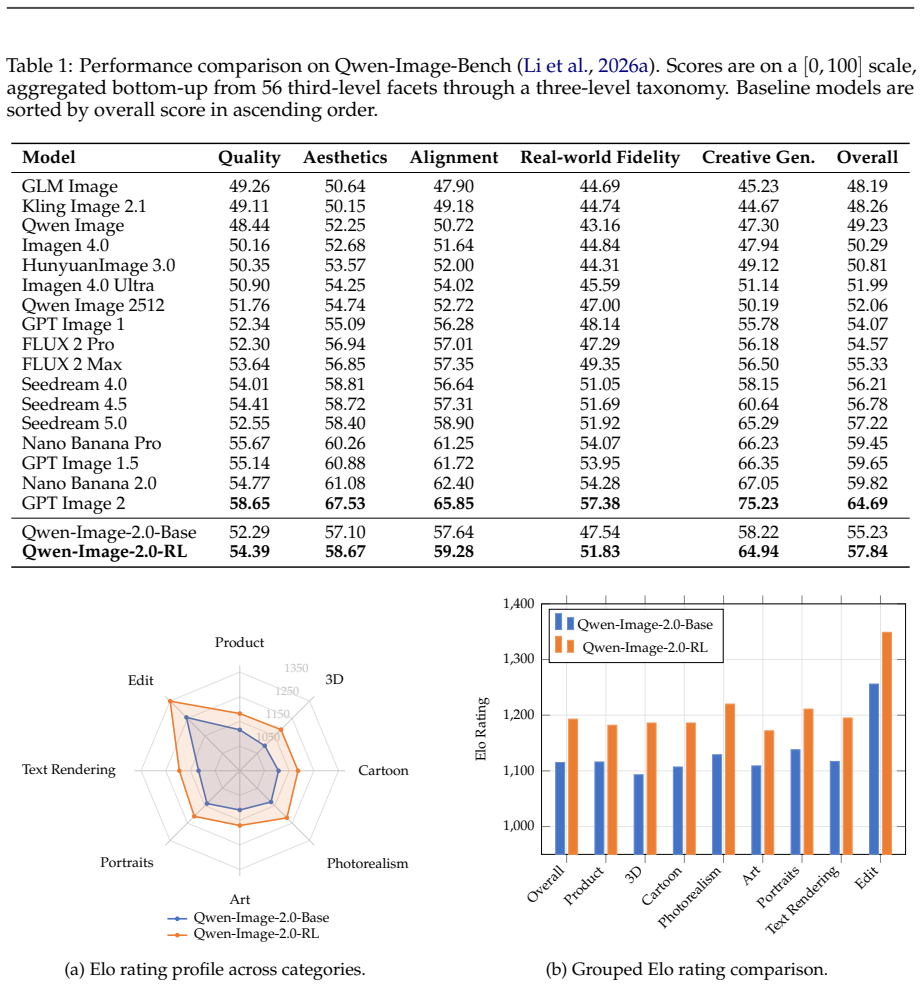
We present Qwen-Image-2.0-RL, a post-training pipeline that applies reinforcement learning from human feedback (RLHF) and on-policy distillation (OPD) to improve both the visual quality and instruction-following capability of the Qwen-Image-2.0 diffusion model. To provide reliable reward signals, we construct task-specific composite reward models by fine-tuning vision-language models with a pointwise scoring paradigm and chain-of-thought reasoning. For text-to-image generation, the reward models cover alignment, aesthetics, and portrait fidelity dimensions. For image editing tasks, the reward system addresses instruction-following accuracy and face identity preservation. Building on this reward system, we develop a scalable GRPO-based RL training framework, incorporating a hybrid classifier-free guidance (CFG) strategy to preserve pre-trained knowledge, prompt curation via intra-group reward range filtering, and per-category reward weight calibration. To merge the task-specialized RL policies for T2I and editing, we propose on-policy distillation as the final training stage, which consolidates multiple teachers into a single student model through trajectory-level velocity matching. Extensive evaluation shows that Qwen-Image-2.0-RL achieves 57.84 overall score on Qwen-Image-Bench (+2.61 over the base model), Elo ratings of 1193 in text-to-image arena (+78) and 1349 in image edit arena (+93), demonstrating consistent gains in aesthetic quality, prompt adherence, and editing accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Qwen-Image-2.0-RL, a post-training pipeline applying RLHF via GRPO and on-policy distillation (OPD) to the Qwen-Image-2.0 diffusion model. Task-specific composite reward models are built by fine-tuning VLMs using pointwise scoring and chain-of-thought reasoning, covering alignment, aesthetics, portrait fidelity for T2I and instruction-following plus face identity for editing. The framework incorporates hybrid CFG, intra-group reward filtering, per-category weighting, and trajectory-level velocity matching for distillation. Reported results include 57.84 overall on Qwen-Image-Bench (+2.61), Elo 1193 in T2I arena (+78), and 1349 in editing arena (+93).
Significance. If the reward models prove reliable, the work offers a practical demonstration of scalable RL for diffusion models with measurable gains in quality metrics. The hybrid CFG and OPD stages address knowledge preservation and policy merging in a concrete way. However, the absence of any reported validation for the reward signals against human preferences means the significance cannot be assessed from the provided information.
major comments (2)
- [Abstract] Abstract: The headline improvements (+2.61 on Qwen-Image-Bench, +78/+93 Elo) are attributed to GRPO updates driven by the composite reward models, yet no correlation, calibration, or held-out human agreement statistics for these scalar rewards are supplied. This is load-bearing because any misalignment in the per-category weighted rewards would be directly amplified by the described filtering and distillation steps.
- [Abstract] Abstract (evaluation paragraph): No experimental controls, baseline comparisons beyond the base model, statistical significance tests, or data-split details are mentioned for the reported scores. Without these, it is impossible to determine whether the gains exceed what could arise from reward model artifacts or training variance.
minor comments (1)
- [Abstract] Abstract: The description of 'intra-group reward range filtering' and 'per-category reward weight calibration' lacks even high-level equations or pseudocode, making the method difficult to reproduce from the text alone.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the validation of reward models and the need for stronger experimental controls. We address each major comment below and will revise the manuscript to incorporate additional analyses and details.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline improvements (+2.61 on Qwen-Image-Bench, +78/+93 Elo) are attributed to GRPO updates driven by the composite reward models, yet no correlation, calibration, or held-out human agreement statistics for these scalar rewards are supplied. This is load-bearing because any misalignment in the per-category weighted rewards would be directly amplified by the described filtering and distillation steps.
Authors: We agree that explicit validation of the reward models against human preferences is important for assessing reliability. The current manuscript does not report correlation coefficients, calibration metrics, or held-out human agreement statistics for the composite VLM rewards. We will add a dedicated subsection on reward model validation in the revised version, including Pearson/Spearman correlations and agreement rates on a held-out human preference dataset for each reward dimension (alignment, aesthetics, portrait fidelity, instruction-following, and identity preservation). This will directly address potential misalignment concerns before the filtering and distillation stages. revision: yes
-
Referee: [Abstract] Abstract (evaluation paragraph): No experimental controls, baseline comparisons beyond the base model, statistical significance tests, or data-split details are mentioned for the reported scores. Without these, it is impossible to determine whether the gains exceed what could arise from reward model artifacts or training variance.
Authors: We acknowledge the need for more rigorous experimental reporting. The manuscript currently emphasizes comparisons to the base Qwen-Image-2.0 model as the primary control. In revision we will expand the evaluation section to include: (i) additional baselines such as standard PPO and other diffusion RL variants where feasible, (ii) statistical significance testing (e.g., paired t-tests or bootstrap confidence intervals on the benchmark scores), and (iii) explicit details on training/evaluation data splits and prompt curation procedures. These additions will help isolate the contribution of the GRPO and OPD stages from potential artifacts. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The abstract describes a standard RLHF + OPD pipeline: reward models are fine-tuned on VLMs using pointwise scoring + CoT, then used to drive GRPO updates with hybrid CFG, filtering, and distillation. Reported gains are measured on external benchmarks (Qwen-Image-Bench overall score, Elo arenas) that are independent of the training rewards. No equations, self-definitional reductions, fitted-input-as-prediction steps, or load-bearing self-citations appear in the text. The central claim (performance lift from the pipeline) does not reduce to its own inputs by construction; it remains an empirical outcome on held-out evaluations.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
On-policy distillation of language models: Learning from self-generated mistakes
Rishabh Agarwal, Nino Vieillard, Yongchao Zhou, Piotr Stanczyk, Sabela Ramos Garea, Matthieu Geist, and Olivier Bachem. On-policy distillation of language models: Learning from self-generated mistakes. InInternational Conference on Learning Representations, volume 2024, pp. 21246–21263,
2024
-
[2]
Error bounds for flow matching methods.arXiv preprint arXiv:2305.16860,
Joe Benton, George Deligiannidis, and Arnaud Doucet. Error bounds for flow matching methods.arXiv preprint arXiv:2305.16860,
-
[3]
Huanqia Cai, Sihan Cao, Ruoyi Du, Peng Gao, Steven Hoi, Zhaohui Hou, Shijie Huang, Dengyang Jiang, Xin Jin, Liangchen Li, et al. Z-image: An efficient image generation foundation model with single-stream diffusion transformer.arXiv preprint arXiv:2511.22699,
-
[4]
Hunyuanimage 3.0 technical report.arXiv preprint arXiv:2509.23951,
Siyu Cao, Hangting Chen, Peng Chen, Yiji Cheng, Yutao Cui, Xinchi Deng, Ying Dong, Kipper Gong, Tianpeng Gu, Xiusen Gu, et al. Hunyuanimage 3.0 technical report.arXiv preprint arXiv:2509.23951,
-
[5]
Pixart-alpha: Fast training of diffusion transformer for photorealistic text-to-image synthesis
Junsong Chen, Jincheng Yu, Chongjian Ge, Lewei Yao, Enze Xie, Zhongdao Wang, James Kwok, Ping Luo, Huchuan Lu, and Zhenguo Li. Pixart-alpha: Fast training of diffusion transformer for photorealistic text-to-image synthesis. InInternational conference on learning representations, volume 2024, pp. 57611– 57640,
2024
-
[6]
Flow-opd: On-policy distillation for flow matching models.arXiv preprint arXiv:2605.08063,
Zhen Fang, Wenxuan Huang, Yu Zeng, Yiming Zhao, Shuang Chen, Kaituo Feng, Yunlong Lin, Lin Chen, Zehui Chen, Shaosheng Cao, et al. Flow-opd: On-policy distillation for flow matching models.arXiv preprint arXiv:2605.08063,
-
[7]
Seedream 3.0 technical report.arXiv preprint arXiv:2504.11346,
Yu Gao, Lixue Gong, Qiushan Guo, Xiaoxia Hou, Zhichao Lai, Fanshi Li, Liang Li, Xiaochen Lian, Chao Liao, Liyang Liu, et al. Seedream 3.0 technical report.arXiv preprint arXiv:2504.11346,
-
[8]
Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598,
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598,
-
[9]
Black Forest Labs, Stephen Batifol, Andreas Blattmann, Frederic Boesel, Saksham Consul, Cyril Diagne, Tim Dockhorn, Jack English, Zion English, Patrick Esser, et al. Flux. 1 kontext: Flow matching for in-context image generation and editing in latent space.arXiv preprint arXiv:2506.15742,
-
[10]
Niantong Li, Guangzheng Hu, Weixu Qiao, Ying Ba, Qichen Hong, Shijun Shen, Jinlin Wang, Fan Zhou, Jianye Kang, Xin Shang, et al. Qwen-image-bench: From generation to creation in text-to-image evaluation.arXiv preprint arXiv:2605.28091, 2026a. Quanhao Li, Junqiu Yu, Kaixun Jiang, Yujie Wei, Zhen Xing, Pandeng Li, Ruihang Chu, Shiwei Zhang, Yu Liu, and Zuxu...
-
[11]
Jie Liu, Gongye Liu, Jiajun Liang, Yangguang Li, Jiaheng Liu, Xintao Wang, Pengfei Wan, Di Zhang, and Wanli Ouyang. Flow-grpo: Training flow matching models via online rl.Advances in neural information processing systems, 38:40783–40818, 2026a. 14 Shih-Yang Liu, Xin Dong, Ximing Lu, Shizhe Diao, Peter Belcak, Mingjie Liu, Min-Hung Chen, Hongxu Yin, Yu-Chi...
-
[12]
Sdxl: Improving latent diffusion models for high-resolution image synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion models for high-resolution image synthesis. In International Conference on Learning Representations, volume 2024, pp. 1862–1874,
2024
-
[13]
Seedream 4.0: Toward next-generation multimodal image generation.arXiv preprint arXiv:2509.20427,
Team Seedream, Yunpeng Chen, Yu Gao, Lixue Gong, Meng Guo, Qiushan Guo, Zhiyao Guo, Xiaoxia Hou, Weilin Huang, Yixuan Huang, et al. Seedream 4.0: Toward next-generation multimodal image generation.arXiv preprint arXiv:2509.20427,
-
[14]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
-
[15]
Jing Wang, Jiajun Liang, Jie Liu, Henglin Liu, Gongye Liu, Jun Zheng, Wanyuan Pang, Ao Ma, Zhenyu Xie, Xintao Wang, et al. Grpo-guard: Mitigating implicit over-optimization in flow matching via regulated clipping.arXiv preprint arXiv:2510.22319, 2025a. Yibin Wang, Yuhang Zang, Hao Li, Cheng Jin, and Jiaqi Wang. Unified reward model for multimodal understa...
-
[16]
Qwen-image technical report.arXiv preprint arXiv:2508.02324, 2025a
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng-ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, et al. Qwen-image technical report.arXiv preprint arXiv:2508.02324, 2025a. Jie Wu, Yu Gao, Zilyu Ye, Ming Li, Liang Li, Hanzhong Guo, Jie Liu, Zeyue Xue, Xiaoxia Hou, Wei Liu, et al. Rewarddance: Reward scaling in visual generation.arXiv...
-
[17]
Shuchen Xue, Chongjian Ge, Shilong Zhang, Yichen Li, and Zhi-Ming Ma. Advantage weighted matching: Aligning rl with pretraining in diffusion models.arXiv preprint arXiv:2509.25050,
-
[18]
Qwen-image-2.0 technical report.arXiv preprint arXiv:2605.10730,
Bing Zhao, Chenfei Wu, Deqing Li, Hao Meng, Jiahao Li, Jie Zhang, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kuan Cao, et al. Qwen-image-2.0 technical report.arXiv preprint arXiv:2605.10730,
-
[19]
Diffusionnft: Online diffusion reinforcement with forward process
Kaiwen Zheng, Huayu Chen, Haotian Ye, Haoxiang Wang, Qinsheng Zhang, Kai Jiang, Hang Su, Stefano Ermon, Jun Zhu, and Ming-Yu Liu. Diffusionnft: Online diffusion reinforcement with forward process. arXiv preprint arXiv:2509.16117,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.