Ontology-constrained multi-LLM scoring of hypothesis support in the predictive processing literature
Pith reviewed 2026-06-30 11:47 UTC · model grok-4.3
The pith
Local multi-LLM councils score papers on predictive coding hypotheses using a fixed 36-concept glossary to create quantitative evidence maps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
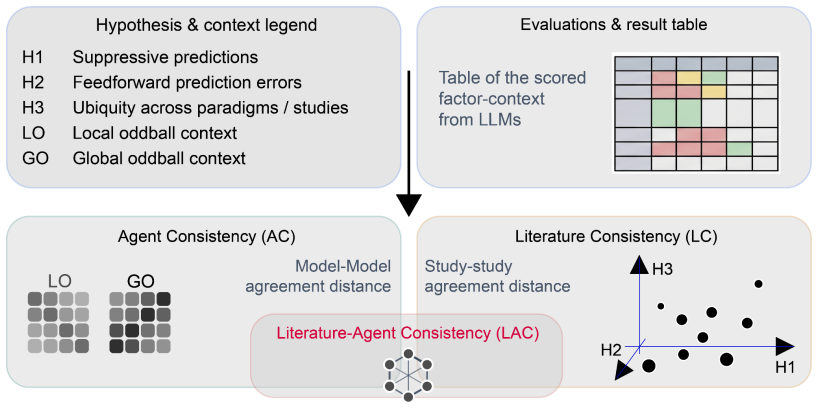
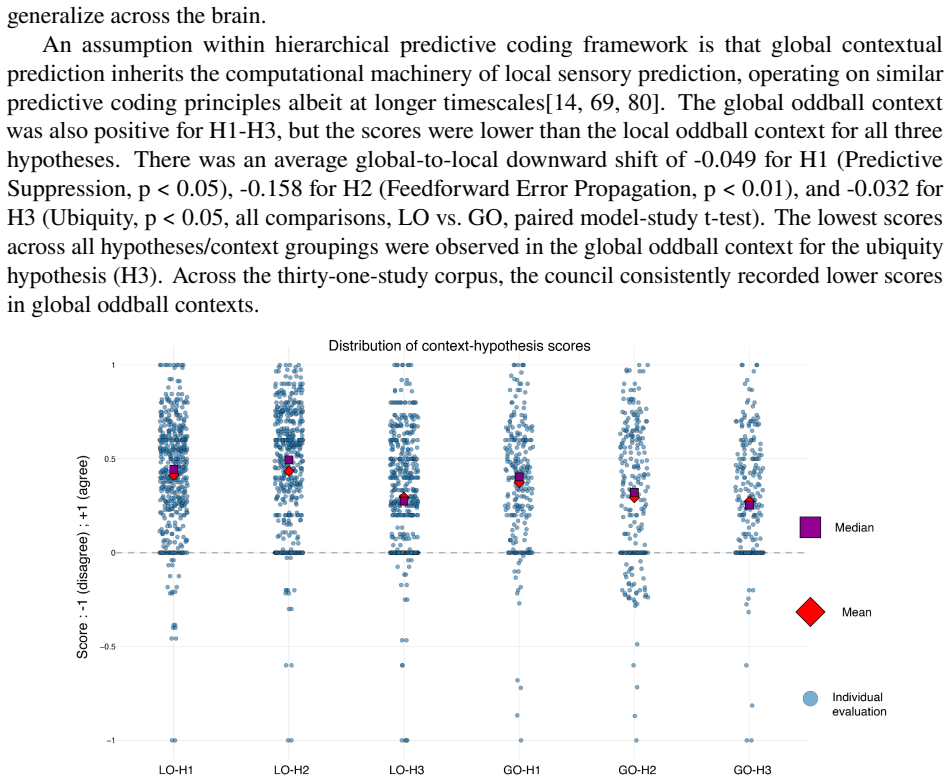
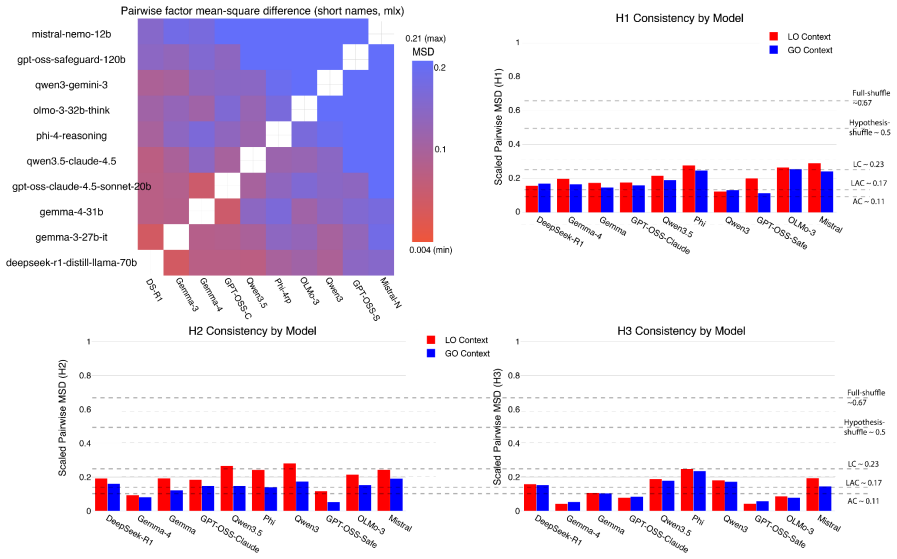
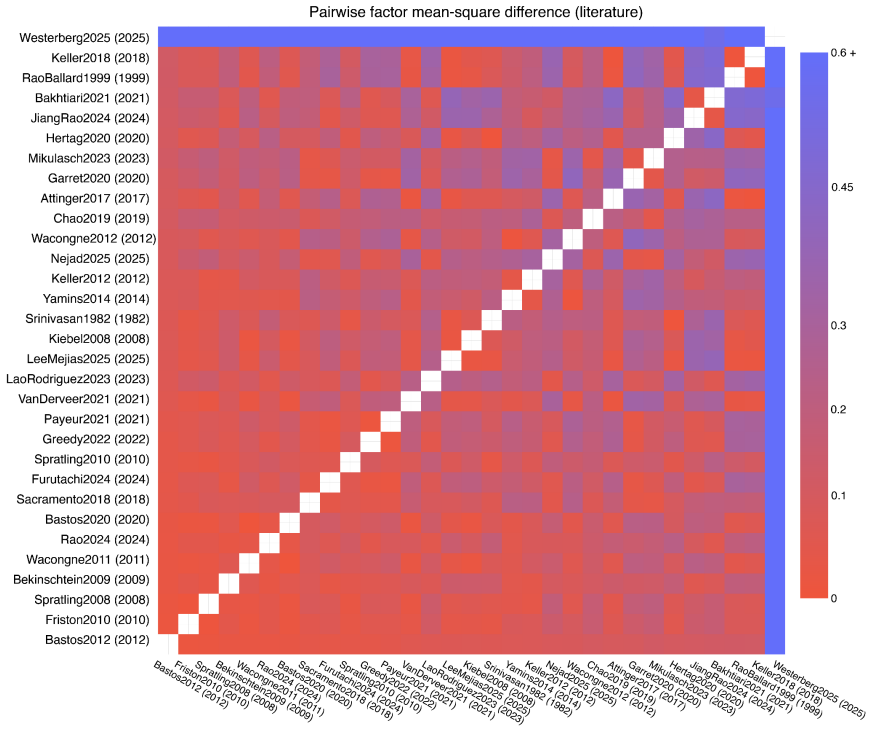
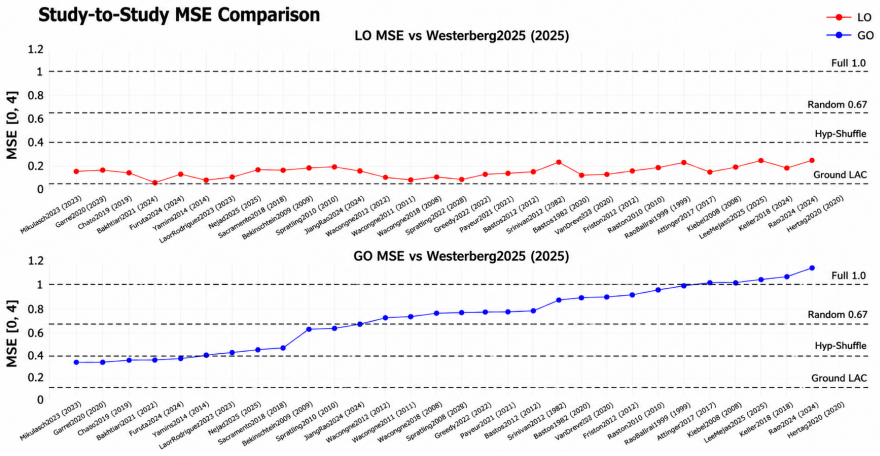
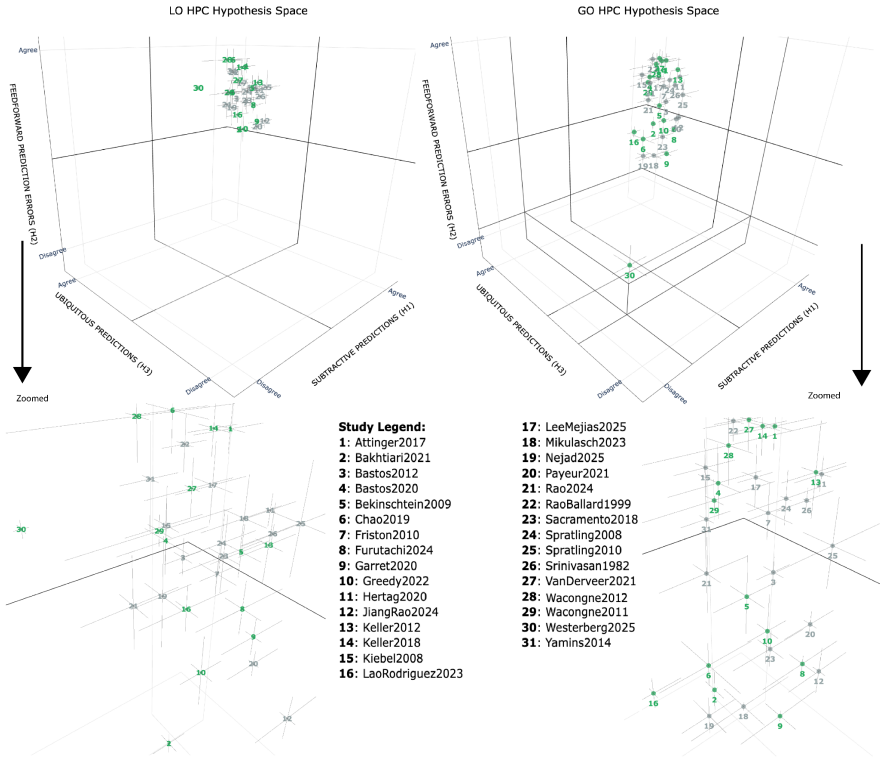
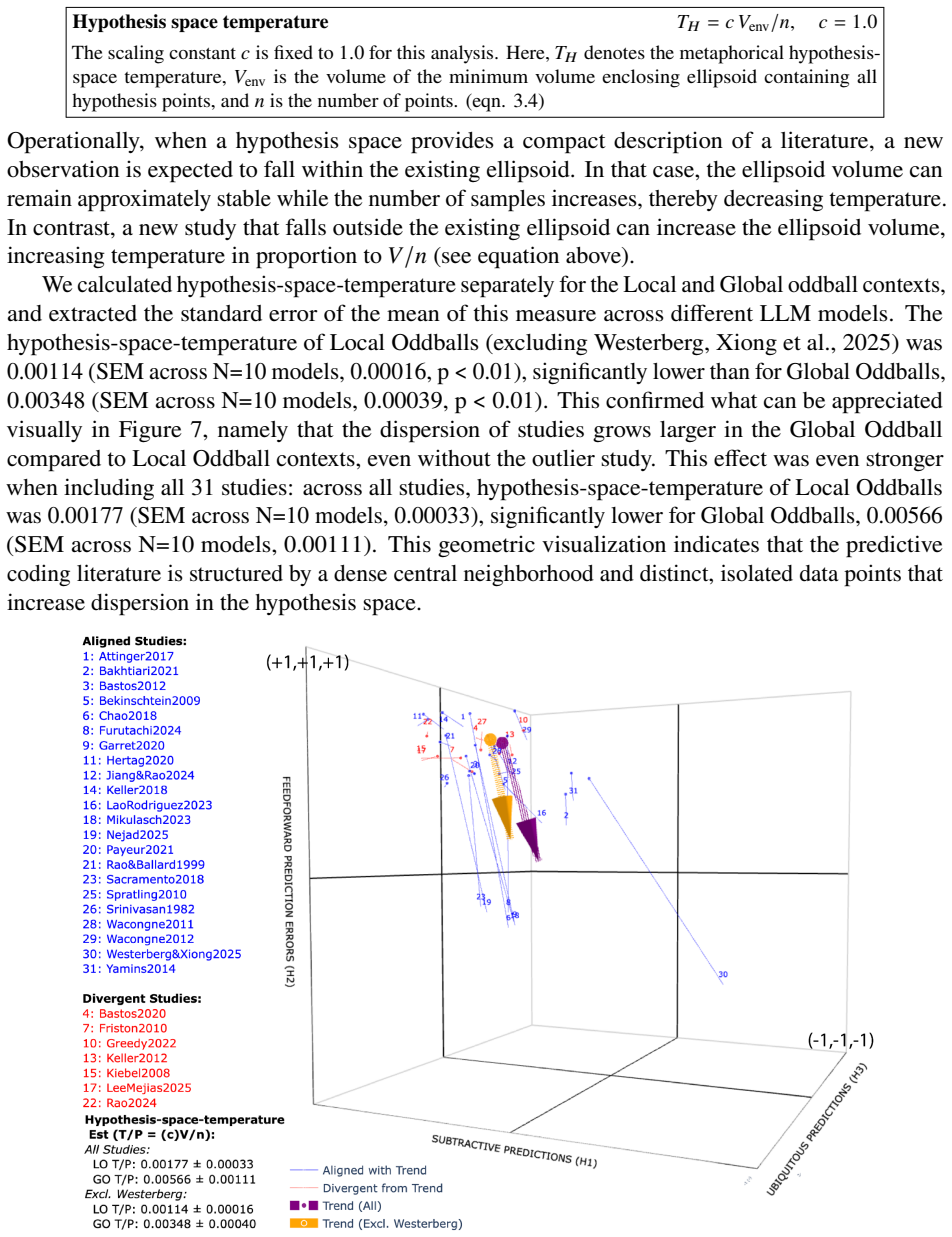
The central discovery is that a council of ten local language models, guided by an expert glossary of thirty-six concepts in the hypotheses of predictive suppression, feedforward error propagation, and ubiquity, can assign agreement scores to 31 studies across local and global oddball contexts. This yields auditable pairwise agreement data, cross-model comparisons, three-dimensional mappings of the hypothesis space, and a temperature metric for dispersion that is lower in local oddball contexts and higher in global ones, as well as vectors tracking changes between contexts.
What carries the argument
The multi-LLM scoring council constrained by the expert-defined 36-concept glossary, which serves as the common reference for evidence extraction and hypothesis scoring.
Load-bearing premise
The expert-defined 36-concept glossary is comprehensive and unbiased, and the ten local LLMs extract evidence and assign scores that faithfully reflect paper content without systematic model-specific distortions or misapplication of the ontology.
What would settle it
Running the same scoring task with human neuroscientists using the glossary on the 31 papers and observing that the LLM scores differ substantially and systematically from the human scores beyond inter-rater variability.
Figures
read the original abstract
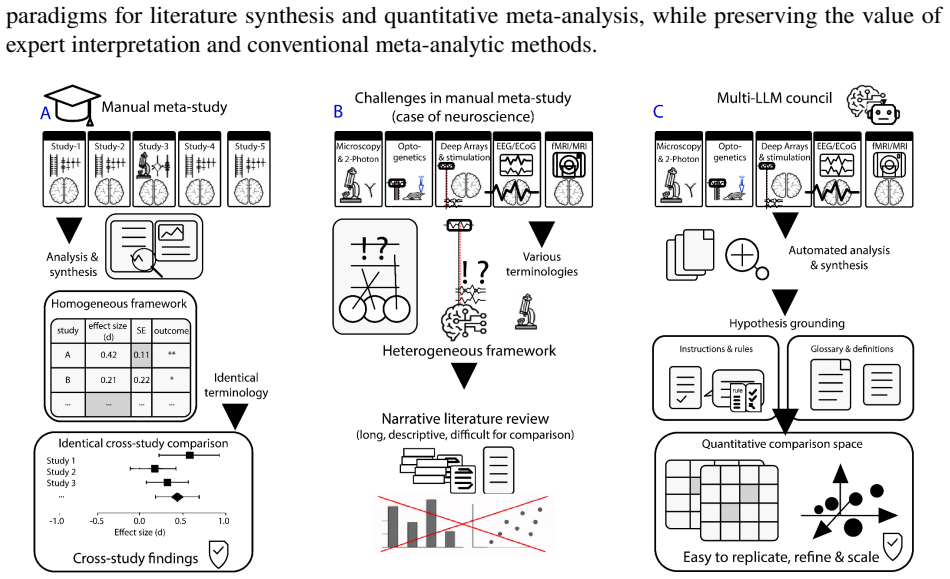
Fragmentation is common in interdisciplinary fields with diverse methods and theoretical commitments. Predictive coding neuroscience is a clear example: its literature spans computational theory, electrophysiology, imaging, behavior, and modeling, creating a synthesis problem that conventional meta-analysis cannot easily resolve. Here, we describe a local multi-LLM pipeline for ontology-constrained literature synthesis. The pipeline reads papers, extracts evidence, incorporates figure descriptions, assembles constrained prompts, and validates outputs against an expert glossary. We manually defined a predictive-coding glossary of thirty-six concepts grouped into three hypotheses: predictive suppression, feedforward error propagation, and ubiquity. A council of ten local language models scored 31 studies according to their agreement or disagreement with each glossary factor across local and global oddball contexts. This enabled pairwise study-agreement analysis, cross-model comparison, and three-dimensional hypothesis-space mapping. Agreement was high for some hypotheses but weaker for others, revealing structured disagreement, particularly across local versus global oddball paradigms. We further define hypothesis-space temperature, a geometric dispersion metric measuring how compactly studies occupy the hypothesis space. Temperature was lower for local oddball contexts and higher for global oddball contexts, indicating greater dispersion in the latter. The scoring geometry also allowed us to estimate vectors of change between experimental contexts. These results demonstrate that local multi-LLM councils can produce auditable disagreement measurements that map heterogeneous literatures into quantitative evidence spaces. This framework may generalize to cross-study hypothesis mapping where conventional meta-analysis lacks a common comparison space.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript describes an ontology-constrained multi-LLM pipeline to synthesize the predictive processing literature. It manually defines a 36-concept glossary grouped into three hypotheses (predictive suppression, feedforward error propagation, and ubiquity), uses a council of ten local LLMs to score 31 papers on agreement with these concepts in local and global oddball contexts, performs pairwise agreement analysis, and introduces a 'hypothesis-space temperature' metric as a geometric dispersion measure. The results show structured disagreement, lower temperature in local contexts, and vectors of change between contexts, claiming this maps heterogeneous literatures into quantitative evidence spaces.
Significance. If the LLM scoring is shown to be reliable, this approach could offer a novel way to quantitatively map and compare studies in fragmented fields like predictive coding neuroscience, where conventional meta-analysis struggles due to diverse methods. The geometric temperature metric provides a new tool for assessing dispersion in hypothesis spaces, and the auditable nature of the multi-LLM council is a strength. However, without validation, its significance remains potential rather than demonstrated.
major comments (3)
- [Abstract] Abstract and Methods: the pipeline description reports no quantitative validation of LLM scoring accuracy against human raters (e.g., Cohen's kappa or equivalent inter-rater metrics) and supplies no error bars on the temperature metric. This is load-bearing because the pairwise agreement, hypothesis-space temperature, and context vectors all depend on the fidelity of the 36-concept scores.
- [Methods] Methods: no details are provided on how post-hoc decisions about context or concept grouping were made, and there is no ablation on model-specific biases in interpreting concepts such as predictive suppression or feedforward error propagation. This leaves open the possibility of systematic distortions in the derived evidence space.
- [Results] Results: the claim that temperature is lower for local oddball contexts and higher for global ones rests on the untested assumption that the ten LLMs faithfully extract evidence without model-specific distortions; the geometric definition alone does not address scoring validity.
minor comments (2)
- The three-dimensional hypothesis-space mapping would benefit from an explicit equation or diagram showing how the 36-concept scores are projected into the three hypothesis axes.
- Clarify whether the expert glossary was applied strictly during prompting or allowed any post-processing adjustments.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight important aspects of validation and transparency. We address each major comment below, indicating planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract and Methods: the pipeline description reports no quantitative validation of LLM scoring accuracy against human raters (e.g., Cohen's kappa or equivalent inter-rater metrics) and supplies no error bars on the temperature metric. This is load-bearing because the pairwise agreement, hypothesis-space temperature, and context vectors all depend on the fidelity of the 36-concept scores.
Authors: We agree that the absence of direct human validation is a limitation. In the revised manuscript we will add a dedicated limitations subsection discussing this gap and outlining future human-LLM comparison protocols. We will also compute and report bootstrap-derived confidence intervals for the temperature metric and include inter-model agreement statistics as an internal reliability proxy. revision: yes
-
Referee: [Methods] Methods: no details are provided on how post-hoc decisions about context or concept grouping were made, and there is no ablation on model-specific biases in interpreting concepts such as predictive suppression or feedforward error propagation. This leaves open the possibility of systematic distortions in the derived evidence space.
Authors: We will expand the Methods section with a new subsection detailing the rationale and process for context classification and concept grouping decisions. We will additionally conduct and report an ablation study that compares per-model score distributions and discusses potential biases for key concepts. revision: yes
-
Referee: [Results] Results: the claim that temperature is lower for local oddball contexts and higher for global ones rests on the untested assumption that the ten LLMs faithfully extract evidence without model-specific distortions; the geometric definition alone does not address scoring validity.
Authors: We accept that the temperature comparison should be qualified. In revision we will rephrase the relevant Results and Discussion passages to state that the metric captures dispersion within the LLM-derived scoring space and will cross-reference the new limitations and ablation sections. Full external validation remains outside the scope of the current study. revision: partial
Circularity Check
No significant circularity; new scoring pipeline with geometrically defined metrics
full rationale
The paper defines an expert glossary of 36 concepts, applies LLM scoring constrained by that glossary to 31 papers, then computes derived quantities (pairwise agreement, hypothesis-space temperature as geometric dispersion, context vectors) directly from the resulting coordinates. Temperature is introduced as a geometric definition applied to LLM-derived positions rather than fitted or self-referential. No equations or steps reduce by construction to prior fitted parameters, self-citations, or ansatzes from the authors' prior work. The central claim is the introduction of the pipeline itself, which is self-contained against external benchmarks and does not invoke load-bearing self-citations or uniqueness theorems. This is the normal non-circular outcome for a methodological contribution.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The manually defined 36-concept glossary accurately and exhaustively captures the three target hypotheses without significant omission or bias.
- domain assumption Local language models can extract relevant evidence from papers and assign consistent agreement scores according to the glossary without introducing systematic interpretive errors.
invented entities (1)
-
hypothesis-space temperature
no independent evidence
Reference graph
Works this paper leans on
-
[1]
(Verso, London, 2002)
Feyerabend, P.Against Method: Outline of an Anarchistic Theory of Knowledge. (Verso, London, 2002). 20
2002
-
[2]
Nature650, 857–863 (2026)
Asai, A.et al.Synthesizing scientific literature with retrieval-augmented language models. Nature650, 857–863 (2026)
2026
-
[3]
Intell.1, 14 (2025)
Zhang, Y.et al.Exploring the role of large language models in the scientific method: from hypothesis to discovery.npj Artif. Intell.1, 14 (2025)
2025
-
[4]
(2025) doi:10.48550/ARXIV.2502.18878
Lu, Y.et al.Learning to Generate Structured Output with Schema Reinforcement Learning. (2025) doi:10.48550/ARXIV.2502.18878
-
[5]
Nat Hum Behav9, 305–315 (2024)
Luo, X.et al.Large language models surpass human experts in predicting neuroscience results. Nat Hum Behav9, 305–315 (2024)
2024
-
[6]
Rao,R.P.N.&Ballard,D.H.Predictivecodinginthevisualcortex: afunctionalinterpretation of some extra-classical receptive-field effects.nature neuroscience2, 79–87 (1999)
1999
-
[7]
V., Laughlin, S
Srinivasan, M. V., Laughlin, S. B. & Dubs, A. Predictive coding: a fresh view of inhibition in the retina.Proc. R. Soc. Lond., B, Biol. Sci.216, 427–459 (1982)
1982
-
[8]
H., Summerfield, C., Morin, E
Bell, A. H., Summerfield, C., Morin, E. L., Malecek, N. J. & Ungerleider, L. G. Encoding of Stimulus Probability in Macaque Inferior Temporal Cortex.Current Biology26, 2280–2290 (2016)
2016
-
[9]
B., Cadieu, C
Issa, E. B., Cadieu, C. F. & DiCarlo, J. J. Neural dynamics at successive stages of the ventral visual stream are consistent with hierarchical error signals.Elife7, (2018)
2018
-
[10]
The free-energy principle: a unified brain theory?Nature Reviews Neuroscience 11, 127–138 (2010)
Friston, K. The free-energy principle: a unified brain theory?Nature Reviews Neuroscience 11, 127–138 (2010)
2010
-
[11]
A., Shipp, S
Adams, R. A., Shipp, S. & Friston, K. J. Predictions not commands: active inference in the motor system.Brain Struct Funct218, 611–643 (2013)
2013
-
[12]
What Is Optimal about Motor Control?Neuron72, 488–498 (2011)
Friston, K. What Is Optimal about Motor Control?Neuron72, 488–498 (2011)
2011
-
[13]
T.et al.A Weighted and Directed Interareal Connectivity Matrix for Macaque Cerebral Cortex.Cereb
Markov, N. T.et al.A Weighted and Directed Interareal Connectivity Matrix for Macaque Cerebral Cortex.Cereb. Cortexhttps://doi.org/10.1093/cercor/bhs270 (2012) doi:10.1093/cercor/bhs270
-
[14]
M.et al.Canonical microcircuits for predictive coding.Neuron76, 695–711 (2012)
Bastos, A. M.et al.Canonical microcircuits for predictive coding.Neuron76, 695–711 (2012)
2012
-
[15]
Adams, R. A. Bayesian Inference, Predictive Coding, and Computational Models of Psychosis. inComputational Psychiatry175–195 (Elsevier, 2018). doi:10.1016/B978-0-12-809825- 7.00007-9
-
[16]
Sterzer, P.et al.The Predictive Coding Account of Psychosis.Biological Psychiatry84, 634–643 (2018)
2018
-
[17]
K., Suzuki, K
Seth, A. K., Suzuki, K. & Critchley, H. D. An interoceptive predictive coding model of conscious presence.Front. Psychol3, 395 (2012). 21
2012
-
[18]
& Litwin, P
Miłkowski, M. & Litwin, P. Testable or bust: theoretical lessons for predictive processing. Synthese200, 462 (2022)
2022
-
[19]
J., Nayak, A
Bowman, H., Collins, D. J., Nayak, A. K. & Cruse, D. Is predictive coding falsifiable? Neuroscience & Biobehavioral Reviews154, 105404 (2023)
2023
-
[20]
Behavioral and Brain Sciences36, 181–204 (2013)
Clark,A.Whatevernext? Predictivebrains,situatedagents,andthefutureofcognitivescience. Behavioral and Brain Sciences36, 181–204 (2013)
2013
-
[21]
(Oxford University Press, Oxford, 2013)
Hohwy, J.The Predictive Mind. (Oxford University Press, Oxford, 2013)
2013
-
[22]
Arnal, L. H. & Giraud, A.-L. Cortical oscillations and sensory predictions.Trends Cogn. Sci. (Regul. Ed.)16, 390–398 (2012)
2012
-
[23]
Keller, G. B. & Mrsic-Flogel, T. D. Predictive Processing: A Canonical Cortical Computation. Neuron100, 424–435 (2018)
2018
-
[24]
M., Lundqvist, M., Waite, A
Bastos, A. M., Lundqvist, M., Waite, A. S., Kopell, N. & Miller, E. K. Layer and rhythm specificity for predictive routing.Proc Natl Acad Sci U S A117, 31459–31469 (2020)
2020
-
[25]
C., Huang, Y
Chao, Z. C., Huang, Y. T. & Wu, C.-T. A quantitative model reveals a frequency ordering of prediction and prediction-error signals in the human brain.Commun Biol5, 1–18 (2022)
2022
-
[26]
C., Takaura, K., Wang, L., Fujii, N
Chao, Z. C., Takaura, K., Wang, L., Fujii, N. & Dehaene, S. Large-Scale Cortical Networks for Hierarchical Prediction and Prediction Error in the Primate Brain.Neuron100, 1252-1266.e3 (2018)
2018
-
[27]
Garrido,M.I.,Kilner,J.M.,Kiebel,S.J.&Friston,K.J.Evokedbrainresponsesaregenerated by feedback loops.Proc. Natl. Acad. Sci. U.S.A.104, 20961–20966 (2007)
2007
-
[28]
Kok, P., Rahnev, D., Jehee, J. F. M., Lau, H. C. & de Lange, F. P. Attention Reverses the Effect of Prediction in Silencing Sensory Signals.Cerebral Cortex22, 2197–2206 (2011)
2011
-
[29]
A.et al.Neural signature of the conscious processing of auditory regularities
Bekinschtein, T. A.et al.Neural signature of the conscious processing of auditory regularities. Proceedings of the National Academy of Sciences106, 1672–1677 (2009)
2009
-
[30]
J., van Mourik, T., Norris, D
Kok, P., Bains, L. J., van Mourik, T., Norris, D. G. & de Lange, F. P. Selective Activation of the Deep Layers of the Human Primary Visual Cortex by Top-Down Feedback.Current Biology26, 371–376 (2016)
2016
-
[31]
Kok, P., Jehee, J. F. M. & de Lange, F. P. Less is more: expectation sharpens representations in the primary visual cortex.Neuron75, 265–270 (2012)
2012
-
[32]
R.et al.Predictions and errors are distinctly represented across V1 layers.Current Biology34, 2265-2271.e4 (2024)
Thomas, E. R.et al.Predictions and errors are distinctly represented across V1 layers.Current Biology34, 2265-2271.e4 (2024)
2024
-
[33]
Xiong,Y.(Sophy)etal.Propofol-mediatedlossofconsciousnessdisruptspredictiveroutingand local field phase modulation of neural activity.Proc. Natl. Acad. Sci. U.S.A.121, e2315160121 (2024). 22
2024
-
[34]
A.et al.Hierarchical substrates of prediction in visual cortical spiking
Westerberg, J. A.et al.Hierarchical substrates of prediction in visual cortical spiking. Preprint at https://doi.org/10.1101/2024.10.02.616378 (2024)
-
[35]
& Keller, G
Zmarz, P. & Keller, G. B. Mismatch Receptive Fields in Mouse Visual Cortex.Neuron92, 766–772 (2016)
2016
-
[36]
Bastos, G.et al.Top-down input modulates visual context processing through an interneuron- specific circuit.Cell Reports42, 113133 (2023)
2023
-
[37]
P., Shymkiv, Y., Han, S., Yang, W
Hamm, J. P., Shymkiv, Y., Han, S., Yang, W. & Yuste, R. Cortical ensembles selective for context.Proc Natl Acad Sci U S A118, e2026179118 (2021)
2021
-
[38]
Nature645, 192–200 (2025)
Findling, C.et al.Brain-wide representations of prior information in mouse decision-making. Nature645, 192–200 (2025)
2025
-
[39]
Rodriguez,N.Y.,Ahuja,A.,Basu,D.,McKim,T.H.&Desrochers,T.M.DifferentSubregions of Monkey Lateral Prefrontal Cortex Respond to Abstract Sequences and Their Components. J. Neurosci.44, (2024)
2024
-
[40]
Preprint at https://doi.org/10.48550/arXiv.2504.09614 (2026)
Aizenbud, I.et al.Neural mechanisms of predictive processing: a col- laborative community experiment through the OpenScope program. Preprint at https://doi.org/10.48550/arXiv.2504.09614 (2026)
-
[41]
in (Montreal, Canada, 2024)
MulveyA.G.etal.DeficitsinGABAergicInhibitoryInterneuronsinSchizophreniaareSpecific to Cell type, Cortical layer, and Brain Region. in (Montreal, Canada, 2024)
2024
-
[42]
2025.06.13.25329541 Preprint at https://doi.org/10.1101/2025.06.13.25329541 (2026)
Cao, C.et al.Automation of Systematic Reviews with Large Language Models. 2025.06.13.25329541 Preprint at https://doi.org/10.1101/2025.06.13.25329541 (2026)
-
[43]
Li, L., Mathrani, A. & Susnjak, T. Transforming Evidence Synthesis: A Systematic Review of the Evolution of Automated Meta-Analysis in the Age of AI. Preprint at https://doi.org/10.48550/arXiv.2504.20113 (2025)
-
[44]
Song, Z.et al.Evaluating Large Language Models in Scientific Discovery.arXiv.org https://arxiv.org/abs/2512.15567v1 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
Lu, C.et al.Towards end-to-end automation of AI research.Nature651, 914–919 (2026)
2026
-
[46]
Li, J., Zhang, Q., Yu, Y., Fu, Q. & Ye, D. More Agents Is All You Need. Preprint at https://doi.org/10.48550/arXiv.2402.05120 (2024)
-
[47]
Luo, Z., Kasirzadeh, A. & Shah, N. B. The More You Automate, the Less You See: Hidden Pitfalls of AI Scientist Systems. Preprint at https://doi.org/10.48550/arXiv.2509.08713 (2025)
-
[48]
Aygün, E.et al.An AI system to help scientists write expert-level empirical software.Nature https://doi.org/10.1038/s41586-026-10658-6 (2026) doi:10.1038/s41586-026-10658-6
-
[49]
M., Xiong, Y
Gabhart, K. M., Xiong, Y. (Sophy) & Bastos, A. M. Predictive coding: a more cognitive process than we thought?Trends in Cognitive Sciences0, (2025). 23
2025
-
[50]
S., Tang, H., Sussman, E
Solomon, S. S., Tang, H., Sussman, E. & Kohn, A. Limited Evidence for Sensory Prediction Error Responses in Visual Cortex of Macaques and Humans.Cerebral Cortex31, 3136–3152 (2021)
2021
-
[51]
V.et al.Auditory Predictive Coding across Awareness States under Anesthesia: An Intracranial Electrophysiology Study.J
Nourski, K. V.et al.Auditory Predictive Coding across Awareness States under Anesthesia: An Intracranial Electrophysiology Study.J. Neurosci.38, 8441–8452 (2018)
2018
-
[52]
Wacongne, C.et al.Evidence for a hierarchy of predictions and prediction errors in human cortex.Proceedings of the National Academy of Sciences108, 20754–20759 (2011)
2011
-
[53]
Biases in the Blind Spot: Detecting What LLMs Fail to Mention
Arcuschin, I., Chanin, D., Garriga-Alonso, A. & Camburu, O.-M. Biases in the Blind Spot: Detecting What LLMs Fail to Mention.arXiv.orghttps://arxiv.org/abs/2602.10117v4 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[54]
Beatty, D., Masanthia, K., Kaphol, T. & Sethi, N. Revealing Hidden Bias in AI: Lessons from Large Language Models.arXiv.orghttps://arxiv.org/abs/2410.16927v1 (2024)
-
[55]
karpathy/llm-council
Andrej. karpathy/llm-council. (2026)
2026
-
[56]
Yang, H.et al.Large Language Model Synergy for Ensemble Learning in Medical Question Answering: Design and Evaluation Study.Journal of Medical Internet Research27, e70080 (2025)
2025
-
[57]
Li, Z., Tian, H., Luo, L., Cao, Y. & Luo, P. DeepRead: Document Structure-Aware Reasoning to Enhance Agentic Search. Preprint at https://doi.org/10.48550/arXiv.2602.05014 (2026)
-
[58]
A Prompt Pattern Catalog to Enhance Prompt Engineering with ChatGPT
White, J.et al.A Prompt Pattern Catalog to Enhance Prompt Engineering with ChatGPT. Preprint at https://doi.org/10.48550/arXiv.2302.11382 (2023)
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2302.11382 2023
-
[59]
Rao,R.P.N.&Ballard,D.H.Predictivecodinginthevisualcortex: afunctionalinterpretation of some extra-classical receptive-field effects.Nat Neurosci2, 79–87 (1999)
1999
-
[60]
& Keller, G
Attinger, A., Wang, B. & Keller, G. B. Visuomotor Coupling Shapes the Functional Develop- ment of Mouse Visual Cortex.Cell169, 1291-1302.e14 (2017)
2017
-
[61]
& Richards, B
Bakhtiari, S., Mineault, P., Lillicrap, T., Pack, C. & Richards, B. The functional specialization of visual cortex emerges from training parallel pathways with self-supervised predictive learning. inAdvances in Neural Information Processing Systemsvol. 34 25164–25178 (Curran Associates, Inc., 2021)
2021
-
[62]
A.et al.Neural signature of the conscious processing of auditory regularities
Bekinschtein, T. A.et al.Neural signature of the conscious processing of auditory regularities. Proc. Natl. Acad. Sci. U.S.A.106, 1672–1677 (2009)
2009
-
[63]
D., Aldea, A
Furutachi, S., Franklin, A. D., Aldea, A. M., Mrsic-Flogel, T. D. & Hofer, S. B. Cooperative thalamocortical circuit mechanism for sensory prediction errors.Nature633, 398–406 (2024)
2024
-
[64]
Garrett, M.et al.Experience shapes activity dynamics and stimulus coding of VIP inhibitory cells.eLife9, e50340 (2020). 24
2020
-
[65]
W., Pemberton, J., Mellor, J
Greedy, W., Zhu, H. W., Pemberton, J., Mellor, J. & Ponte Costa, R. Single-phase deep learning in cortico-cortical networks.Advances in Neural Information Processing Systems35, 24213–24225 (2022)
2022
-
[66]
eLife9, e57541 (2020)
Hertäg,L.&Sprekeler,H.Learningpredictionerrorneuronsinacanonicalinterneuroncircuit. eLife9, e57541 (2020)
2020
-
[67]
Jiang, L. P. & Rao, R. P. Dynamic predictive coding: A model of hierarchical sequence learning and prediction in the neocortex.PLOS Computational Biology20, e1011801 (2024)
2024
-
[68]
B., Bonhoeffer, T
Keller, G. B., Bonhoeffer, T. & Hübener, M. Sensorimotor mismatch signals in primary visual cortex of the behaving mouse.Neuron74, 809–815 (2012)
2012
-
[69]
J., Daunizeau, J
Kiebel, S. J., Daunizeau, J. & Friston, K. J. A Hierarchy of Time-Scales and the Brain.PLoS Comput Biol4, e1000209 (2008)
2008
-
[70]
B. Lao-Rodríguez, A.et al.Neuronal responses to omitted tones in the auditory brain: A neu- ronal correlate for predictive coding.Science Advanceshttps://doi.org/10.1126/sciadv.abq8657 (2023) doi:10.1126/sciadv.abq8657
-
[71]
Lee, K., Pennartz, C. M. A. & Mejias, J. F. Cortical networks with multiple interneuron types generate oscillatory patterns during predictive coding.PLOS Computational Biology21, e1013469 (2025)
2025
-
[72]
A., Rudelt, L., Wibral, M
Mikulasch, F. A., Rudelt, L., Wibral, M. & Priesemann, V. Where is the error? Hierarchical predictive coding through dendritic error computation.Trends in Neurosciences46, 45–59 (2023)
2023
-
[73]
K., Anastasiades, P., Hertäg, L
Nejad, K. K., Anastasiades, P., Hertäg, L. & Costa, R. P. Self-supervised predictive learning accounts for cortical layer-specificity.Nature Communications16, 6178 (2025)
2025
-
[74]
Payeur, A., Guerguiev, J., Zenke, F., Richards, B. A. & Naud, R. Burst-dependent synaptic plasticity can coordinate learning in hierarchical circuits.Nat Neurosci24, 1010–1019 (2021)
2021
-
[75]
Rao, R. P. N. A sensory–motor theory of the neocortex.Nat Neurosci27, 1221–1235 (2024)
2024
-
[76]
& Senn, W
Sacramento, J., Ponte Costa, R., Bengio, Y. & Senn, W. Dendritic cortical microcircuits approximate the backpropagation algorithm. inAdvances in Neural Information Processing Systemsvol. 31 (Curran Associates, Inc., 2018)
2018
-
[77]
Spratling, M. W. Reconciling predictive coding and biased competition models of cortical function.Front. Comput. Neurosci2, 4, (2008)
2008
-
[78]
Spratling, M. W. Predictive coding as a model of response properties in cortical area V1.J. Neurosci. Off. J. Soc. Neurosci30, 3531–3543 (2010)
2010
-
[79]
B.et al.A Role for Somatostatin-Positive Interneurons in Neuro-Oscillatory and Information Processing Deficits in Schizophrenia.Schizophrenia Bulletin47, 1385–1398 (2021)
Van Derveer, A. B.et al.A Role for Somatostatin-Positive Interneurons in Neuro-Oscillatory and Information Processing Deficits in Schizophrenia.Schizophrenia Bulletin47, 1385–1398 (2021). 25
2021
-
[80]
& Dehaene, S
Wacongne, C., Changeux, J.-P. & Dehaene, S. A Neuronal Model of Predictive Coding Accounting for the Mismatch Negativity.J. Neurosci.32, 3665–3678 (2012)
2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.