Widening the Representation Bottleneck in Neural Machine Translation with Lexical Shortcuts
Pith reviewed 2026-05-25 13:34 UTC · model grok-4.3
The pith
Gated shortcuts from the embedding layer to each transformer layer let the model access lexical content directly and improve translation quality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that the need to represent and propagate lexical features through every hidden layer in the transformer limits capacity for other task-relevant information, and that introducing gated shortcut connections between the embedding layer and each subsequent layer in the encoder and decoder removes this requirement, yielding consistent BLEU improvements on WMT tasks while measurably reducing lexical information passed along the hidden layers.
What carries the argument
Gated shortcut connections that link the embedding layer directly to each hidden layer and use learned gates to control when lexical content is injected.
If this is right
- Hidden layers can devote more of their capacity to contextual and syntactic computations instead of re-encoding word identities.
- Lexical information becomes less dominant in intermediate representations, as confirmed by the paper's analysis.
- The same modification produces gains in both the encoder and decoder across multiple language pairs.
- Different integration methods for the shortcuts can be compared through ablation, showing the gated version is effective.
Where Pith is reading between the lines
- Similar direct-access shortcuts might reduce the depth required for other sequence-to-sequence tasks that currently rely on deep stacking.
- The technique could be tested in non-translation settings such as language modeling to check whether the bottleneck diagnosis generalizes.
- If lexical features are the main repeated content, then comparable shortcuts for other low-level features like positional signals might yield further gains.
Load-bearing premise
The primary capacity limit in the transformer comes from having to repeatedly store and forward lexical features through every layer rather than from attention computation or optimization.
What would settle it
A controlled experiment that increases hidden-state dimension or layer count in the baseline transformer by the same parameter budget as the shortcuts and finds equal or larger BLEU gains without any reduction in lexical content in the hidden states.
Figures




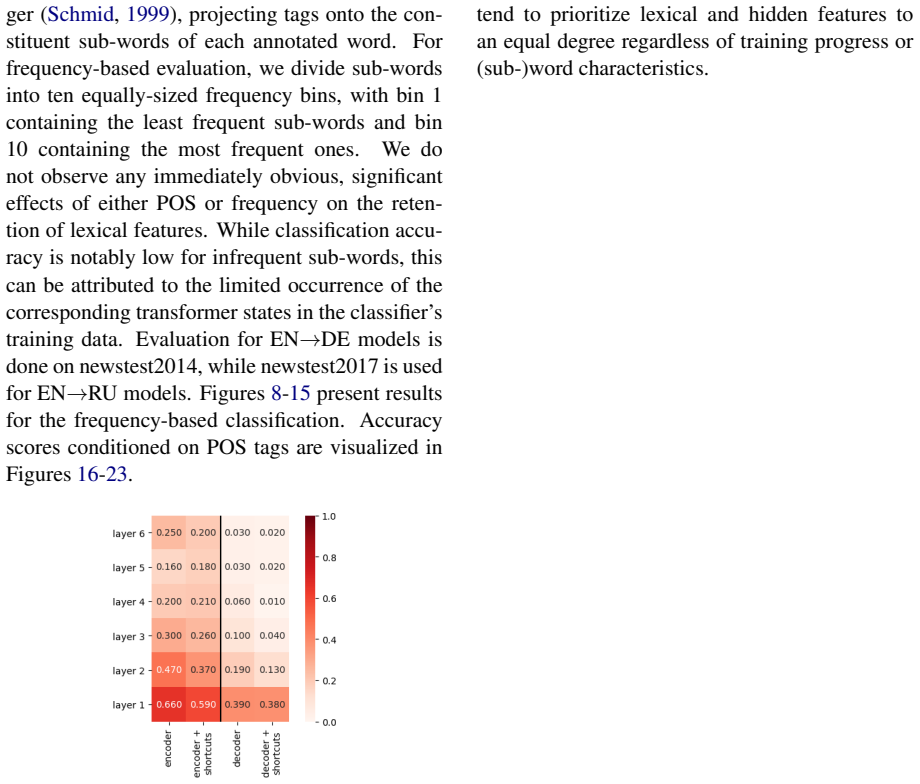









read the original abstract
The transformer is a state-of-the-art neural translation model that uses attention to iteratively refine lexical representations with information drawn from the surrounding context. Lexical features are fed into the first layer and propagated through a deep network of hidden layers. We argue that the need to represent and propagate lexical features in each layer limits the model's capacity for learning and representing other information relevant to the task. To alleviate this bottleneck, we introduce gated shortcut connections between the embedding layer and each subsequent layer within the encoder and decoder. This enables the model to access relevant lexical content dynamically, without expending limited resources on storing it within intermediate states. We show that the proposed modification yields consistent improvements over a baseline transformer on standard WMT translation tasks in 5 translation directions (0.9 BLEU on average) and reduces the amount of lexical information passed along the hidden layers. We furthermore evaluate different ways to integrate lexical connections into the transformer architecture and present ablation experiments exploring the effect of proposed shortcuts on model behavior.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper argues that the transformer NMT architecture creates a representation bottleneck by requiring lexical features to be encoded and propagated through every hidden layer. It introduces gated shortcut connections from the embedding layer directly to each subsequent encoder/decoder layer, allowing dynamic access to lexical content without storing it in intermediate states. Experiments on WMT tasks across five translation directions report an average 0.9 BLEU improvement over a baseline transformer, reduced lexical information in hidden layers, and ablations on different integration methods.
Significance. If the empirical results hold, the work demonstrates a lightweight architectural change that yields consistent gains on standard benchmarks while offering a concrete way to reallocate model capacity away from lexical repetition. The inclusion of ablation experiments on integration variants and the measurement of lexical content reduction provide useful diagnostic evidence. Strengths include evaluation on multiple language pairs with external test sets and exploration of model behavior under the proposed modification.
major comments (2)
- [§4] §4 (Experiments) and ablation subsection: the reported 0.9 BLEU gains and lexical-content reduction are consistent, but the manuscript lacks a control condition using non-lexical gated residual pathways of matched parameter count. Without this, it remains unclear whether the improvement arises specifically from bypassing lexical propagation (the central hypothesis) or from generic effects of additional residual/gating pathways.
- [§3.2] §3.2 (Gated Shortcut Connections): the gating formulation is presented as enabling dynamic lexical access, yet no capacity-ablation or layer-wise analysis quantifies how much hidden-state capacity is actually freed versus simply redistributed; this measurement is load-bearing for the claim that the modification alleviates the hypothesized bottleneck rather than adding capacity in a generic way.
minor comments (2)
- [§4.3] The lexical-information measurement procedure (used to support the reduction claim) should be described with sufficient detail for reproduction, including any auxiliary classifier or probing setup, in the main text or appendix.
- Figure 2 or equivalent (architecture diagram) would benefit from explicit annotation of the new gated paths versus standard residuals to improve clarity for readers unfamiliar with the modification.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and outline revisions that will strengthen the experimental support for our claims.
read point-by-point responses
-
Referee: [§4] §4 (Experiments) and ablation subsection: the reported 0.9 BLEU gains and lexical-content reduction are consistent, but the manuscript lacks a control condition using non-lexical gated residual pathways of matched parameter count. Without this, it remains unclear whether the improvement arises specifically from bypassing lexical propagation (the central hypothesis) or from generic effects of additional residual/gating pathways.
Authors: We agree that a matched-parameter control using non-lexical gated residuals would more cleanly isolate whether gains stem from lexical bypassing rather than the addition of gated pathways per se. Our existing ablations compare integration variants of the lexical shortcuts but do not include this non-lexical baseline. In the revised manuscript we will add the requested control condition, using random or position-based embeddings in place of lexical ones while preserving parameter count and gating structure. revision: yes
-
Referee: [§3.2] §3.2 (Gated Shortcut Connections): the gating formulation is presented as enabling dynamic lexical access, yet no capacity-ablation or layer-wise analysis quantifies how much hidden-state capacity is actually freed versus simply redistributed; this measurement is load-bearing for the claim that the modification alleviates the hypothesized bottleneck rather than adding capacity in a generic way.
Authors: We acknowledge that the current manuscript reports an overall reduction in lexical content within hidden states but does not supply a quantitative layer-wise breakdown of freed versus redistributed capacity. To address this, the revision will include additional layer-wise probes (e.g., lexical probe accuracy per encoder/decoder layer) comparing the baseline and shortcut models, together with a short discussion of how the observed reductions support the bottleneck-alleviation interpretation. revision: yes
Circularity Check
No significant circularity; results measured on external benchmarks
full rationale
The paper proposes gated lexical shortcuts motivated by a hypothesis on representation bottlenecks in transformers, then reports empirical BLEU gains (0.9 average) and reduced lexical content on standard WMT test sets across 5 directions. These outcomes are evaluated against independent held-out data rather than being derived from internally fitted parameters or self-citations by construction. No load-bearing step reduces to a self-definition, renamed known result, or ansatz smuggled via citation; the evaluation chain remains falsifiable outside the paper's own quantities.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Lexical features must be represented and propagated through every layer of a standard transformer
invented entities (1)
-
gated shortcut connections
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Ankur Bapna, Mia Xu Chen, Orhan Firat, Yuan Cao, and Yonghui Wu. 2018. Training deeper neural machine translation models with transparent attention. arXiv preprint arXiv:1808.07561
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[2]
Yonatan Belinkov, Nadir Durrani, Fahim Dalvi, Hassan Sajjad, and James Glass. 2017. What do neural machine translation models learn about morphology? arXiv preprint arXiv:1704.03471
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[3]
Yonatan Belinkov, Llu \' s M \`a rquez, Hassan Sajjad, Nadir Durrani, Fahim Dalvi, and James Glass. 2018. Evaluating layers of representation in neural machine translation on part-of-speech and semantic tagging tasks. arXiv preprint arXiv:1801.07772
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[4]
Ondřej Bojar, Christian Federmann, Mark Fishel, Yvette Graham, Barry Haddow, Matthias Huck, Philipp Koehn, and Christof Monz. 2018. http://www.aclweb.org/anthology/W18-64028 Findings of the 2018 conference on machine translation (wmt18) . In Proceedings of the Third Conference on Machine Translation, pages 272--307, Belgium, Brussels. Association for Comp...
work page 2018
-
[5]
Mia Xu Chen, Orhan Firat, Ankur Bapna, Melvin Johnson, Wolfgang Macherey, George Foster, Llion Jones, Niki Parmar, Mike Schuster, Zhifeng Chen, et al. 2018. The best of both worlds: Combining recent advances in neural machine translation. arXiv preprint arXiv:1804.09849
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[6]
Kyunghyun Cho, Bart Van Merri \"e nboer, Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. 2014. Learning phrase representations using rnn encoder-decoder for statistical machine translation. arXiv preprint arXiv:1406.1078
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[7]
Yann N Dauphin, Angela Fan, Michael Auli, and David Grangier. 2017. Language modeling with gated convolutional networks. In Proceedings of the 34th International Conference on Machine Learning-Volume 70, pages 933--941. JMLR. org
work page 2017
-
[8]
Mostafa Dehghani, Stephan Gouws, Oriol Vinyals, Jakob Uszkoreit, and ukasz Kaiser. 2018. Universal transformers. arXiv preprint arXiv:1807.03819
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[9]
Zi-Yi Dou, Zhaopeng Tu, Xing Wang, Shuming Shi, and Tong Zhang. 2018. Exploiting deep representations for neural machine translation. arXiv preprint arXiv:1810.10181
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[10]
Klaus Greff, Rupesh K Srivastava, and J \"u rgen Schmidhuber. 2016. Highway and residual networks learn unrolled iterative estimation. arXiv preprint arXiv:1612.07771
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[11]
Barry Haddow, Nikolay Bogoychev, Denis Emelin, Ulrich Germann, Roman Grundkiewicz, Kenneth Heafield, Antonio Valerio Miceli Barone, and Rico Sennrich. 2018. http://www.aclweb.org/anthology/W18-64039 The university of edinburgh’s submissions to the wmt18 news translation task . In Proceedings of the Third Conference on Machine Translation, pages 403--413, ...
work page 2018
-
[12]
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770--778
work page 2016
-
[13]
Gao Huang, Zhuang Liu, Laurens Van Der Maaten, and Kilian Q Weinberger. 2017. Densely connected convolutional networks. In CVPR, 2, page 3
work page 2017
-
[14]
Andrej Karpathy, Justin Johnson, and Li Fei-Fei. 2015. Visualizing and understanding recurrent networks. arXiv preprint arXiv:1506.02078
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[15]
Diederik P Kingma and Jimmy Ba. 2014. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[16]
Shaohui Kuang, Junhui Li, Ant \'o nio Branco, Weihua Luo, and Deyi Xiong. 2017. Attention focusing for neural machine translation by bridging source and target embeddings. arXiv preprint arXiv:1711.05380
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[17]
Chen-Yu Lee, Saining Xie, Patrick Gallagher, Zhengyou Zhang, and Zhuowen Tu. 2015. Deeply-supervised nets. In Artificial Intelligence and Statistics, pages 562--570
work page 2015
-
[18]
Toan Q Nguyen and David Chiang. 2017. Improving lexical choice in neural machine translation. arXiv preprint arXiv:1710.01329
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[19]
Matt Post. 2018. A call for clarity in reporting bleu scores. arXiv preprint arXiv:1804.08771
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[20]
Ofir Press and Lior Wolf. 2016. Using the output embedding to improve language models. arXiv preprint arXiv:1608.05859
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[21]
Peng Qian, Xipeng Qiu, and Xuanjing Huang. 2016. Analyzing linguistic knowledge in sequential model of sentence. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pages 826--835
work page 2016
-
[22]
Annette Rios, Laura Mascarell, and Rico Sennrich. 2017. Improving word sense disambiguation in neural machine translation with sense embeddings. In Proceedings of the 2nd Conference on Machine Translation, Copenhagen, Denmark
work page 2017
-
[23]
Danielle Saunders, Felix Stahlberg, Adria de Gispert, and Bill Byrne. 2018. Multi-representation ensembles and delayed sgd updates improve syntax-based nmt. arXiv preprint arXiv:1805.00456
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[24]
Helmut Schmid. 1999. Improvements in part-of-speech tagging with an application to german. In Natural language processing using very large corpora, pages 13--25. Springer
work page 1999
-
[25]
Rico Sennrich, Barry Haddow, and Alexandra Birch. 2015. Neural machine translation of rare words with subword units. arXiv preprint arXiv:1508.07909
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[26]
Xing Shi, Inkit Padhi, and Kevin Knight. 2016. Does string-based neural mt learn source syntax? In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pages 1526--1534
work page 2016
-
[27]
Nitish Srivastava, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov. 2014. Dropout: a simple way to prevent neural networks from overfitting. The Journal of Machine Learning Research, 15(1):1929--1958
work page 2014
-
[28]
Rupesh Kumar Srivastava, Klaus Greff, and J \"u rgen Schmidhuber. 2015. Highway networks. arXiv preprint arXiv:1505.00387
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[29]
Gongbo Tang, Mathias M \"u ller, Annette Rios, and Rico Sennrich. 2018. Why self-attention? a targeted evaluation of neural machine translation architectures. arXiv preprint arXiv:1808.08946
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[30]
Ashish Vaswani, Samy Bengio, Eugene Brevdo, Francois Chollet, Aidan N Gomez, Stephan Gouws, Llion Jones, ukasz Kaiser, Nal Kalchbrenner, Niki Parmar, et al. 2018. Tensor2tensor for neural machine translation. arXiv preprint arXiv:1803.07416
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[31]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, ukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Advances in Neural Information Processing Systems, pages 5998--6008
work page 2017
-
[32]
Lijun Wu, Fei Tian, Li Zhao, Jianhuang Lai, and Tie-Yan Liu. 2018. Word attention for sequence to sequence text understanding. In Thirty-Second AAAI Conference on Artificial Intelligence
work page 2018
-
[33]
ENTRY address author booktitle chapter edition editor howpublished institution journal key month note number organization pages publisher school series title type volume year eprint doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRINGS urlintro eprinturl eprintpr...
-
[34]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.