Manifold Bandits: Bayesian Curriculum Learning over the Latent Geometry of Large Language Models
Pith reviewed 2026-06-26 18:27 UTC · model grok-4.3
The pith
Problem sampling as a manifold bandit with Bayesian learning over a hierarchical task tree improves LLM training beyond difficulty prioritization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
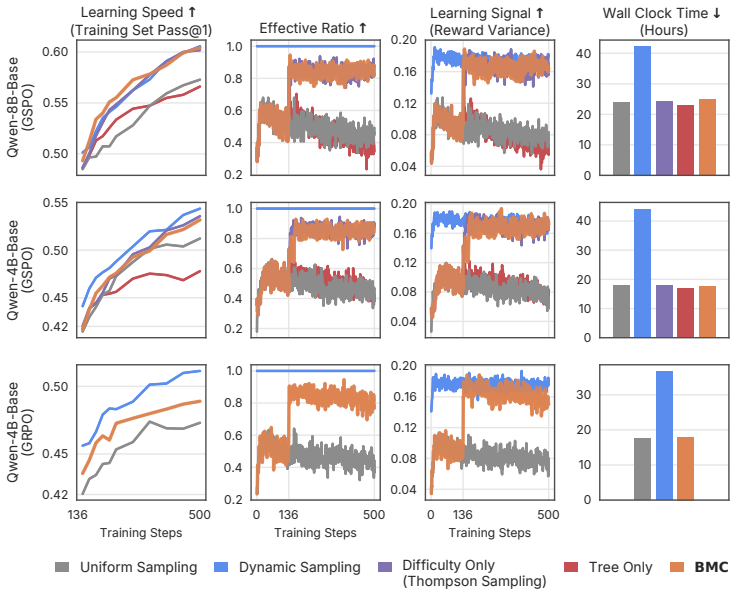
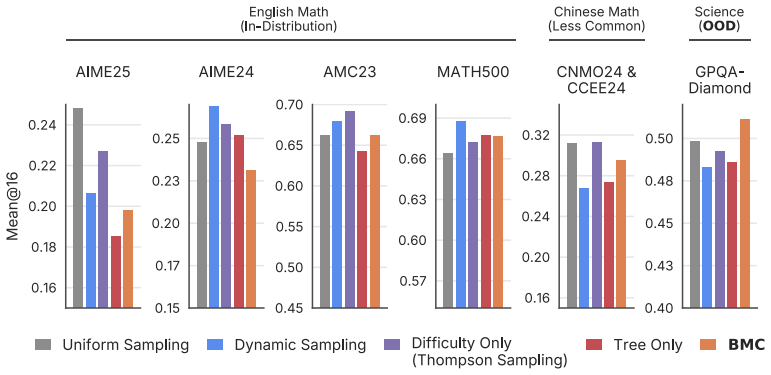
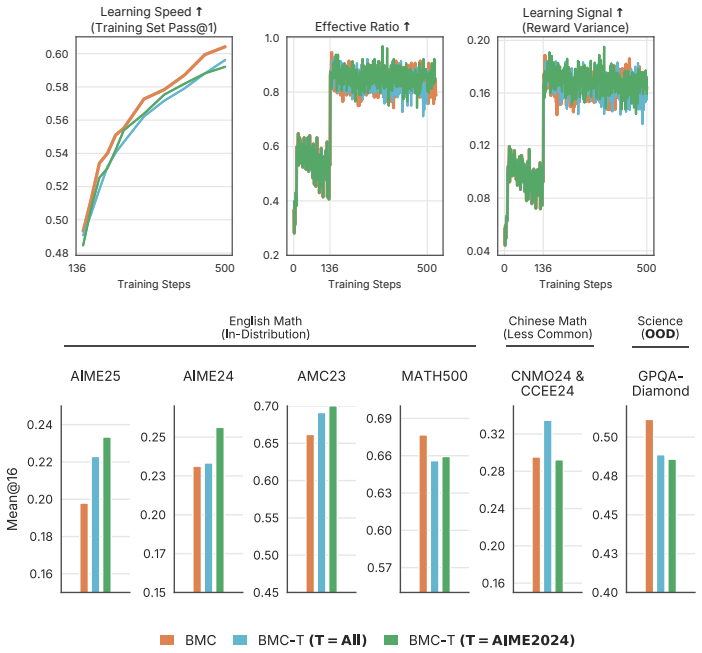
Framing problem sampling as a manifold-structured bandit problem with endogenous non-stationarity allows Bayesian learning to steer learning signals across the latent space, and empirical results show that structure-aware sampling outperforms difficulty-only methods by balancing multiple objectives.
What carries the argument
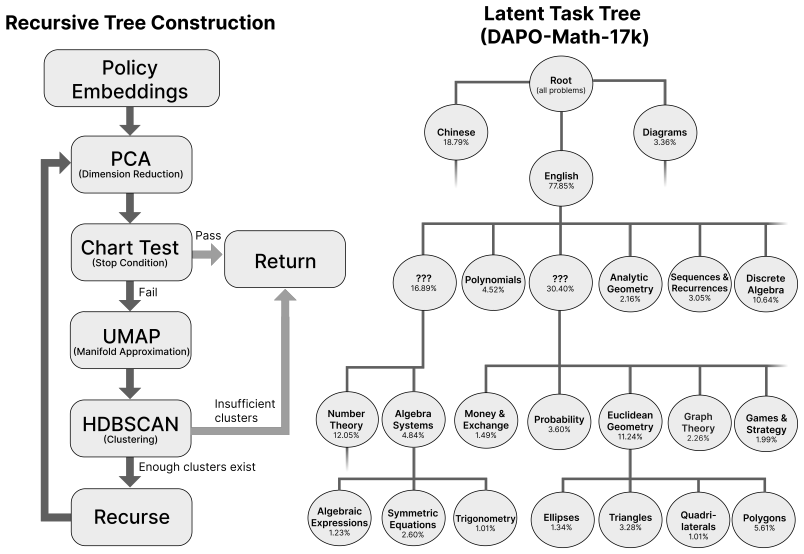
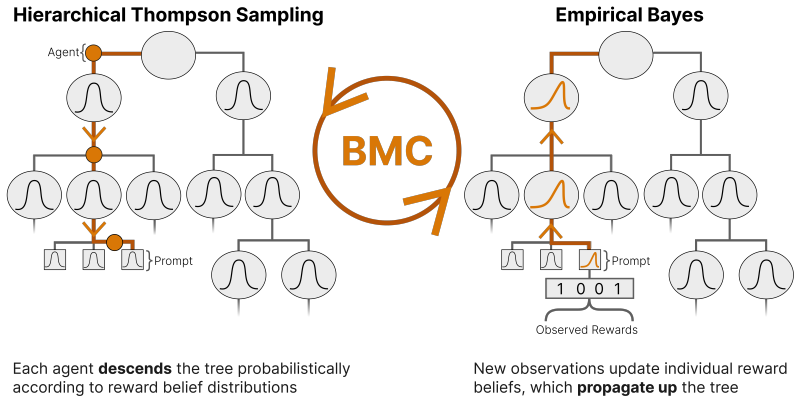
Bayesian Manifold Curriculum (BMC) organizes problems into a hierarchical task tree and uses Bayesian learning to guide sampling decisions over the manifold of the model's latent representations.
If this is right
- Different sampling strategies induce tradeoffs between productivity, diversity, and utility.
- Prioritizing difficulty alone is insufficient for strong downstream performance.
- Incorporating structure and type-awareness into problem sampling improves results.
- Sampling decisions can steer how learning signals evolve across the task manifold.
Where Pith is reading between the lines
- Extending this to other RL settings beyond LLMs might reveal similar manifold structures in task spaces.
- Testing BMC on different model scales could show how the latent geometry changes with model size.
- The hierarchical task tree construction might be generalized to automatic discovery without manual organization.
Load-bearing premise
Problems are related through the model's latent representation space in a manifold structure that can be organized into a hierarchical task tree, allowing sampling decisions to steer learning signals in a way Bayesian learning can exploit.
What would settle it
A controlled experiment where a standard difficulty-based curriculum achieves equivalent or better downstream performance than BMC on the same tasks would falsify the claim that structure and type-awareness are necessary.
Figures
















read the original abstract
Reinforcement learning (RL) is a central approach for improving reasoning capabilities in large language models (LLMs), where training efficiency depends critically on how problems are sampled during optimization. Existing adaptive curriculum learning methods typically prioritize prompts of intermediate difficulty, treating problem selection as a standard bandit problem with independent arms and overlooking the structured, heterogeneous nature of the task space. In this work, we frame problem sampling as a manifold-structured bandit problem with endogenous non-stationarity: problems are related through the model's latent representation space, and sampling decisions can steer how learning signals evolve across that space. To operationalize this perspective, we introduce Bayesian Manifold Curriculum (BMC), a structure-aware framework that organizes problems into a hierarchical task tree and applies Bayesian learning to guide sampling. Empirically, we find that different sampling strategies induce non-trivial tradeoffs between productivity (learning signal), diversity (coverage of the task manifold), and utility (evaluation relevance). These results show that prioritizing difficulty alone is insufficient for strong downstream performance, highlighting the importance of incorporating structure and type-awareness into problem sampling.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper frames problem sampling for RL-based LLM reasoning improvement as a manifold-structured bandit problem with endogenous non-stationarity, where problems relate via the model's latent representation space. It introduces Bayesian Manifold Curriculum (BMC), which organizes problems into a hierarchical task tree and applies Bayesian learning for sampling guidance. The central empirical claim is that sampling strategies induce tradeoffs among productivity, diversity, and utility, such that difficulty-only prioritization is insufficient and structure/type-awareness yields stronger downstream performance.
Significance. If the empirical tradeoffs and attribution to manifold structure hold, the work would be significant for curriculum learning in LLMs by moving beyond independent-arm bandits to geometry-aware sampling. No machine-checked proofs, reproducible code, or parameter-free derivations are described.
major comments (2)
- [Abstract] Abstract: The claim that 'different sampling strategies induce non-trivial tradeoffs between productivity (learning signal), diversity (coverage of the task manifold), and utility' and that 'prioritizing difficulty alone is insufficient' is presented without any quantitative results, baselines, error bars, dataset details, or experimental protocol. This is load-bearing for the conclusion that manifold structure and type-awareness improve performance.
- [Abstract] Abstract: The modeling choice that 'problems are related through the model's latent representation space' and can be 'organized into a hierarchical task tree' for Bayesian updates is stated without construction details, validation that the tree reflects genuine task geometry (vs. imposed clustering), or ablation showing the Bayesian manifold component outperforms non-manifold adaptive baselines. This is load-bearing for attributing any gains to the proposed structure.
Simulated Author's Rebuttal
We thank the referee for their detailed feedback on the abstract claims and modeling choices. We address each major comment below, noting that the full manuscript contains the supporting experimental details and method descriptions, but we agree the abstract can be strengthened for self-containment.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that 'different sampling strategies induce non-trivial tradeoffs between productivity (learning signal), diversity (coverage of the task manifold), and utility' and that 'prioritizing difficulty alone is insufficient' is presented without any quantitative results, baselines, error bars, dataset details, or experimental protocol. This is load-bearing for the conclusion that manifold structure and type-awareness improve performance.
Authors: We agree the abstract, due to length constraints, summarizes the empirical findings at a high level without including specific quantitative results or protocol details. These are fully reported with baselines, error bars, datasets, and protocols in the Experiments section. The claims are supported by those results. We will revise the abstract to include a concise mention of key empirical outcomes to better ground the statements. revision: yes
-
Referee: [Abstract] Abstract: The modeling choice that 'problems are related through the model's latent representation space' and can be 'organized into a hierarchical task tree' for Bayesian updates is stated without construction details, validation that the tree reflects genuine task geometry (vs. imposed clustering), or ablation showing the Bayesian manifold component outperforms non-manifold adaptive baselines. This is load-bearing for attributing any gains to the proposed structure.
Authors: Construction of the latent-space embeddings, hierarchical task tree, and Bayesian update procedure are detailed in the Method section, along with validation experiments and ablations versus non-manifold adaptive baselines in the Experiments section. These elements attribute performance gains to the manifold-aware components. We will revise the abstract to briefly note that full construction and validation details appear in the main text. revision: partial
Circularity Check
No significant circularity detected; modeling choices presented without self-referential reductions
full rationale
The abstract and description introduce BMC as a structure-aware framework that organizes problems into a hierarchical task tree and applies Bayesian learning to guide sampling, framing the task space as manifold-structured with endogenous non-stationarity. No equations, fitted parameters, predictions that reduce to inputs by construction, or load-bearing self-citations are visible. The claims about tradeoffs between productivity, diversity, and utility, and the insufficiency of difficulty-only sampling, are presented as empirical observations without any derivation step that equates outputs to the modeling assumptions themselves. The paper's central premise relies on external validation of the manifold and tree structure rather than internal self-definition, making the derivation self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
URLhttps://openreview.net/forum?id=8HvWBamUkS. Dana Arad, Aaron Mueller, and Yonatan Belinkov. Saes are good for steering – if you select the right features. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, page 10252–10270. Association for Computational Linguistics, 2025. doi: 10.18653/v1/2025.emnlp-main.519. URLh...
-
[2]
Correlated bandits or: How to minimize mean-squared error online
URLhttps://arxiv.org/abs/1902.02953. Sébastien Bubeck, Rémi Munos, and Gilles Stoltz. Pure exploration for multi-armed bandit problems, 2010. URLhttps://arxiv.org/abs/0802.2655. Ricardo J. G. B. Campello, Davoud Moulavi, and Joerg Sander. Density-based clustering based on hierarchical density estimates. In Jian Pei, Vincent S. Tseng, Longbing Cao, Hiroshi...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1109/tit.2021.3081508 1902
-
[3]
Zirui He, Haiyan Zhao, Yiran Qiao, Fan Yang, Ali Payani, Jing Ma, and Mengnan Du
URLhttps://arxiv.org/abs/2310.16828. Zirui He, Haiyan Zhao, Yiran Qiao, Fan Yang, Ali Payani, Jing Ma, and Mengnan Du. Saif: A sparse autoencoder framework for interpreting and steering instruction following of language models, 2025. URL https://arxiv.org/abs/2502.11356. Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, D...
Pith/arXiv arXiv 2025
-
[4]
Guochao Jiang, Wenfeng Feng, Guofeng Quan, Chuzhan Hao, Yuewei Zhang, Guohua Liu, and Hao Wang
URLhttps://arxiv.org/abs/2506.08725. Guochao Jiang, Wenfeng Feng, Guofeng Quan, Chuzhan Hao, Yuewei Zhang, Guohua Liu, and Hao Wang. Vcrl: Variance-based curriculum reinforcement learning for large language models.arXiv preprint arXiv:2509.19803, 2025. Xia Jiang and Rong J. B. Zhu. Empirical bayesian multi-bandit learning, 2025. URL https://arxiv.org/ abs...
arXiv 2025
-
[5]
Ilia Mahrooghi, Aryo Lotfi, and Emmanuel Abbe
Notion Blog. Ilia Mahrooghi, Aryo Lotfi, and Emmanuel Abbe. Goldilocks rl: Tuning task difficulty to escape sparse rewards for reasoning, 2026. URLhttps://arxiv.org/abs/2602.14868. Tambet Matiisen, Avital Oliver, Taco Cohen, and John Schulman. Teacher-student curriculum learning, 2017. URLhttps://arxiv.org/abs/1707.00183. Maxwell-Jia. Aime 2024 dataset.ht...
Pith/arXiv arXiv 2026
-
[6]
Ankit Pal, Logesh Kumar Umapathi, and Malaikannan Sankarasubbu
Hugging Face dataset, v202412. Ankit Pal, Logesh Kumar Umapathi, and Malaikannan Sankarasubbu. Medmcqa : A large-scale multi-subject multi-choice dataset for medical domain question answering, 2022. URL https://arxiv.org/abs/2203. 14371. Sandeep Pandey, Deepak Agarwal, Deepayan Chakrabarti, and Vanja Josifovski. Bandits for taxonomies: A model-based appro...
arXiv 2022
-
[7]
Xinyu Tang, Zhenduo Zhang, Yurou Liu, Wayne Xin Zhao, Zujie Wen, Zhiqiang Zhang, and Jun Zhou
Accessed: 2026-05-04. Xinyu Tang, Zhenduo Zhang, Yurou Liu, Wayne Xin Zhao, Zujie Wen, Zhiqiang Zhang, and Jun Zhou. Towards high data efficiency in reinforcement learning with verifiable reward, 2025. URL https://arxiv.org/ abs/2509.01321. Gemma Team, Thomas Mesnard, Cassidy Hardin, Robert Dadashi, Surya Bhupatiraju, Shreya Pathak, Laurent Sifre, Morgane...
arXiv 2026
-
[8]
Manning, Peter Hender- son, and Daniel E
URLhttps://arxiv.org/abs/2510.19178. Zhenda Xie, Yixuan Wei, Huanqi Cao, Chenggang Zhao, Chengqi Deng, Jiashi Li, Damai Dai, Huazuo Gao, Jiang Chang, Liang Zhao, et al. mhc: Manifold-constrained hyper-connections.arXiv preprint arXiv:2512.24880, 2025. An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huan...
-
[9]
bandit pattern
show that token input embeddings can contain singularities and non-constant local dimension, violating the requirements of a smooth global manifold. We view this as a critique of a strongglobal manifold assumption, whereas BMC adopts a weaker operational view: prompt representations need only exhibit enoughlocalgeometric regularity to support neighborhood...
2025
-
[10]
assign each promptx i an estimated learning valuev i
-
[11]
initialize{v i}N i=1 uniformly or from a prior model
-
[12]
for each training stept: (a) sample a batch of individual prompts according to their estimated values, often without replacement; (b) generate rollouts and observe rewards for the sampled prompts; (c) update the values of the sampled prompts using the observed rollout rewards
-
[13]
difficulty awareness,
repeat as the policy evolves. The standard bandit pattern is therefore a strong mechanism for improving sampling productivity, but it does not explicitly control several dimensions that can be important when training LLMs on broad, heterogeneous mixtures. In particular, it does not directly controldiversityover problem types orutilityrelative to a target ...
2025
-
[14]
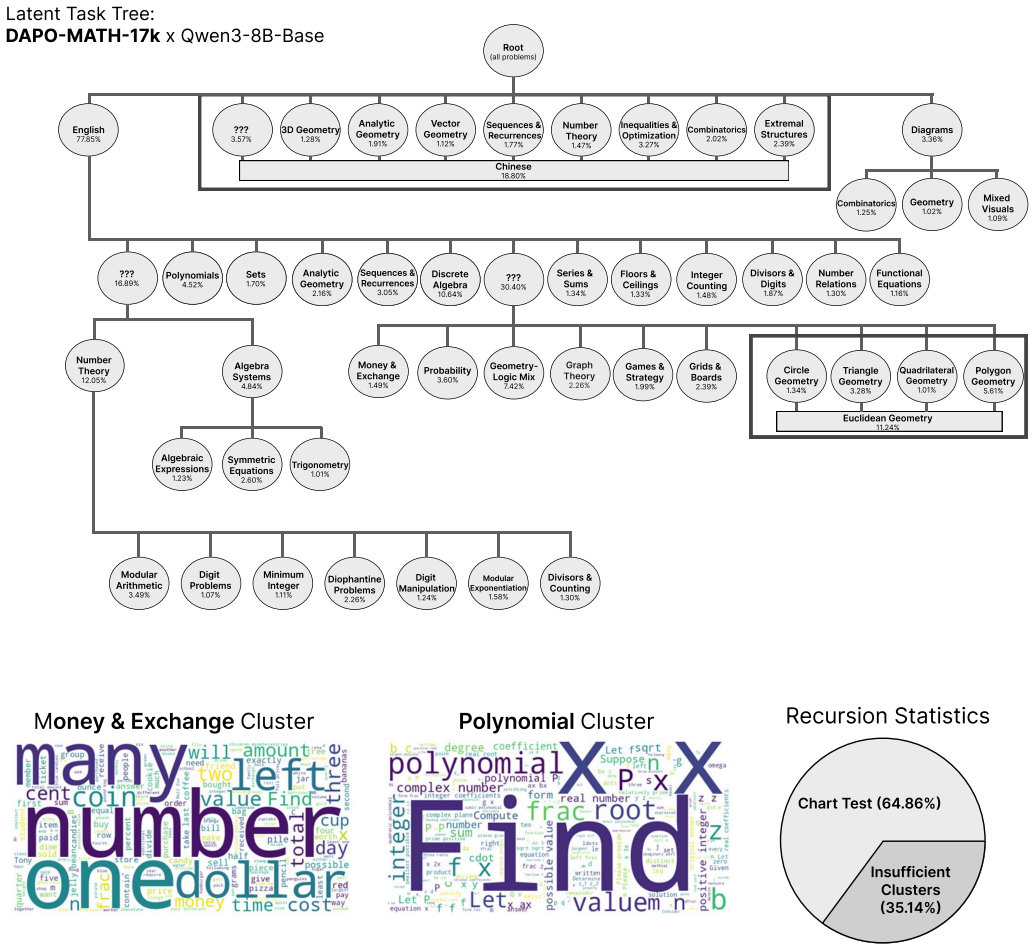
0 2% E x tr ema l S tructur e s
-
[15]
3 6 % C om b inat orics 1 .25% Geometr y 1
39% Diagr am s 3 . 3 6 % C om b inat orics 1 .25% Geometr y 1 . 0 2% M i x e d Visual s 1 . 0 9% ??? 16 . 89% P olynomials 4 . 52% P olynomials 4 . 52% ??? 30 .40% S et s 1 . 7 0% Analytic Geometr y
-
[16]
34% Sequences & R ecurr ences 3
16% Series & Sums 1 . 34% Sequences & R ecurr ences 3 . 05% Sequences & R ecurr ences 3 . 05% Discr et e Algebr a 10 . 64% Discr et e Algebr a 10 . 64% ??? 3 0 .4 0 % S eries & S um s 1 . 34% F loors & C eiling s 1 . 33% I nt eger C ountin g 1 .48% Di v isors & Digit s 1 . 87% Number R elation s 1 . 3 0 % F unctiona l E q uation s 1 . 1 6 % N umbe r Theor y
-
[17]
8 4% Mone y & Ex change 1 .49% P r obability 3
05% Algebr a Syst ems 4 . 8 4% Mone y & Ex change 1 .49% P r obability 3 . 60% Geometr y - L ogic Mi x 7 .42% Gr aph Theor y 2.26% Games & Str at egy 1 . 99% Grids & Boar ds
-
[18]
34% T riangle Geometr y 3 .2 8 % Quad ri la t er al G eometr y 1
39% C ir cle Geometr y 1 . 34% T riangle Geometr y 3 .2 8 % Quad ri la t er al G eometr y 1 . 01% Eucli d ean Geometr y 11 .2 4% P oly go n Geometr y 5 . 61% Algebr aic Expr essions 1 .23% Symmetric Equations
-
[19]
01% M o d ular Arit hmeti c 3 .49% Digit P r oblem s 1
60% T rigonometr y 1 . 01% M o d ular Arit hmeti c 3 .49% Digit P r oblem s 1 . 0 7% M inimu m I nt eger 1 . 11% Dio p hantin e P r oblem s 2.2 6 % Digit Manipulation 1 .2 4% Modular Exponentiation 1 . 58% Di v isors & C ountin g 1 . 3 0 % M one y & Ex change Clust er P olynomial Clust er R e cu rs io n S tat i st ic s C har t T est (64 . 86%) I nsu ff ic...
-
[20]
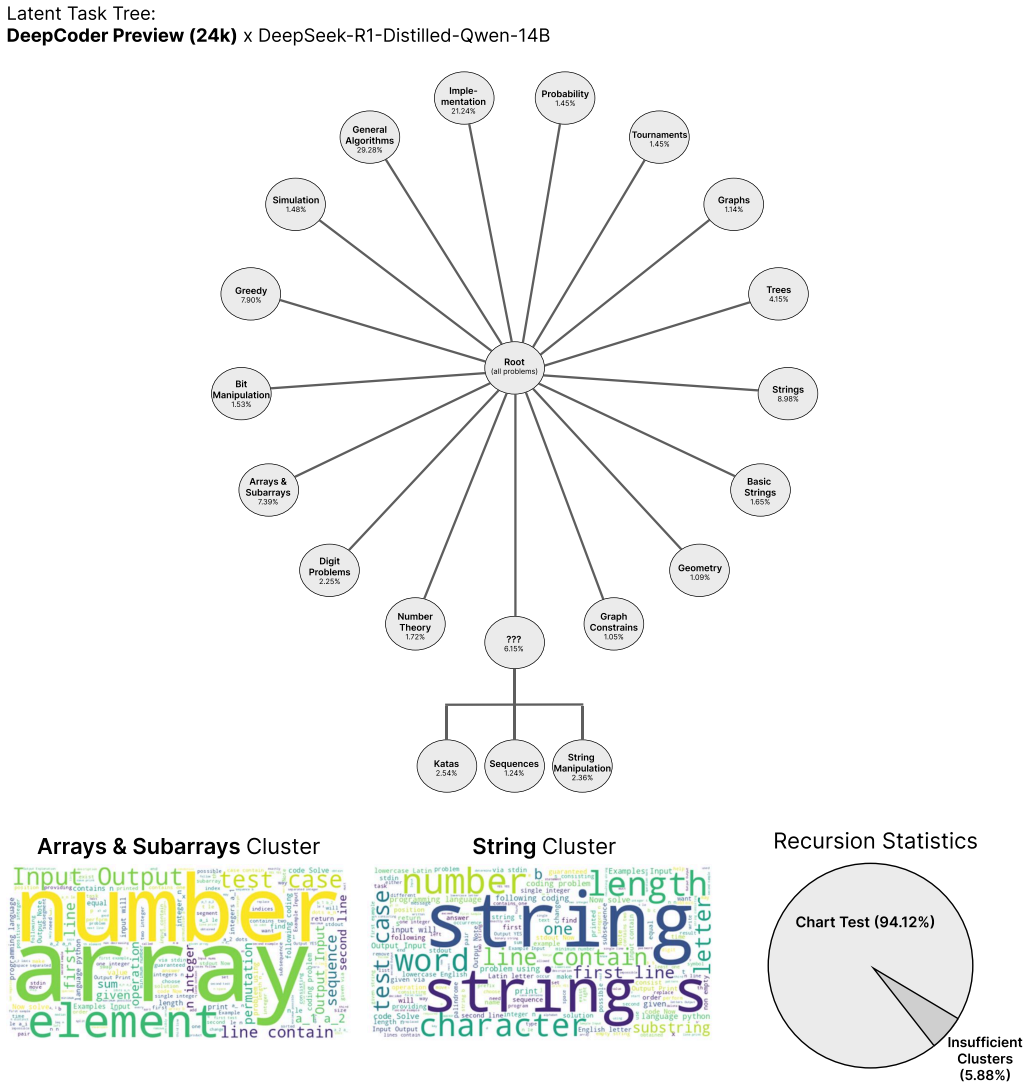
54% Sequences 1 .2 4% String Manipulation
-
[21]
12%) Insufficient Clust ers (5
36% Arr a ys & Subarr a ys Clust er String Clust er R e cu rsi o n Statisti c s Char t T est (94 . 12%) Insufficient Clust ers (5 . 88%) Figure 13.Latent Task Tree forDeepCoder-Preview-Dataset[Luo et al., 2025] using DeepSeek- R1-Distilled-Qwen-14B’s latent space.The dataset consists of 24K coding problems. The induced tree contains 49 nodes. On one node ...
2025
-
[22]
14% Mechanisms 48
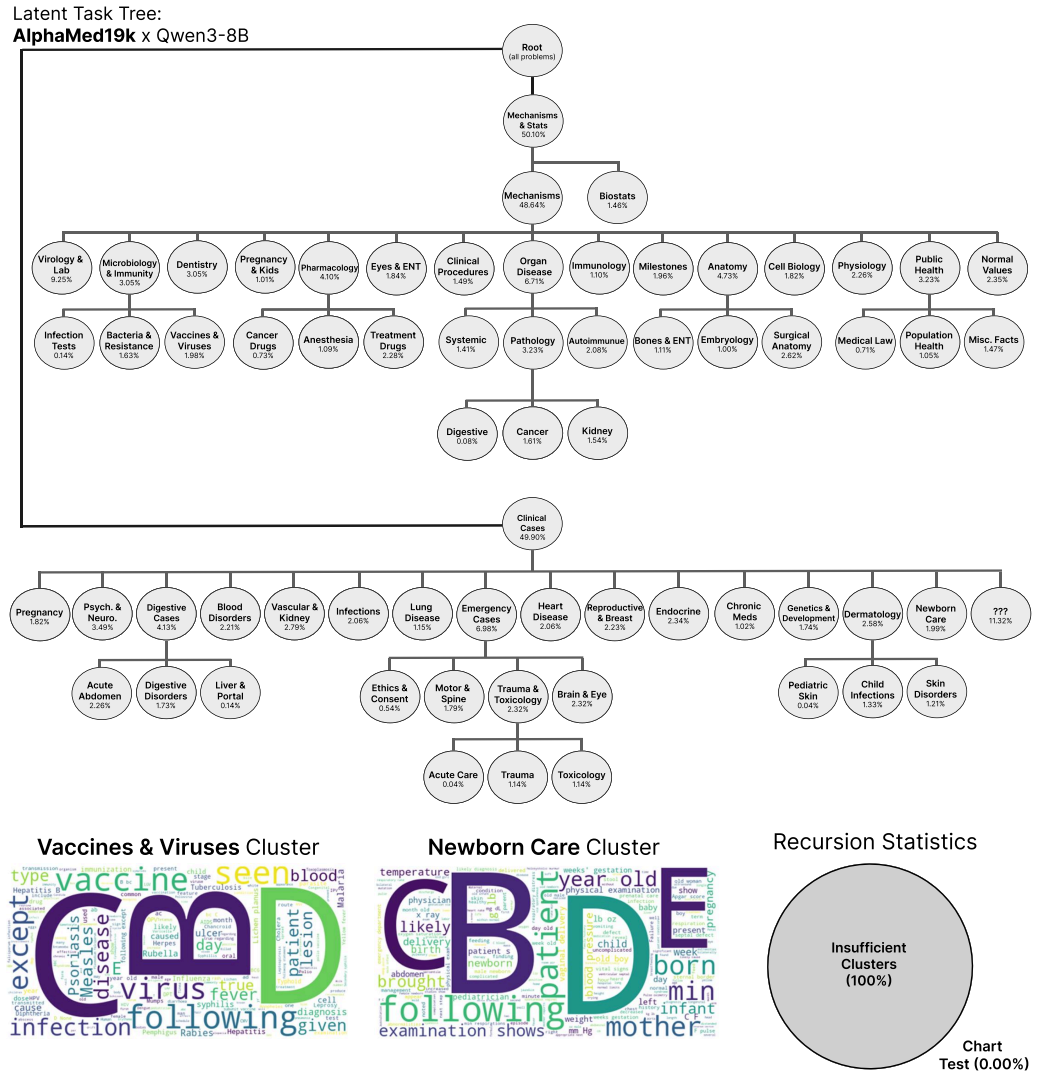
35% I n f ectio n T est s 0 . 14% Mechanisms 48 . 64% Bact eria & R esistance 1 . 63% V accines & V iruses 1 . 98% Cancer Drugs 0 . 7 3% XXX xx.xx% Mechanisms 48 . 64% Mechanisms 48 . 64% Anest hesia 1 . 09% XXX xx.xx% T r eatment Drugs 2.28% XXX xx.xx% Syst emic 1 .4 1% P at hology 3 .23% Aut oimmunue
-
[23]
11% Mechanisms 48
08% Bones & ENT 1 . 11% Mechanisms 48 . 64% Embr y ology 1 . 00% Sur gical Anat om y
-
[24]
71% Mechanisms 48
62% Medical L a w 0 . 71% Mechanisms 48 . 64% P o p ulatio n H ealt h 1 . 05% Misc . F act s 1 .47% Digestiv e 0 . 08% XXX xx.xx% Mechanisms 48 . 64% Mechanisms 48 . 64% Cancer 1 . 61% XXX xx.xx% K idne y 1 . 54% XXX xx.xx% Clinical Cases 49 . 90% Mechanisms 48 . 64% Mechanisms 48 . 64% Pr egnancy 1 . 82% XXX xx.xx% Mechanisms 48 . 64% Mechanisms 48 . 64%...
-
[25]
64% Mechanisms 48
7 9% XXX xx.xx% Mechanisms 48 . 64% Mechanisms 48 . 64% I n f ections
-
[26]
64% Mechanisms 48
06% XXX xx.xx% Mechanisms 48 . 64% Mechanisms 48 . 64% L ung Disease 1 . 15% XXX xx.xx% Emer gency Cases 6 . 98% XXX xx.xx% Mechanisms 48 . 64% Mechanisms 48 . 64% H ear t Disease
-
[27]
64% R ep r o d u c ti v e & B r e a st 2.23% Mechanisms 48
06% XXX xx.xx% Mechanisms 48 . 64% R ep r o d u c ti v e & B r e a st 2.23% Mechanisms 48 . 64% Endocrine
-
[28]
64% Chr onic Meds 1
34% Mechanisms 48 . 64% Chr onic Meds 1 . 02% Mechanisms 48 . 64% Ge n e ti c s & De v e lo p m e n t 1 . 7 4% Dermat ology
-
[29]
64% Ne w bor n Car e 1
58% Mechanisms 48 . 64% Ne w bor n Car e 1 . 99% Mechanisms 48 . 64% ??? 11 . 32% A cut e Abdome n 2.26% Mechanisms 48 . 64% Digestiv e Disor ders 1 . 7 3% L iv er & P or tal 0 . 14% Et hics & Consent 0 . 54% XXX xx.xx% Mot or & S p ine 1 . 7 9% XXX xx.xx% T r auma & T o x icology
-
[30]
32% XXX xx.xx% Br ain & Ey e
-
[31]
04% Mechanisms 48
32% XXX xx.xx% P ediatric S k i n 0 . 04% Mechanisms 48 . 64% Chil d I n f ections 1 . 33% S k i n Disor ders 1 .21% A cut e Car e 0 . 04% XXX xx.xx% T r auma 1 . 14% XXX xx.xx% T o x icology 1 . 14% XXX xx.xx% V accines & Viruses Clust er Ne wborn Car e Clust er R e cu rs io n S tat i st ic s Insufficient Clust ers (100%) Char t T est (0 . 00%) Figure 14...
2025
-
[32]
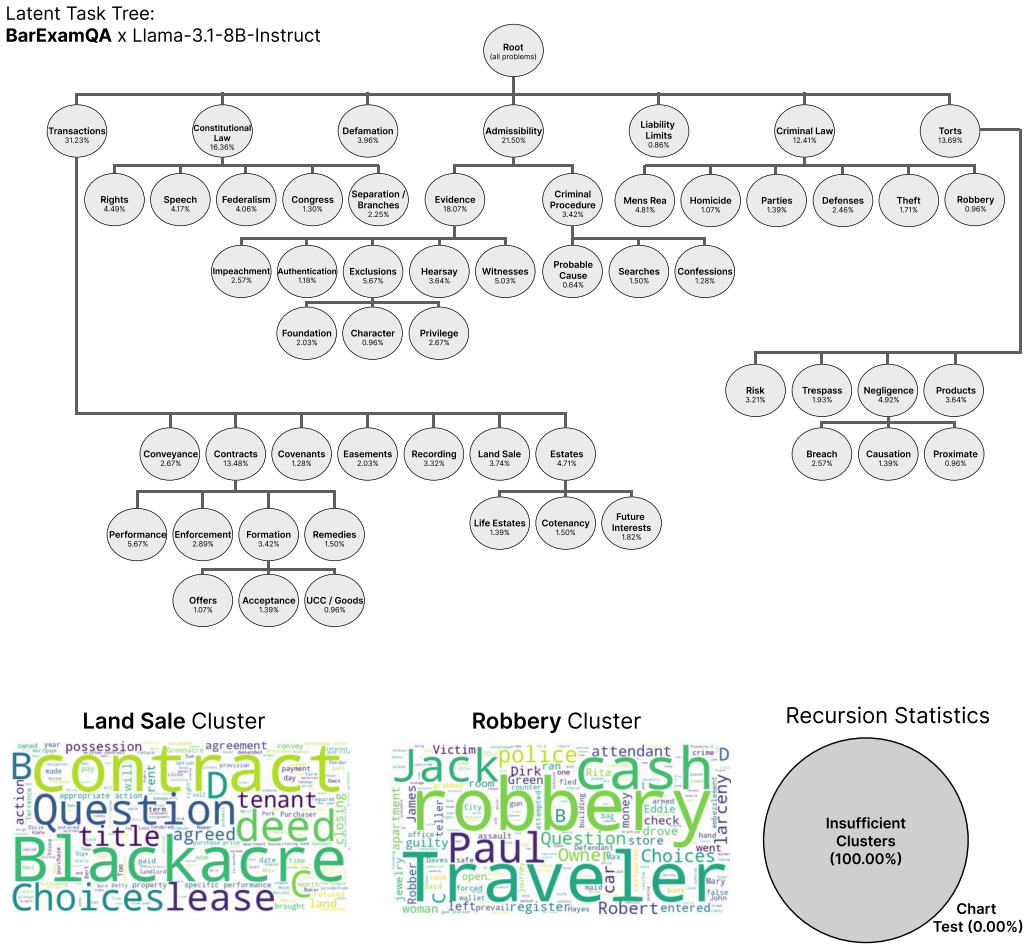
18% E x clusions 5
57% A ut he nti c atio n 1 . 18% E x clusions 5 . 67% H earsa y 3 . 64% W itnesses 5 . 03% Pr obable Cause 0 . 64% Sear ches 1 . 50% Conf essions 1 .28% F oundation
-
[33]
96% Privile g e
03% Char act e r 0 . 96% Privile g e
-
[34]
93% N e g li g ence 4
67% R is k 3 .21% T r es p ass 1 . 93% N e g li g ence 4 . 92% Pr oduct s 3 . 64% Con v e y ance
-
[35]
67% Cont r a c t s 13 .48% Co v enant s 1 .28% Easement s
-
[36]
32% Land Sale 3
03% R ecor din g 3 . 32% Land Sale 3 . 7 4% Estat es 4 . 71% B r eac h
-
[37]
39% Pr o x imat e 0
57% Causation 1 . 39% Pr o x imat e 0 . 96% P er f ormance 5 . 67% E n f o r ceme n t
-
[38]
50% Li f e E stat es 1
89% F ormation 3 .42% R emedies 1 . 50% Li f e E stat es 1 . 39% Cot enanc y 1 . 50% F utur e I nt er est s 1 . 82% O ff ers 1 . 0 7% A cceptance 1 . 39% U CC / G oods 0 . 96% Land Sale Clust er R obber y Clust er R ecursion Statistics Insufficient Clust ers (100 . 00%) Char t T est (0 . 00%) Figure 15.Latent Task Tree forBarExamQA[Zheng et al., 2025c] us...
2024
-
[39]
51% Compan y L a w 1
9 8 % In v estment F unds 1 . 51% Compan y L a w 1 . 4 0% R i s k M a n a g e m e n t
-
[40]
5 8 % Insur ance 1
47 % Managerial Finance 1 . 5 8 % Insur ance 1 . 51% Macr o Finance 1 . 62% Capital Budgeting 1 . 13% R oot (all pr oblems) Financial R epor t s 5 . 0 4 % Securities Rules 1 . 05% Business Str at eg y 1 . 05% Securities Compliance 1 . 31% St oc k Sentiment
-
[41]
6 7 % T a x A ccounting 11 .21% E v ent E x tr actio n 2.23% Industr y N e w s 5
69% N e w s T as k s 9 . 6 7 % T a x A ccounting 11 .21% E v ent E x tr actio n 2.23% Industr y N e w s 5 . 7 5% Mar k et N e w s 1 . 6 8 % A sset A ccounting 1 . 53% A ccounting Entries 3 . 02% A ccounting Mat h
-
[42]
96% Mar k et Causalit y 3
35% Ris k Entities 1 .25% Finance Concept s 5 . 96% Mar k et Causalit y 3 . 7 7 % P u b lic Finance 3 . 16% Sett lement L a w 1 . 3 4 % Contr act L a w 1 . 7 4 % P olic y N e w s 0 . 8 5% Compan y E v ent s
-
[43]
03% Mar k et T r ends
-
[44]
84 % P ersonal Finance 4
87 % Economics 1 . 84 % P ersonal Finance 4 . 0 4 % A d v ice Mi x 0 . 0 8 % T ax E x a m
-
[45]
48 % T ax V aluation
-
[46]
01% V alue-A dded T ax 1
09% T a x L a w 1 .2 4 % A ccounting P r o b lems 3 . 01% V alue-A dded T ax 1 . 3 8 % J ournal Entries 1 . 02% Economics Clust er P ersonal Finance Clust er R ecursion Statistics A sset Calculations 1 . 8 1% Financial A sset s 1 .20% Insufficient Clust ers (9 7 . 5%) Char t T est (2. 5%) Figure 16.Latent Task Tree forAgentar-DeepFinance-100K[Zhao et al.,...
2025
-
[47]
64% Mechanisms 48
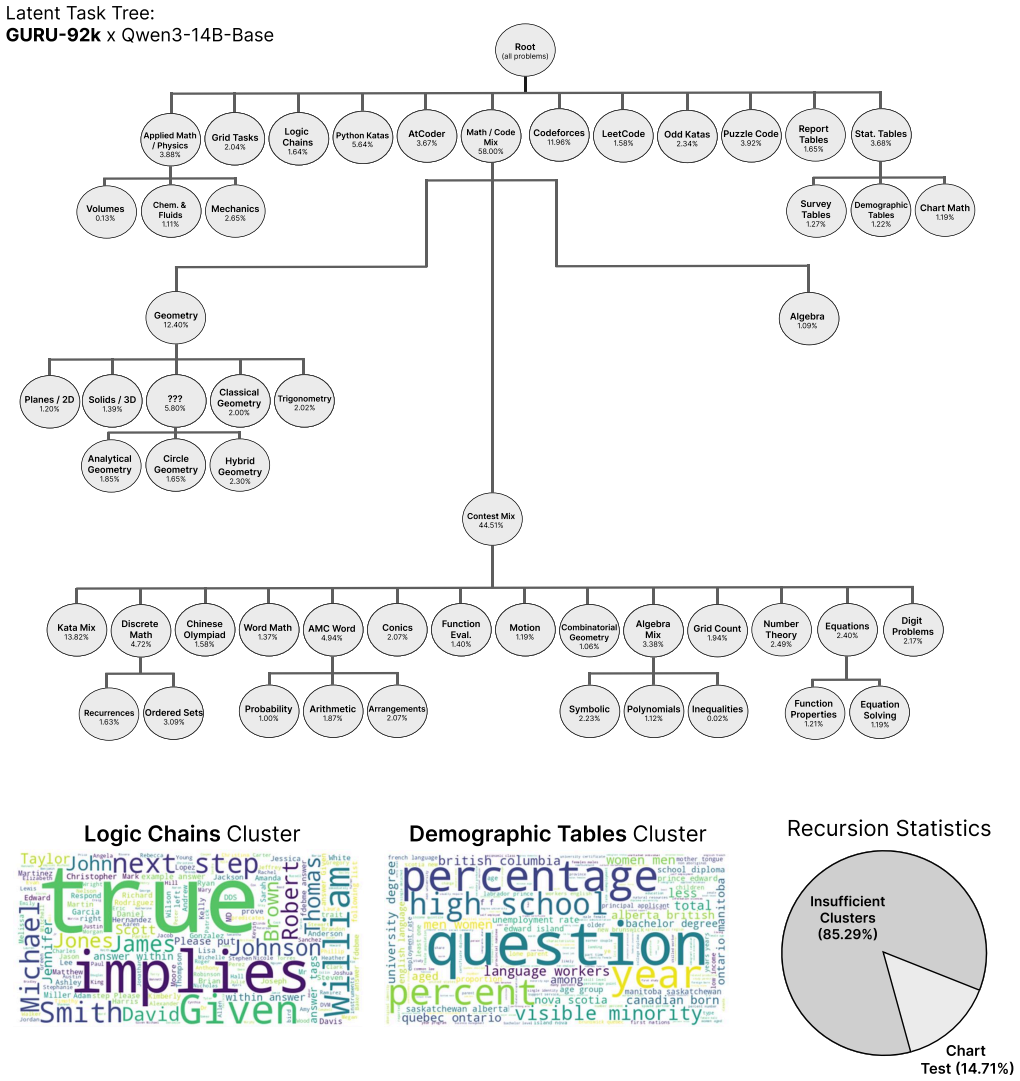
04% XXX xx.xx% Mechanisms 48 . 64% Mechanisms 48 . 64% Logic Chains 1 . 64% XXX xx.xx% Mechanisms 48 . 64% Mechanisms 48 . 64% Pyt hon K a t as 5 . 64% XXX xx.xx% Mechanisms 48 . 64% A tCode r 3 . 67% XXX xx.xx% Mechanisms 48 . 64% Mechanisms 48 . 64% M a t h / Cod e M i x 58 . 00% XXX xx.xx% Mechanisms 48 . 64% Mechanisms 48 . 64% Code f or ces 11 . 96% ...
-
[48]
64% Puzzle Code 3
34% XXX xx.xx% Mechanisms 48 . 64% Puzzle Code 3 . 92% R epor t T ables 1 . 65% Mechanisms 48 . 64% Stat . T ables 3 . 68% V olumes 0 . 13% Mechanisms 48 . 64% Chem. & Fluids 1 . 11% Mechanics
-
[49]
64% Demogr aphic T ables 1 .22% Char t Mat h 1
65% Sur v e y T ables 1 .27% Mechanisms 48 . 64% Demogr aphic T ables 1 .22% Char t Mat h 1 . 19% Geometr y 12.40% Mechanisms 48 . 64% Algebr a 1 . 09% Mechanisms 48 . 64% Planes / 2D 1 .20% Mechanisms 48 . 64% Mechanisms 48 . 64% Solids / 3D 1 . 39% XXX xx.xx% Mechanisms 48 . 64% Mechanisms 48 . 64% XXX xx.xx% ??? 5 . 80% Mechanisms 48 . 64% Mechanisms 4...
-
[50]
64% Mechanisms 48
00% XXX xx.xx% Mechanisms 48 . 64% Mechanisms 48 . 64% T rigonome t r y
-
[51]
85% Mechanisms 48
02% XXX xx.xx% Analytical Geometr y 1 . 85% Mechanisms 48 . 64% Cir cle Geometr y 1 . 65% Hybrid Geometr y
-
[52]
51% Mechanisms 48
30% Con t e st M i x 44 . 51% Mechanisms 48 . 64% K ata Mi x 13 . 82% Mechanisms 48 . 64% D iscr et e Mat h 4 . 72% Mechanisms 48 . 64% Mechanisms 48 . 64% Chinese Olympiad 1 . 58% XXX xx.xx% Mechanisms 48 . 64% Mechanisms 48 . 64% W o r d M a t h 1 . 37% XXX xx.xx% Mechanisms 48 . 64% Mechanisms 48 . 64% AMC W or d 4 . 94% XXX xx.xx% Mechanisms 48 . 64% ...
-
[53]
64% Mechanisms 48
0 7% XXX xx.xx% Mechanisms 48 . 64% Mechanisms 48 . 64% F unction Ev al . 1 .40% XXX xx.xx% Mechanisms 48 . 64% Mechanisms 48 . 64% Motion 1 . 19% XXX xx.xx% Co mb ina t o r ia l G eo m e tr y 1 . 06% XXX xx.xx% Mechanisms 48 . 64% Mechanisms 48 . 64% Algebr a Mi x 3 . 38% XXX xx.xx% Mechanisms 48 . 64% Gr id Coun t 1 . 94% N umbe r Theor y 2.49% Mechanis...
-
[54]
63% Or der ed Set s 3
17% R ecurr ences 1 . 63% Or der ed Set s 3 . 09% Mechanisms 48 . 64% Pr obability 1 . 00% XXX xx.xx% Arit hmeti c 1 . 87% XXX xx.xx% A rr angemen t s
-
[55]
12% XXX xx.xx% I nequalities 0
0 7% XXX xx.xx% Symboli c 2.23% XXX xx.xx% P olynomials 1 . 12% XXX xx.xx% I nequalities 0 . 02% XXX xx.xx% F unction Pr oper ties 1 .21% Mechanisms 48 . 64% Equation Solving 1 . 19% Logic Chains Clust er Dem og r a p hic T a ble s Clust er R e cu rs io n S tat i st ic s I ns uff ici e n t C lu s t er s (85 .29%) Cha r t T e s t (14 . 71%) Figure 17.Laten...
-
[56]
53% Natur al Language Inf er ence
71% Common Sense 1 . 53% Natur al Language Inf er ence
-
[57]
51% C op y T as k s 1
00% R e s ear c h T a sks 1 .20% Cr eativ e Fiction 1 . 51% C op y T as k s 1 . 83% Ed g y / ??? 9 .27% In d ic Q A 1 . 1 6 % R egiona l Q A 2.21% A frican Q A 1 .2 6 % T r a n s l atio n T as k s
-
[58]
7 4 % Gener al R e q ue s t s 1 9
0 9 % Co d e H el p 2.2 6 % P y t h on F unction s 3 . 7 4 % Gener al R e q ue s t s 1 9 . 0 4 % M at h 6 . 82% Appl ie d P r o b l em s 31 . 4 5% NL P 3 . 33% Pr o g r a mming T ask s 6 . 6 0% Basic Mat h 3 . 30% Algebr a Pr oof s 2.21% Geometr y 1 . 31% Op timi z ation M o d e ls 6 . 33% Modeling Pr oblems 7 . 6 1% Arit hmetic St ories 10 . 82% A d v an...
-
[59]
88% L a b e l i ng T as k s 1
82% Dy nami c M o d e ls 3 . 88% L a b e l i ng T as k s 1 . 1 6 % L ing u istic T a s k s 1 . 05% T e xt A na lys i s 1 . 12% D ecisio n Mo d e l s 4 . 8 4 % D iscr et e Mat h 1 .2 6 % M i x tur e Op timi z ation 0 .22% R at e A rit h meti c
-
[60]
6 0% M u l ti - S t e p A rit h meti c 3
51% E v er y d a y Arit hmetic 4 . 6 0% M u l ti - S t e p A rit h meti c 3 . 7 0% Alg orit h ms 4 . 0 7% Da t a S c ien c e 1 . 4 5% Sys t e m D e s ign 1 . 08% Misc . R e qu est s 6 . 11% Sensiti v e R e qu est s 7 . 9 5% W ritin g R e q ue s t s 3 . 37% Con s tr aine d A n sw er s 1 . 6 1% Mat eria l Q u a n tities 0 .25% Da il y Q ua ntities 3 . 10% M...
2025
-
[61]
33% T angent s
18% Inscribed 1 . 33% T angent s
-
[62]
Ratios 1
9 2% T rig . Ratios 1 . 00% Congruence 1 . 96 % P r o p or tions 1 . 7 8% Figur e Solv e
-
[63]
7 4% Segment Ratios 1 .44% Similarity I 1
0 7% Segment s 1 . 7 4% Segment Ratios 1 .44% Similarity I 1 . 11% Quadrilat er als
-
[64]
Algebr a 2.48% R ounding I 1 .22% P ar aellogr ams 1
18% Similarity II 1 .48% Q uad . Algebr a 2.48% R ounding I 1 .22% P ar aellogr ams 1 . 81% R ounding II 1 .4 1% Ar ea 4 . 37% Angles & Lengt hs 1 . 04% Ar cs I 2.48% Angle Chasing 1 . 7 8% Ar cs II
-
[65]
0 7% R elations I 3 .40% Angles I 1
7 0% R oot (all pr oblems) Angle Algebr a 1 . 0 7% R elations I 3 .40% Angles I 1 . 85% R elations II 4 . 18% Angles II
-
[66]
00% Angles III 1
00% Diagr am Only 1 . 00% Angles III 1 . 04% V isual I 1 . 5 9 % P erimet e r & Ar ea 7 . 7 4% V isual II 1 . 5 9 % M i x ed V 1 . 96 % V isual III 1 . 7 0% V isual IV 2.22% V isual V 1 .4 1% M i x ed II
-
[67]
30% V isual V I I 3 .48% V isual V II I
00% M i x ed III 3 .48% M i x ed IV 1 .22% V isual V I 1 . 30% V isual V I I 3 .48% V isual V II I
-
[68]
Goldilocks
04% V isual IX 1 . 6 3% M i x ed I 11 .2 9 % Figure 19.Latent Task Tree forGeometry3KLu et al. [2021] using Qwen3-VL-32B-Instruct’s [Bai et al., 2025] latent space.The dataset consists of multimodal geometry problems, and the induced tree contains 54 nodes. On one node with 8×H100 GPUs, loading the latent representations took 3:26 minutes, and recursive t...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.