VLK: Learning Humanoid Loco-Manipulation from Synthetic Interactions in Reconstructed Scenes
Pith reviewed 2026-06-30 04:47 UTC · model grok-4.3
The pith
Synthesizing vision-language-kinematics trajectories in reconstructed scenes trains policies that enable physical humanoid loco-manipulation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
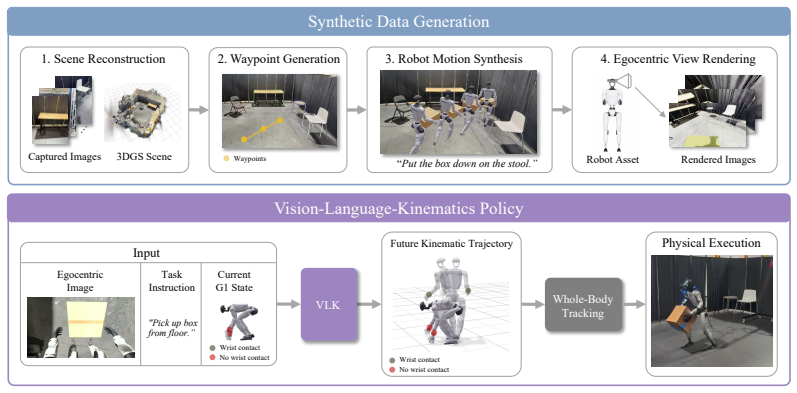
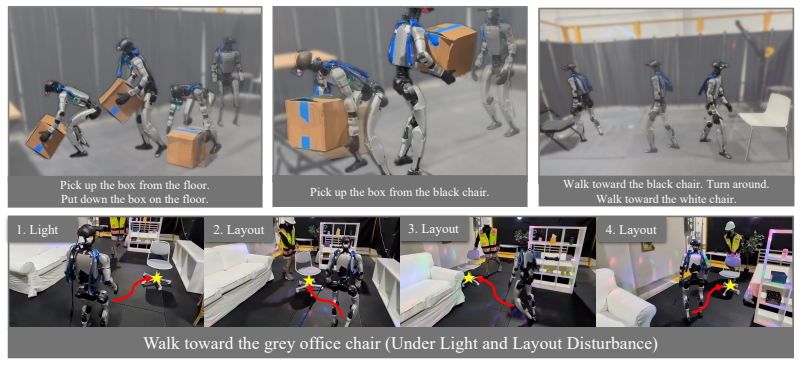
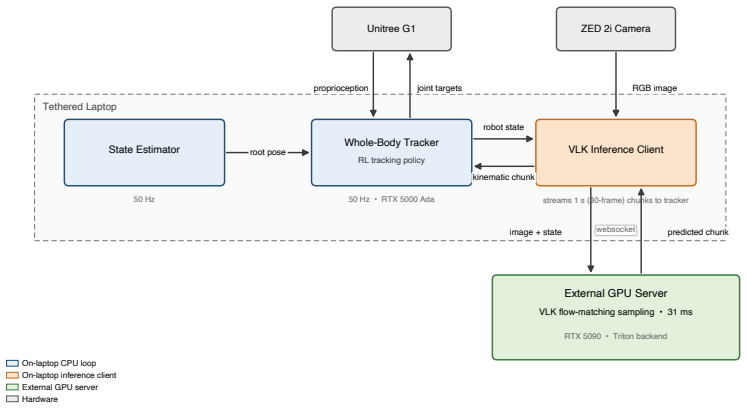
Reconstructing scenes with 3D Gaussian Splatting, synthesizing trajectories with privileged scene information, and rendering paired egocentric observations produces 48,000 vision-language-kinematics tuples that suffice to train a policy predicting short-horizon whole-body kinematic trajectories; when executed by a whole-body tracker on the physical Unitree G1, the policy completes navigation and single-object transport tasks.
What carries the argument
The VLK data-generation pipeline that uses 3D Gaussian Splatting for metric scene reconstruction, privileged-information trajectory synthesis for navigation and object interaction, and post-hoc egocentric rendering to create paired supervision for whole-body policy learning.
If this is right
- Training data for perception-based loco-manipulation can be scaled without manual collection or real-robot trials.
- A single policy can handle both navigation and object transport through short-horizon whole-body kinematic predictions.
- 3D Gaussian Splatting reconstructions supply metric-scale geometry sufficient for trajectory synthesis that transfers to hardware.
- Language commands can be directly paired with robot-compatible motions via the rendered observation-trajectory tuples.
Where Pith is reading between the lines
- The same reconstruction-plus-synthesis approach could support multi-step or multi-object tasks if the underlying scene model is extended to handle dynamics.
- Reducing dependence on real data collection may allow faster iteration on humanoid controllers for varied indoor environments.
- Similar synthetic pipelines might be tested on other robot platforms to check whether the transfer property holds beyond the Unitree G1.
Load-bearing premise
Trajectories synthesized with privileged scene information and rendered egocentric views will produce policies that transfer to physical hardware without large domain gaps or additional real data.
What would settle it
Deployment of the trained policy on the physical Unitree G1 yields near-zero success rate on the navigation and single-object transport tasks, or quantitative metrics show a large performance gap relative to privileged-information baselines.
Figures



read the original abstract
Perception-based humanoid loco-manipulation requires connecting egocentric observations and task instructions to whole-body motion. Learning this mapping requires synchronized egocentric images, language commands, and robot-compatible kinematic trajectories, yet no existing data source provides this complete tuple at scale. We address this bottleneck by generating vision-language-kinematics (VLK) supervision synthetically in reconstructed scenes. Our pipeline leverages 3D Gaussian Splatting to reconstruct metric-scale indoor environments, synthesizes navigation and object-interaction trajectories using privileged scene information, and renders paired egocentric observations after the fact. We produce 48,000 paired trajectories with no human intervention and train a VLK policy that predicts short-horizon whole-body kinematic trajectories. A whole-body tracker converts these predictions into actions on the physical humanoid. We evaluate on the physical Unitree G1 performing navigation and single-object transport, demonstrating that synthesized interactions in reconstructed scenes provide effective supervision for sim-to-real perception-based humanoid loco-manipulation. Project Website: https://vision-language-kinematics.github.io/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a synthetic data generation pipeline for vision-language-kinematics (VLK) supervision to train policies for perception-based humanoid loco-manipulation. It reconstructs indoor scenes using 3D Gaussian Splatting, synthesizes navigation and interaction trajectories with privileged scene access, renders egocentric images, generates 48,000 trajectories, trains a policy predicting short-horizon whole-body kinematics, and transfers to the physical Unitree G1 robot using a whole-body tracker, claiming successful demonstration on navigation and single-object transport tasks.
Significance. Should the transfer results be quantitatively validated, this work would offer a valuable contribution by providing a scalable approach to generating large-scale, synchronized VLK data without human effort. This could significantly reduce the data collection barrier for training end-to-end policies that map egocentric vision and language to whole-body actions in humanoid robots. The use of 3DGS for metric-scale reconstruction and post-hoc rendering is a promising direction for bridging simulation and reality in loco-manipulation.
major comments (1)
- [Abstract] Abstract: The central claim that synthesized interactions in reconstructed scenes provide effective supervision for sim-to-real perception-based humanoid loco-manipulation is not supported by quantitative evidence. The abstract asserts evaluation and demonstration of effectiveness on the physical Unitree G1 for navigation and single-object transport, yet supplies no success rates, baseline comparisons, error bars, ablation studies on reconstruction fidelity or rendering quality, or transfer metrics. This absence is load-bearing for the supervision claim, as the policy transfer assertion cannot be assessed without these results.
minor comments (2)
- The abstract introduces the VLK policy and 'short-horizon whole-body kinematic trajectories' without specifying the prediction horizon, output representation (e.g., joint angles vs. velocities), or conditioning details, which would improve clarity of the learned mapping.
- A schematic diagram of the full pipeline (reconstruction → trajectory synthesis → rendering → policy training → tracker) would aid reader understanding of the data flow and privileged information usage.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for quantitative support. We address the major comment below and will revise the manuscript to strengthen the presentation of results.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that synthesized interactions in reconstructed scenes provide effective supervision for sim-to-real perception-based humanoid loco-manipulation is not supported by quantitative evidence. The abstract asserts evaluation and demonstration of effectiveness on the physical Unitree G1 for navigation and single-object transport, yet supplies no success rates, baseline comparisons, error bars, ablation studies on reconstruction fidelity or rendering quality, or transfer metrics. This absence is load-bearing for the supervision claim, as the policy transfer assertion cannot be assessed without these results.
Authors: We agree that quantitative metrics are necessary to substantiate the central claim of effective supervision and sim-to-real transfer. The manuscript currently presents the pipeline and qualitative physical demonstrations; in revision we will add success rates for navigation and single-object transport on the Unitree G1, baseline comparisons, error bars, and any available ablations on reconstruction fidelity or rendering quality to the results section and abstract. revision: yes
Circularity Check
No circularity: empirical data-generation pipeline with no derivation chain
full rationale
The paper presents an empirical pipeline that reconstructs scenes with 3D Gaussian Splatting, synthesizes trajectories using privileged information, renders egocentric views, and trains a policy on the resulting VLK tuples. No equations, fitted parameters renamed as predictions, self-citational uniqueness theorems, or ansatzes are described in the abstract or reader summary. The central claim is that the generated synthetic supervision enables sim-to-real transfer on hardware, which is an empirical assertion rather than a mathematical derivation that could reduce to its own inputs by construction. No load-bearing steps match any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Y . Ze, S. Zhao, W. Wang, A. Kanazawa, R. Duan, P. Abbeel, G. Shi, J. Wu, and C. K. Liu. Twist2: Scalable, portable, and holistic humanoid data collection system.arXiv preprint arXiv:2511.02832, 2025. URLhttps://arxiv.org/abs/2511.02832
arXiv 2025
-
[2]
Y . Li, Y . Lin, J. Cui, T. Liu, W. Liang, Y . Zhu, and S. Huang. Clone: Closed-loop whole-body humanoid teleoperation for long-horizon tasks.arXiv preprint arXiv:2506.08931, 2025. URL https://arxiv.org/abs/2506.08931
arXiv 2025
-
[3]
Kerbl, G
B. Kerbl, G. Kopanas, T. Leimk ¨uhler, G. Drettakis, et al. 3d gaussian splatting for real-time radiance field rendering.ACM Trans. Graph., 42(4):139–1, 2023
2023
-
[5]
S. Chen, S. Zhao, Z. Wu, J. Li, G. Shi, and C. K. Liu. Scenebot: Contact-prompted general humanoid whole body tracking with scene-interaction, 2026. URLhttps://arxiv.org/ abs/2606.27581
Pith/arXiv arXiv 2026
-
[6]
Zitkovich, T
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahid, Q. Vuong, V . Vanhoucke, H. Tran, R. Soricut, A. Singh, J. Singh, P. Sermanet, P. R. San- keti, G. Salazar, M. S. Ryoo, K. Reymann, K. Rao, K. Pertsch, I. Mordatch, H. Michalewski, Y . Lu, S. Levine, L. Lee, T.-W. E. Lee, I. Leal, Y . Kuang, D. Kalashnikov, R. Jul...
2023
-
[7]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. P. Foster, P. R. Sanketi, Q. Vuong, T. Kollar, B. Burchfiel, R. Tedrake, D. Sadigh, S. Levine, P. Liang, and C. Finn. OpenVLA: An open-source vision-language-action model. InProceedings of The 8th Conference on Robot Learning, volume 270 ofProceedings of Machine Learni...
2025
-
[8]
Black, N
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Haus- man, B. Ichter, S. Jakubczak, T. Jones, L. Ke, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, 9 K. Pertsch, L. X. Shi, J. Tanner, Q. Vuong, A. Walling, H. Wang, and U. Zhilinsky.π 0: A vision-language-action flow model for general robot control. InRobotics: Science and...
2025
-
[9]
NVIDIA, J. Bjorck, F. Casta ˜neda, N. Cherniadev, X. Da, R. Ding, L. Fan, Y . Fang, D. Fox, F. Hu, et al. GR00T N1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734, 2025
Pith/arXiv arXiv 2025
-
[10]
H. Xue, X. Huang, D. Niu, Q. Liao, T. Kragerud, J. T. Gravdahl, X. B. Peng, G. Shi, T. Dar- rell, K. Sreenath, and S. Sastry. LeVERB: Humanoid whole-body control with latent vision- language instruction.arXiv preprint arXiv:2506.13751, 2025
arXiv 2025
-
[11]
Jiang, J
H. Jiang, J. Chen, Q. Bu, L. Chen, M. Shi, Y . Zhang, D. Li, C. Suo, C. Wang, Z. Peng, and H. Li. WholeBodyVLA: Towards unified latent VLA for whole-body loco-manipulation control. InInternational Conference on Learning Representations, 2026
2026
-
[12]
P. Ding, J. Ma, X. Tong, B. Zou, X. Luo, Y . Fan, T. Wang, H. Lu, P. Mo, J. Liu, et al. Humanoid-vla: Towards universal humanoid control with visual integration.arXiv preprint arXiv:2502.14795, 2025
arXiv 2025
-
[13]
S. Wei, H. Jing, B. Li, Z. Zhao, J. Mao, Z. Ni, S. He, J. Liu, X. Liu, K. Kang, S. Zang, W. Yuan, M. Pavone, D. Huang, and Y . Wang.Ψ 0: An open foundation model towards universal hu- manoid loco-manipulation. InRobotics: Science and Systems, 2026
2026
-
[14]
S. Chen, Y . Ye, Z.-A. Cao, J. Lew, P. Xu, and C. K. Liu. Hand-eye autonomous delivery: Learning humanoid navigation, locomotion and reaching.arXiv preprint arXiv:2508.03068, 2025
arXiv 2025
-
[15]
Y . Shao, X. Huang, B. Zhang, Q. Liao, Y . Gao, Y . Chi, Z. Li, S. Shao, and K. Sreenath. Lang- WBC: Language-directed humanoid whole-body control via end-to-end learning. InRobotics: Science and Systems, 2025
2025
-
[16]
P. Li, Z. Zhuang, Y . Gao, Y . Dong, S. Li, C. Jiang, S. Dou, Z. Xi, E. Zhou, J. Huang, H. Li, J. Gong, X. Ma, T. Gui, Z. Wu, Q. Zhang, X. Huang, Y .-G. Jiang, and X. Qiu. FRoM-W1: Towards general humanoid whole-body control with language instructions.arXiv preprint arXiv:2601.12799, 2026
arXiv 2026
-
[18]
Y . Mu, T. Chen, Z. Chen, S. Peng, Z. Lan, Z. Gao, Z. Liang, Q. Yu, Y . Zou, M. Xu, L. Lin, Z. Xie, M. Ding, and P. Luo. RoboTwin: Dual-arm robot benchmark with generative digital twins. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion, 2025
2025
-
[19]
M. N. Qureshi, S. Garg, F. Yandun, D. Held, G. Kantor, and A. Silwal. SplatSim: Zero- shot sim2real transfer of RGB manipulation policies using gaussian splatting.arXiv preprint arXiv:2409.10161, 2024
arXiv 2024
-
[20]
X. Li, J. Li, Z. Zhang, R. Zhang, F. Jia, T. Wang, H. Fan, K.-K. Tseng, and R. Wang. RoboGSim: A real2sim2real robotic gaussian splatting simulator.arXiv preprint arXiv:2411.11839, 2024
arXiv 2024
-
[21]
Y . Wu, L. Pan, W. Wu, G. Wang, Y . Miao, and H. Wang. RL-GSBridge: 3d gaussian splatting based real2sim2real method for robotic manipulation learning. InIEEE International Confer- ence on Robotics and Automation, 2025. 10
2025
-
[22]
Escontrela, J
A. Escontrela, J. Kerr, A. Allshire, J. Frey, R. Duan, C. Sferrazza, and P. Abbeel. GaussGym: An open-source real-to-sim framework for learning locomotion from pixels. InInternational Conference on Learning Representations, 2026
2026
-
[23]
L. Yang, X. Huang, Z. Wu, A. Kanazawa, P. Abbeel, C. Sferrazza, C. K. Liu, R. Duan, and G. Shi. OmniRetarget: Interaction-preserving data generation for humanoid whole-body loco- manipulation and scene interaction. InIEEE International Conference on Robotics and Au- tomation, 2026
2026
-
[24]
J. P. Araujo, Y . Ze, P. Xu, J. Wu, and C. K. Liu. Retargeting matters: General motion retargeting for humanoid motion tracking. InIEEE International Conference on Robotics and Automation, 2026
2026
-
[25]
T. He, Z. Luo, X. He, W. Xiao, C. Zhang, W. Zhang, K. Kitani, C. Liu, and G. Shi. Om- niH2O: Universal and dexterous human-to-humanoid whole-body teleoperation and learning. InProceedings of The 8th Conference on Robot Learning, Proceedings of Machine Learning Research. PMLR, 2024
2024
-
[26]
Z. Chen, M. Ji, X. Cheng, X. Peng, X. B. Peng, and X. Wang. GMT: General motion tracking for humanoid whole-body control.arXiv preprint arXiv:2506.14770, 2025
arXiv 2025
-
[27]
Q. Liao, T. E. Truong, X. Huang, G. Tevet, K. Sreenath, and C. K. Liu. BeyondMimic: From motion tracking to versatile humanoid control via guided diffusion.arXiv preprint arXiv:2508.08241, 2025
Pith/arXiv arXiv 2025
-
[28]
S. Zhao, Y . Ze, Y . Wang, C. K. Liu, P. Abbeel, G. Shi, and R. Duan. Resmimic: From gen- eral motion tracking to humanoid whole-body loco-manipulation via residual learning.arXiv preprint arXiv:2510.05070, 2025
arXiv 2025
-
[29]
Z. Luo, Y . Yuan, T. Wang, C. Li, S. Chen, F. Casta ˜neda, Z.-A. Cao, J. Li, D. Minor, Q. Ben, X. Da, R. Ding, C. Hogg, L. Song, E. Lim, E. Jeong, T. He, H. Xue, W. Xiao, Z. Wang, S. Yuen, J. Kautz, Y . Chang, U. Iqbal, L. Fan, and Y . Zhu. Sonic: Supersizing motion tracking for natural humanoid whole-body control.arXiv preprint arXiv:2511.07820, 2025
Pith/arXiv arXiv 2025
-
[30]
D. Kalaria, S. S. Harithas, P. Katara, S. Kwak, S. Bhagat, S. Sastry, S. Sridhar, S. Vemprala, A. Kapoor, and J. C.-K. Huang. DreamControl: Human-inspired whole-body humanoid con- trol for scene interaction via guided diffusion.arXiv preprint arXiv:2509.14353, 2025
arXiv 2025
-
[31]
Z. Zhang, K. Wen, M. Xu, J. He, C. Li, T. Miki, C. Schwarke, C. Zhang, X. B. Peng, and M. Hutter. Learning whole-body humanoid locomotion via motion generation and motion tracking.arXiv preprint arXiv:2604.17335, 2026
Pith/arXiv arXiv 2026
-
[32]
D. Rempe, M. Zanfir, Y .-T. Hu, R. Li, C. Li, J. Tseng, L. Liu, T. Darrell, A. Kanazawa, J. Kautz, C. K. Liu, S. Fidler, L. Guibas, S. Saito, O. Litany, G. Shafir, T.-Y . Lin, S. Tulsiani, A. A. Efros, et al. Kimodo: Scaling controllable human motion generation.arXiv preprint arXiv:2603.15546, 2026. URLhttps://arxiv.org/abs/2603.15546
arXiv 2026
-
[33]
J. Li, A. Clegg, R. Mottaghi, J. Wu, X. Puig, and C. K. Liu. Controllable human-object interaction synthesis. InEuropean Conference on Computer Vision, 2024
2024
-
[34]
Z. Wu, J. Li, P. Xu, and C. K. Liu. Human-object interaction from human-level instructions. InProceedings of the IEEE/CVF International Conference on Computer Vision, 2025
2025
-
[35]
BONES-SEED: Skeletal everyday embodiment dataset.https:// huggingface.co/datasets/bones-studio/seed, 2025
Bones Studio. BONES-SEED: Skeletal everyday embodiment dataset.https:// huggingface.co/datasets/bones-studio/seed, 2025. Hugging Face dataset. Accessed: 2026-05-22
2025
-
[36]
J. Li, J. Wu, and C. K. Liu. Object motion guided human motion synthesis.ACM Transactions on Graphics, 42(6):225:1–225:11, 2023. doi:10.1145/3618333. 11
-
[37]
Y . Zhou, C. Barnes, J. Lu, J. Yang, and H. Li. On the continuity of rotation representations in neural networks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5745–5753, 2019
2019
-
[38]
Prokudin, C
S. Prokudin, C. Lassner, and J. Romero. Efficient learning on point clouds with basis point sets. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 4332–4341, 2019
2019
-
[39]
P. Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, et al.π 0.5: a vision-language-action model with open-world generalization. arXiv preprint arXiv:2504.16054, 2025
Pith/arXiv arXiv 2025
-
[40]
S. Chen, Z. ang Cao, Z. Luo, F. Casta ˜neda, C. Li, T. Wang, Y . Yuan, L. J. Fan, C. K. Liu, and Y . Zhu. Chip: Adaptive compliance for humanoid control through hindsight perturbation,
-
[41]
URLhttps://arxiv.org/abs/2512.14689
-
[42]
Y . Ma, Y . Zhou, Y . Yang, T. Wang, and H. Fan. Running vlas at real-time speed.arXiv preprint arXiv:2510.26742, 2025
arXiv 2025
-
[43]
Z. Wu, J. Li, P. Xu, and C. K. Liu. Human-object interaction from human-level instructions. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 11176– 11186, 2025
2025
-
[44]
B. Yi, V . Ye, M. Zheng, Y . Li, L. M ¨uller, G. Pavlakos, Y . Ma, J. Malik, and A. Kanazawa. Estimating body and hand motion in an ego-sensed world. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[45]
M. Mittal, P. Roth, J. Tigue, A. Richard, O. Zhang, P. Du, A. Serrano-Mu ˜noz, X. Yao, R. Z ¨urbr¨ugg, N. Rudin, L. Wawrzyniak, M. Rakhsha, A. Denzler, E. Heiden, A. Borovicka, O. Ahmed, I. Akinola, A. Anwar, M. T. Carlson, J. Y . Feng, A. Garg, R. Gasoto, L. Gulich, Y . Guo, M. Gussert, A. Hansen, M. Kulkarni, C. Li, W. Liu, V . Makoviychuk, G. Malczyk, ...
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.