Quantifying Prior Dominance in RAG Systems
Pith reviewed 2026-07-01 08:31 UTC · model grok-4.3
The pith
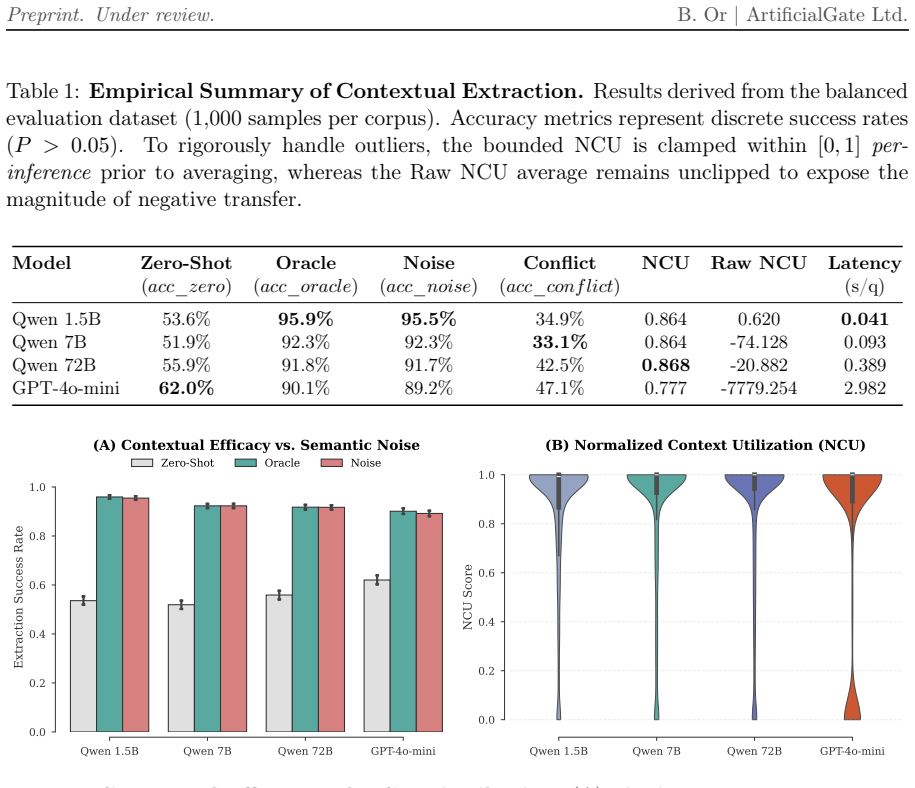
Small language models match or outperform much larger ones when strictly extracting facts from retrieved context.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
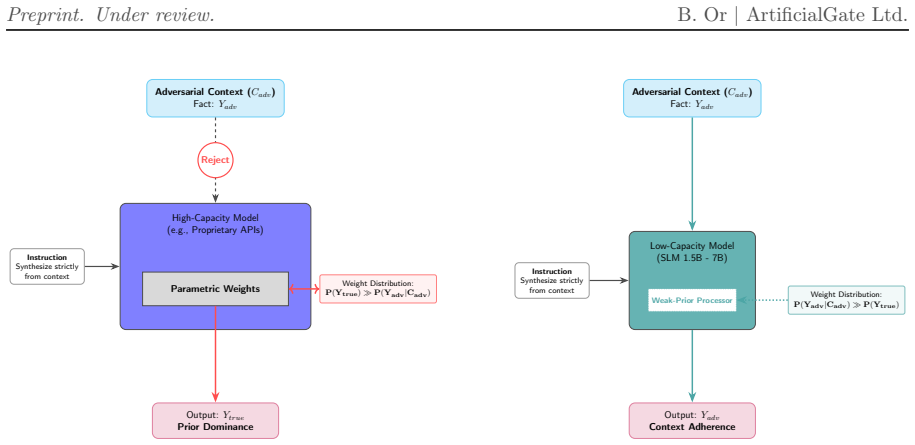
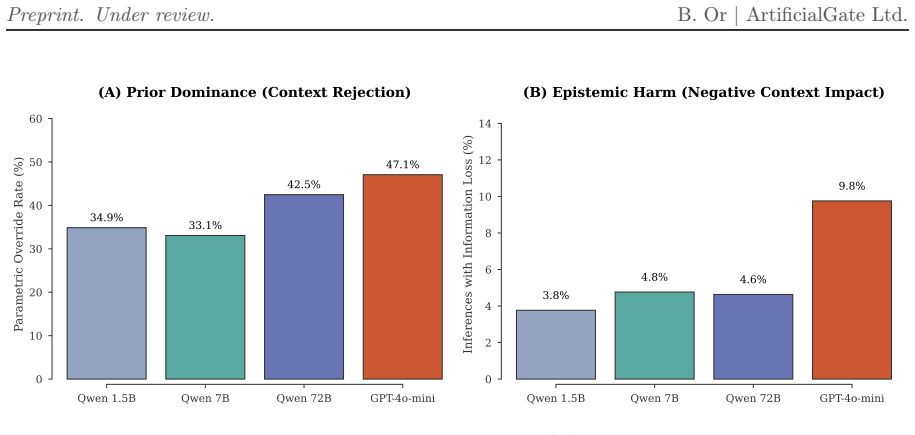
The Normalized Context Utilization metric applied to models from 1.5B to 72B parameters and a commercial API shows that for strict factual extraction without Chain-of-Thought, traditional scaling laws exhibit extreme diminishing returns, with highly efficient small language models matching or outperforming high-capacity architectures, while prior dominance increases with model scale and proprietary alignments.
What carries the argument
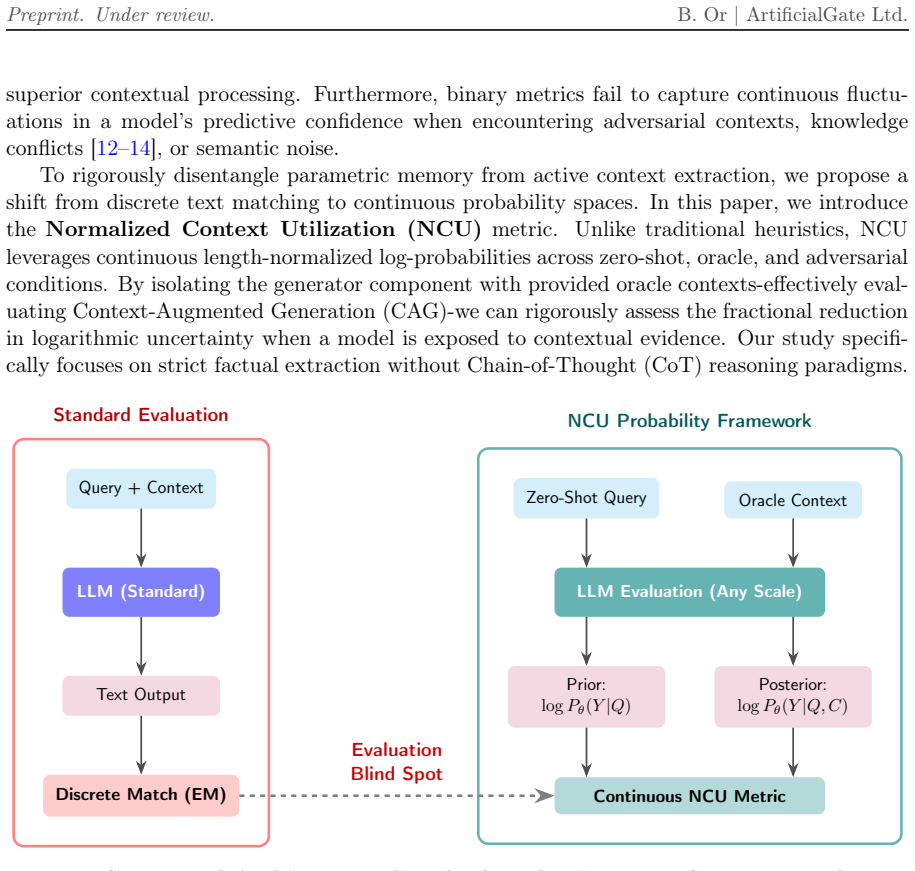
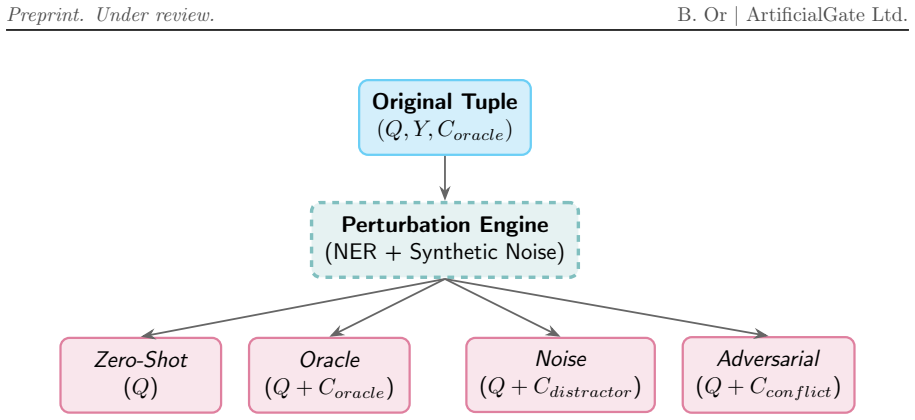
Normalized Context Utilization (NCU) metric, which computes contextual information gain from differences in token log-probabilities across zero-shot, oracle, and adversarial conditions.
If this is right
- Scaling produces extreme diminishing returns for strict factual extraction without reasoning steps.
- Prior dominance increases with model scale and in proprietary alignments.
- Commercial APIs override explicit external evidence in nearly half of adversarial conflicts.
- Small language models exhibit superior contextual adherence in strict extraction workflows.
Where Pith is reading between the lines
- RAG pipelines for factual tasks could achieve better cost-performance by defaulting to smaller models.
- The NCU approach could be extended to measure adherence after fine-tuning or with different retrieval ranks.
- Techniques that suppress parametric recall might close the gap for larger models in context-heavy settings.
Load-bearing premise
The three conditions combined with token log-probabilities isolate genuine contextual information gain from parametric recall without confounding effects from model architecture or training differences.
What would settle it
Finding that models above 7B parameters consistently achieve higher NCU scores than 1.5B models across multiple factual extraction datasets would contradict the diminishing-returns claim.
Figures
read the original abstract
Retrieval-Augmented Generation (RAG) grounds Large Language Models in external knowledge, yet current evaluations rely on discrete heuristics that suffer from ''epistemic blindness'' - failing to distinguish genuine contextual information extraction from parametric memory recall. To address this, we introduce the Normalized Context Utilization (NCU) metric, leveraging continuous token log-probabilities across zero-shot, oracle, and adversarial conditions to strictly quantify contextual information gain. Evaluating architectures ranging from 1.5B to 72B parameters alongside a proprietary commercial API reveals that for strict factual extraction (without Chain-of-Thought reasoning), traditional scaling laws exhibit extreme diminishing returns: highly efficient Small Language Models (SLMs) match or outperform high-capacity architectures. Furthermore, we demonstrate that ``Prior Dominance'' correlates with model scale and proprietary alignments. The evaluated commercial API not only overrode explicit external evidence in nearly half of adversarial conflicts, but also frequently suffered from systemic confidence collapse (Negative Transfer) when its parametric priors were contradicted. Our findings highlight the structural epistemic advantage and superior contextual adherence of SLMs in strict extraction workflows.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Normalized Context Utilization (NCU) metric, which computes contextual information gain from token log-probabilities under zero-shot, oracle, and adversarial conditions to distinguish genuine retrieval use from parametric recall in RAG. It evaluates models from 1.5B to 72B parameters plus a commercial API on strict factual extraction (no CoT), claiming extreme diminishing returns in scaling laws such that SLMs match or outperform larger models, with prior dominance increasing with scale and the API overriding external evidence in ~50% of adversarial cases while exhibiting negative transfer.
Significance. If the NCU metric is shown to isolate contextual gain without architectural confounds, the work would provide evidence against naive scaling in RAG factual tasks and practical guidance favoring SLMs for context adherence, while documenting reliability failures in proprietary APIs.
major comments (2)
- [NCU definition] NCU definition (likely §3): the claim that the three conditions isolate genuine contextual gain assumes log-probability differences are comparable across models without residual effects from calibration, tokenization, or training regime. No ablations or corrections are described, so the observed diminishing returns and SLM advantage could partly reflect metric artifacts (directly matching the stress-test concern on confounding).
- [Model comparison results] Model comparison results (likely §4 or §5): the central claim that SLMs match or outperform high-capacity models for strict extraction rests on NCU being architecture-independent; without evidence that the metric controls for the listed confounds, the scaling-law conclusion is load-bearing and at risk.
minor comments (3)
- Provide the exact NCU formula, normalization procedure, and any free parameters (the abstract implies none, but this must be explicit).
- Add dataset descriptions, statistical details, error bars, and reproducibility information for the API experiments, as these are absent from the abstract-level description.
- Clarify how 'epistemic blindness' is operationalized and distinguished from standard RAG failure modes.
Simulated Author's Rebuttal
We appreciate the referee's detailed feedback on our manuscript. The comments highlight important considerations regarding the robustness of the NCU metric. We address each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [NCU definition] NCU definition (likely §3): the claim that the three conditions isolate genuine contextual gain assumes log-probability differences are comparable across models without residual effects from calibration, tokenization, or training regime. No ablations or corrections are described, so the observed diminishing returns and SLM advantage could partly reflect metric artifacts (directly matching the stress-test concern on confounding).
Authors: We thank the referee for pointing this out. The NCU metric is designed such that the differences in log-probabilities under the three conditions (zero-shot, oracle, adversarial) are intended to normalize for model-specific effects by focusing on relative gains. However, we acknowledge that without explicit ablations for calibration and tokenization differences, there remains a possibility of artifacts. In the revised manuscript, we will include a new subsection discussing these potential confounds and provide additional analysis on how the adversarial condition helps mitigate them. We will also report results with normalized probabilities where applicable. revision: partial
-
Referee: [Model comparison results] Model comparison results (likely §4 or §5): the central claim that SLMs match or outperform high-capacity models for strict extraction rests on NCU being architecture-independent; without evidence that the metric controls for the listed confounds, the scaling-law conclusion is load-bearing and at risk.
Authors: The model comparisons are indeed central to our conclusions. To address this, we will expand the evaluation section to include cross-model normalization techniques and sensitivity analyses to tokenization variations. This will provide stronger evidence that the observed patterns are not solely due to metric artifacts. We maintain that the consistent trends across multiple model families support our claims, but agree that additional controls will bolster the argument. revision: yes
Circularity Check
No circularity: NCU defined from independent conditions; empirical claims not forced by construction
full rationale
The paper defines NCU directly from token log-probabilities measured under three explicit conditions (zero-shot, oracle, adversarial) without any fitting step, parameter estimation from the target result, or self-citation chains. The scaling-law observations (SLMs matching larger models) are presented as direct empirical outputs of applying this metric across model sizes. No equations, ansatzes, or uniqueness theorems are shown that reduce the central claim to its own inputs. The derivation is therefore self-contained and externally falsifiable via the stated conditions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Token log-probabilities across zero-shot, oracle, and adversarial conditions isolate contextual information gain.
Reference graph
Works this paper leans on
-
[1]
Retrieval- augmented generation for knowledge-intensive nlp tasks.Advances in neural information processing systems, 33:9459–9474, 2020
PatrickLewis, EthanPerez, AleksandraPiktus, FabioPetroni, VladimirKarpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. Retrieval- augmented generation for knowledge-intensive nlp tasks.Advances in neural information processing systems, 33:9459–9474, 2020
2020
-
[2]
Improving language models by retrieving from trillions of tokens
Sebastian Borgeaud, Arthur Mensch, Jordan Hoffmann, Trevor Cai, Eliza Rutherford, Katie Millican, George Bm Van Den Driessche, Jean-Baptiste Lespiau, Bogdan Damoc, Aidan Clark, et al. Improving language models by retrieving from trillions of tokens. InInterna- tional conference on machine learning, pages 2206–2240. PMLR, 2022
2022
-
[3]
Retrieval augmented language model pre-training
Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat, and Mingwei Chang. Retrieval augmented language model pre-training. InInternational conference on machine learning, pages 3929–3938. PMLR, 2020
2020
-
[4]
Densepassageretrievalforopen-domainquestionanswering
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, DanqiChen, andWen-tauYih. Densepassageretrievalforopen-domainquestionanswering. InProceedings of the 2020 conference on empirical methods in natural language processing (EMNLP), pages 6769–6781, 2020
2020
-
[5]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[6]
Training Compute-Optimal Large Language Models
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, DDL Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. Training compute-optimal large language models.arXiv preprint arXiv:2203.15556, 10, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[7]
A Survey of Scaling in Large Language Model Reasoning
Zihan Chen, Song Wang, Zhen Tan, Xingbo Fu, Zhenyu Lei, Peng Wang, Huan Liu, Cong Shen, and Jundong Li. A survey of scaling in large language model reasoning.arXiv preprint arXiv:2504.02181, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Revisiting scaling laws for language models: The role of data quality and training strategies
Zhengyu Chen, Siqi Wang, Teng Xiao, Yudong Wang, Shiqi Chen, Xunliang Cai, Junxian He, and Jingang Wang. Revisiting scaling laws for language models: The role of data quality and training strategies. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 23881–23899, 2025
2025
-
[9]
Bleu: a method for automatic evaluation of machine translation
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. Bleu: a method for automatic evaluation of machine translation. InProceedings of the 40th annual meeting of the Association for Computational Linguistics, pages 311–318, 2002
2002
-
[10]
Rouge: A package for automatic evaluation of summaries
Chin-Yew Lin. Rouge: A package for automatic evaluation of summaries. InText summa- rization branches out, pages 74–81, 2004
2004
-
[11]
Factscore: Fine-grained atomic evalua- tion of factual precision in long form text generation
Sewon Min, Kalpesh Krishna, Xinxi Lyu, Mike Lewis, Wen-tau Yih, Pang Wei Koh, Mohit Iyyer, Luke Zettlemoyer, and Hannaneh Hajishirzi. Factscore: Fine-grained atomic evalua- tion of factual precision in long form text generation. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 12076–12100, 2023
2023
-
[12]
Rich knowledge sources bring complex knowledge conflicts: Recalibrating models to reflect conflicting evidence
Hung-Ting Chen, Michael Zhang, and Eunsol Choi. Rich knowledge sources bring complex knowledge conflicts: Recalibrating models to reflect conflicting evidence. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 2292– 2307, 2022. 12 Preprint. Under review.B. Or|ArtificialGate Ltd
2022
-
[13]
Entity-based knowledge conflicts in question answering
Shayne Longpre, Kartik Perisetla, Anthony Chen, Nikhil Ramesh, Chris DuBois, and Sameer Singh. Entity-based knowledge conflicts in question answering. InProceedings of the 2021 conference on empirical methods in natural language processing, pages 7052–7063, 2021
2021
-
[14]
When not to trust language models: Investigating effectiveness of parametric and non-parametric memories
Alex Mallen, Akari Asai, Victor Zhong, Rajarshi Das, Daniel Khashabi, and Hannaneh Hajishirzi. When not to trust language models: Investigating effectiveness of parametric and non-parametric memories. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics, pages 9802–9822, 2023
2023
-
[15]
Ragas: Automated evaluation of retrieval augmented generation
Shahul Es, Jithin James, Luis Espinosa Anke, and Steven Schockaert. Ragas: Automated evaluation of retrieval augmented generation. InProceedings of the 18th conference of the european chapter of the association for computational linguistics: system demonstrations, pages 150–158, 2024
2024
-
[16]
Ares: An auto- mated evaluation framework for retrieval-augmented generation systems
Jon Saad-Falcon, Omar Khattab, Christopher Potts, and Matei Zaharia. Ares: An auto- mated evaluation framework for retrieval-augmented generation systems. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 338–354, 2024
2024
-
[17]
Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information processing systems, 36:46595– 46623, 2023
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information processing systems, 36:46595– 46623, 2023
2023
-
[18]
Redefining retrieval evaluation in the era of llms
Giovanni Trappolini, Florin Cuconasu, Simone Filice, Yoelle Maarek, and Fabrizio Silvestri. Redefining retrieval evaluation in the era of llms. InProceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8359–8375, 2026
2026
-
[19]
Revisiting rag retrievers: An information theoretic benchmark.arXiv preprint arXiv:2602.21553, 2026
Wenqing Zheng, Dmitri Kalaev, Noah Fatsi, Daniel Barcklow, Owen Reinert, Igor Melnyk, Senthil Kumar, and C Bayan Bruss. Revisiting rag retrievers: An information theoretic benchmark.arXiv preprint arXiv:2602.21553, 2026
-
[20]
Rageval: Scenario specific rag evaluation dataset generation framework
Kunlun Zhu, Yifan Luo, Dingling Xu, Yukun Yan, Zhenghao Liu, Shi Yu, Ruobing Wang, Shuo Wang, Yishan Li, Nan Zhang, et al. Rageval: Scenario specific rag evaluation dataset generation framework. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8520–8544, 2025
2025
-
[21]
Inference scaling law for retrieval augmented generation
Shu Zhou, Yuxuan Ao, Yunyang Xuan, Xin Wang, Tao Fan, and Hao Wang. Inference scaling law for retrieval augmented generation. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 16522–16530, 2026
2026
-
[22]
To memorize or to retrieve: Scaling laws for rag-considerate pretraining
Karan Singh, Michael Yu, Varun Gangal, Zhuofu Tao, Sachin Kumar, Emmy Liu, and Steven Y Feng. To memorize or to retrieve: Scaling laws for rag-considerate pretraining. arXiv preprint arXiv:2604.00715, 2026
-
[23]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
Suriya Gunasekar, Yi Zhang, Jyoti Aneja, Caio César Teodoro Mendes, Allie Del Giorno, Sivakanth Gopi, Mojan Javaheripi, Piero Kauffmann, Gustavo de Rosa, Olli Saarikivi, et al. Textbooks are all you need.arXiv preprint arXiv:2306.11644, 2023. 13 Preprint. Under review.B. Or|ArtificialGate Ltd
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
Small language models improve giants by rewriting their outputs
Giorgos Vernikos, Arthur Bražinskas, Jakub Adamek, Jonathan Mallinson, Aliaksei Sev- eryn, and Eric Malmi. Small language models improve giants by rewriting their outputs. InProceedings of the 18th Conference of the European Chapter of the Association for Com- putational Linguistics (Volume 1: Long Papers), pages 2703–2718, 2024
2024
-
[26]
Yi Chen, JiaHao Zhao, and HaoHao Han. A survey on collaborative mechanisms between large and small language models.arXiv preprint arXiv:2505.07460, 2025
-
[27]
Orlando Marquez Ayala, Patrice Bechard, Emily Chen, Maggie Baird, and Jingfei Chen. Fine-tune an slm or prompt an llm? the case of generating low-code workflows.arXiv preprint arXiv:2505.24189, 2025
-
[28]
RAG-RL: Advancing Retrieval-Augmented Generation via RL and Curriculum Learning
Jerry Huang, Siddarth Madala, Risham Sidhu, Cheng Niu, Hao Peng, Julia Hockenmaier, and Tong Zhang. Rag-rl: Advancing retrieval-augmented generation via rl and curriculum learning.arXiv preprint arXiv:2503.12759, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Rag-star: Enhancing deliberative reasoning with retrieval augmented verifi- cation and refinement
JinhaoJiang, JiayiChen, JunyiLi, RuiyangRen, ShijieWang, WayneXinZhao, YangSong, and Tao Zhang. Rag-star: Enhancing deliberative reasoning with retrieval augmented verifi- cation and refinement. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume ...
2025
-
[30]
Survey of hallucination in natural language generation.ACM computing surveys, 55(12):1–38, 2023
Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. Survey of hallucination in natural language generation.ACM computing surveys, 55(12):1–38, 2023
2023
-
[31]
Lost in the middle: How language models use long contexts
Nelson F Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts. Transactions of the association for computational linguistics, 12:157–173, 2024
2024
-
[32]
Adaptivechameleonorstubborn sloth: Revealing the behavior of large language models in knowledge conflicts
JianXie, KaiZhang, JiangjieChen, RenzeLou, andYuSu. Adaptivechameleonorstubborn sloth: Revealing the behavior of large language models in knowledge conflicts. InThe Twelfth International Conference on Learning Representations, 2023
2023
-
[33]
Exploring Knowledge Conflicts for Faithful LLM Reasoning: Benchmark and Method
Tianzhe Zhao et al. Exploring knowledge conflicts for faithful llm reasoning: Benchmark and method.arXiv preprint arXiv:2604.11209, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[34]
Hua Ye, Siyuan Chen, Ziqi Zhong, Canran Xiao, Haoliang Zhang, Yuhan Wu, and Fei Shen. Seeingthroughtheconflict: Transparentknowledgeconflicthandlinginretrieval-augmented generation.arXiv preprint arXiv:2601.06842, 2026
-
[35]
Large language models hallucination: A comprehen- sive survey.Computer Science Review, 61:100970, 2026
Aisha Alansari and Hamzah Luqman. Large language models hallucination: A comprehen- sive survey.Computer Science Review, 61:100970, 2026
2026
-
[36]
Mitigating Hallucinations in Large Vision-Language Models without Performance Degradation
Xingyu Zhu, Junfeng Fang, Shuo Wang, Beier Zhu, Zhicai Wang, Yonghui Yang, and Xi- angnan He. Mitigating hallucinations in large vision-language models without performance degradation.arXiv preprint arXiv:2604.20366, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[37]
Retrieval-Augmented Generation for Large Language Models: A Survey
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yixin Dai, Jiawei Sun, Haofen Wang, Haofen Wang, et al. Retrieval-augmented generation for large language models: A survey.arXiv preprint arXiv:2312.10997, 2(1):32, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[38]
Freshllms: Refreshing large language models with search engine augmentation
Tu Vu, Mohit Iyyer, Xuezhi Wang, Noah Constant, Jerry Wei, Jason Wei, Chris Tar, Yun- Hsuan Sung, Denny Zhou, Quoc Le, et al. Freshllms: Refreshing large language models with search engine augmentation. InFindings of the Association for Computational Linguistics: ACL 2024, pages 13697–13720, 2024. 14 Preprint. Under review.B. Or|ArtificialGate Ltd
2024
-
[39]
A mathematical theory of communication.The Bell system technical journal, 27(3):379–423, 1948
Claude Elwood Shannon. A mathematical theory of communication.The Bell system technical journal, 27(3):379–423, 1948
1948
-
[40]
John Wiley & Sons, 1999
Thomas M Cover.Elements of information theory. John Wiley & Sons, 1999
1999
-
[41]
Kalman-inspired runtime stability and recovery in hybrid reasoning systems
Barak Or. Kalman-inspired runtime stability and recovery in hybrid reasoning systems. arXiv preprint arXiv:2602.15855, 2026
-
[42]
Active retrieval augmented generation
Zhengbao Jiang, Frank F Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi-Yu, Yiming Yang, Jamie Callan, and Graham Neubig. Active retrieval augmented generation. In Proceedings of the 2023 conference on empirical methods in natural language processing, pages 7969–7992, 2023
2023
-
[43]
In-context retrieval-augmented language models.Transactions of the Association for Computational Linguistics, 11:1316–1331, 2023
Ori Ram, Yoav Levine, Itay Dalmedigos, Dor Muhlgay, Amnon Shashua, Kevin Leyton- Brown, and Yoav Shoham. In-context retrieval-augmented language models.Transactions of the Association for Computational Linguistics, 11:1316–1331, 2023
2023
-
[44]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025. 15
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.