SUNTA: Hierarchical Video Prediction with Surprise-based Chunking
Pith reviewed 2026-07-03 13:17 UTC · model grok-4.3
The pith
Prediction-error chunking in hierarchical state-space models sustains video forecasts over 250 timesteps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
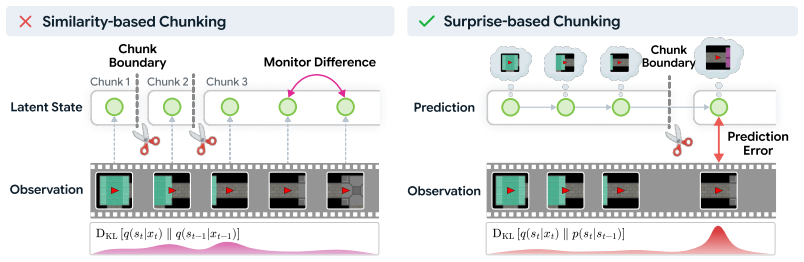
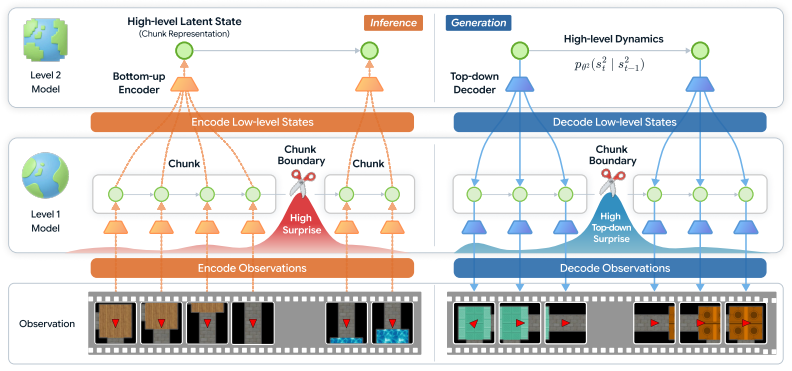
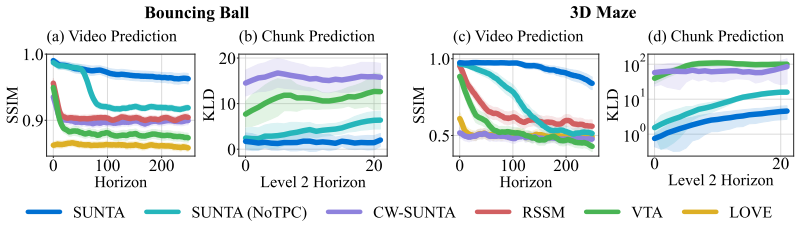
SUNTA determines chunk boundaries by treating internal inconsistency during imagined rollouts as a top-down surprise metric and applies a decoupled training strategy to keep surprise signals usable without triggering hierarchical collapse; this produces models that sustain accurate video predictions over 250 timesteps in 2D and 3D environments while all tested baselines degrade within the first 10 timesteps.
What carries the argument
Internal inconsistency within imagined rollouts functions as the top-down surprise metric that sets chunk boundaries, enabled by decoupled training that isolates surprise signal preservation from end-to-end optimization.
If this is right
- The model sustains accurate predictions over 250 timesteps in both 2D and 3D video tasks.
- Baselines that rely on fixed-length or similarity-based chunking lose accuracy within the first 10 timesteps.
- Decoupled training prevents hierarchical collapse while retaining surprise signals for boundary detection.
- Surprise-based chunking aligns boundaries more closely with intrinsic temporal structure than prior methods.
Where Pith is reading between the lines
- The same inconsistency metric could be applied to set boundaries in non-visual sequence domains such as audio or text streams.
- Longer stable rollouts would support more reliable model-based planning loops that query the predictor hundreds of steps ahead.
- One could test whether replacing internal inconsistency with other surprise proxies, such as reconstruction variance, produces comparable boundary quality.
Load-bearing premise
Internal inconsistency observed during imagined rollouts reliably marks points where longer-range context is needed and the decoupled training leaves usable surprise signals intact.
What would settle it
A direct experiment showing that SUNTA's chunk boundaries do not reduce prediction error accumulation compared with fixed-length chunking on the same video datasets, with accuracy dropping at similar rates beyond 10 timesteps.
Figures




read the original abstract
Hierarchical state-space models (HSSMs) offer a promising approach to long-horizon prediction by segmenting sequences into temporal chunks. However, their performance hinges on how chunk boundaries are determined. While prior HSSMs typically rely on fixed-length chunking or similarity-based boundary detection, these methods often misalign with the intrinsic temporal structure of the data. We argue that chunking should instead be driven by prediction errors, which more directly indicate when longer-range context becomes necessary. Nevertheless, integrating surprise-based chunking into HSSMs introduces critical challenges, including hierarchical collapse during end-to-end training and the absence of surprise signals during open-loop prediction. To address these issues, we propose Surprise-based Nested Temporal Abstraction (SUNTA), a method that employs a decoupled training strategy to preserve surprise signals and uses internal inconsistency as a top-down surprise metric to determine chunk boundaries within imagined rollouts. Experiments on video prediction tasks in 2D and 3D environments demonstrate that SUNTA outperforms baselines, uniquely maintaining accurate predictions over 250 timesteps, whereas all baselines degrade within the first 10 timesteps.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Surprise-based Nested Temporal Abstraction (SUNTA), a hierarchical state-space model for long-horizon video prediction. Chunk boundaries are set using internal inconsistency during imagined rollouts as a top-down surprise metric. A decoupled training strategy is introduced to avoid hierarchical collapse in end-to-end training and to preserve usable surprise signals in open-loop prediction. Experiments on 2D and 3D video prediction tasks are reported to show that SUNTA sustains accurate predictions for 250 timesteps while all baselines degrade within the first 10 timesteps.
Significance. If the reported long-horizon results hold under scrutiny, the work would offer a concrete mechanism for aligning temporal chunking with intrinsic prediction-error structure rather than fixed lengths or similarity, addressing a recurring limitation in hierarchical state-space models for video.
major comments (1)
- [Abstract] Abstract: the 250-timestep performance claim rests entirely on the decoupled training strategy successfully preserving surprise signals without new instabilities during open-loop rollouts. The abstract identifies hierarchical collapse and missing surprise signals as the two critical challenges yet provides no equations, pseudocode, or verification procedure for the decoupling step, so it is impossible to determine whether the reported advantage follows from the method or from an unstated implementation detail.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for clarity on how the decoupled training strategy is specified. The abstract is a high-level summary; the full technical description, including equations and procedure, appears in the manuscript body. We address the point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the 250-timestep performance claim rests entirely on the decoupled training strategy successfully preserving surprise signals without new instabilities during open-loop rollouts. The abstract identifies hierarchical collapse and missing surprise signals as the two critical challenges yet provides no equations, pseudocode, or verification procedure for the decoupling step, so it is impossible to determine whether the reported advantage follows from the method or from an unstated implementation detail.
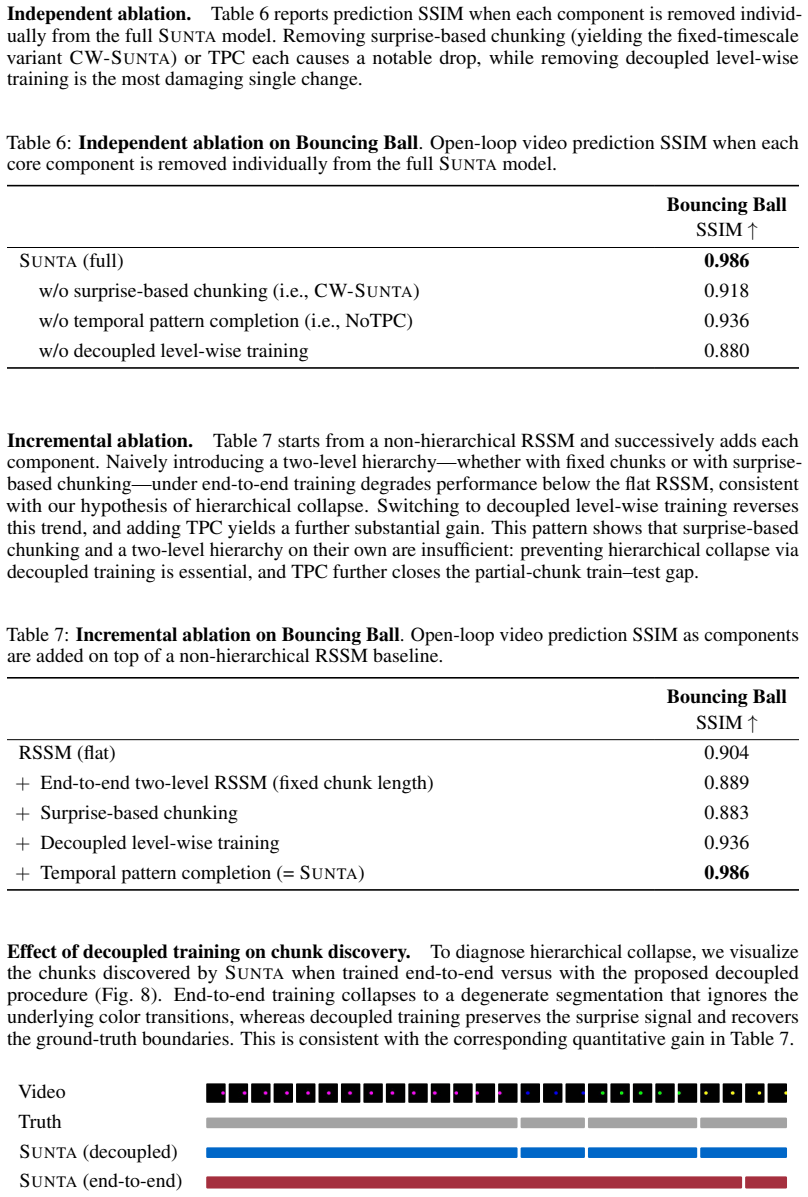
Authors: The abstract follows standard conventions by summarizing the two challenges and the high-level solution without equations or pseudocode. The decoupled training strategy is fully specified in Section 3.2 (Equations 4–7) together with Algorithm 1, which details the alternating optimization that prevents hierarchical collapse while keeping surprise signals available during open-loop rollouts. The verification procedure is the open-loop video-prediction protocol reported in Sections 4.2–4.3, where SUNTA alone sustains accuracy to 250 timesteps. No implementation detail is left unstated; the performance difference is therefore attributable to the described method. If the referee prefers an explicit cross-reference in the abstract, we can add one sentence directing readers to Section 3.2. revision: partial
Circularity Check
No significant circularity in derivation chain
full rationale
The paper proposes SUNTA to solve hierarchical collapse and missing surprise signals via decoupled training plus internal inconsistency as a top-down metric for chunk boundaries in imagined rollouts. No equations, self-definitions, or fitted-input-as-prediction reductions appear in the provided text. Performance claims rest on external experimental benchmarks (250-timestep accuracy vs. baselines collapsing at 10 steps), not on any quantity being renamed or forced by construction from the inputs. The derivation is therefore self-contained against the reported results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Prediction error is a more direct indicator of when longer-range context is needed than fixed length or similarity.
Reference graph
Works this paper leans on
-
[1]
Aakur and Sudeep Sarkar
Sathyanarayanan N. Aakur and Sudeep Sarkar. A perceptual prediction framework for self supervised event segmentation. In2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019
2019
-
[2]
xLSTM: Extended long short-term memory
Maximilian Beck, Korbinian Pöppel, Markus Spanring, Andreas Auer, Oleksandra Prudnikova, Michael Kopp, Günter Klambauer, Johannes Brandstetter, and Sepp Hochreiter. xLSTM: Extended long short-term memory. InAdvances in Neural Information Processing Systems, 2024
2024
-
[3]
Real-Time Execution of Action Chunking Flow Policies
Kevin Black, Manuel Y . Galliker, and Sergey Levine. Real-time execution of action chunking flow policies, 2025. URLhttps://arxiv.org/abs/2506.07339
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Botvinick
Matthew M. Botvinick. Hierarchical models of behavior and prefrontal function.Trends in Cognitive Sciences, 12(5), 2008
2008
-
[5]
Chase and Herbert A
William G. Chase and Herbert A. Simon. Perception in chess.Cognitive Psychology, 4(1),
-
[6]
doi: https://doi.org/10.1016/0010-0285(73)90004-2
ISSN 0010-0285. doi: https://doi.org/10.1016/0010-0285(73)90004-2
-
[7]
Hierarchical deep generative models for multi-rate multivariate time series
Zhengping Che, Sanjay Purushotham, Guangyu Li, Bo Jiang, and Yan Liu. Hierarchical deep generative models for multi-rate multivariate time series. In Jennifer Dy and Andreas Krause, editors,Proceedings of the 35th International Conference on Machine Learning, volume 80 of Proceedings of Machine Learning Research. PMLR, 10–15 Jul 2018
2018
-
[8]
Maxime Chevalier-Boisvert, Bolun Dai, Mark Towers, Rodrigo de Lazcano, Lucas Willems, Salem Lahlou, Suman Pal, Pablo Samuel Castro, and Jordan Terry. Minigrid & miniworld: Modular & customizable reinforcement learning environments for goal-oriented tasks.CoRR, abs/2306.13831, 2023
-
[9]
Hierarchical multiscale recurrent neural networks
Junyoung Chung, Sungjin Ahn, and Yoshua Bengio. Hierarchical multiscale recurrent neural networks. InInternational Conference on Learning Representations, 2017
2017
-
[10]
Moran, Yukie Nagai, Tadahiro Taniguchi, Hiroaki Gomi, and Josh Tenenbaum
Karl Friston, Rosalyn J. Moran, Yukie Nagai, Tadahiro Taniguchi, Hiroaki Gomi, and Josh Tenenbaum. World model learning and inference.Neural Networks, 144, 2021. ISSN 0893-6080. doi: https://doi.org/10.1016/j.neunet.2021.09.011
-
[11]
A new algorithm for data compression.C Users J., 12(2), February 1994
Philip Gage. A new algorithm for data compression.C Users J., 12(2), February 1994. ISSN 0898-9788
1994
-
[12]
Christian Gumbsch, Noor Sajid, Georg Martius, and Martin V . Butz. Learning hierarchical world models with adaptive temporal abstractions from discrete latent dynamics. InInternational Conference on Learning Representations, 2024
2024
-
[13]
Recurrent world models facilitate policy evolution
David Ha and Jürgen Schmidhuber. Recurrent world models facilitate policy evolution. In Advances in Neural Information Processing Systems, volume 31, 2018
2018
-
[14]
Learning latent dynamics for planning from pixels
Danijar Hafner, Timothy Lillicrap, Ian Fischer, Ruben Villegas, David Ha, Honglak Lee, and James Davidson. Learning latent dynamics for planning from pixels. InProceedings of the 36th International Conference on Machine Learning, volume 97, 2019
2019
-
[15]
Dream to control: Learning behaviors by latent imagination
Danijar Hafner, Timothy Lillicrap, Jimmy Ba, and Mohammad Norouzi. Dream to control: Learning behaviors by latent imagination. InInternational Conference on Learning Representa- tions, 2020
2020
-
[16]
Mastering atari with discrete world models
Danijar Hafner, Timothy P Lillicrap, Mohammad Norouzi, and Jimmy Ba. Mastering atari with discrete world models. InInternational Conference on Learning Representations, 2021
2021
-
[17]
Deep hierarchical planning from pixels
Danijar Hafner, Kuang-Huei Lee, Ian Fischer, and Pieter Abbeel. Deep hierarchical planning from pixels. InAdvances in Neural Information Processing Systems, volume 35, 2022
2022
-
[18]
Mastering Diverse Domains through World Models
Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Timothy Lillicrap. Mastering diverse domains through world models.arXiv preprint arXiv:2301.04104, 2023. 10
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
Training Agents Inside of Scalable World Models
Danijar Hafner, Wilson Yan, and Timothy Lillicrap. Training agents inside of scalable world models, 2025. URLhttps://arxiv.org/abs/2509.24527
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
TD-MPC2: Scalable, robust world models for continuous control
Nicklas Hansen, Hao Su, and Xiaolong Wang. TD-MPC2: Scalable, robust world models for continuous control. InInternational Conference on Learning Representations, 2024
2024
-
[21]
Temporal difference learning for model predictive control
Nicklas A Hansen, Hao Su, and Xiaolong Wang. Temporal difference learning for model predictive control. InProceedings of the 39th International Conference on Machine Learning, volume 162, 2022
2022
-
[22]
Times Books, 2004
Jeff Hawkins and Sandra Blakeslee.On Intelligence. Times Books, 2004. ISBN 0805074562
2004
-
[23]
Hierarchical recurrent neural networks for long-term dependen- cies
Salah Hihi and Yoshua Bengio. Hierarchical recurrent neural networks for long-term dependen- cies. InAdvances in Neural Information Processing Systems, volume 8, 1995
1995
-
[24]
Oxford University Press, 2013
Jakob Hohwy.The Predictive Mind. Oxford University Press, 2013
2013
-
[25]
Dynamic chunking for end-to-end hierarchical sequence modeling, 2025
Sukjun Hwang, Brandon Wang, and Albert Gu. Dynamic chunking for end-to-end hierarchical sequence modeling, 2025. URLhttps://arxiv.org/abs/2507.07955
-
[26]
Zico Kolter, and Chelsea Finn
Yiding Jiang, Evan Liu, Benjamin Eysenbach, J. Zico Kolter, and Chelsea Finn. Learning options via compression. InAdvances in Neural Information Processing Systems, volume 35, 2022
2022
-
[27]
Variational temporal abstraction
Taesup Kim, Sungjin Ahn, and Yoshua Bengio. Variational temporal abstraction. InAdvances in Neural Information Processing Systems, volume 32, 2019
2019
-
[28]
A clockwork rnn
Jan Koutnik, Klaus Greff, Faustino Gomez, and Juergen Schmidhuber. A clockwork rnn. In Proceedings of the 31st International Conference on Machine Learning, volume 32, 2014
2014
-
[29]
A path towards autonomous machine intelligence.OpenReview Archive Preprint, 2022
Yann LeCun. A path towards autonomous machine intelligence.OpenReview Archive Preprint, 2022
2022
-
[30]
Reinforcement learning with action chunking,
Qiyang Li, Zhiyuan Zhou, and Sergey Levine. Reinforcement learning with action chunking,
-
[31]
URLhttps://arxiv.org/abs/2507.07969
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
Hieros: Hierarchical imagination on struc- tured state space sequence world models
Paul Mattes, Rainer Schlosser, and Ralf Herbrich. Hieros: Hierarchical imagination on struc- tured state space sequence world models. InProceedings of the 41st International Conference on Machine Learning, volume 235, 2024
2024
-
[33]
Linking fast and slow: The case for generative models.Network Neuroscience, 8, 2024
Johan Medrano, Karl Friston, and Peter Zeidman. Linking fast and slow: The case for generative models.Network Neuroscience, 8, 2024
2024
-
[34]
George A. Miller. The magical number seven, plus or minus two: Some limits on our capacity for processing information.The Psychological Review, 63(2), March 1956
1956
-
[35]
A taxonomy of surprise definitions
Alireza Modirshanechi, Johanni Brea, and Wulfram Gerstner. A taxonomy of surprise definitions. Journal of Mathematical Psychology, 110, 2022. ISSN 0022-2496. doi: https://doi.org/10.1016/ j.jmp.2022.102712
-
[36]
Streamer: Streaming representation learning and event segmentation in a hierarchical manner
Ramy Mounir, Sujal Vijayaraghavan, and Sudeep Sarkar. Streamer: Streaming representation learning and event segmentation in a hierarchical manner. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural Information Processing Systems, volume 36. Curran Associates, Inc., 2023
2023
-
[37]
Fast-slow recurrent neural networks
Asier Mujika, Florian Meier, and Angelika Steger. Fast-slow recurrent neural networks. In Advances in Neural Information Processing Systems, volume 30, 2017
2017
-
[38]
Artidoro Pagnoni, Ram Pasunuru, Pedro Rodriguez, John Nguyen, Benjamin Muller, Margaret Li, Chunting Zhou, Lili Yu, Jason Weston, Luke Zettlemoyer, Gargi Ghosh, Mike Lewis, Ari Holtzman, and Srinivasan Iyer. Byte latent transformer: Patches scale better than tokens, 2024. URLhttps://arxiv.org/abs/2412.09871. 11
-
[39]
Karl Pertsch, Oleh Rybkin, Frederik Ebert, Chelsea Finn, Dinesh Jayaraman, and Sergey Levine. Long-horizon visual planning with goal-conditioned hierarchical predictors.arXiv preprint arXiv:2006.13205, 2020
-
[40]
Rajesh P. N. Rao and Dana H. Ballard. Predictive coding in the visual cortex: a functional interpretation of some extra-classical receptive-field effects.Nature Neuroscience, 2(1), 1999. doi: 10.1038/4580
-
[41]
Clockwork variational autoencoders
Vaibhav Saxena, Jimmy Ba, and Danijar Hafner. Clockwork variational autoencoders. In Advances in Neural Information Processing Systems, volume 34, 2021
2021
-
[42]
Jürgen Schmidhuber. Learning complex, extended sequences using the principle of history compression.Neural Computation, 4(2), 1992. doi: 10.1162/neco.1992.4.2.234
-
[43]
Multi time scale world models
Vaisakh Shaj, Saleh Gholam Zadeh, Ozan Demir, Luiz Ricardo Douat, and Gerhard Neumann. Multi time scale world models. InAdvances in Neural Information Processing Systems, volume 36, 2023
2023
-
[44]
Richard S. Sutton. TD Models: Modeling the World at a Mixture of Time Scales. InProceedings of the 12th International Conference on Machine Learning. Morgan Kaufmann, 1995. ISBN 1-55860-377-8
1995
-
[45]
Sutton, Doina Precup, and Satinder Singh
Richard S. Sutton, Doina Precup, and Satinder Singh. Between mdps and semi-mdps: A framework for temporal abstraction in reinforcement learning.Artificial Intelligence, 112(1), 1999
1999
-
[46]
Adopt: Modified adam can converge with any β2 with the optimal rate
Shohei Taniguchi, Keno Harada, Gouki Minegishi, Yuta Oshima, Seong Cheol Jeong, Go Naga- hara, Tomoshi Iiyama, Masahiro Suzuki, Yusuke Iwasawa, and Yutaka Matsuo. Adopt: Modified adam can converge with any β2 with the optimal rate. InAdvances in Neural Information Processing Systems, 2024
2024
-
[47]
Learning structure from the ground up—hierarchical representation learning by chunking
Shuchen Wu, Noemi Elteto, Ishita Dasgupta, and Eric Schulz. Learning structure from the ground up—hierarchical representation learning by chunking. InAdvances in Neural Informa- tion Processing Systems, volume 35, 2022
2022
-
[48]
Yuichi Yamashita and Jun Tani. Emergence of functional hierarchy in a multiple timescale neural network model: A humanoid robot experiment.PLOS Computational Biology, 4, 2008. doi: 10.1371/journal.pcbi.1000220
-
[49]
Megabyte: Predicting million-byte sequences with multiscale transformers
LILI YU, Daniel Simig, Colin Flaherty, Armen Aghajanyan, Luke Zettlemoyer, and Mike Lewis. Megabyte: Predicting million-byte sequences with multiscale transformers. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural Information Processing Systems, volume 36. Curran Associates, Inc., 2023
2023
-
[50]
Event perception: a mind-brain perspective.Psychological bulletin, 133(2), March 2007
Jeffrey M Zacks, Nicole K Speer, Khena M Swallow, Todd S Braver, and Jeremy R Reynolds. Event perception: a mind-brain perspective.Psychological bulletin, 133(2), March 2007. ISSN 0033-2909. doi: 10.1037/0033-2909.133.2.273
-
[51]
Episodic memory for subjective- timescale models
Alexey Zakharov, Matthew Crosby, and Zafeirios Fountas. Episodic memory for subjective- timescale models. InICML 2021 Workshop on Unsupervised Reinforcement Learning, 2021
2021
-
[52]
Variational predictive routing with nested subjective timescales
Alexey Zakharov, Qinghai Guo, and Zafeirios Fountas. Variational predictive routing with nested subjective timescales. InInternational Conference on Learning Representations, 2022. 12 A Hyperparameters Table 3 summarizes the hyperparameters used in our main experiments. Unless otherwise stated, the same values are used across all datasets. Table 3:Hyperpa...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.