GeoSearcher: Anchor-Guided Progressive Reasoning for Remote Sensing Visual Grounding with Process Supervision
Pith reviewed 2026-07-02 13:50 UTC · model grok-4.3
The pith
GeoSearcher uses anchor-guided progressive reasoning to help models find small targets in large remote sensing images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central discovery is that anchor-centric reasoning data combined with process-faithful optimization allows the model to represent key visual clues as anchors and progressively integrate location, relational, and attribute clues, transforming large-scale visual search into constrained local reasoning and outperforming prior one-step methods on multiple benchmarks.
What carries the argument
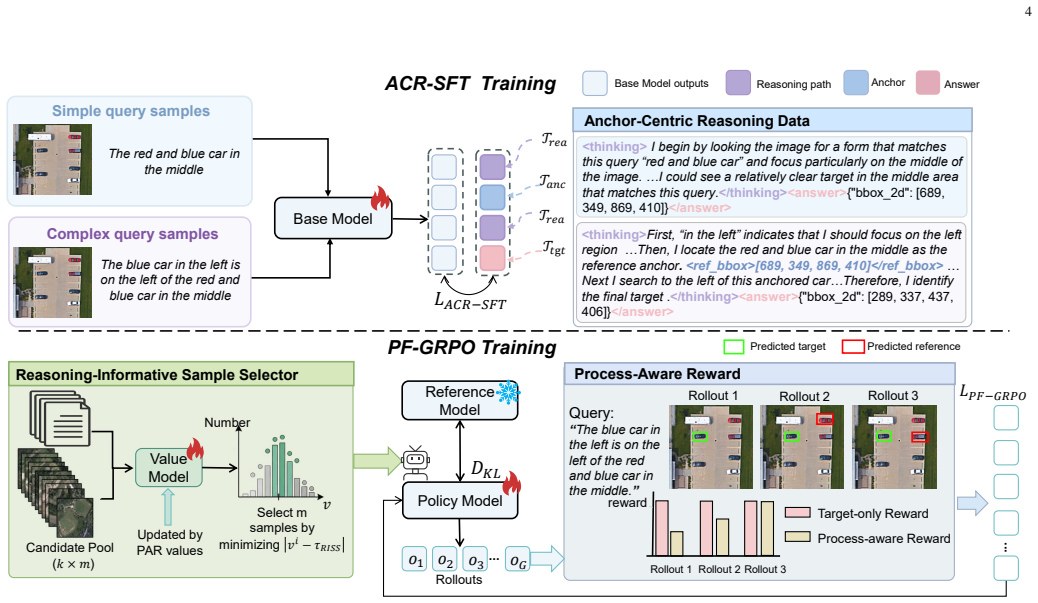
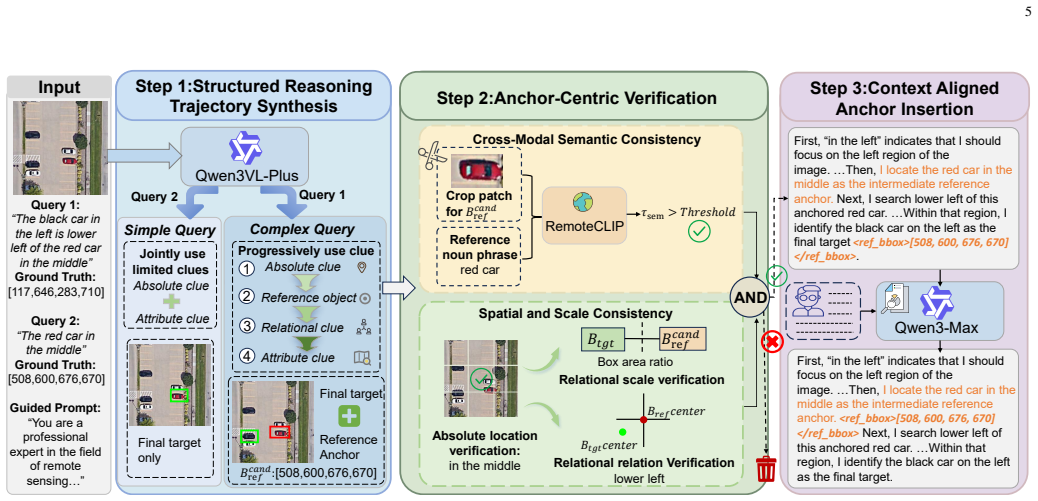
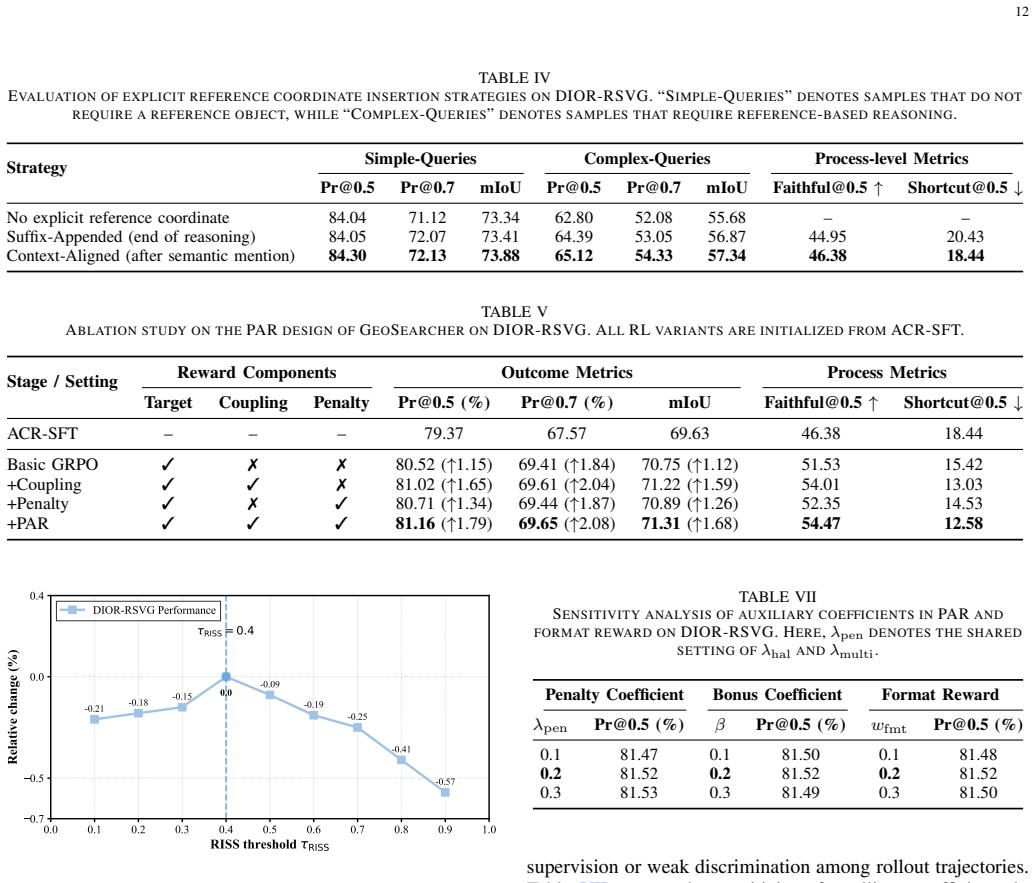
The anchor-guided progressive reasoning process, implemented via Anchor-Centric Reasoning Supervised Fine-Tuning to teach anchor representation and Process-Faithful Group Relative Policy Optimization to refine reasoning behavior with process-aware rewards.
If this is right
- Transforms the global search in large scenes into a series of local reasoning steps around anchors.
- Improves stability for localizing extremely small targets surrounded by similar distractors.
- Handles queries with multiple clues by progressively integrating them rather than in one step.
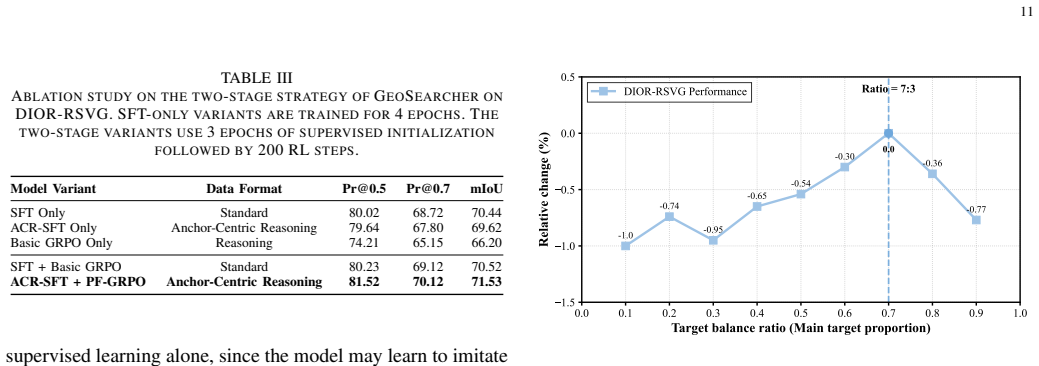
- Shows superior results on DIOR-RSVG, OPT-RSVG, and VRS-Bench compared to existing methods.
Where Pith is reading between the lines
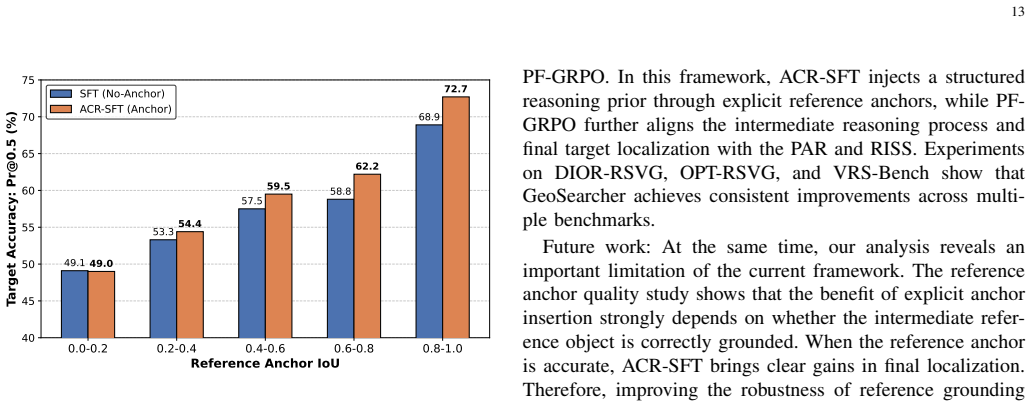
- Similar anchoring techniques might help in other visual grounding tasks involving scale differences, such as finding small items in high-resolution photos.
- The emphasis on process supervision could be applied to reduce errors in other coordinate prediction tasks for language models.
- Testing on even larger scenes or real-time applications would reveal if the progressive steps add computational overhead.
Load-bearing premise
That the generated anchor-centric reasoning data and the process-aware rewards will consistently enable the model to integrate clues effectively for accurate small object localization.
What would settle it
Running the model on a held-out set of remote sensing images with queries designed to have highly ambiguous anchors or more distractors, checking if performance gains disappear compared to baseline one-step models.
Figures





read the original abstract
Recent multimodal large language models (MLLMs) have shown strong cross-modal understanding and coordinate generation abilities in visual grounding. However, transferring these abilities to remote sensing visual grounding (RSVG) remains challenging. High-resolution remote sensing images usually cover large-scale scenes, where targets are often extremely small and surrounded by numerous visually similar distractors. Meanwhile, queries often contain multiple clues, such as reference objects, spatial relations, and target attributes. Existing MLLM-based methods usually formulate RSVG as one-step coordinate generation, which may lead to unstable predictions for small-object localization and complex queries. To address these challenges, we propose GeoSearcher, which reformulates RSVG as an anchor-guided progressive reasoning process and realizes it through two coupled stages: Anchor-Centric Reasoning Supervised Fine-Tuning (ACR-SFT) and Process-Faithful Group Relative Policy Optimization (PF-GRPO). In ACR-SFT, anchor-centric reasoning data are used to teach the model to represent key visual clues as anchors and progressively integrate location, relational, and attribute clues around them. In PF-GRPO, Process-Aware Reward (PAR) and Reasoning-Informative Sample Selector (RISS) further optimize this reasoning behavior by jointly evaluating key reasoning steps and target localization, while focusing training on samples that are more beneficial for improving progressive reasoning. Through this design, GeoSearcher transforms large-scale visual search into a more constrained local reasoning process. Extensive experiments on DIOR-RSVG, OPT-RSVG, and VRS-Bench show that GeoSearcher outperforms existing state-of-the-art methods. The project will be released at https://github.com/wangdianyu954-xixi/GeoSearcher.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes GeoSearcher for remote sensing visual grounding (RSVG), reformulating the task as anchor-guided progressive reasoning implemented via two stages: Anchor-Centric Reasoning Supervised Fine-Tuning (ACR-SFT), which trains models to represent key visual clues as anchors and progressively integrate location, relational, and attribute clues, and Process-Faithful Group Relative Policy Optimization (PF-GRPO), which uses Process-Aware Reward (PAR) and Reasoning-Informative Sample Selector (RISS) to jointly optimize reasoning steps and target localization while focusing on informative samples. Experiments on DIOR-RSVG, OPT-RSVG, and VRS-Bench are reported to show outperformance over existing state-of-the-art MLLM-based methods for small-object localization in large scenes with multi-clue queries.
Significance. If the reported gains hold under rigorous evaluation, the work could meaningfully advance MLLM applications in remote sensing by shifting from unstable one-step coordinate prediction to constrained local progressive reasoning, with direct relevance to small-target detection amid distractors. The explicit use of process supervision and the planned public release of code and data at the cited GitHub repository are strengths that support reproducibility and further research.
minor comments (2)
- [Abstract] Abstract: the claim of transforming 'large-scale visual search into a more constrained local reasoning process' would benefit from a brief concrete example of how an anchor is initialized and updated across steps.
- The manuscript would be strengthened by an explicit statement of the base MLLM architecture and any modifications to its coordinate generation head.
Simulated Author's Rebuttal
We thank the referee for their positive review, recognition of the significance of shifting to constrained progressive reasoning for RSVG, and recommendation to accept. We appreciate the acknowledgment of the reproducibility strengths via planned code and data release.
Circularity Check
No significant circularity
full rationale
The paper describes an empirical training procedure (ACR-SFT followed by PF-GRPO) that reformulates RSVG as anchor-guided progressive reasoning. No equations, derivations, or parameter-fitting steps appear in the abstract or described method. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The central claims rest on experimental comparisons to external benchmarks rather than any reduction of outputs to inputs by construction. This is the most common honest finding for a purely empirical methods paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
J. Bai, S. Bai, S. Yang, S. Wang, S. Tan, P. Wang, J. Lin, C. Zhou, and J. Zhou, “Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond,” 2023. [Online]. Available: https://arxiv.org/abs/2308.12966
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Minigpt-v2: large language model as a unified interface for vision-language multi-task learning,
J. Chen, D. Zhu, X. Shen, X. Li, Z. Liu, P. Zhang, R. Krishnamoorthi, V . Chandra, Y . Xiong, and M. Elhoseiny, “Minigpt-v2: large language model as a unified interface for vision-language multi-task learning,”
-
[3]
MiniGPT-v2: large language model as a unified interface for vision-language multi-task learning
[Online]. Available: https://arxiv.org/abs/2310.09478
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Visual instruction tuning,
H. Liu, C. Li, Q. Wu, and Y . J. Lee, “Visual instruction tuning,” Advances in neural information processing systems, vol. 36, pp. 34 892– 34 916, 2023
2023
-
[5]
Geochat: Grounded large vision-language model for remote sensing,
K. Kuckreja, M. S. Danish, M. Naseer, A. Das, S. Khan, and F. S. Khan, “Geochat: Grounded large vision-language model for remote sensing,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 27 831–27 840
2024
-
[6]
arXiv preprint arXiv:2411.11904 , year=
Y . Zhou, M. Lan, X. Li, L. Feng, Y . Ke, X. Jiang, Q. Li, X. Yang, and W. Zhang, “Geoground: A unified large vision-language model for remote sensing visual grounding,”arXiv preprint arXiv:2411.11904, 2024
-
[7]
arXiv preprint arXiv:2406.10100 , year=
J. Luo, Z. Pang, Y . Zhang, T. Wang, L. Wang, B. Dang, J. Lao, J. Wang, J. Chen, Y . Tanet al., “Skysensegpt: A fine-grained instruction tuning dataset and model for remote sensing vision-language understanding,” arXiv preprint arXiv:2406.10100, 2024
-
[8]
Language-guided progressive attention for visual grounding in remote sensing images,
K. Li, D. Wang, H. Xu, H. Zhong, and C. Wang, “Language-guided progressive attention for visual grounding in remote sensing images,” IEEE Trans. Geosci. Remote Sens., vol. 62, pp. 1–13, 2024
2024
-
[9]
A. Jaech, A. Kalai, A. Lerer, A. Richardson, A. El-Kishky, A. Low, A. Helyar, A. Madry, A. Beutel, A. Carneyet al., “Openai o1 system card,”arXiv preprint arXiv:2412.16720, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
D. Guo, D. Yang, H. Zhang, J. Song, P. Wang, Q. Zhu, R. Xu, R. Zhang, S. Ma, X. Biet al., “Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning,”arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
arXiv preprint arXiv:2509.25026 , year=
M. Fiaz, H. Debary, P. Fraccaro, D. Paudel, L. Van Gool, F. Khan, and S. Khan, “Geovlm-r1: Reinforcement fine-tuning for improved remote sensing reasoning,”arXiv preprint arXiv:2509.25026, 2025
-
[12]
VLM-R1: A Stable and Generalizable R1-style Large Vision-Language Model
H. Shen, P. Liu, J. Li, C. Fang, Y . Ma, J. Liao, Q. Shen, Z. Zhang, K. Zhao, Q. Zhanget al., “Vlm-r1: A stable and generalizable r1-style large vision-language model,”arXiv preprint arXiv:2504.07615, 2025. 14
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Remotereasoner: Towards unifying geospatial reasoning workflow,
L. Yao, F. Liu, H. Lu, C. Zhang, R. Min, S. Xu, S. Di, and P. Peng, “Remotereasoner: Towards unifying geospatial reasoning workflow,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 40, no. 14, 2026, pp. 11 883–11 891
2026
-
[14]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, X. Bi, H. Zhang, M. Zhang, Y . Li, Y . Wuet al., “Deepseekmath: Pushing the limits of mathematical reasoning in open language models,”arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Rsground-r1: Rethinking remote sensing visual grounding through spatial reasoning,
S. Huang, S. He, and B. Wen, “Rsground-r1: Rethinking remote sensing visual grounding through spatial reasoning,”arXiv preprint arXiv:2601.21634, 2026
-
[16]
arXiv preprint arXiv:2505.14231 , year=
S. Bai, M. Li, Y . Liu, J. Tang, H. Zhang, L. Sun, X. Chu, and Y . Tang, “Univg-r1: Reasoning guided universal visual grounding with reinforcement learning,”arXiv preprint arXiv:2505.14231, 2025
-
[17]
Tinyrs-r1: Compact vision language model for remote sensing,
A. K ¨oksal and A. A. Alatan, “Tinyrs-r1: Compact vision language model for remote sensing,”IEEE Geosci. Remote Sens. Lett., vol. 22, pp. 1–5, 2025
2025
-
[18]
Geozero: Incentivizing reasoning from scratch on geospatial scenes,
D. Wang, S. Liu, W. Jiang, F. Wang, Y . Liu, X. Qin, Z. Luo, C. Zhou, H. Guo, J. Zhanget al., “Geozero: Incentivizing reasoning from scratch on geospatial scenes,”arXiv preprint arXiv:2511.22645, 2025
-
[19]
Rsvg: Exploring data and models for visual grounding on remote sensing data,
Y . Zhan, Z. Xiong, and Y . Yuan, “Rsvg: Exploring data and models for visual grounding on remote sensing data,”IEEE Trans. Geosci. Remote Sens., vol. 61, pp. 1–13, 2023
2023
-
[20]
Vrsbench: A versatile vision-language benchmark dataset for remote sensing image understanding,
X. Li, J. Ding, and M. Elhoseiny, “Vrsbench: A versatile vision-language benchmark dataset for remote sensing image understanding,”Advances in Neural Information Processing Systems, vol. 37, pp. 3229–3242, 2024
2024
-
[21]
Visual grounding in remote sensing images,
Y . Sun, S. Feng, X. Li, Y . Ye, J. Kang, and X. Huang, “Visual grounding in remote sensing images,” inProceedings of the 30th ACM International conference on Multimedia, 2022, pp. 404–412
2022
-
[22]
Language query-based transformer with multiscale cross-modal alignment for visual grounding on remote sensing images,
M. Lan, F. Rong, H. Jiao, Z. Gao, and L. Zhang, “Language query-based transformer with multiscale cross-modal alignment for visual grounding on remote sensing images,”IEEE Trans. Geosci. Remote Sens., vol. 62, pp. 1–13, 2024
2024
-
[23]
Shikra: Unleashing Multimodal LLM's Referential Dialogue Magic
K. Chen, Z. Zhang, W. Zeng, R. Zhang, F. Zhu, and R. Zhao, “Shikra: Unleashing multimodal llm’s referential dialogue magic,”arXiv preprint arXiv:2306.15195, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
Ferret: Refer and Ground Anything Anywhere at Any Granularity
H. You, H. Zhang, Z. Gan, X. Du, B. Zhang, Z. Wang, L. Cao, S.-F. Chang, and Y . Yang, “Ferret: Refer and ground anything anywhere at any granularity,”arXiv preprint arXiv:2310.07704, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
Kosmos-2: Grounding Multimodal Large Language Models to the World
Z. Peng, W. Wang, L. Dong, Y . Hao, S. Huang, S. Ma, and F. Wei, “Kosmos-2: Grounding multimodal large language models to the world,” arXiv preprint arXiv:2306.14824, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
Lhrs-bot: Empowering remote sensing with vgi-enhanced large multimodal language model,
D. Muhtar, Z. Li, F. Gu, X. Zhang, and P. Xiao, “Lhrs-bot: Empowering remote sensing with vgi-enhanced large multimodal language model,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 440– 457
2024
-
[27]
H2rsvlm: Towards helpful and honest remote sensing large vision language model,
C. Pang, J. Wu, J. Li, Y . Liu, J. Sun, W. Li, X. Weng, S. Wang, L. Feng, G.-S. Xiaet al., “H2rsvlm: Towards helpful and honest remote sensing large vision language model,”arXiv preprint arXiv:2403.20213, 2024
-
[28]
Earthgpt: A universal multimodal large language model for multisensor image comprehension in remote sensing domain,
W. Zhang, M. Cai, T. Zhang, Y . Zhuang, and X. Mao, “Earthgpt: A universal multimodal large language model for multisensor image comprehension in remote sensing domain,”IEEE Trans. Geosci. Remote Sens., vol. 62, pp. 1–20, 2024
2024
-
[29]
arXiv preprint arXiv:2501.13925 , year =
A. Shabbir, M. Zumri, M. Bennamoun, F. S. Khan, and S. Khan, “Geopixel: Pixel grounding large multimodal model in remote sensing,” arXiv preprint arXiv:2501.13925, 2025
-
[30]
Asking like Socrates: Socrates helps VLMs understand remote sensing images
R. Shao, Z. Li, Z. Zhang, L. Xu, X. He, H. Yuan, B. He, Y . Dai, Y . Yan, Y . Chenet al., “Asking like socrates: Socrates helps vlms understand remote sensing images,”arXiv preprint arXiv:2511.22396, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
H. Hu, P. Wang, Y . Feng, K. Wei, W. Yin, W. Diao, M. Wang, H. Bi, K. Kang, T. Linget al., “Ringmo-agent: A unified remote sensing foundation model for multi-platform and multi-modal reasoning,”arXiv preprint arXiv:2507.20776, 2025
-
[32]
arXiv preprint arXiv:2509.22221 , year=
J. Liu, L. Sun, R. Fu, and B. Yang, “Towards faithful reasoning in remote sensing: A perceptually-grounded geospatial chain-of-thought for vision- language models,”arXiv preprint arXiv:2509.22221, 2025
-
[33]
Z. Zhang, Z. Guan, T. Zhao, H. Shen, T. Li, Y . Cai, Z. Su, Z. Liu, J. Yin, and X. Li, “Geo-r1: Improving few-shot geospatial referring expression understanding with reinforcement fine-tuning,”arXiv preprint arXiv:2509.21976, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Direct preference optimization: Your language model is secretly a reward model,
R. Rafailov, A. Sharma, E. Mitchell, C. D. Manning, S. Ermon, and C. Finn, “Direct preference optimization: Your language model is secretly a reward model,”Advances in neural information processing systems, vol. 36, pp. 53 728–53 741, 2023
2023
-
[35]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Prox- imal policy optimization algorithms,”arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[36]
W. Hong, W. Yu, X. Gu, G. Wang, G. Gan, H. Tang, J. Cheng, J. Qi, J. Ji, L. Panet al., “Glm-4.5 v and glm-4.1 v-thinking: Towards versatile multimodal reasoning with scalable reinforcement learning,” arXiv preprint arXiv:2507.01006, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Kimi K2: Open Agentic Intelligence
K. Team, Y . Bai, Y . Bao, Y . Charles, C. Chen, G. Chen, H. Chen, H. Chen, J. Chen, N. Chenet al., “Kimi k2: Open agentic intelligence,” arXiv preprint arXiv:2507.20534, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
Remoteclip: A vision language foundation model for remote sensing,
F. Liu, D. Chen, Z. Guan, X. Zhou, J. Zhu, Q. Ye, L. Fu, and J. Zhou, “Remoteclip: A vision language foundation model for remote sensing,” IEEE Trans. Geosci. Remote Sens., vol. 62, pp. 1–16, 2024
2024
-
[39]
S. Bai, Y . Cai, R. Chen, K. Chen, X. Chen, Z. Cheng, L. Deng, W. Ding, C. Gao, C. Geet al., “Qwen3-vl technical report,”arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
Llamafactory: Unified efficient fine-tuning of 100+ language models,
Y . Zheng, R. Zhang, J. Zhang, Y . Ye, and Z. Luo, “Llamafactory: Unified efficient fine-tuning of 100+ language models,” inProceedings of the 62nd annual meeting of the association for computational linguistics (volume 3: system demonstrations), 2024, pp. 400–410
2024
-
[41]
Hybridflow: A flexible and efficient rlhf framework,
G. Sheng, C. Zhang, Z. Ye, X. Wu, W. Zhang, R. Zhang, Y . Peng, H. Lin, and C. Wu, “Hybridflow: A flexible and efficient rlhf framework,” inProceedings of the Twentieth European Conference on Computer Systems, 2025, pp. 1279–1297
2025
-
[42]
Deepspeed: System optimizations enable training deep learning models with over 100 billion parameters,
J. Rasley, S. Rajbhandari, O. Ruwase, and Y . He, “Deepspeed: System optimizations enable training deep learning models with over 100 billion parameters,” inProceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining, 2020, pp. 3505– 3506
2020
-
[43]
A. Singh, A. Fry, A. Perelman, A. Tart, A. Ganesh, A. El-Kishky, A. McLaughlin, A. Low, A. Ostrow, A. Ananthramet al., “Openai gpt-5 system card,”arXiv preprint arXiv:2601.03267, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[44]
S. Bai, K. Chen, X. Liu, J. Wang, W. Ge, S. Song, K. Dang, P. Wang, S. Wang, J. Tang, H. Zhong, Y . Zhu, M. Yang, Z. Li, J. Wan, P. Wang, W. Ding, Z. Fu, Y . Xu, J. Ye, X. Zhang, T. Xie, Z. Cheng, H. Zhang, Z. Yang, H. Xu, and J. Lin, “Qwen2.5-vl technical report,” 2025. [Online]. Available: https://arxiv.org/abs/2502.13923
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
W. Wang, Z. Gao, L. Gu, H. Pu, L. Cui, X. Wei, Z. Liu, L. Jing, S. Ye, J. Shaoet al., “Internvl3. 5: Advancing open-source multi- modal models in versatility, reasoning, and efficiency,”arXiv preprint arXiv:2508.18265, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
Earthdial: Turning multi-sensory earth observations to interactive dialogues,
S. Soni, A. Dudhane, H. Debary, M. Fiaz, M. A. Munir, M. S. Danish, P. Fraccaro, C. D. Watson, L. J. Klein, F. S. Khanet al., “Earthdial: Turning multi-sensory earth observations to interactive dialogues,” in Proceedings of the Computer Vision and Pattern Recognition Confer- ence, 2025, pp. 14 303–14 313
2025
-
[47]
Vhm: Versatile and honest vision language model for remote sensing image analysis,
C. Pang, X. Weng, J. Wu, J. Li, Y . Liu, J. Sun, W. Li, S. Wang, L. Feng, G.-S. Xiaet al., “Vhm: Versatile and honest vision language model for remote sensing image analysis,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 6, 2025, pp. 6381–6388
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.