Search for Truth from Reasoning: A Dynamic Representation Editing Framework for Steering LLM Trajectories
Pith reviewed 2026-06-30 00:33 UTC · model grok-4.3
The pith
DynaSteer steers LLM reasoning trajectories toward truth by clustering patterns and projecting purified vectors at early high-entropy forks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
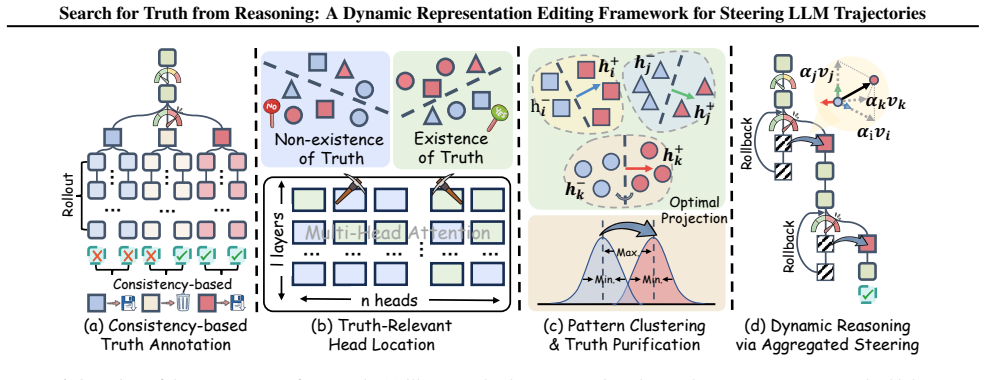
Truth is encoded at the sentence level and entangled with latent reasoning patterns. Effective intervention follows an Uncertainty Principle and a Decay Effect, requiring localization to early, high-entropy forks. Naive steering vectors suffer from noise and risk collateral damage. DynaSteer therefore employs pattern clustering to disentangle reasoning manifolds, Fisher-LDA to project purified truth, and dynamic lookahead entropy monitoring to steer and roll back trajectories only when necessary.
What carries the argument
DynaSteer, a dynamic representation editing framework that disentangles reasoning manifolds via pattern clustering and projects purified truth using Fisher-LDA, guided by lookahead entropy monitoring for selective intervention.
If this is right
- Higher accuracy on MATH benchmark tasks through selective steering at uncertain points.
- Generalization to out-of-domain coding tasks without task-specific retraining.
- Avoidance of collateral damage by rolling back when entropy monitoring indicates the trajectory remains on track.
- Shift from simply encouraging longer thinking to actively directing trajectories toward truth.
Where Pith is reading between the lines
- The same entropy-monitoring logic could be applied to detect likely errors in deployed LLM systems before they complete a response.
- Insights on sentence-level truth encoding may inform how other control methods, such as activation patching, locate truthful directions.
- The decay effect suggests that steering windows shrink as reasoning chains lengthen, which could guide scheduling of interventions in longer tasks.
Load-bearing premise
Truth can be reliably disentangled from latent reasoning patterns via Fisher-LDA projection without collateral damage to correct trajectories.
What would settle it
An experiment in which the DynaSteer interventions at the identified early high-entropy forks produce no accuracy gain or reduce accuracy on MATH problems relative to the unsteered baseline.
Figures



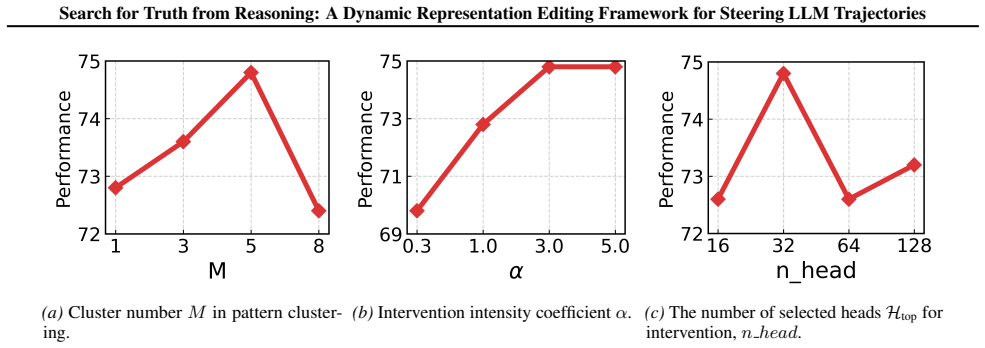

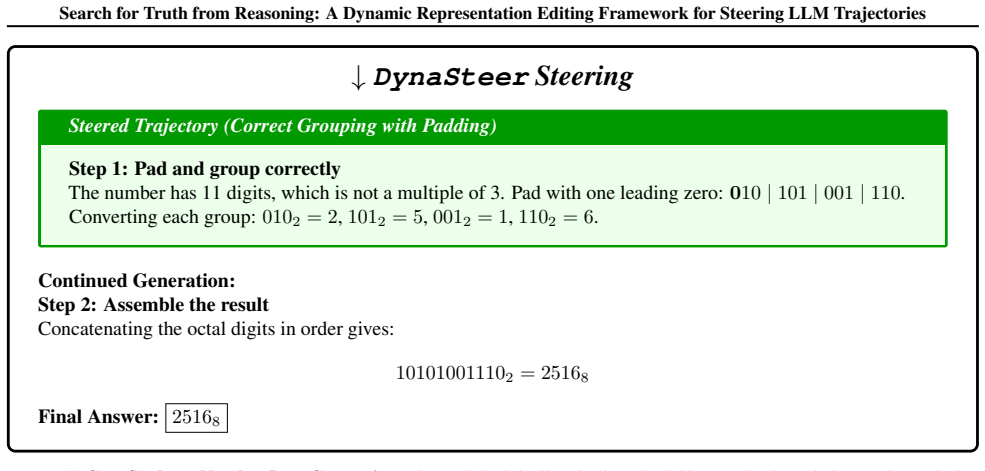







read the original abstract
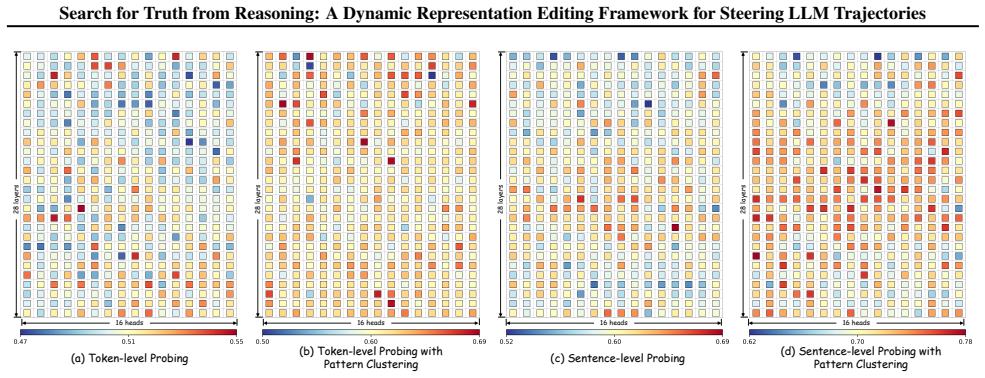
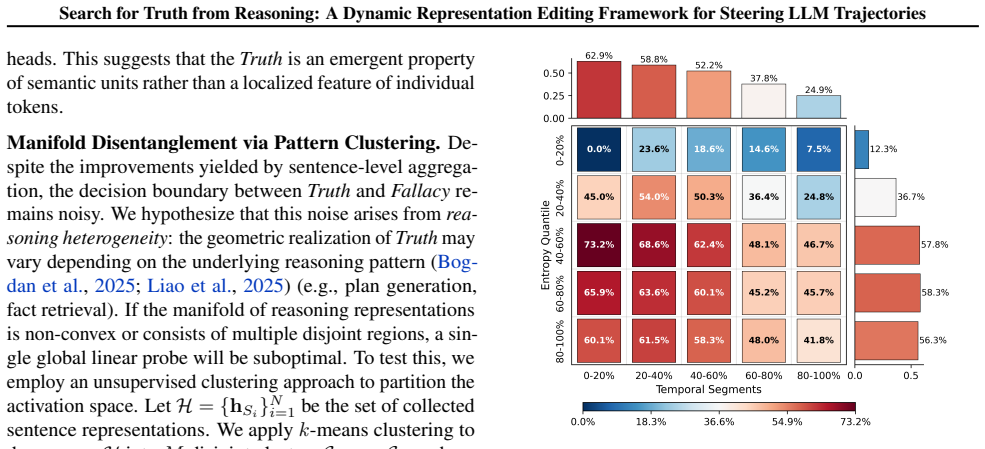
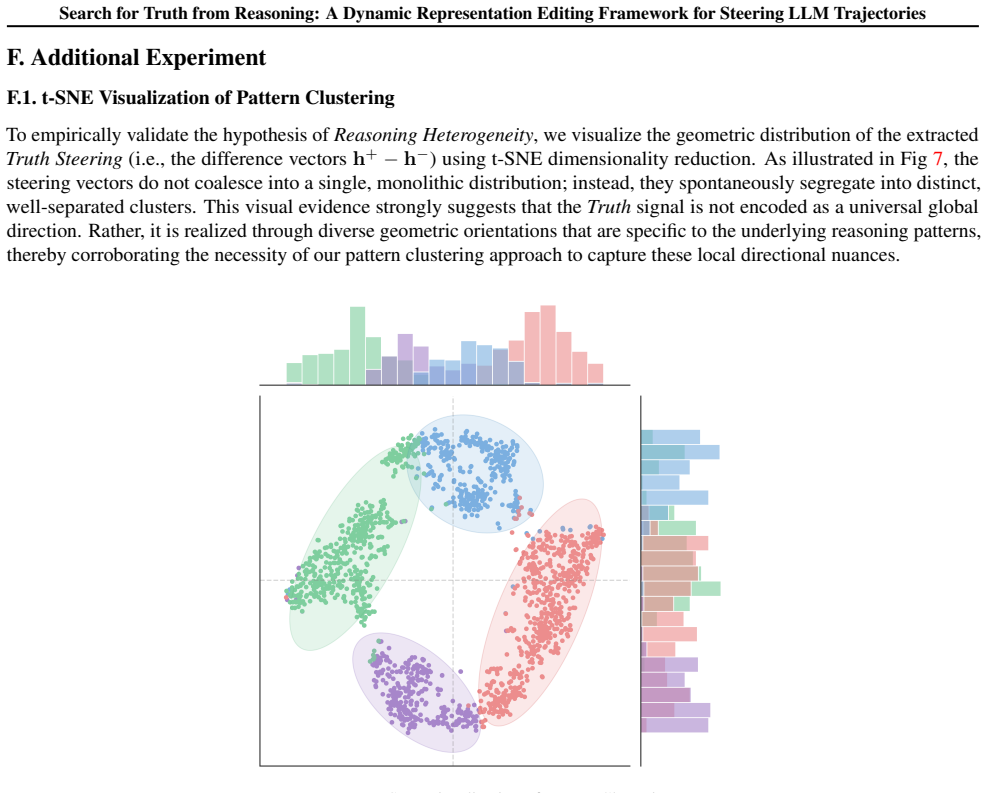
Current approaches to enhance Large Language Model (LLM) reasoning, such as Chain-of-Thought and "Wait" prompts, primarily encourage models to think more, yet often fail to guide them toward Truth. While Representation Editing (RepE) offers a intrinsic control, its application to dynamic reasoning trajectories remains underexplored. In this work, we bridge this gap by investigating the geometry of truth within unfolding reasoning chains. We uncover three critical insights: (1) Truth is encoded at the sentence level and is entangled with latent reasoning patterns; (2) Effective intervention follows an Uncertainty Principle and a Decay Effect, requiring localization to early, high-entropy forks; (3) Naive steering vectors suffer from noise, risking collateral damage to correct trajectories. Based on these findings, we propose DynaSteer, a dynamic RepE framework. DynaSteer employs pattern clustering to disentangle reasoning manifolds and utilizes Fisher-LDA to project purified truth. By dynamically monitoring lookahead entropy, it selectively steers and rolls back trajectories only when necessary. Comprehensive experimental results on several MATH benchmark verify the effectiveness of DynaSteer, and experiments on out-of-domain coding tasks further confirm its generalization ability. Our code is publicly available at https://github.com/tianlwang/DynaSteer.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that by investigating the geometry of truth in unfolding LLM reasoning chains, three insights are uncovered—(1) truth is encoded at the sentence level and entangled with latent reasoning patterns, (2) effective intervention obeys an Uncertainty Principle and Decay Effect localized to early high-entropy forks, and (3) naive steering vectors introduce noise risking collateral damage—and these motivate DynaSteer, a dynamic RepE framework that applies pattern clustering, Fisher-LDA projection for purified truth vectors, and lookahead entropy monitoring for selective steering with rollback. The method is reported to improve reasoning accuracy on MATH benchmarks and to generalize to out-of-domain coding tasks.
Significance. If the geometric assumptions and empirical gains hold, the work would advance intrinsic control of LLM reasoning trajectories beyond static prompting or CoT methods by providing a dynamic, geometry-aware editing approach. The public release of code at https://github.com/tianlwang/DynaSteer is a positive contribution that enables direct reproducibility of the reported results.
major comments (2)
- [Abstract / method overview] The central performance claims rest on Fisher-LDA successfully disentangling sentence-level truth from other reasoning manifolds after pattern clustering (insight 1 and method description). No quantitative check—such as cosine similarity of the projected vectors to ground-truth answers, class-separability metrics, or an ablation removing the LDA step—is described to confirm that the projection avoids mixing truth with high-variance correct patterns or introducing collateral damage.
- [Abstract / insight 2] Insight 2 (Uncertainty Principle and Decay Effect) asserts that intervention is both necessary and safe only at early high-entropy forks. The manuscript provides no ablation on intervention timing, no comparison of early vs. late rollback outcomes, and no evidence that later low-entropy corrections are never required; if this timing assumption fails, the selective-rollback mechanism could either miss fixes or cause unnecessary damage.
minor comments (1)
- The abstract states the three insights as “uncovered” but does not indicate where in the manuscript the supporting geometric observations or visualizations are presented.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments identify important areas where additional evidence would strengthen the claims regarding the Fisher-LDA projection and intervention timing. We address each point below and commit to revisions that incorporate the requested analyses.
read point-by-point responses
-
Referee: [Abstract / method overview] The central performance claims rest on Fisher-LDA successfully disentangling sentence-level truth from other reasoning manifolds after pattern clustering (insight 1 and method description). No quantitative check—such as cosine similarity of the projected vectors to ground-truth answers, class-separability metrics, or an ablation removing the LDA step—is described to confirm that the projection avoids mixing truth with high-variance correct patterns or introducing collateral damage.
Authors: We agree that direct quantitative validation of the LDA projection would provide stronger support for Insight 1. The reported gains on MATH and out-of-domain coding offer indirect evidence, but we will add explicit checks in the revision: (1) cosine similarity between projected truth vectors and ground-truth answer embeddings, (2) class-separability metrics (e.g., between-class vs. within-class variance ratios) pre- and post-projection, and (3) an ablation comparing full DynaSteer against a version without the LDA step. These additions will directly address concerns about mixing with high-variance patterns or collateral damage. revision: yes
-
Referee: [Abstract / insight 2] Insight 2 (Uncertainty Principle and Decay Effect) asserts that intervention is both necessary and safe only at early high-entropy forks. The manuscript provides no ablation on intervention timing, no comparison of early vs. late rollback outcomes, and no evidence that later low-entropy corrections are never required; if this timing assumption fails, the selective-rollback mechanism could either miss fixes or cause unnecessary damage.
Authors: We acknowledge the absence of explicit timing ablations in the current manuscript. The Uncertainty Principle and Decay Effect are motivated by our geometric observations of entropy and pattern separation along trajectories. In the revision we will include a new ablation that varies intervention timing (early high-entropy forks vs. later low-entropy points), reports rollback success rates, accuracy deltas, and any collateral effects. This will empirically test whether late corrections are required and confirm the safety of selective early steering. revision: yes
Circularity Check
No significant circularity; empirical framework validated externally
full rationale
The paper presents three geometric insights derived from representation analysis, then constructs DynaSteer by applying standard tools (pattern clustering, Fisher-LDA projection, entropy monitoring) to those observations. Performance is reported via direct experiments on MATH benchmarks and out-of-domain coding tasks rather than any closed derivation or fitted parameter renamed as prediction. No self-citations appear in the abstract or described method, Fisher-LDA is invoked as an off-the-shelf technique, and the central claims do not reduce by the paper's own equations to its inputs. The work is therefore self-contained as an engineering contribution.
Axiom & Free-Parameter Ledger
axioms (3)
- domain assumption Truth is encoded at the sentence level and entangled with latent reasoning patterns
- domain assumption Effective intervention follows an Uncertainty Principle and a Decay Effect, requiring localization to early, high-entropy forks
- domain assumption Naive steering vectors suffer from noise and risk collateral damage
Reference graph
Works this paper leans on
-
[1]
Findings of the association for computational linguistics: ACL 2023 , pages=
Towards reasoning in large language models: A survey , author=. Findings of the association for computational linguistics: ACL 2023 , pages=
2023
-
[2]
arXiv preprint arXiv:2407.11511 , year=
Reasoning with large language models, a survey , author=. arXiv preprint arXiv:2407.11511 , year=
-
[3]
arXiv preprint arXiv:2410.12854 , year=
TPO: Aligning large language models with multi-branch & multi-step preference trees , author=. arXiv preprint arXiv:2410.12854 , year=
-
[4]
Findings of the Association for Computational Linguistics: EMNLP 2025 , pages=
Teaching LLMs to Plan, Not Just Solve: Plan Learning Boosts LLMs Generalization in Reasoning Tasks , author=. Findings of the Association for Computational Linguistics: EMNLP 2025 , pages=
2025
-
[5]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[6]
Advances in neural information processing systems , volume=
Tree of thoughts: Deliberate problem solving with large language models , author=. Advances in neural information processing systems , volume=
-
[7]
Proceedings of the 33rd annual ACM conference on human factors in computing systems , pages=
Wait-learning: Leveraging wait time for second language education , author=. Proceedings of the 33rd annual ACM conference on human factors in computing systems , pages=
-
[8]
Why Do Reasoning Models Loop? , author=
Wait, Wait, Wait... Why Do Reasoning Models Loop? , author=. arXiv preprint arXiv:2512.12895 , year=
-
[9]
arXiv preprint arXiv:2504.02956 , year=
Understanding aha moments: from external observations to internal mechanisms , author=. arXiv preprint arXiv:2504.02956 , year=
-
[10]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Safekey: Amplifying aha-moment insights for safety reasoning , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[11]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Investigating and Mitigating the Multimodal Hallucination Snowballing in Large Vision-Language Models , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[12]
Proceedings of the ACM on Web Conference 2025 , pages=
Adaptive activation steering: A tuning-free llm truthfulness improvement method for diverse hallucinations categories , author=. Proceedings of the ACM on Web Conference 2025 , pages=
2025
-
[13]
Advances in Neural Information Processing Systems , volume=
Inference-time intervention: Eliciting truthful answers from a language model , author=. Advances in Neural Information Processing Systems , volume=
-
[14]
arXiv preprint arXiv:2501.14371 , year=
DRESSing up LLM: Efficient stylized question-answering via style subspace editing , author=. arXiv preprint arXiv:2501.14371 , year=
-
[15]
Advances in Neural Information Processing Systems , volume=
Towards safe concept transfer of multi-modal diffusion via causal representation editing , author=. Advances in Neural Information Processing Systems , volume=
-
[16]
arXiv preprint arXiv:2508.04530 , year=
Balancing Stylization and Truth via Disentangled Representation Steering , author=. arXiv preprint arXiv:2508.04530 , year=
-
[17]
arXiv preprint arXiv:2510.01243 , year=
Detoxifying Large Language Models via Autoregressive Reward Guided Representation Editing , author=. arXiv preprint arXiv:2510.01243 , year=
-
[18]
Thought anchors: Which llm reasoning steps matter? arXiv preprint arXiv:2506.19143,
Thought Anchors: Which LLM Reasoning Steps Matter? , author=. arXiv preprint arXiv:2506.19143 , year=
-
[19]
arXiv preprint arXiv:2407.06645 , year=
Entropy law: The story behind data compression and llm performance , author=. arXiv preprint arXiv:2407.06645 , year=
-
[20]
Beyond the 80/20 rule: High-entropy minority tokens drive effective reinforcement learning for llm reasoning , author=. arXiv preprint arXiv:2506.01939 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Rethinking Entropy Interventions in RLVR: An Entropy Change Perspective
Rethinking entropy interventions in rlvr: An entropy change perspective , author=. arXiv preprint arXiv:2510.10150 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Qwen technical report , author=. arXiv preprint arXiv:2309.16609 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
LLaMA: Open and Efficient Foundation Language Models
Llama: Open and efficient foundation language models , author=. arXiv preprint arXiv:2302.13971 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Evaluating Large Language Models Trained on Code
Evaluating large language models trained on code , author=. arXiv preprint arXiv:2107.03374 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Program Synthesis with Large Language Models
Program synthesis with large language models , author=. arXiv preprint arXiv:2108.07732 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
arXiv preprint arXiv:2402.19255 , year=
GSM-Plus: A Comprehensive Benchmark for Evaluating the Robustness of LLMs as Mathematical Problem Solvers , author=. arXiv preprint arXiv:2402.19255 , year=
-
[27]
Measuring Mathematical Problem Solving With the MATH Dataset
Measuring mathematical problem solving with the math dataset , author=. arXiv preprint arXiv:2103.03874 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
HuggingFace's Transformers: State-of-the-art Natural Language Processing
Huggingface's transformers: State-of-the-art natural language processing , author=. arXiv preprint arXiv:1910.03771 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[29]
The Twelfth International Conference on Learning Representations,
William Rudman and Carsten Eickhoff , title =. The Twelfth International Conference on Learning Representations,. 2024 , url =
2024
-
[30]
Representation Engineering: A Top-Down Approach to AI Transparency
Representation engineering: A top-down approach to ai transparency , author=. arXiv preprint arXiv:2310.01405 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
The geometry of truth: Emergent linear structure in large language model representations of true/false datasets , author=. arXiv preprint arXiv:2310.06824 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
The Twelfth International Conference on Learning Representations , year=
Let's verify step by step , author=. The Twelfth International Conference on Learning Representations , year=
-
[33]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles , year=
Efficient Memory Management for Large Language Model Serving with PagedAttention , author=. Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles , year=
-
[35]
Is Your Code Generated by Chat
Liu, Jiawei and Xia, Chunqiu Steven and Wang, Yuyao and Zhang, Lingming , booktitle =. Is Your Code Generated by Chat. 2023 , url =
2023
-
[36]
2013 , publisher=
The theory of sound, Volume One , author=. 2013 , publisher=
2013
-
[37]
Designing and interpreting probes with control tasks , author=. Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (emnlp-ijcnlp) , pages=
2019
-
[38]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Truthx: Alleviating hallucinations by editing large language models in truthful space , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[39]
TruthFlow: Truthful LLM Generation via Representation Flow Correction , author=
-
[40]
Advances in neural information processing systems , volume=
Locating and editing factual associations in gpt , author=. Advances in neural information processing systems , volume=
-
[41]
Mass-Editing Memory in a Transformer , author=
-
[42]
Advances in Neural Information Processing Systems , volume=
Magical: Medical lay language generation via semantic invariance and layperson-tailored adaptation , author=. Advances in Neural Information Processing Systems , volume=
-
[43]
arXiv preprint arXiv:2504.02327 , year=
Learnat: Learning nl2sql with ast-guided task decomposition for large language models , author=. arXiv preprint arXiv:2504.02327 , year=
-
[44]
Proceedings of the 32nd ACM SIGKDD Conference on Knowledge Discovery and Data Mining V
HyFunc: Accelerating LLM-based Function Calls for Agentic AI through Hybrid-Model Cascade and Dynamic Templating , author=. Proceedings of the 32nd ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 1 , pages=
-
[45]
arXiv preprint arXiv:2510.10071 , year=
ADEPT: Continual Pretraining via Adaptive Expansion and Dynamic Decoupled Tuning , author=. arXiv preprint arXiv:2510.10071 , year=
-
[46]
ProMed: Shapley Information Gain Guided Reinforcement Learning for Proactive Medical LLMs
Promed: Shapley information gain guided reinforcement learning for proactive medical llms , author=. arXiv preprint arXiv:2508.13514 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[47]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
3DS: Medical Domain Adaptation of LLMs via Decomposed Difficulty-based Data Selection , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[48]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Toward better EHR reasoning in llms: Reinforcement learning with expert attention guidance , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[49]
GraphWalker: Graph-Guided In-Context Learning for Clinical Reasoning on Electronic Health Records , author=. arXiv preprint arXiv:2604.06684 , year=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.