STEAM: Self-Supervised Temporal Ensemble Advantage Modeling for Real-World Robot Learning
Pith reviewed 2026-06-30 06:15 UTC · model grok-4.3
The pith
STEAM learns frame-level advantages for robot policies by predicting normalized temporal offsets between frames in expert demonstrations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
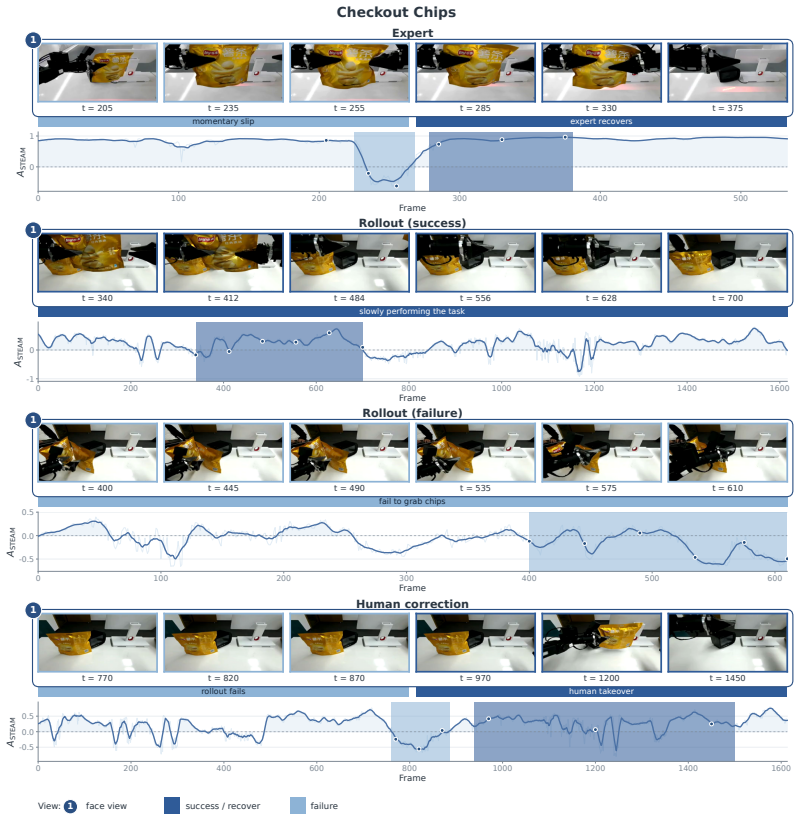
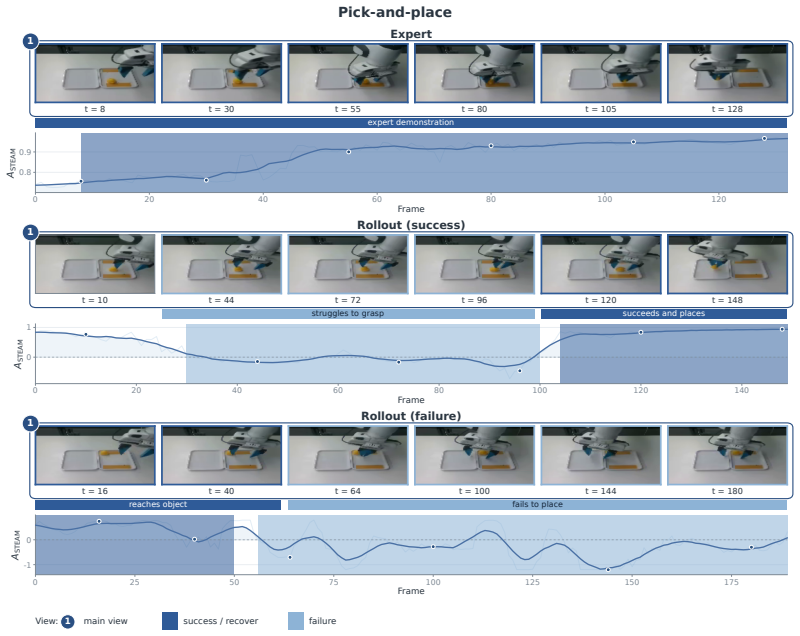
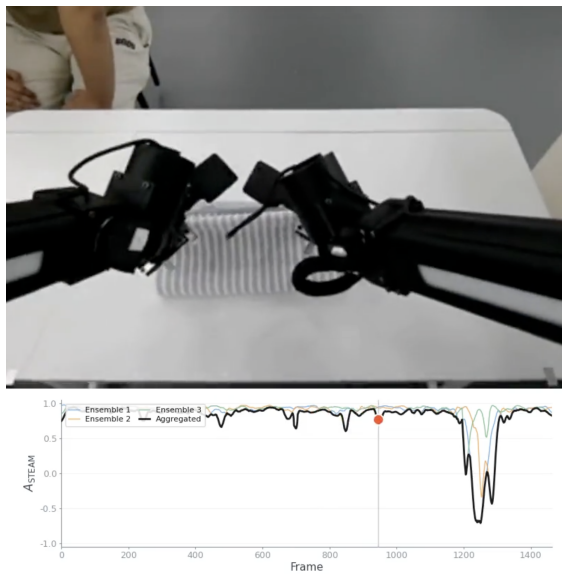
STEAM trains an ensemble of temporal-offset predictors on frame pairs drawn from expert trajectories, treating the normalized temporal offset as a self-supervised target. Each predictor outputs a distribution over offsets; this distribution is converted to a scalar advantage value. The minimum advantage across the ensemble is used to score individual frames in mixed-quality rollout data, providing a conservative estimate that distinguishes local progress from stalls and regressions without any additional supervision.
What carries the argument
Ensemble of temporal-offset predictors that map frame pairs to offset distributions, converted to scalar advantages whose minimum supplies conservative scoring of rollout data.
If this is right
- STEAM identifies stalls, failures, and recoveries directly from unlabeled rollout data.
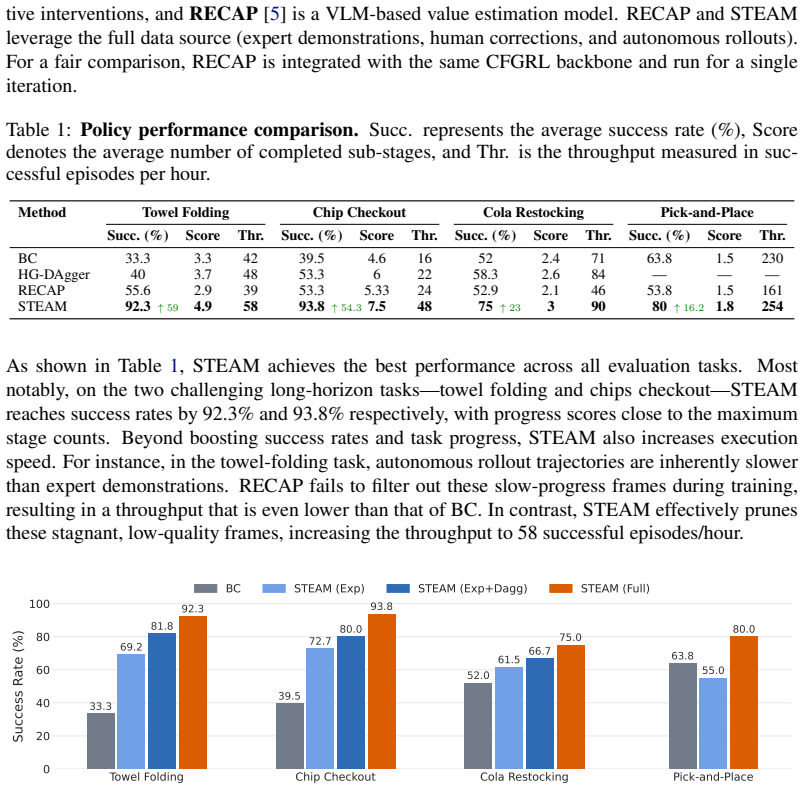
- When combined with CFGRL, STEAM raises policy success rate by 59% on bimanual towel folding, 54.3% on chip checkout, 23% on cola restocking, and 16.2% on single-arm pick-and-place.
- The same self-supervised signal can be extracted from any set of expert trajectories that contain consistent temporal ordering.
Where Pith is reading between the lines
- The method could be applied to any sequential decision domain where expert traces exhibit reliable ordering, such as video game play or surgical tool trajectories.
- Because the advantage is computed per frame pair, it may support fine-grained credit assignment inside long-horizon tasks without requiring full episode returns.
- An online version could periodically retrain the ensemble on newly collected expert data to keep the advantage model current as task distributions shift.
Load-bearing premise
Normalized temporal offset between frames in expert trajectories acts as a reliable proxy for advantage that transfers to scoring non-expert rollout data.
What would settle it
Collect a held-out set of mixed-quality robot trajectories, have humans label frame-level progress, and check whether STEAM advantage scores fail to rank frames in the same order as the human labels.
Figures
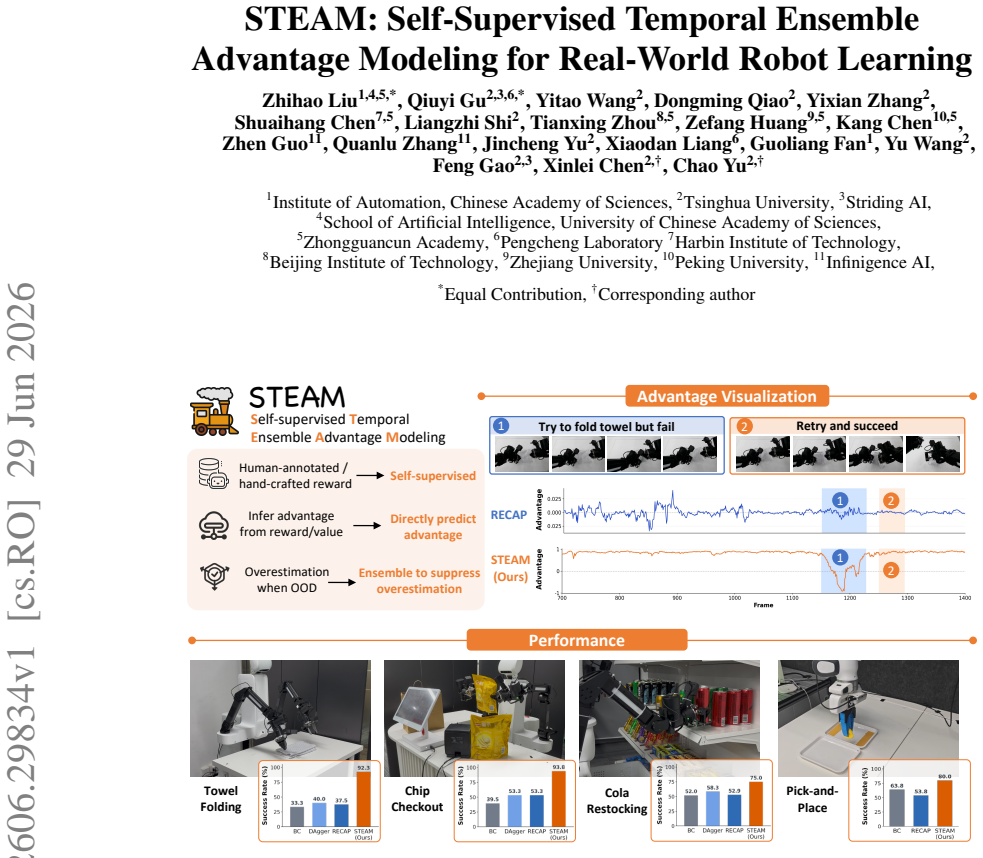
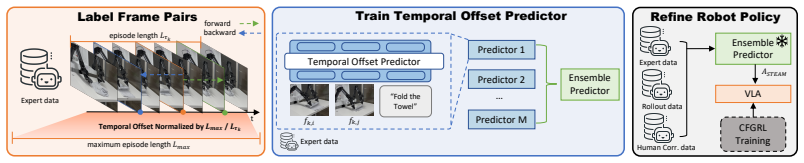


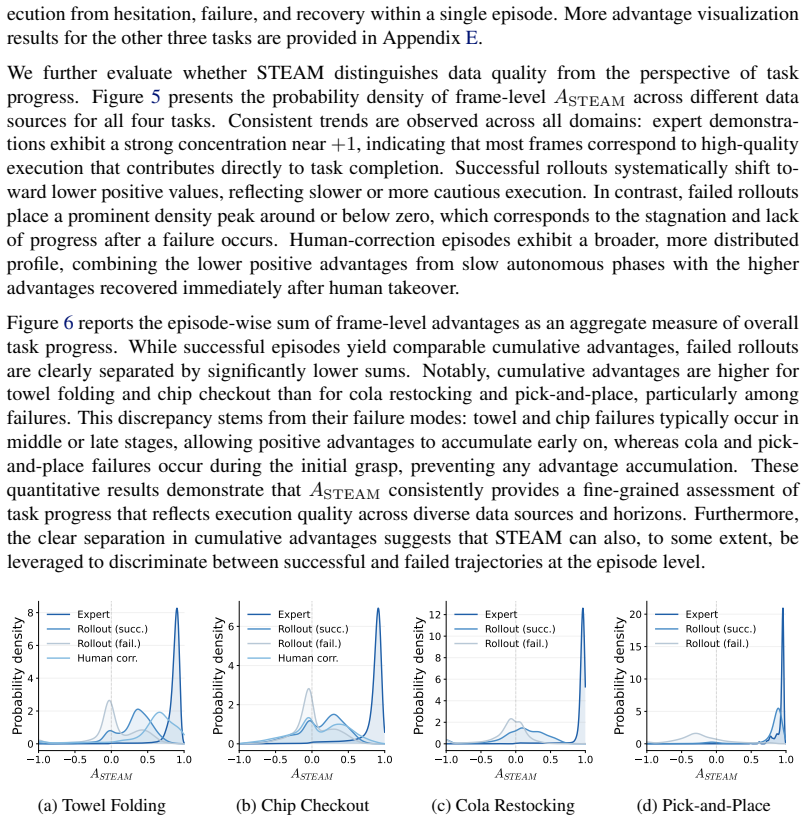
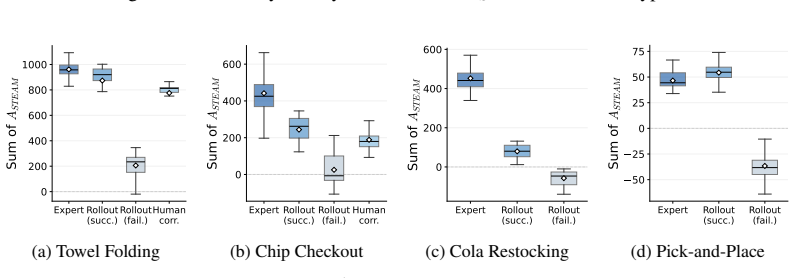

read the original abstract
Real-world robot learning increasingly relies on heterogeneous data, but demonstrations and rollouts often mix useful progress with stalls, corrections, and suboptimal behavior. Effective policy learning therefore requires frame-level advantages that distinguish reliable local progress from failures and regressions. We propose Self-supervised Temporal Ensemble Advantage Modeling (STEAM), a label-free method that learns such advantages from expert demonstrations. STEAM trains an ensemble of temporal-offset predictors on frame pairs within expert trajectories, using the normalized temporal offset between two frames as a self-supervised signal. Each predictor maps a frame pair to a distribution over temporal offsets, which is converted into a scalar advantage. STEAM then takes the minimum advantage across the ensemble to score mixed-quality rollout data conservatively. Across real-world bimanual towel folding, chip checkout, cola restocking, and single-arm pick-and-place tasks, STEAM identifies stalls, failures, and recoveries. When combined with CFGRL, STEAM further improves policy success rate by 59%, 54.3%, 23% and 16.2% over baselines, respectively.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes STEAM, a self-supervised method for learning frame-level advantages from expert demonstrations in robot learning. It trains an ensemble of predictors on frame pairs from expert trajectories using normalized temporal offset as the regression target, converts predictions to scalar advantages, and uses the minimum across the ensemble to conservatively score mixed-quality rollout data. When combined with CFGRL, it reports improvements in policy success rates of 59%, 54.3%, 23%, and 16.2% on four real-world tasks: bimanual towel folding, chip checkout, cola restocking, and single-arm pick-and-place.
Significance. If the self-supervised advantage modeling generalizes reliably to non-expert data, this approach could enable more effective use of heterogeneous robot datasets without requiring additional labels, addressing a key challenge in real-world robot learning.
major comments (3)
- [Method] The central claim that the learned temporal-offset predictors transfer to score stalls, failures, and recoveries in mixed-quality non-expert rollouts is load-bearing for attributing the reported gains to STEAM, yet the manuscript provides no explicit validation such as correlation with human-labeled progress or ground-truth returns on held-out mixed trajectories.
- [Experiments] The abstract and experiments report specific success-rate improvements (59%, 54.3%, 23%, 16.2%) when STEAM is combined with CFGRL, but without ablation studies that isolate the contribution of the min-ensemble advantage scores versus CFGRL alone or other factors, the source of the gains cannot be verified.
- [Abstract] No implementation details, error analysis on the self-supervised regression target, or sensitivity to the choice of ensemble size and min operation are provided, leaving the soundness of the advantage modeling unverifiable from the supplied text.
minor comments (2)
- Clarify the precise mapping from the predicted distribution over temporal offsets to the scalar advantage value.
- Specify the number of predictors in the ensemble and any hyperparameters used for training the temporal-offset models.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment point by point below, providing the strongest honest defense based on the manuscript content while agreeing to revisions where the points identify verifiable gaps.
read point-by-point responses
-
Referee: [Method] The central claim that the learned temporal-offset predictors transfer to score stalls, failures, and recoveries in mixed-quality non-expert rollouts is load-bearing for attributing the reported gains to STEAM, yet the manuscript provides no explicit validation such as correlation with human-labeled progress or ground-truth returns on held-out mixed trajectories.
Authors: The manuscript demonstrates the transfer through qualitative visualizations in the experiments, where STEAM-assigned advantages correctly highlight stalls, failures, and recoveries in mixed-quality rollouts, directly supporting the downstream policy gains. While explicit quantitative correlations with human labels or ground-truth returns on held-out mixed trajectories are not reported, the self-supervised training on expert data and conservative min-ensemble design provide a principled basis for generalization. We will add such correlation analysis in the revision to make the validation explicit. revision: yes
-
Referee: [Experiments] The abstract and experiments report specific success-rate improvements (59%, 54.3%, 23%, 16.2%) when STEAM is combined with CFGRL, but without ablation studies that isolate the contribution of the min-ensemble advantage scores versus CFGRL alone or other factors, the source of the gains cannot be verified.
Authors: The reported gains are measured against baselines that lack STEAM, establishing that the combined system outperforms alternatives. However, we acknowledge that dedicated ablations isolating the min-ensemble advantage scores (e.g., CFGRL with vs. without STEAM or with random scores) would strengthen attribution. We will incorporate these ablations in the revised experiments section. revision: yes
-
Referee: [Abstract] No implementation details, error analysis on the self-supervised regression target, or sensitivity to the choice of ensemble size and min operation are provided, leaving the soundness of the advantage modeling unverifiable from the supplied text.
Authors: The abstract is a concise summary by design. Full implementation details, error analysis on the regression target (including prediction distributions and normalization), and sensitivity studies to ensemble size and the min operation are presented in Sections 3 (method) and 4 (experiments) with supporting figures and tables. We will add explicit forward references in the abstract and ensure these elements are highlighted more prominently in the revision. revision: partial
Circularity Check
No circularity: advantage proxy constructed independently of target rollouts
full rationale
The described method trains temporal-offset predictors exclusively on expert frame pairs with normalized offset as the explicit regression target, then converts the output distribution to a scalar advantage and applies the min-ensemble only to separate mixed-quality rollouts. This separation means the advantage labels on non-expert data are not forced by construction to reproduce the training inputs; any success on stalls or recoveries is an empirical generalization claim rather than a definitional equivalence. No equations, self-citations, or ansatzes are supplied that would collapse the final scores back to the expert offsets by algebraic identity. The derivation therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
-
[2]
Belkhale, Y
S. Belkhale, Y . Cui, and D. Sadigh. Data quality in imitation learning.Advances in neural information processing systems, 36:80375–80395, 2023
2023
-
[3]
Q. Chen, J. Yu, M. Schwager, P. Abbeel, Y . Shentu, and P. Wu. SARM: Stage-aware reward modeling for long horizon robot manipulation. InInternational Conference on Learning Rep- resentations, 2026. URLhttps://openreview.net/forum?id=aemqAxScl9
2026
-
[4]
Y . Mao, Z. Yu, W. Mao, Y . Li, Q. Hu, Z. Lan, M. Zhu, and H. Chen. ARM: Advantage reward modeling for long-horizon manipulation.arXiv preprint arXiv:2604.03037, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[5]
A. Amin, R. Aniceto, A. Balakrishna, K. Black, K. Conley, G. Connors, J. Darpinian, K. Dha- balia, J. DiCarlo, D. Driess, et al.π ∗ 0.6: a VLA that learns from experience.arXiv preprint arXiv:2511.14759, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
J. Yang, K. Lin, J. Li, W. Zhang, T. Lin, L. Wu, Z. Su, H. Zhao, Y .-Q. Zhang, L. Chen, P. Luo, X. Yue, and H. Li. RISE: Self-improving robot policy with compositional world model. Robotics: Science and Systems, 2026. URLhttps://arxiv.org/abs/2602.11075
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [7]
-
[8]
Y . Liu, C. Wen, Y . Hu, D. Jayaraman, and Y . Gao. Timerewarder: Learning dense reward from passive videos via frame-wise temporal distance.arXiv preprint arXiv:2509.26627, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [9]
-
[10]
H. Xu, X. Zhan, H. Yin, and H. Qin. Discriminator-weighted offline imitation learning from suboptimal demonstrations. InInternational Conference on Machine Learning, pages 24725– 24742. PMLR, 2022
2022
-
[11]
Kostrikov, A
I. Kostrikov, A. Nair, and S. Levine. Offline reinforcement learning with implicit q-learning. InInternational Conference on Learning Representations, 2022
2022
-
[12]
X. B. Peng, A. Kumar, G. Zhang, and S. Levine. Advantage-weighted regression: Simple and scalable off-policy reinforcement learning.arXiv preprint arXiv:1910.00177, 2019. URL https://arxiv.org/abs/1910.00177
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[13]
H. Tan, S. Chen, Y . Xu, Z. Wang, Y . Ji, C. Chi, Y . Lyu, Z. Zhao, X. Chen, P. Co, S. Xie, G. Yao, P. Wang, Z. Wang, and S. Zhang. Robo-Dopamine: General process reward modeling for high-precision robotic manipulation.arXiv preprint arXiv:2512.23703, 2025. URLhttps: //arxiv.org/abs/2512.23703. 10
-
[14]
Y . J. Ma, J. Hejna, A. Wahid, C. Fu, D. Shah, J. Liang, Z. Xu, S. Kirmani, P. Xu, D. Driess, T. Xiao, J. Tompson, O. Bastani, D. Jayaraman, W. Yu, T. Zhang, D. Sadigh, and F. Xia. Vision language models are in-context value learners. InInternational Conference on Learning Representations, 2025. URLhttps://openreview.net/forum?id=friHAl5ofG
2025
-
[15]
Robometer: Scaling General-Purpose Robotic Reward Models via Trajectory Comparisons
A. Liang, Y . Korkmaz, J. Zhang, M. Hwang, A. Anwar, S. Kaushik, A. Shah, A. S. Huang, L. Zettlemoyer, D. Fox, Y . Xiang, A. Li, A. Bobu, A. Gupta, S. Tu, E. Biyik, and J. Zhang. Robometer: Scaling general-purpose robotic reward models via trajectory compar- isons.Robotics: Science and Systems, 2026. URLhttps://arxiv.org/abs/2603.02115
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[16]
Dwibedi, Y
D. Dwibedi, Y . Aytar, J. Tompson, P. Sermanet, and A. Zisserman. Tempo- ral cycle-consistency learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1801–1810, 2019. URL https://openaccess.thecvf.com/content_CVPR_2019/html/Dwibedi_Temporal_ Cycle-Consistency_Learning_CVPR_2019_paper.html
2019
-
[17]
Zakka, A
K. Zakka, A. Zeng, P. Florence, J. Tompson, J. Bohg, and D. Dwibedi. XIRL: Cross- embodiment inverse reinforcement learning. In5th Conference on Robot Learning, 2022. URLhttps://openreview.net/forum?id=RO4DM85Z4P7
2022
-
[18]
S. Nair, A. Rajeswaran, V . Kumar, C. Finn, and A. Gupta. R3M: A universal visual rep- resentation for robot manipulation. In6th Conference on Robot Learning, 2022. URL https://arxiv.org/abs/2203.12601
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[19]
Y . J. Ma, S. Sodhani, D. Jayaraman, O. Bastani, V . Kumar, and A. Zhang. VIP: Towards universal visual reward and representation via value-implicit pre-training. InInternational Conference on Learning Representations, 2023. URLhttps://openreview.net/forum? id=YJ7o2wetJ2
2023
-
[20]
Y . J. Ma, W. Liang, V . Som, V . Kumar, A. Zhang, O. Bastani, and D. Jayaraman. LIV: Language-image representations and rewards for robotic control. InProceedings of the 40th In- ternational Conference on Machine Learning, volume 202 ofProceedings of Machine Learn- ing Research, 2023
2023
-
[21]
Zhang, Y
J. Zhang, Y . Luo, A. Anwar, S. A. Sontakke, J. J. Lim, J. Thomason, E. Bıyık, and J. Zhang. ReWiND: Language-guided rewards teach robot policies without new demonstrations. In9th Conference on Robot Learning, 2025
2025
-
[22]
Lakshminarayanan, A
B. Lakshminarayanan, A. Pritzel, and C. Blundell. Simple and scalable predictive uncertainty estimation using deep ensembles. InAdvances in Neural Information Processing Systems, volume 30, 2017
2017
- [23]
-
[24]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, et al.π 0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Kelly, C
M. Kelly, C. Sidrane, K. Driggs-Campbell, and M. J. Kochenderfer. Hg-dagger: Interactive imitation learning with human experts. In2019 International Conference on Robotics and Automation (ICRA), pages 8077–8083. IEEE, 2019
2019
-
[26]
R. He, Y . Wei, L. Yu, and X. Zeng. Spars: Structure-informed progress-aware reward shaping for fabric manipulation learning from demonstration.Robotics and Autonomous Systems, page 105499, 2026. 11 A Classifier-Free Guidance RL Details We integrate the frame-level advantages learned by STEAM into the classifier-free guidance rein- forcement learning fram...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.