Test-Time Verification for Text-to-SQL via Outcome Reward Models
Pith reviewed 2026-07-01 02:07 UTC · model grok-4.3
The pith
Outcome Reward Models improve Text-to-SQL by learning to score candidates beyond execution success.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
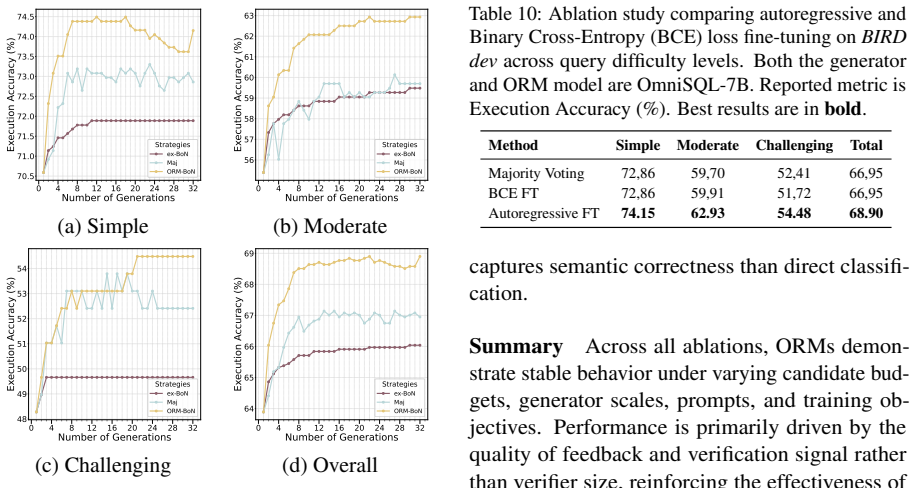
ORM-based selection consistently outperforms execution-based Best-of-N and Majority Voting, with gains of up to +4.33% on BIRD and +2.10% on Spider. ORMs scale effectively with larger candidate sets and yield stronger improvements on complex queries. The GradeSQL framework enables verifier training without manual annotation by using automated candidate generation and execution-based labeling.
What carries the argument
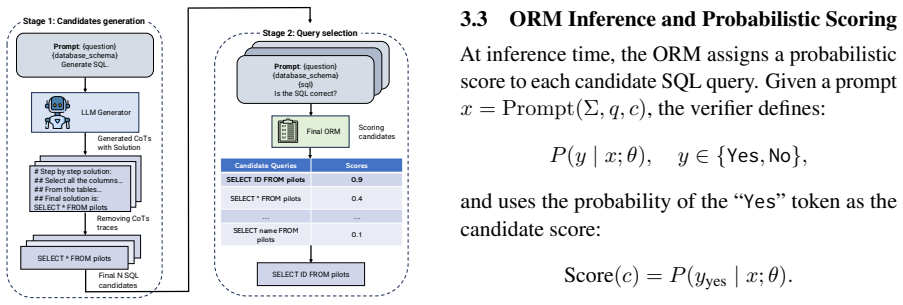
Outcome Reward Models (ORMs) as learned semantic scoring functions trained on execution-labeled candidates and inserted into a verification-driven Best-of-N pipeline.
If this is right
- ORM selection beats execution-based Best-of-N and Majority Voting on both BIRD and Spider.
- Gains increase with the size of the candidate pool.
- Larger accuracy lifts appear on complex queries than on simple ones.
- No manual annotation is required because execution labels suffice for training.
- The same verifier can be reused across different base LLMs in the same family.
Where Pith is reading between the lines
- The same training recipe could be tested on other verifiable structured outputs such as SPARQL or Python code.
- ORMs might be combined with self-consistency or tree-of-thought methods to compound gains.
- If the learned scores capture semantics beyond execution, they could flag subtle logical errors that pass execution checks.
- Cross-benchmark transfer of a single ORM could be measured to test domain robustness.
Load-bearing premise
Execution success on automatically generated candidates supplies training labels rich enough for ORMs to learn reliable semantic distinctions among queries.
What would settle it
A held-out set of Text-to-SQL examples containing multiple executable candidates where only one is semantically correct; the trained ORM ranks the correct query lower than a simple execution baseline or majority vote.
Figures

read the original abstract
Improving the reliability of large language models (LLMs) at inference time is a central challenge in structured reasoning tasks such as Text-to-SQL. Common test-time inference strategies, including Best-of-N sampling and Majority Voting, rely on heuristic signals such as execution success or output frequency, which provide limited semantic discrimination across candidate outputs. In this work, we study Outcome Reward Models (ORMs) as learned semantic scoring functions for test-time verification in Text-to-SQL. While ORMs have been previously explored for test-time scaling and alignment, their application to structured query generation remains underexplored. We introduce GradeSQL, a scalable framework for training task-specific ORMs via automated candidate generation and execution-based labeling, enabling verifier training without manual annotation. We integrate ORMs into a verification-driven Best-of-N pipeline and evaluate our approach on the BIRD and Spider benchmarks across multiple open-source LLM families. ORM-based selection consistently outperforms execution-based Best-of-N and Majority Voting, with gains of up to +4.33% on BIRD and +2.10% on Spider. We further show that ORMs scale effectively with larger candidate sets and yield stronger improvements on complex queries. Overall, our results demonstrate that ORM-based verification provides a simple, effective, and scalable alternative to heuristic test-time selection strategies for Text-to-SQL. Code datasets and models are publicly available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces GradeSQL, a framework for training task-specific Outcome Reward Models (ORMs) for test-time verification in Text-to-SQL via automated candidate generation and execution-based labeling without manual annotation. It integrates ORMs into a verification-driven Best-of-N pipeline and reports that ORM-based selection outperforms execution-based Best-of-N and Majority Voting, with gains up to +4.33% on BIRD and +2.10% on Spider, plus improved scaling with larger candidate sets and stronger gains on complex queries.
Significance. If the empirical gains are robust, the work offers a scalable, annotation-free approach to improving reliability of LLMs on structured reasoning tasks. The public release of code, datasets, and models is a clear strength that supports reproducibility.
major comments (3)
- [Abstract and §4] Abstract and §4 (results): The reported percentage gains lack any mention of statistical significance tests, variance or standard deviation across multiple runs, or details on the number and diversity of generated candidates, which undermines verification of the central claim that ORM selection is reliably superior.
- [§3.2 and §4.3] §3.2 and §4.3: No ablation is presented that isolates ORM performance on the subset of examples where execution-based signals are uninformative (multiple candidates execute correctly to the gold result, or execution fails to distinguish semantically distinct queries). Without this, it is unclear whether the ORM learns semantic discrimination beyond the execution labels used for training.
- [§4.2] §4.2: The comparison to execution-based Best-of-N does not clarify whether the ORM is evaluated against an oracle that has access to the same execution outcomes at test time; if the ORM merely approximates the execution signal, the reported gains would not demonstrate independent verification capability.
minor comments (2)
- [Abstract] The abstract states gains 'up to' specific values but does not specify on which model or setting the maximum is achieved; this should be clarified with a table reference.
- [§3.1] Notation for ORM scoring function and how it is combined with Best-of-N should be made explicit in §3.1 to avoid ambiguity with standard reward model usage.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments help clarify the presentation of our empirical results and the capabilities of the ORM. We respond to each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (results): The reported percentage gains lack any mention of statistical significance tests, variance or standard deviation across multiple runs, or details on the number and diversity of generated candidates, which undermines verification of the central claim that ORM selection is reliably superior.
Authors: We agree that reporting variance, standard deviations, and statistical significance would strengthen verification of the gains. In the revised manuscript, we will add results averaged over three runs with different random seeds, include standard deviations, and report p-values from paired t-tests comparing ORM selection to baselines. We will also specify the candidate generation details: 10 candidates per query sampled with temperature 0.8 and nucleus sampling p=0.9. revision: yes
-
Referee: [§3.2 and §4.3] §3.2 and §4.3: No ablation is presented that isolates ORM performance on the subset of examples where execution-based signals are uninformative (multiple candidates execute correctly to the gold result, or execution fails to distinguish semantically distinct queries). Without this, it is unclear whether the ORM learns semantic discrimination beyond the execution labels used for training.
Authors: This is a fair observation that would better isolate the ORM's contribution. We will add an ablation in the revised §4.3 evaluating ORM selection specifically on the subset of queries where at least two candidates execute to the gold result. On this subset, we will compare against random selection among the correct executors to demonstrate additional semantic discrimination learned by the model beyond the binary execution labels. revision: yes
-
Referee: [§4.2] §4.2: The comparison to execution-based Best-of-N does not clarify whether the ORM is evaluated against an oracle that has access to the same execution outcomes at test time; if the ORM merely approximates the execution signal, the reported gains would not demonstrate independent verification capability.
Authors: We clarify that the ORM functions as an independent verifier without access to execution outcomes at test time: it receives only the natural language question and candidate SQL as input and outputs a scalar reward score. The execution-based Best-of-N baseline, in contrast, uses actual database execution results (e.g., success or result matching) to select among candidates. The ORM's outperformance without execution access at inference demonstrates its independent verification value. We will revise §4.2 to make this distinction explicit. revision: partial
Circularity Check
No circularity: empirical comparison with external benchmarks
full rationale
The paper reports measured accuracy gains from an empirical pipeline (candidate generation + execution labeling + ORM training + test-time selection) evaluated on standard BIRD and Spider test sets. No equations, derivations, or fitted parameters are presented whose outputs are redefined as predictions. The central result is a direct experimental comparison against execution-based baselines; the reported deltas (+4.33% / +2.10%) are not reduced to quantities defined inside the training loop by construction. No self-citation is load-bearing for the uniqueness or validity of the method.
Axiom & Free-Parameter Ledger
free parameters (1)
- ORM training hyperparameters
axioms (1)
- domain assumption Execution success on generated candidates provides a valid proxy signal for semantic correctness suitable for ORM training
Reference graph
Works this paper leans on
-
[1]
CoRR , volume =
Zijin Hong and Zheng Yuan and Qinggang Zhang and Hao Chen and Junnan Dong and Feiran Huang and Xiao Huang , title =. CoRR , volume =
-
[2]
2025 , eprint=
From Natural Language to SQL: Review of LLM-based Text-to-SQL Systems , author=. 2025 , eprint=
2025
-
[3]
Long Short-Term Memory , year=
Hochreiter, Sepp and Schmidhuber, Jürgen , journal=. Long Short-Term Memory , year=
-
[4]
Attention is All you Need , url =
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, ukasz and Polosukhin, Illia , booktitle =. Attention is All you Need , url =
-
[5]
Computational Linguistics , volume =
Choi, DongHyun and Shin, Myeong Cheol and Kim, EungGyun and Shin, Dong Ryeol , title =. Computational Linguistics , volume =. 2021 , month =. doi:10.1162/coli_a_00403 , url =
-
[6]
2017 , eprint=
SQLNet: Generating Structured Queries From Natural Language Without Reinforcement Learning , author=. 2017 , eprint=
2017
-
[7]
2021 , eprint=
Improving Text-to-SQL with Schema Dependency Learning , author=. 2021 , eprint=
2021
-
[8]
Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina. BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding. Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019. doi:10.18653/v...
-
[9]
2019 , eprint=
RoBERTa: A Robustly Optimized BERT Pretraining Approach , author=. 2019 , eprint=
2019
-
[10]
2017 , eprint=
Seq2SQL: Generating Structured Queries from Natural Language using Reinforcement Learning , author=. 2017 , eprint=
2017
-
[11]
2020 , eprint=
TaBERT: Pretraining for Joint Understanding of Textual and Tabular Data , author=. 2020 , eprint=
2020
-
[12]
2019 , eprint=
Towards Complex Text-to-SQL in Cross-Domain Database with Intermediate Representation , author=. 2019 , eprint=
2019
-
[13]
2023 , eprint=
Towards Knowledge-Intensive Text-to-SQL Semantic Parsing with Formulaic Knowledge , author=. 2023 , eprint=
2023
-
[14]
Proceedings of the AAAI Conference on Artificial Intelligence , author=
RESDSQL: Decoupling Schema Linking and Skeleton Parsing for Text-to-SQL , volume=. Proceedings of the AAAI Conference on Artificial Intelligence , author=. 2023 , month=. doi:10.1609/aaai.v37i11.26535 , abstractNote=
-
[15]
2018 , publisher=
Improving language understanding by generative pre-training , author=. 2018 , publisher=
2018
-
[16]
The Graph Neural Network Model , year=
Scarselli, Franco and Gori, Marco and Tsoi, Ah Chung and Hagenbuchner, Markus and Monfardini, Gabriele , journal=. The Graph Neural Network Model , year=
-
[17]
Language Models are Few-Shot Learners , url =
Brown, Tom and Mann, Benjamin and Ryder, Nick and Subbiah, Melanie and Kaplan, Jared D and Dhariwal, Prafulla and Neelakantan, Arvind and Shyam, Pranav and Sastry, Girish and Askell, Amanda and Agarwal, Sandhini and Herbert-Voss, Ariel and Krueger, Gretchen and Henighan, Tom and Child, Rewon and Ramesh, Aditya and Ziegler, Daniel and Wu, Jeffrey and Winte...
-
[18]
2024 , eprint=
GPT-4 Technical Report , author=. 2024 , eprint=
2024
-
[19]
2023 , eprint=
How to Prompt LLMs for Text-to-SQL: A Study in Zero-shot, Single-domain, and Cross-domain Settings , author=. 2023 , eprint=
2023
-
[20]
Natural language to
Hyeonji Kim and Byeong. Natural language to. Proc
-
[21]
A Survey of Large Language Model-Based Generative AI for Text-to-SQL: Benchmarks, Applications, Use Cases, and Challenges , year=
Singh, Aditi and Shetty, Akash and Ehtesham, Abul and Kumar, Saket and Khoei, Tala Talaei , booktitle=. A Survey of Large Language Model-Based Generative AI for Text-to-SQL: Benchmarks, Applications, Use Cases, and Challenges , year=
-
[22]
2025 , eprint=
Exploring the Landscape of Text-to-SQL with Large Language Models: Progresses, Challenges and Opportunities , author=. 2025 , eprint=
2025
-
[23]
Shi, Liang and Tang, Zhengju and Zhang, Nan and Zhang, Xiaotong and Yang, Zhi , title =. ACM Comput. Surv. , month = jun, keywords =. 2025 , publisher =. doi:10.1145/3737873 , abstract =
-
[24]
Turkish J
Ali Bugra Kanburoglu and Faik Boray Tek , title =. Turkish J. Electr. Eng. Comput. Sci. , volume =
-
[25]
2025 , eprint=
Think2SQL: Reinforce LLM Reasoning Capabilities for Text2SQL , author=. 2025 , eprint=
2025
-
[26]
Pu and Ying Zhu , title =
Limin Ma and Ken Q. Pu and Ying Zhu , title =. CoRR , volume =
-
[27]
Bradley C. A. Brown and Jordan Juravsky and Ryan Ehrlich and Ronald Clark and Quoc V. Le and Christopher R. Large Language Monkeys: Scaling Inference Compute with Repeated Sampling , journal =
-
[28]
Proceedings of the 40th International Conference on Machine Learning , pages =
Scaling Laws for Reward Model Overoptimization , author =. Proceedings of the 40th International Conference on Machine Learning , pages =. 2023 , editor =
2023
-
[29]
CoRR , volume =
Lei Sheng and Shuai. CoRR , volume =
-
[30]
Dawei Gao and Haibin Wang and Yaliang Li and Xiuyu Sun and Yichen Qian and Bolin Ding and Jingren Zhou , title =. Proc
-
[31]
Zhenru Zhang and Chujie Zheng and Yangzhen Wu and Beichen Zhang and Runji Lin and Bowen Yu and Dayiheng Liu and Jingren Zhou and Junyang Lin , title =
-
[32]
Gu, Zihui and Fan, Ju and Tang, Nan and Cao, Lei and Jia, Bowen and Madden, Sam and Du, Xiaoyong , title =. Proc. ACM Manag. Data , month = jun, articleno =. 2023 , issue_date =. doi:10.1145/3589292 , abstract =
-
[33]
Critical current of a Josephson junction containing a conical magnet
Almohaimeed, Saleh and Almohaimeed, Saad and Wang, Liqiang , booktitle=. GAT-SQL: An Advanced Prompt Engineering Approach for Effective Text-to-SQL Interactions , year=. doi:10.1109/CEC60901.2024.10611969 , ISSN=
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1109/cec60901.2024.10611969 2024
-
[34]
2025 , eprint=
MAC-SQL: A Multi-Agent Collaborative Framework for Text-to-SQL , author=. 2025 , eprint=
2025
-
[35]
2024 , eprint=
MAG-SQL: Multi-Agent Generative Approach with Soft Schema Linking and Iterative Sub-SQL Refinement for Text-to-SQL , author=. 2024 , eprint=
2024
-
[36]
2025 , eprint=
SQL-o1: A Self-Reward Heuristic Dynamic Search Method for Text-to-SQL , author=. 2025 , eprint=
2025
-
[37]
2024 , eprint=
Using LLM to select the right SQL Query from candidates , author=. 2024 , eprint=
2024
-
[38]
Bin Xie and Bingbing Xu and Yige Yuan and Shengmao Zhu and Huawei Shen , title =
-
[39]
CoRR , volume =
Karl Cobbe and Vineet Kosaraju and Mohammad Bavarian and Mark Chen and Heewoo Jun and Lukasz Kaiser and Matthias Plappert and Jerry Tworek and Jacob Hilton and Reiichiro Nakano and Christopher Hesse and John Schulman , title =. CoRR , volume =
-
[40]
CoRR , volume =
Lukasz Borchmann and Marek Wydmuch , title =. CoRR , volume =
-
[41]
Daya Guo and Yibo Sun and Duyu Tang and Nan Duan and Jian Yin and Hong Chi and James Cao and Peng Chen and Ming Zhou , title =
-
[42]
Hideo Kobayashi and Wuwei Lan and Peng Shi and Shuaichen Chang and Jiang Guo and Henghui Zhu and Zhiguo Wang and Patrick Ng , title =
-
[43]
ScienceBenchmark:
Yi Zhang and Jan Deriu and George Katsogiannis. ScienceBenchmark:. Proc
-
[44]
Wang and Luke Zettlemoyer , title =
Victor Zhong and Mike Lewis and Sida I. Wang and Luke Zettlemoyer , title =
-
[45]
Jiaxi Yang and Binyuan Hui and Min Yang and Jian Yang and Junyang Lin and Chang Zhou , title =
-
[46]
Qwen2.5: A Party of Foundation Models , url =
Qwen Team , month =. Qwen2.5: A Party of Foundation Models , url =
-
[47]
Glass and Junkyu Lee and Dharmashankar Subramanian , title =
Gaetano Rossiello and Nhan Pham and Michael R. Glass and Junkyu Lee and Dharmashankar Subramanian , title =. CoRR , volume =
-
[48]
Glass and Mustafa Eyceoz and Dharmashankar Subramanian and Gaetano Rossiello and Long Vu and Alfio Gliozzo , title =
Michael R. Glass and Mustafa Eyceoz and Dharmashankar Subramanian and Gaetano Rossiello and Long Vu and Alfio Gliozzo , title =. CoRR , volume =
-
[49]
2025 , eprint=
LogicCat: A Chain-of-Thought Text-to-SQL Benchmark for Multi-Domain Reasoning Challenges , author=. 2025 , eprint=
2025
-
[50]
2025 , eprint=
A Survey on Test-Time Scaling in Large Language Models: What, How, Where, and How Well? , author=. 2025 , eprint=
2025
-
[51]
2025 , eprint=
Alpha-SQL: Zero-Shot Text-to-SQL using Monte Carlo Tree Search , author=. 2025 , eprint=
2025
-
[52]
2025 , eprint=
SQL-R1: Training Natural Language to SQL Reasoning Model By Reinforcement Learning , author=. 2025 , eprint=
2025
-
[53]
2025 , eprint=
Sparks of Tabular Reasoning via Text2SQL Reinforcement Learning , author=. 2025 , eprint=
2025
-
[54]
Zijin Hong and Zheng Yuan and Hao Chen and Qinggang Zhang and Feiran Huang and Xiao Huang , title =
-
[55]
Jinyang Li and Binyuan Hui and Ge Qu and Jiaxi Yang and Binhua Li and Bowen Li and Bailin Wang and Bowen Qin and Ruiying Geng and Nan Huo and Xuanhe Zhou and Chenhao Ma and Guoliang Li and Kevin Chen. Can. NeurIPS , year =
-
[56]
CoRR , volume =
Muhammad Khalifa and Rishabh Agarwal and Lajanugen Logeswaran and Jaekyeom Kim and Hao Peng and Moontae Lee and Honglak Lee and Lu Wang , title =. CoRR , volume =
-
[57]
2025 , eprint=
Reward-SQL: Boosting Text-to-SQL via Stepwise Reasoning and Process-Supervised Rewards , author=. 2025 , eprint=
2025
-
[58]
2025 , eprint=
Process Reinforcement through Implicit Rewards , author=. 2025 , eprint=
2025
-
[59]
2025 , eprint=
Arctic-Text2SQL-R1: Simple Rewards, Strong Reasoning in Text-to-SQL , author=. 2025 , eprint=
2025
-
[60]
2025 , eprint=
Reasoning-SQL: Reinforcement Learning with SQL Tailored Partial Rewards for Reasoning-Enhanced Text-to-SQL , author=. 2025 , eprint=
2025
-
[61]
Mingqian He and Yongliang Shen and Wenqi Zhang and Qiuying Peng and Jun Wang and Weiming Lu , title =
-
[62]
2024 , eprint=
MCS-SQL: Leveraging Multiple Prompts and Multiple-Choice Selection For Text-to-SQL Generation , author=. 2024 , eprint=
2024
-
[63]
Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen
Edward J. Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen. LoRA: Low-Rank Adaptation of Large Language Models , booktitle =
-
[64]
2019 , journal=
Language Models are Unsupervised Multitask Learners , author=. 2019 , journal=
2019
-
[65]
2023 , eprint=
LEONARDO: A Pan‑European Pre‑Exascale Supercomputer for HPC and AI Applications , author=. 2023 , eprint=
2023
-
[66]
Proceedings of the 2021 International Conference on Management of Data , pages =
Katsogiannis-Meimarakis, George and Koutrika, Georgia , title =. Proceedings of the 2021 International Conference on Management of Data , pages =. 2021 , isbn =. doi:10.1145/3448016.3457543 , abstract =
-
[67]
2022 , eprint=
Evaluating the Text-to-SQL Capabilities of Large Language Models , author=. 2022 , eprint=
2022
-
[68]
2021 , eprint=
GraPPa: Grammar-Augmented Pre-Training for Table Semantic Parsing , author=. 2021 , eprint=
2021
-
[69]
DIN-SQL: Decomposed In-Context Learning of Text-to-SQL with Self-Correction , url =
Pourreza, Mohammadreza and Rafiei, Davood , booktitle =. DIN-SQL: Decomposed In-Context Learning of Text-to-SQL with Self-Correction , url =
-
[70]
Haoyang Li and Jing Zhang and Hanbing Liu and Ju Fan and Xiaokang Zhang and Jun Zhu and Renjie Wei and Hongyan Pan and Cuiping Li and Hong Chen , title =. Proc
-
[71]
Companion of the 2024 International Conference on Management of Data , pages =
Zhang, Chao and Mao, Yuren and Fan, Yijiang and Mi, Yu and Gao, Yunjun and Chen, Lu and Lou, Dongfang and Lin, Jinshu , title =. Companion of the 2024 International Conference on Management of Data , pages =. 2024 , isbn =. doi:10.1145/3626246.3653375 , abstract =
-
[72]
2023 , eprint=
StarCoder: may the source be with you! , author=. 2023 , eprint=
2023
-
[73]
A Survey of Text-to-SQL in the Era of LLMs: Where are We, and Where are We Going? , year=
Liu, Xinyu and Shen, Shuyu and Li, Boyan and Ma, Peixian and Jiang, Runzhi and Zhang, Yuxin and Fan, Ju and Li, Guoliang and Tang, Nan and Luo, Yuyu , journal=. A Survey of Text-to-SQL in the Era of LLMs: Where are We, and Where are We Going? , year=
-
[74]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[75]
Terry , journal =
Ralph Allan Bradley and Milton E. Terry , journal =. Rank Analysis of Incomplete Block Designs: I. The Method of Paired Comparisons , urldate =
-
[76]
2024 , eprint=
HelpSteer2: Open-source dataset for training top-performing reward models , author=. 2024 , eprint=
2024
-
[77]
2024 , eprint=
HelpSteer2-Preference: Complementing Ratings with Preferences , author=. 2024 , eprint=
2024
-
[78]
Skywork-Reward: Bag of Tricks for Reward Modeling in LLMs
Skywork-Reward: Bag of Tricks for Reward Modeling in LLMs , author=. arXiv preprint arXiv:2410.18451 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[79]
Constitutional AI: Harmlessness from AI Feedback
Constitutional ai: Harmlessness from ai feedback , author=. arXiv preprint arXiv:2212.08073 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[80]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.