On the Inseparability of Instructions and Data in Shared-Embedding Sequence Models
Pith reviewed 2026-06-29 01:25 UTC · model grok-4.3
The pith
In shared-embedding sequence models without enforced separation, perfect prompt-injection prevention is mathematically impossible.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In Prompted Action Models that use shared embeddings, Semantic-Faithful Control is unachievable because shared representations make trusted and untrusted content statistically inseparable up to total variation distance, untrusted tokens reach control-relevant computation through the same attention aggregation that produces outputs, and finite training sets cannot certify invariance across infinite semantic-equivalence classes of untrusted input.
What carries the argument
Semantic-Faithful Control (SFC), the property that control-authoritative actions such as refusal decisions and tool authorization depend only on the meaning of untrusted input and not on its encoding.
If this is right
- Any defense that keeps instructions and data in the same embedding space cannot guarantee perfect prevention of prompt injection.
- Control decisions will always remain vulnerable to encoding-based manipulations that preserve meaning.
- The problem is analogous to the code-data confusion in von Neumann architectures that enables buffer overflows.
- Eliminating the vulnerability requires architectural separation of instruction and data channels rather than in-pipeline improvements alone.
Where Pith is reading between the lines
- The same inseparability argument may extend to other sequence models that mix control and data in a single representation space.
- Designers could test whether adding explicit provenance tokens or separate embedding streams restores SFC in practice.
- The result suggests that safety properties relying on semantic invariance will need hardware or software isolation mechanisms similar to those developed for memory safety.
Load-bearing premise
Semantic-Faithful Control is defined to depend only on the meaning of untrusted input independent of how that input is encoded.
What would settle it
Construction of a shared-embedding model that produces control-authoritative outputs depending solely on the meaning of untrusted input across all semantic equivalents while remaining within the single pipeline would falsify the impossibility claim.
Figures
read the original abstract
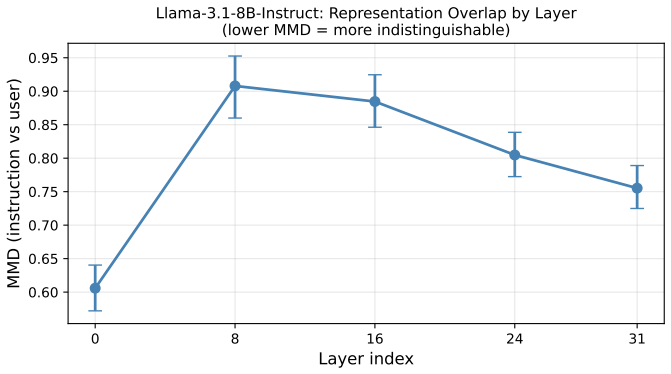
Prompt injection is the top security risk for LLM-integrated applications, yet every defense proposed so far has been broken. We prove this is not a coincidence: in shared-embedding architectures that lack enforced control-data separation, perfect prompt-injection prevention is mathematically impossible. We formalize prompted systems as Prompted Action Models whose outputs include control-authoritative actions: refusal decisions, tool authorization, policy routing, and memory writes. We define Semantic-Faithful Control (SFC), the property that such behavior depends only on the meaning of untrusted input, not on how it is encoded. We then prove SFC is unachievable within the shared pipeline, via three results: a provenance-recovery impossibility (shared representations make trusted and untrusted content statistically inseparable, bounded by total variation distance); control-path exposure (untrusted tokens enter control-relevant computation through the same attention value-aggregation that determines outputs); and a finite-coverage invariance gap (finite training cannot certify invariance over infinite semantic-equivalence classes). We ground each quantity in measurements on production tokenizers and models. The result is structural, not a gap in current defenses. It mirrors the code-data confusion in Von Neumann machines that gives rise to buffer overflows, a vulnerability class that took decades of layered defenses (DEP, Write-XOR-Execute, ASLR, stack canaries, and ultimately memory-safe languages) to contain, because no single mechanism sufficed. The implication is the same: prompt injection cannot be eliminated by better in-pipeline classification or alignment alone. It requires architectural separation of instruction and data channels. We identify the root cause and the class of solution it demands.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that perfect prompt-injection prevention is mathematically impossible in shared-embedding sequence models lacking enforced control-data separation. It formalizes such systems as Prompted Action Models whose outputs include control-authoritative actions, defines Semantic-Faithful Control (SFC) as the property that control depends only on the meaning (not encoding) of untrusted input, and proves SFC unachievable via three results: provenance-recovery impossibility (shared representations inseparable by total variation distance), control-path exposure (untrusted tokens enter control computation via attention aggregation), and finite-coverage invariance gap (finite training cannot certify invariance over infinite semantic classes). Each is grounded in measurements on production tokenizers and models; the result is analogized to Von Neumann code-data confusion.
Significance. If the central claim holds, the work would be significant for LLM security by supplying a structural, information-theoretic account of why in-pipeline defenses have failed and why architectural separation is required. Credit is due for the explicit formalization of Prompted Action Models and SFC, the three distinct proof sketches, and the post-hoc grounding of the quantities (TV distance, attention paths, invariance) in production measurements rather than purely abstract arguments.
major comments (1)
- [Abstract / SFC definition] Abstract and the section introducing SFC: the manuscript proves that SFC is unachievable and concludes that perfect prevention is therefore impossible, yet does not establish that every possible prevention mechanism must satisfy SFC. The three results are derived specifically under the SFC definition (control depends only on meaning of untrusted input, not encoding); if a defense can succeed while allowing control to depend on encoding or other non-SFC properties, the impossibility results do not apply. This premise is load-bearing for the central claim but is introduced definitionally rather than derived.
minor comments (2)
- [Abstract] The abstract refers to 'three proof results' and 'proof sketches' but does not provide section or equation numbers for the formal statements; adding explicit references (e.g., 'Theorem 3.2') would improve traceability.
- The grounding measurements on production tokenizers and models are mentioned but not detailed with error bounds or sample sizes in the abstract; the full text should include these in a dedicated subsection or table.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for identifying the need to strengthen the justification of Semantic-Faithful Control (SFC) as the relevant target property. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract / SFC definition] Abstract and the section introducing SFC: the manuscript proves that SFC is unachievable and concludes that perfect prevention is therefore impossible, yet does not establish that every possible prevention mechanism must satisfy SFC. The three results are derived specifically under the SFC definition (control depends only on meaning of untrusted input, not encoding); if a defense can succeed while allowing control to depend on encoding or other non-SFC properties, the impossibility results do not apply. This premise is load-bearing for the central claim but is introduced definitionally rather than derived.
Authors: We agree that the manuscript introduces SFC definitionally and does not contain an explicit derivation showing that every conceivable prevention mechanism must satisfy it. Our position is that SFC is the appropriate formalization of reliable prompt-injection prevention because any mechanism whose control decisions depend on encoding (rather than meaning) remains vulnerable to semantically equivalent inputs that differ only in representation; such inputs can be generated via synonym substitution, alternative tokenizations, or paraphrases that preserve intent while changing the token sequence. Consequently, encoding-dependent controls do not constitute prevention in the sense relevant to the security goal. Nevertheless, the referee's observation is fair: the manuscript would be stronger with an explicit argument for why non-SFC mechanisms fail to deliver the claimed security property. We will therefore revise the abstract and the section defining SFC to add a short paragraph deriving the necessity of SFC from the requirement that prevention must be robust to meaning-preserving transformations. This revision will not alter the three technical results but will make the scope of the impossibility claim explicit. revision: yes
Circularity Check
No circularity; derivation uses independent definitions and standard arguments
full rationale
The paper introduces Prompted Action Models and defines Semantic-Faithful Control (SFC) explicitly, then derives three impossibility results for SFC using total variation distance bounds on shared representations, attention aggregation paths, and finite-coverage gaps over semantic classes. These rest on architectural properties of sequence models and information-theoretic quantities rather than any self-referential equation, fitted parameter renamed as prediction, or self-citation chain. No load-bearing step reduces by construction to its inputs; the proofs supply independent content grounded in tokenizer and model measurements. The overall claim follows from the stated definitions and results without circular reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math total variation distance bounds statistical inseparability of trusted and untrusted content in shared representations
invented entities (2)
-
Prompted Action Models
no independent evidence
-
Semantic-Faithful Control (SFC)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
An embarrassingly simple defense against LLM abliteration attacks
Harethah Abu Shairah, Hasan Abed Al Kader Hammoud, Bernard Ghanem, and George Turkiyyah. An embarrassingly simple defense against LLM abliteration attacks. arXiv:2505.19056, 2025
arXiv 2025
-
[2]
Anderson
James P. Anderson. Computer Security Technology Planning Study. Technical Report ESD-TR-73-51, USAF, 1972
1972
-
[3]
Many-shot jailbreaking
Cem Anil, Esin Durmus, Mrinank Sharma, Joe Benton, et al. Many-shot jailbreaking. In NeurIPS, 2024
2024
-
[4]
Refusal in language models is mediated by a single direction
Andy Arditi, Oscar Obeso, Aaquib Syed, Daniel Paleka, Nina Panickssery, Wes Gurnee, and Neel Nanda. Refusal in language models is mediated by a single direction. In NeurIPS, 2024
2024
-
[5]
Yampolskiy
Mario Brci\' c and Roman V. Yampolskiy. Impossibility results in AI: A survey. ACM Computing Surveys, 56(1):Article 8, 1--24, 2023
2023
-
[6]
A representation engineering perspective on the effectiveness of multi-turn jailbreaks
Blake Bullwinkel, Mark Russinovich, Ahmed Salem, Santiago Zanella-Beguelin, Daniel Jones, Giorgio Severi, Eugenia Kim, Keegan Hines, Amanda Minnich, Yonatan Zunger, and Ram Shankar Siva Kumar. A representation engineering perspective on the effectiveness of multi-turn jailbreaks. arXiv:2507.02956, 2025
arXiv 2025
-
[7]
Choquette-Choo, Matthew Jagielski, et al
Nicholas Carlini, Milad Nasr, Christopher A. Choquette-Choo, Matthew Jagielski, et al. Are aligned neural networks adversarially aligned? In NeurIPS, 2023
2023
-
[8]
Enhancing chat language models by scaling high-quality instructional conversations
Ning Ding, Yulin Chen, Bokai Xu, et al. Enhancing chat language models by scaling high-quality instructional conversations. In EMNLP, 2023
2023
-
[9]
Goguen and Jos\' e Meseguer
Joseph A. Goguen and Jos\' e Meseguer. Security policies and security models. In IEEE Symposium on Security and Privacy, pages 11--20, 1982
1982
-
[10]
Probabilistic encryption
Shafi Goldwasser and Silvio Micali. Probabilistic encryption. Journal of Computer and System Sciences, 28(2):270--299, 1984
1984
-
[11]
Kai Greshake, Sahar Abdelnabi, Shailesh Mishra, Christoph Endres, Thorsten Holz, and Mario Fritz. Not what you've signed up for: Compromising real-world LLM-integrated applications with indirect prompt injection. arXiv:2302.12173, 2023
Pith/arXiv arXiv 2023
-
[12]
Jailbreaking LLMs: A survey of attacks, defenses and evaluation
Safayat Bin Hakim, Kanchon Gharami, Nahid Farhady Ghalaty, Shafika Showkat Moni, Shouhuai Xu, and Houbing Herbert Song. Jailbreaking LLMs: A survey of attacks, defenses and evaluation. TechRxiv, 2026
2026
-
[13]
Uncensor any LLM with abliteration
Maxime Labonne. Uncensor any LLM with abliteration. HuggingFace Blog, 2024. https://huggingface.co/blog/mlabonne/abliteration
2024
-
[14]
Projected abliteration
Jim Lai. Projected abliteration. HuggingFace Blog, 2025
2025
-
[15]
Formalizing and benchmarking prompt injection attacks and defenses
Yupei Liu, Yuqi Jia, Runpeng Geng, Jinyuan Jia, and Neil Zhenqiang Gong. Formalizing and benchmarking prompt injection attacks and defenses. In USENIX Security, 2024
2024
-
[16]
OWASP Foundation, 2025
OWASP Top 10 for Large Language Model Applications 2025. OWASP Foundation, 2025
2025
-
[17]
Andrei Sabelfeld and Andrew C. Myers. Language-based information-flow security. IEEE Journal on Selected Areas in Communications, 21(1):5--19, 2003
2003
-
[18]
Tsybakov
Alexandre B. Tsybakov. Introduction to Nonparametric Estimation. Springer, 2009
2009
-
[19]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. In NeurIPS, 2017
2017
-
[20]
Jailbroken: How does LLM safety training fail? In NeurIPS, 2023
Alexander Wei, Nika Haghtalab, and Jacob Steinhardt. Jailbroken: How does LLM safety training fail? In NeurIPS, 2023
2023
-
[21]
TurboQuant: Online vector quantization with near-optimal distortion rate
Amir Zandieh, Majid Daliri, Majid Hadian, and Vahab Mirrokni. TurboQuant: Online vector quantization with near-optimal distortion rate. In ICLR, 2026. arXiv:2504.19874
Pith/arXiv arXiv 2026
-
[22]
Zico Kolter, and Matt Fredrikson
Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J. Zico Kolter, and Matt Fredrikson. Universal and transferable adversarial attacks on aligned language models. arXiv:2307.15043, 2023
Pith/arXiv arXiv 2023
-
[23]
Improving alignment and robustness with circuit breakers
Andy Zou, Long Phan, Justin Wang, Derek Duenas, Maxwell Lin, Maksym Andriushchenko, Rowan Wang, Zico Kolter, Matt Fredrikson, and Dan Hendrycks. Improving alignment and robustness with circuit breakers. In NeurIPS, 2024
2024
-
[24]
Egor Zverev, Sahar Abdelnabi, Soroush Tabesh, Mario Fritz, and Christoph H. Lampert. Can LLMs separate instructions from data? and what do we even mean by that? In ICLR, 2025
2025
-
[25]
Egor Zverev, Evgenii Kortukov, Alexander Panfilov, Alexandra Volkova, Soroush Tabesh, Sebastian Lapuschkin, Wojciech Samek, and Christoph H. Lampert. ASIDE: Architectural separation of instructions and data in language models. arXiv:2503.10566, 2025
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.