Safe Autoregressive Image Generation with Iterative Self-Improving Codebooks
Pith reviewed 2026-06-26 05:49 UTC · model grok-4.3
The pith
Autoregressive image models can iteratively refine their codebooks to remove unsafe outputs using only their own judgments.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
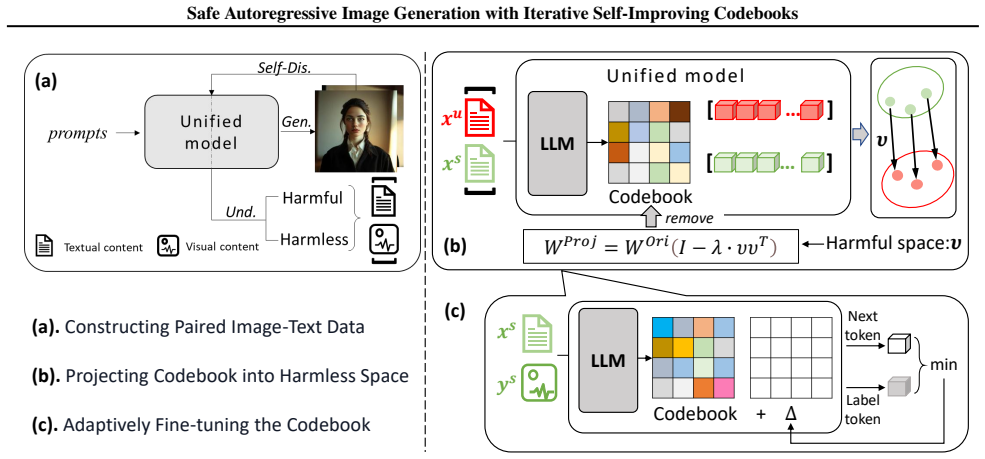
The central discovery is that by leveraging the model's own understanding to identify unsafe generations and construct harmful and safe image-text pairs, the codebook can be updated to eliminate harmful mappings and then adaptively fine-tuned in harmless space, with the process repeated until no further improvement, resulting in a safety-enhanced codebook without additional external feedback.
What carries the argument
Iterative self-improving codebooks, which use the model's judgments to fix representations in the codebook and eliminate harmful outputs while preserving generation quality.
If this is right
- Models can generate safer images by fixing harmful mappings in their codebooks.
- Safety improvements occur iteratively without human annotation.
- Generation quality is maintained through adaptive fine-tuning in harmless space.
- The process stops when no further improvement is observed.
Where Pith is reading between the lines
- If the model's self-judgment is reliable, this method could apply to other safety concerns in multimodal generation.
- Deployed systems might achieve better safety by periodically running this self-improvement loop.
- Further tests could involve checking whether the updated codebook generalizes to new unsafe prompts not seen in the iteration.
Load-bearing premise
The unified multimodal model can accurately and reliably identify unsafe generated images without human annotation.
What would settle it
If the model fails to correctly classify a significant portion of unsafe images it generates, or if fixing the codebook representations reduces image quality substantially.
Figures



read the original abstract
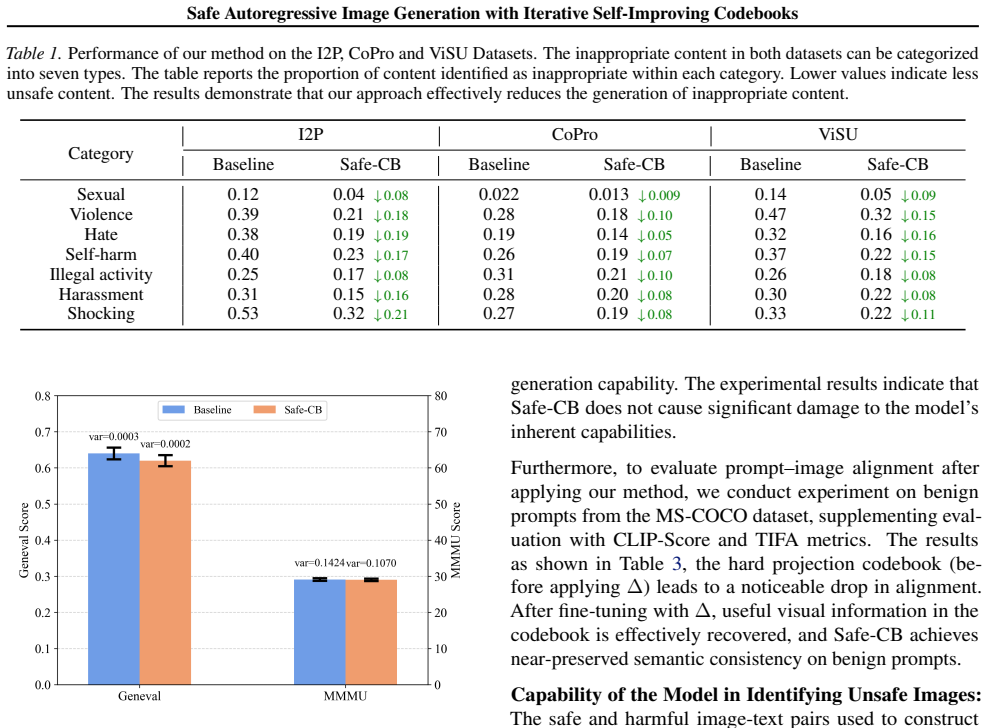
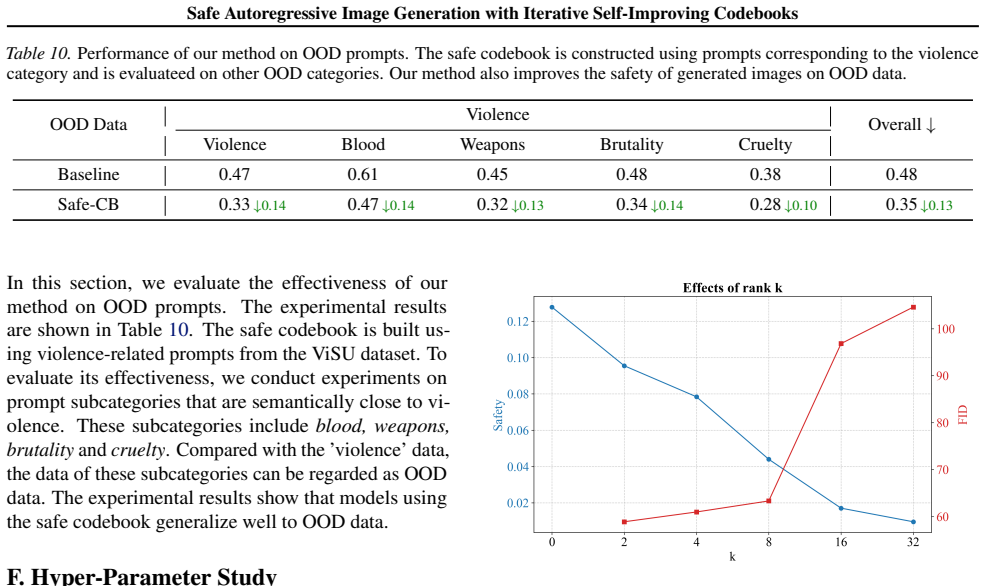
Unlike diffusion-based models that operate in continuous latent spaces, autoregressive unified multimodal models produce images by sequentially predicting discretized visual tokens. These tokens are derived from a codebook that maps embeddings to quantized visual patterns. The language-like architecture enables unified multimodal models to effectively capture text conditional information for generation, making them promising for text-to-image tasks. This also raises an interesting question: how safe are the images generated in such an autoregressive way? In this work, we propose iterative self-improving codebooks for safe autoregressive generation. We leverage the understanding and judgment capabilities of the unified multimodal model itself to identify unsafe generated images without human annotation. Subsequently, the inherent representations in the codebook are fixed to eliminate harmful mappings. Our method comprises two steps: first, we use the unified model to identify unsafe generations and construct corresponding harmful and safe image-text pairs. These pairs are used to construct the Harmful Space and guide updates to the codebook, thereby eliminating harmful outputs. Second, we perform adaptive fine-tuning on the codebook within the harmless space using safe image-text pairs to ensure the quality of generated images. These two steps are repeated until no further improvement is observed, producing a safety-enhanced model codebook. Without additional external feedback, the safety of models is improved iteratively.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes iterative self-improving codebooks for safe autoregressive image generation in unified multimodal models. It claims that the model itself can identify unsafe generated images without human annotation, construct harmful and safe image-text pairs to build a Harmful Space, fix codebook representations to eliminate harmful mappings, and perform adaptive fine-tuning in the harmless space using safe pairs. These steps are repeated iteratively until no further improvement, yielding a safety-enhanced codebook without external feedback.
Significance. If the central claims hold with proper validation, the work would offer a novel annotation-free approach to safety in autoregressive multimodal generation by exploiting internal model judgments and codebook updates. This could address safety concerns in text-to-image systems more scalably than methods requiring external supervision, and the iterative self-improvement loop is a distinctive technical contribution.
major comments (3)
- [Abstract, §3] Abstract and §3: The central claim that the unified model can reliably identify unsafe generations to construct accurate harmful/safe pairs and guide codebook updates is unsupported. No verification of label quality, inter-rater agreement with external annotators, or error rates on the self-labeled pairs is reported, so the subsequent Harmful Space construction and elimination of harmful mappings cannot be guaranteed to succeed.
- [Abstract, §3] Abstract and §3: The iterative process assumes that fixing representations in the codebook eliminates harmful outputs while the adaptive fine-tuning preserves generation quality, yet the manuscript provides no quantitative safety metrics (e.g., before/after safety scores), ablation studies on the two steps, or comparisons against baselines. Without these, the claim that the process produces a safety-enhanced model remains untested.
- [Abstract] Abstract: The method description states that the two steps are repeated 'until no further improvement is observed,' but no convergence criterion, stopping condition, or monitoring metric (e.g., change in harmful output rate) is defined, leaving the termination of the self-improvement loop unspecified.
minor comments (2)
- [Abstract] The abstract and method overview would benefit from explicit definitions of 'Harmful Space' and 'harmless space' with reference to how they are constructed from the image-text pairs.
- Related work on safety in multimodal models (e.g., red-teaming or alignment techniques) is not referenced, which would help situate the self-judgment approach.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and commit to revisions that will strengthen the empirical support for our claims while preserving the annotation-free nature of the proposed method.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3: The central claim that the unified model can reliably identify unsafe generations to construct accurate harmful/safe pairs and guide codebook updates is unsupported. No verification of label quality, inter-rater agreement with external annotators, or error rates on the self-labeled pairs is reported, so the subsequent Harmful Space construction and elimination of harmful mappings cannot be guaranteed to succeed.
Authors: We acknowledge that the submitted manuscript does not report external validation of the self-labeled pairs. While the core contribution is an annotation-free approach, we agree that reliability evidence is needed. In the revision we will add a dedicated evaluation subsection that samples generated images, obtains independent human annotations, and reports error rates together with inter-rater agreement statistics between model and human labels. These results will be used to quantify the quality of the Harmful Space construction. revision: yes
-
Referee: [Abstract, §3] Abstract and §3: The iterative process assumes that fixing representations in the codebook eliminates harmful outputs while the adaptive fine-tuning preserves generation quality, yet the manuscript provides no quantitative safety metrics (e.g., before/after safety scores), ablation studies on the two steps, or comparisons against baselines. Without these, the claim that the process produces a safety-enhanced model remains untested.
Authors: We agree that the current version lacks the quantitative evidence required to substantiate the safety gains. The revised manuscript will include before-and-after safety scores on standard benchmarks, ablation experiments that isolate the codebook-fixing step from the adaptive fine-tuning step, and comparisons against existing safety baselines for autoregressive multimodal models. These additions will appear in the experimental section. revision: yes
-
Referee: [Abstract] Abstract: The method description states that the two steps are repeated 'until no further improvement is observed,' but no convergence criterion, stopping condition, or monitoring metric (e.g., change in harmful output rate) is defined, leaving the termination of the self-improvement loop unspecified.
Authors: We will clarify the stopping condition in both the abstract and Section 3. The revision will define an explicit monitoring metric (change in harmful output rate across iterations) and a numerical threshold below which further iterations are halted. This will make the termination of the self-improvement loop fully specified and reproducible. revision: yes
Circularity Check
No circularity: method is empirical self-labeling without definitional reduction
full rationale
The paper describes an iterative procedure that uses the same multimodal model both to generate images and to label them as safe/unsafe for constructing Harmful Space and updating the codebook. No equations, derivations, or first-principles claims are present that reduce any output quantity to an input by construction (e.g., no fitted parameter renamed as prediction, no self-definitional mapping, no load-bearing self-citation of a uniqueness theorem). The process is an empirical loop whose correctness depends on an external assumption about label quality, but the claimed result (improved codebook) is not mathematically equivalent to the labeling step itself. This is therefore scored as self-contained with no circularity under the enumerated patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F. L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Typology of risks of generative text-to-image models
Bird, C., Ungless, E., and Kasirzadeh, A. Typology of risks of generative text-to-image models. InProceedings of the 2023 AAAI/ACM Conference on AI, Ethics, and Society, pp. 396–410,
2023
-
[4]
D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., et al
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., et al. Language models are few-shot learners. Advances in neural information processing systems, 33: 1877–1901,
1901
-
[5]
Fireact: Toward language agent fine-tuning
Chen, B., Shu, C., Shareghi, E., Collier, N., Narasimhan, K., and Yao, S. Fireact: Toward language agent fine-tuning. arXiv preprint arXiv:2310.05915, 2023a. Chen, X., Lin, M., Sch ¨arli, N., and Zhou, D. Teaching large language models to self-debug.arXiv preprint arXiv:2304.05128, 2023b. Chen, X., Wu, Z., Liu, X., Pan, Z., Liu, W., Xie, Z., Yu, X., and R...
-
[6]
Prompting4debugging: Red-teaming text-to- image diffusion models by finding problematic prompts
Chin, Z.-Y ., Jiang, C.-M., Huang, C.-C., Chen, P.-Y ., and Chiu, W.-C. Prompting4debugging: Red-teaming text-to- image diffusion models by finding problematic prompts. arXiv preprint arXiv:2309.06135,
-
[7]
Fang, J., Jiang, H., Wang, K., Ma, Y ., Jie, S., Wang, X., He, X., and Chua, T.-S. Alphaedit: Null-space constrained knowledge editing for language models.arXiv preprint arXiv:2410.02355,
-
[8]
Mart: Improving llm safety with multi-round automatic red-teaming.arXiv preprint arXiv:2311.07689,
Ge, S., Zhou, C., Hou, R., Khabsa, M., Wang, Y .-C., Wang, Q., Han, J., and Mao, Y . Mart: Improving llm safety with multi-round automatic red-teaming.arXiv preprint arXiv:2311.07689,
-
[9]
CRITIC: Large Language Models Can Self-Correct with Tool-Interactive Critiquing
Gou, Z., Shao, Z., Gong, Y ., Shen, Y ., Yang, Y ., Duan, N., and Chen, W. Critic: Large language models can self- correct with tool-interactive critiquing.arXiv preprint arXiv:2305.11738,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Gu, J. A survey on responsible generative ai: What to generate and what not.arXiv preprint arXiv:2404.05783,
-
[11]
Hahn, M., Zeng, W., Kannen, N., Galt, R., Badola, K., Kim, B., and Wang, Z. Proactive agents for multi-turn text- to-image generation under uncertainty.arXiv preprint arXiv:2412.06771,
-
[12]
Prompt-to-Prompt Image Editing with Cross Attention Control
Hertz, A., Mokady, R., Tenenbaum, J., Aberman, K., Pritch, Y ., and Cohen-Or, D. Prompt-to-prompt im- age editing with cross attention control.arXiv preprint arXiv:2208.01626,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Clipscore: A reference-free evaluation metric for image captioning
Hessel, J., Holtzman, A., Forbes, M., Le Bras, R., and Choi, Y . Clipscore: A reference-free evaluation metric for image captioning. InProceedings of the 2021 conference on empirical methods in natural language processing, pp. 7514–7528,
2021
-
[14]
I., Gu, J., Zhang, J., Pi, R., Chen, Q., Torr, P., Khakzar, A., and Pizzati, F
Liu, R., Chieh, C. I., Gu, J., Zhang, J., Pi, R., Chen, Q., Torr, P., Khakzar, A., and Pizzati, F. Safetydpo: Scalable safety alignment for text-to-image generation.arXiv e-prints, pp. arXiv–2412, 2024a. Liu, R., Khakzar, A., Gu, J., Chen, Q., Torr, P., and Pizzati, F. Latent guard: a safety framework for text-to-image generation. InEuropean Conference on...
-
[15]
Unsafe diffusion: On the generation of unsafe images and hateful memes from text-to-image models
Qu, Y ., Shen, X., He, X., Backes, M., Zannettou, S., and Zhang, Y . Unsafe diffusion: On the generation of unsafe images and hateful memes from text-to-image models. InProceedings of the 2023 ACM SIGSAC conference on computer and communications security, pp. 3403–3417,
2023
-
[16]
arXiv preprint arXiv:2210.04610 , year=
Rando, J., Paleka, D., Lindner, D., Heim, L., and Tram `er, F. Red-teaming the stable diffusion safety filter.arXiv preprint arXiv:2210.04610,
-
[17]
Salimans, T., Karpathy, A., Chen, X., and Kingma, D. P. Pixelcnn++: Improving the pixelcnn with discretized lo- gistic mixture likelihood and other modifications.arXiv preprint arXiv:1701.05517,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Schramowski, P., Tauchmann, C., and Kersting, K. Can ma- chines help us answering question 16 in datasheets, and in turn reflecting on inappropriate content? InProceedings of the 2022 ACM conference on fairness, accountability, and transparency, pp. 1350–1361,
2022
-
[19]
Improving image captioning with better use of captions.arXiv preprint arXiv:2006.11807,
Shi, Z., Zhou, X., Qiu, X., and Zhu, X. Improving image captioning with better use of captions.arXiv preprint arXiv:2006.11807,
-
[20]
Score-Based Generative Modeling through Stochastic Differential Equations
Song, Y ., Sohl-Dickstein, J., Kingma, D. P., Kumar, A., Er- mon, S., and Poole, B. Score-based generative modeling through stochastic differential equations.arXiv preprint arXiv:2011.13456,
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[21]
Autoregressive Model Beats Diffusion: Llama for Scalable Image Generation
Sun, P., Jiang, Y ., Chen, S., Zhang, S., Peng, B., Luo, P., and Yuan, Z. Autoregressive model beats diffusion: Llama for scalable image generation.arXiv preprint arXiv:2406.06525,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y ., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al. Llama 2: Open foundation and fine- tuned chat models.arXiv preprint arXiv:2307.09288,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Effi- cient large language models: A survey.arXiv preprint arXiv:2312.03863,
Wan, Z., Wang, X., Liu, C., Alam, S., Zheng, Y ., Liu, J., Qu, Z., Yan, S., Zhu, Y ., Zhang, Q., et al. Effi- cient large language models: A survey.arXiv preprint arXiv:2312.03863,
-
[24]
Wang, J., Wang, C., Cao, T., Huang, J., and Jin, L. Dif- fchat: Learning to chat with text-to-image synthesis models for interactive image creation.arXiv preprint arXiv:2403.04997, 2024a. Wang, J., He, Y ., Zhong, Y ., Song, X., Su, J., Feng, Y ., He, H., Zhu, W., Yuan, X., Lu, K., et al. Twin co-adaptive dialogue for progressive image generation.arXiv pr...
-
[25]
Emu3: Next-Token Prediction is All You Need
Wang, X., Zhang, X., Luo, Z., Sun, Q., Cui, Y ., Wang, J., Zhang, F., Wang, Y ., Li, Z., Yu, Q., et al. Emu3: Next-token prediction is all you need.arXiv preprint arXiv:2409.18869, 2024b. Wei, J., Wang, X., Schuurmans, D., Bosma, M., Xia, F., Chi, E., Le, Q. V ., Zhou, D., et al. Chain-of-thought prompting elicits reasoning in large language models.Advanc...
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
VILA-U: a Unified Foundation Model Integrating Visual Understanding and Generation
Wu, Y ., Zhang, Z., Chen, J., Tang, H., Li, D., Fang, Y ., Zhu, L., Xie, E., Yin, H., Yi, L., et al. Vila-u: a unified foundation model integrating visual understanding and generation.arXiv preprint arXiv:2409.04429,
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Autore- gressive models in vision: A survey.arXiv preprint arXiv:2411.05902,
Xiong, J., Liu, G., Huang, L., Wu, C., Wu, T., Mu, Y ., Yao, Y ., Shen, H., Wan, Z., Huang, J., et al. Autore- gressive models in vision: A survey.arXiv preprint arXiv:2411.05902,
-
[28]
arXiv preprint arXiv:2410.12761 , year=
Yoon, J., Yu, S., Patil, V ., Yao, H., and Bansal, M. Safree: Training-free and adaptive guard for safe text-to-image and video generation.arXiv preprint arXiv:2410.12761,
-
[29]
Kechi Zhang, Jia Li, Ge Li, Xianjie Shi, and Zhi Jin
Zeng, A., Liu, M., Lu, R., Wang, B., Liu, X., Dong, Y ., and Tang, J. Agenttuning: Enabling generalized agent abilities for llms.arXiv preprint arXiv:2310.12823,
-
[30]
Hive: Harnessing human feedback for instructional visual editing
Zhang, S., Yang, X., Feng, Y ., Qin, C., Chen, C.-C., Yu, N., Chen, Z., Wang, H., Savarese, S., Ermon, S., et al. Hive: Harnessing human feedback for instructional visual editing. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 9026– 9036, 2024a. Zhang, T., Madaan, A., Gao, L., Zheng, S., Mishra, S., Yang, Y ., Tan...
-
[31]
12 Safe Autoregressive Image Generation with Iterative Self-Improving Codebooks Zhang, Y ., Jia, J., Chen, X., Chen, A., Zhang, Y ., Liu, J., Ding, K., and Liu, S. To generate or not? safety-driven un- learned diffusion models are still easy to generate unsafe images... for now. InEuropean Conference on Computer Vision, pp. 385–403. Springer, 2024c. Zhou,...
-
[32]
Zou, J., Liao, B., Zhang, Q., Liu, W., and Wang, X. Omni- mamba: Efficient and unified multimodal understanding and generation via state space models.arXiv preprint arXiv:2503.08686,
-
[33]
The results show that similar experimental phenomena are observed for different categories of harmful content
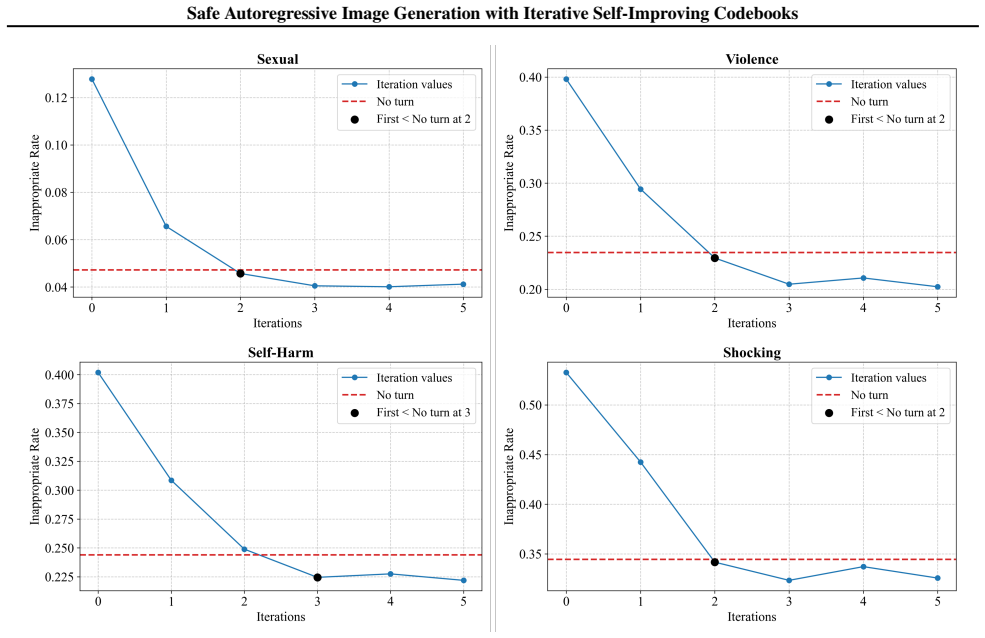
We visualize the detection of inappropriate ratios of generated images for four categories of harmful content:sexual, violence, self-harm,andshocking. The results show that similar experimental phenomena are observed for different categories of harmful content. As the number of iterations increases, the ratio of generated images detected as containing har...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.