SDGBiasBench: Benchmarking and Mitigating Vision--Language Models' Biases in Sustainable Development Goals
Pith reviewed 2026-05-22 07:25 UTC · model grok-4.3
The pith
Vision-language models often substitute SDG-specific priors for visual and contextual evidence when assessing sustainable development tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
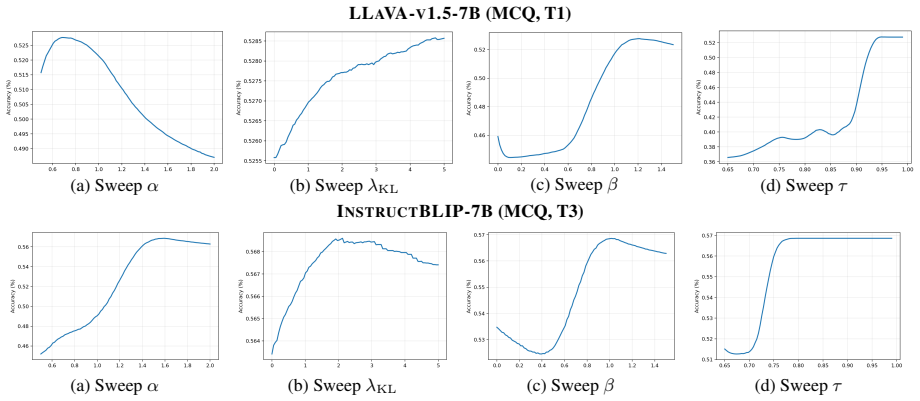
Evaluations on SDGBiasBench reveal an intrinsic SDG bias in current VLMs, where predictions are frequently driven by SDG specific priors rather than reliable multi-modal cues. To mitigate such bias, CADE leverages modality-specific answer priors in a training-free, plug-and-play manner and yields significant gains, improving multiple-choice accuracy by up to 25% and reducing regression MAE by up to 12 points across multiple VLMs.
What carries the argument
SDGBiasBench, a benchmark with 500k expert-involved multiple-choice questions and 50k regression tasks that isolates reliance on SDG priors, paired with CADE which ensembles contrastive modality-specific priors to reduce that reliance.
If this is right
- Both qualitative judgments and quantitative estimations in SDG tasks can be improved simultaneously with the same debiasing step.
- Training-free adjustments suffice to produce measurable lifts in accuracy and error reduction on this scale of benchmark.
- Model outputs become more dependent on the actual image-text pair once modality-specific priors are contrasted.
Where Pith is reading between the lines
- The same prior-substitution pattern could appear in VLMs applied to other specialized domains such as medical imaging or legal document analysis.
- Extending the benchmark to include temporal sequences of images might reveal whether biases strengthen or weaken with additional context.
Load-bearing premise
The expert-involved questions and regression tasks accurately represent real-world SDG monitoring scenarios without introducing their own systematic biases.
What would settle it
If the same models achieve comparable accuracy on a version of the benchmark where SDG labels are randomly reassigned to images while keeping visual content fixed, the claim of intrinsic model priors would be undermined.
Figures






read the original abstract
Assessing progress toward the Sustainable Development Goals (SDGs) requires multi-step reasoning over visual cues, contextual knowledge, and development indicators, where incomplete evidence use and imperfect evidence integration can introduce hidden prediction biases. Real-world SDG monitoring further spans both qualitative judgments and quantitative estimation. However, existing benchmarks typically evaluate these aspects in isolation, obscuring systematic biases that emerge when models substitute priors for evidence. To address this gap, we propose SDGBiasBench, a large-scale benchmark suite for SDG-oriented vision-language reasoning. Spanning 500k expert-involved multiple-choice questions and 50k regression tasks, the benchmark enables comprehensive assessment of both decision-level and estimation-level bias in Vision--Language Models (VLMs). Evaluations on SDGBiasBench reveal an intrinsic SDG bias in current VLMs, where predictions are frequently driven by SDG specific priors rather than reliable multi-modal cues. To mitigate such bias, we propose CADE (Contrastive Adaptive Debias Ensemble), a training-free, plug-and-play method that leverages modality-specific answer priors. CADE yields significant gains on the proposed benchmark, improving multiple-choice accuracy by up to 25% and reducing regression MAE by up to 12 points across multiple VLMs. We hope our work can foster the development of more fair and reliable AI systems for sustainable development.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SDGBiasBench, a large-scale benchmark with 500k expert-involved multiple-choice questions and 50k regression tasks targeting SDG-oriented vision-language reasoning in VLMs. It claims current VLMs exhibit intrinsic SDG bias by substituting SDG-specific priors for multi-modal cues, and proposes the training-free CADE (Contrastive Adaptive Debias Ensemble) method, which reportedly improves multiple-choice accuracy by up to 25% and reduces regression MAE by up to 12 points across multiple VLMs.
Significance. If the benchmark construction demonstrably isolates model priors from visual evidence and the CADE gains are attributable to debiasing rather than benchmark artifacts, the work could support more reliable VLM use in SDG monitoring applications. The scale (500k/50k tasks) is a potential strength for comprehensive evaluation, but this hinges on rigorous validation of the tasks as proxies for real-world multi-modal reasoning.
major comments (2)
- [Benchmark Construction] Benchmark construction section: The paper describes questions and tasks as 'expert-involved' but provides no quantitative validation (e.g., language-only solvability rates on a held-out subset, inter-annotator agreement metrics, or checks for answer-option priors that encode SDG knowledge). Without these, it is unclear whether observed performance gaps reflect VLM substitution of priors for multi-modal cues or artifacts of question phrasing/image selection, directly undermining the central claim of 'intrinsic SDG bias'.
- [Experiments] Evaluation and CADE results section: The reported improvements (up to 25% MC accuracy, 12-point MAE reduction) are given without statistical significance testing, variance across runs, or ablation against non-debiasing baselines (e.g., simple prompt engineering or modality weighting). This makes it difficult to confirm that gains stem specifically from leveraging 'modality-specific answer priors' as intended by CADE rather than other factors.
minor comments (2)
- [Abstract] The abstract and introduction could more explicitly define 'SDG specific priors' with an example from the benchmark to aid reader understanding.
- [Results] Table or figure captions for the main results should include exact VLM names, dataset splits, and confidence intervals to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help clarify areas where the manuscript can be strengthened. We address each major comment below and will revise the paper accordingly to improve the presentation of benchmark validation and experimental results.
read point-by-point responses
-
Referee: [Benchmark Construction] Benchmark construction section: The paper describes questions and tasks as 'expert-involved' but provides no quantitative validation (e.g., language-only solvability rates on a held-out subset, inter-annotator agreement metrics, or checks for answer-option priors that encode SDG knowledge). Without these, it is unclear whether observed performance gaps reflect VLM substitution of priors for multi-modal cues or artifacts of question phrasing/image selection, directly undermining the central claim of 'intrinsic SDG bias'.
Authors: We agree that the manuscript would benefit from explicit quantitative validation metrics to support the benchmark's ability to isolate model priors from visual evidence. The current description notes expert involvement in constructing the 500k multiple-choice questions and 50k regression tasks but does not report the requested metrics. In the revised version, we will expand the benchmark construction section to include language-only solvability rates on a held-out subset, inter-annotator agreement statistics, and analyses of answer-option priors. These additions will directly address whether performance gaps arise from intrinsic SDG bias or from question/image artifacts. revision: yes
-
Referee: [Experiments] Evaluation and CADE results section: The reported improvements (up to 25% MC accuracy, 12-point MAE reduction) are given without statistical significance testing, variance across runs, or ablation against non-debiasing baselines (e.g., simple prompt engineering or modality weighting). This makes it difficult to confirm that gains stem specifically from leveraging 'modality-specific answer priors' as intended by CADE rather than other factors.
Authors: We concur that including statistical tests, run variance, and targeted ablations would strengthen the attribution of CADE's gains to its contrastive debiasing mechanism. The manuscript reports the accuracy and MAE improvements across VLMs but does not present these supporting analyses. We will revise the evaluation and CADE results section to add statistical significance testing, standard deviations or variance across runs, and ablations against non-debiasing baselines such as prompt engineering and modality weighting. This will help confirm that the reported gains arise specifically from leveraging modality-specific answer priors. revision: yes
Circularity Check
No circularity: empirical benchmark construction and plug-and-play mitigation method
full rationale
The paper introduces SDGBiasBench as a new dataset of expert-involved MCQs and regression tasks, then reports VLM performance and proposes the training-free CADE ensemble. No equations, fitted parameters, or derivations are present. The central claims rest on direct evaluation results rather than any self-referential reduction, self-citation chain, or renaming of prior results. The benchmark and method are self-contained against external model testing.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Expert-involved questions accurately capture multi-step SDG reasoning without introducing confounding biases.
invented entities (1)
-
CADE (Contrastive Adaptive Debias Ensemble)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Evaluations on SDGBiasBench reveal an intrinsic SDG bias in current VLMs, where predictions are frequently driven by SDG specific priors rather than reliable multi-modal cues.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
CADE ... leverages modality-specific answer priors ... improving multiple-choice accuracy by up to 25%
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Advances in neural information processing systems , volume =
Flamingo: a visual language model for few-shot learning , author =. Advances in neural information processing systems , volume =
- [2]
-
[3]
Proceedings of the IEEE international conference on computer vision , pages =
Vqa: Visual question answering , author =. Proceedings of the IEEE international conference on computer vision , pages =
-
[4]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages =
Benchmarking and Mitigating MCQA Selection Bias of Large Vision-Language Models , author =. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages =
work page 2025
-
[5]
Qwen2. 5-vl technical report , author =. arXiv preprint arXiv:2502.13923 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Proceedings of the 2021 ACM conference on fairness, accountability, and transparency , pages =
On the dangers of stochastic parrots: Can language models be too big? , author =. Proceedings of the 2021 ACM conference on fairness, accountability, and transparency , pages =
work page 2021
-
[7]
arXiv preprint arXiv:2005.14050 , year =
Language (technology) is power: A critical survey of" bias" in nlp , author =. arXiv preprint arXiv:2005.14050 , year =
-
[8]
On the Opportunities and Risks of Foundation Models
On the opportunities and risks of foundation models , author=. arXiv preprint arXiv:2108.07258 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
arXiv preprint arXiv:2312.10114 , year =
FoMo-Bench: a multi-modal, multi-scale and multi-task Forest Monitoring Benchmark for remote sensing foundation models , author =. arXiv preprint arXiv:2312.10114 , year =
-
[10]
Using satellite imagery to understand and promote sustainable development , author =. Science , volume =. 2021 , publisher =
work page 2021
-
[11]
PaLI-X: On Scaling up a Multilingual Vision and Language Model
Pali-x: On scaling up a multilingual vision and language model , author =. arXiv preprint arXiv:2305.18565 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Expanding performance boundaries of open-source multimodal models with model, data, and test-time scaling , author =. arXiv preprint arXiv:2412.05271 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models , author =. arXiv preprint arXiv:2504.10479 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
The Twelfth International Conference on Learning Representations , year =
DoLa: Decoding by Contrasting Layers Improves Factuality in Large Language Models , author =. The Twelfth International Conference on Learning Representations , year =
-
[15]
International journal of epidemiology , volume =
Demographic and health surveys: a profile , author =. International journal of epidemiology , volume =. 2012 , publisher =
work page 2012
-
[16]
Advances in neural information processing systems , volume =
Instructblip: Towards general-purpose vision-language models with instruction tuning , author =. Advances in neural information processing systems , volume =
-
[17]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages =
Geobench-vlm: Benchmarking vision-language models for geospatial tasks , author =. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages =
-
[18]
Mme: A comprehensive evaluation benchmark for multimodal large language models , author =. The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year =
-
[19]
Gemini 2.0: Unlocking New Capabilities in Multimodal AI , author =. 2024 , url =
work page 2024
-
[20]
Advances in neural information processing systems , volume=
Equality of opportunity in supervised learning , author=. Advances in neural information processing systems , volume=
-
[21]
Can human development be measured with satellite imagery? , author =. Proceedings of the Ninth International Conference on Information and Communication Technologies and Development , pages =
-
[22]
American economic review , volume=
Measuring economic growth from outer space , author=. American economic review , volume=. 2012 , publisher=
work page 2012
-
[23]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages =
Ai sees your location—but with a bias toward the wealthy world , author =. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages =
work page 2025
-
[24]
arXiv preprint arXiv:2503.07575 , year =
VisBias: Measuring Explicit and Implicit Social Biases in Vision Language Models , author =. arXiv preprint arXiv:2503.07575 , year =
-
[25]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages =
Gqa: A new dataset for real-world visual reasoning and compositional question answering , author =. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages =
-
[26]
Multi-modal bias: Introducing a framework for stereotypical bias assessment beyond gender and race in vision--language models , author =. Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics , pages =
-
[27]
Combining satellite imagery and machine learning to predict poverty , author =. Science , volume =. 2016 , doi =
work page 2016
-
[28]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
Geochat: Grounded large vision-language model for remote sensing , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
-
[29]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
Mitigating object hallucinations in large vision-language models through visual contrastive decoding , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
-
[30]
International conference on machine learning , pages =
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models , author =. International conference on machine learning , pages =. 2023 , organization =
work page 2023
-
[31]
Contrastive decoding: Open-ended text generation as optimization , author =. Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: Long papers) , pages =
-
[32]
Evaluating Object Hallucination in Large Vision-Language Models
Evaluating object hallucination in large vision-language models , author =. arXiv preprint arXiv:2305.10355 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
LLaVA-OneVision: Easy Visual Task Transfer
Llava-onevision: Easy visual task transfer , author =. arXiv preprint arXiv:2408.03326 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
arXiv preprint arXiv:2306.01879 , year =
Revisiting the role of language priors in vision-language models , author =. arXiv preprint arXiv:2306.01879 , year =
-
[35]
Advances in neural information processing systems , volume =
Visual instruction tuning , author =. Advances in neural information processing systems , volume =
-
[36]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages =
Improved baselines with visual instruction tuning , author =. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages =
-
[37]
Advances in Neural Information Processing Systems , volume =
Learn to explain: Multimodal reasoning via thought chains for science question answering , author =. Advances in Neural Information Processing Systems , volume =
-
[38]
Large language models are geographically biased , author =. arXiv preprint arXiv:2402.02680 , year =
-
[39]
Pangaea: A global and inclusive benchmark for geospatial foundation models , author =. arXiv preprint arXiv:2412.04204 , year =
-
[40]
Proceedings of the conference on fairness, accountability, and transparency , pages =
Model cards for model reporting , author =. Proceedings of the conference on fairness, accountability, and transparency , pages =
-
[41]
StereoSet: Measuring stereotypical bias in pretrained language models , author =. Proceedings of the 59th annual meeting of the association for computational linguistics and the 11th international joint conference on natural language processing (volume 1: long papers) , pages =
-
[42]
CrowS-pairs: A challenge dataset for measuring social biases in masked language models , author =. Proceedings of the 2020 conference on empirical methods in natural language processing (EMNLP) , pages =
work page 2020
-
[43]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages =
Counterfactual vqa: A cause-effect look at language bias , author =. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages =
- [44]
-
[45]
Advances in Neural Information Processing Systems , volume =
No filter: Cultural and socioeconomic diversity in contrastive vision-language models , author =. Advances in Neural Information Processing Systems , volume =
-
[46]
International conference on machine learning , pages =
Learning transferable visual models from natural language supervision , author =. International conference on machine learning , pages =. 2021 , organization =
work page 2021
-
[47]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages =
Debias your large multi-modal model at test-time with non-contrastive visual attribute steering , author =. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages =
-
[48]
Measuring social biases in grounded vision and language embeddings , author =. Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages =
work page 2021
-
[49]
Findings of the Association for Computational Linguistics: ACL 2023 , year =
A multi-dimensional study on bias in vision-language models , author =. Findings of the Association for Computational Linguistics: ACL 2023 , year =
work page 2023
-
[50]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages =
Earthdial: Turning multi-sensory earth observations to interactive dialogues , author =. Proceedings of the Computer Vision and Pattern Recognition Conference , pages =
-
[51]
Transforming our world: the 2030 Agenda for Sustainable Development , year =
work page 2030
-
[52]
Mitigating hallucinations in large vision-language models with instruction contrastive decoding
Mitigating hallucinations in large vision-language models with instruction contrastive decoding , author =. arXiv preprint arXiv:2403.18715 , year =
-
[53]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages =
Images speak louder than words: Understanding and mitigating bias in vision-language model from a causal mediation perspective , author =. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages =
work page 2024
-
[54]
arXiv preprint arXiv:2407.02814 , year =
Images Speak Louder than Words: Understanding and Mitigating Bias in Vision-Language Model from a Causal Mediation Perspective , author =. arXiv preprint arXiv:2407.02814 , year =
-
[55]
Nature communications , volume =
Using publicly available satellite imagery and deep learning to understand economic well-being in Africa , author =. Nature communications , volume =. 2020 , publisher =
work page 2020
-
[56]
Sustainbench: Bench- marks for monitoring the sustainable development goals with machine learning
Sustainbench: Benchmarks for monitoring the sustainable development goals with machine learning , author =. arXiv preprint arXiv:2111.04724 , year =
-
[57]
Proceedings of the 30th ACM International Conference on Multimedia , pages =
Counterfactually measuring and eliminating social bias in vision-language pre-training models , author =. Proceedings of the 30th ACM International Conference on Multimedia , pages =
-
[58]
Proceedings of the 33rd ACM International Conference on Multimedia , pages =
Debiasing multimodal large language models via penalization of language priors , author =. Proceedings of the 33rd ACM International Conference on Multimedia , pages =
-
[59]
Vlstereoset: A study of stereotypical bias in pre-trained vision-language models , author =. Proceedings of the 2nd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 12th International Joint Conference on Natural Language Processing (Volume 1: Long Papers) , pages =
-
[60]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages =
Ibd: Alleviating hallucinations in large vision-language models via image-biased decoding , author =. Proceedings of the Computer Vision and Pattern Recognition Conference , pages =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.