AMALIA-VL: A Native European Portuguese Open-Source Vision and Language Model
Pith reviewed 2026-07-01 07:32 UTC · model grok-4.3
The pith
AMALIA-VL is the first open-source instruction-tuned LVLM built natively for European Portuguese.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce AMALIA-VL, the first open-source instruction-tuned LVLM built natively for pt-PT, pairing a high-resolution vision encoder with dynamic image tiling and a fully open pt-PT-optimized language model via a learned connector. We contribute with a purposefully designed three-stage training process - vision-language alignment, general visual instruction tuning, and preference optimization - together with a pt-PT-centric multimodal data mix combining curated and translated public datasets with novel datasets that address the near-total absence of European Portuguese multimodal resources. Our evaluation shows that AMALIA-VL establishes a strong baseline for open-source pt-PT LVLMs.
What carries the argument
The three-stage training process applied to a pt-PT-centric multimodal data mix that combines curated public datasets, translations, and novel datasets created to fill the gap in European Portuguese resources.
If this is right
- AMALIA-VL establishes a strong baseline for open-source pt-PT LVLMs.
- Release of model weights, training data, construction pipelines, and machine-translated pt-PT evaluation benchmarks will help democratize pt-PT LVLM development.
- The approach supplies novel datasets that directly address the near-total absence of European Portuguese multimodal resources.
Where Pith is reading between the lines
- Native construction may yield advantages on tasks involving European-specific cultural references or linguistic distinctions that mixed Portuguese training data obscures.
- The same data-mix and staging pattern could be replicated for other language variants that current multilingual models treat as interchangeable.
- Performance gaps would be more convincingly shown by testing on naturally occurring, untranslated pt-PT image-text pairs rather than machine-translated benchmarks.
Load-bearing premise
The curated and translated data mix plus three-stage training process produces a model that is meaningfully native to pt-PT rather than a routine adaptation of existing multilingual LVLMs.
What would settle it
Direct head-to-head results in which a multilingual LVLM fine-tuned on equivalent pt-PT data matches or exceeds AMALIA-VL on pt-PT evaluation benchmarks would undermine the claim that the native construction is required.
Figures
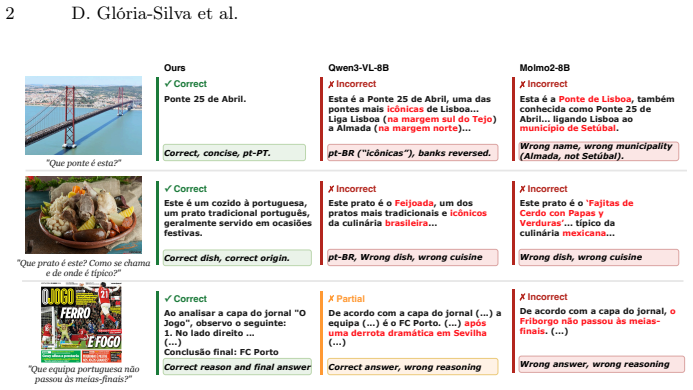


read the original abstract
Large Vision and Language Models (LVLMs) have advanced rapidly, yet European Portuguese (pt-PT) remains systematically underserved by existing open-source multimodal models, which either conflate it with Brazilian Portuguese or severely under-represent it in their training data mixes. We introduce AMALIA-VL, the first open-source instruction-tuned LVLM built natively for pt-PT, pairing a high-resolution vision encoder with dynamic image tiling and a fully open pt-PT-optimized language model via a learned connector. We contribute with a purposefully designed three-stage training process - vision-language alignment, general visual instruction tuning, and preference optimization - together with a pt-PT-centric multimodal data mix combining curated and translated public datasets with novel datasets that address the near-total absence of European Portuguese multimodal resources. Our evaluation shows that AMALIA-VL establishes a strong baseline for open-source pt-PT LVLMs.We will release model weights, training data, and construction pipelines along with machine-translated pt-PT evaluation benchmarks to help democratize pt-PT LVLM development.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce AMALIA-VL, the first open-source instruction-tuned LVLM built natively for European Portuguese (pt-PT). It pairs a high-resolution vision encoder with dynamic image tiling and a pt-PT-optimized language model via a learned connector, using a three-stage training process (vision-language alignment, general visual instruction tuning, and preference optimization) along with a pt-PT-centric multimodal data mix of curated/translated public datasets and novel datasets. The abstract asserts that evaluations establish a strong baseline for open-source pt-PT LVLMs and announces plans to release model weights, training data, pipelines, and machine-translated benchmarks.
Significance. If supported by quantitative evidence, the work would address a clear gap in open multimodal resources for pt-PT, providing a dedicated training pipeline and data contributions that could serve as a template for other underrepresented language variants.
major comments (2)
- [Abstract] Abstract: The assertion that 'Our evaluation shows that AMALIA-VL establishes a strong baseline for open-source pt-PT LVLMs' is unsupported by any quantitative results, tables, figures, ablation studies, or error analysis. This directly undermines the central claim of successful native training and performance.
- [Abstract] Abstract, paragraph 2: The claim that the pt-PT-centric data mix and three-stage training produces a model 'meaningfully native to pt-PT' (rather than a routine multilingual adaptation) lacks any dialect-specific metrics, pt-PT vs. pt-BR task deltas, or ablations removing the novel datasets, making the 'native' distinction unverifiable from the manuscript.
minor comments (1)
- [Abstract] Abstract: The abstract is lengthy and packs multiple technical claims into single sentences; breaking it into clearer paragraphs would improve readability.
Simulated Author's Rebuttal
We thank the referee for the thorough review and constructive feedback on the abstract. We agree that the current manuscript text does not provide the quantitative support needed for the stated claims and will revise to address this.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion that 'Our evaluation shows that AMALIA-VL establishes a strong baseline for open-source pt-PT LVLMs' is unsupported by any quantitative results, tables, figures, ablation studies, or error analysis. This directly undermines the central claim of successful native training and performance.
Authors: We acknowledge this point. The manuscript as submitted does not include the supporting evaluation results, tables, or analyses referenced in the abstract. In the revised version we will add a full evaluation section with quantitative benchmarks, baseline comparisons, ablations, and error analysis to substantiate the claim, and we will revise the abstract to align with the new content. revision: yes
-
Referee: [Abstract] Abstract, paragraph 2: The claim that the pt-PT-centric data mix and three-stage training produces a model 'meaningfully native to pt-PT' (rather than a routine multilingual adaptation) lacks any dialect-specific metrics, pt-PT vs. pt-BR task deltas, or ablations removing the novel datasets, making the 'native' distinction unverifiable from the manuscript.
Authors: We agree that dialect-specific evidence is required to support the 'native' framing. The current manuscript does not contain pt-PT vs. pt-BR deltas or ablations isolating the novel datasets. We will incorporate these analyses in the revised manuscript, including targeted metrics and ablation studies, to make the distinction verifiable. revision: yes
Circularity Check
No circularity in empirical LVLM construction
full rationale
The paper presents an empirical model-building effort: data curation/translation, a three-stage training pipeline (alignment, instruction tuning, preference optimization), and a connector between vision encoder and language model. No equations, fitted parameters presented as predictions, uniqueness theorems, or first-principles derivations exist that could reduce to inputs by construction. The central claim of 'native' pt-PT status rests on the described data mix and training choices rather than any self-referential loop or renamed known result. Self-citations, if present, are not load-bearing for any mathematical step. This is a standard self-contained empirical contribution with no detectable circularity under the specified patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Existing open-source LVLMs either conflate pt-PT with Brazilian Portuguese or severely under-represent it
Reference graph
Works this paper leans on
-
[1]
et al.: Tallyqa: Answering complex counting questions
Acharya, M. et al.: Tallyqa: Answering complex counting questions. In: AAAI (2019)
2019
-
[2]
AI, M.: Ministral 3. CoRRabs/2601.08584(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
LLaVA-OneVision-1.5: Fully Open Framework for Democratized Multimodal Training
An, X. et al.: Llava-onevision-1.5: Fully open framework for democratized multi- modal training. CoRRabs/2509.23661(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
et al.: VQA: Visual Question Answering
Antol, S. et al.: VQA: Visual Question Answering. In: ICCV (2015)
2015
-
[5]
et al.: Are we on the right way for evaluating large vision-language models? In: NeurIPS (2024)
Chen, L. et al.: Are we on the right way for evaluating large vision-language models? In: NeurIPS (2024)
2024
-
[6]
Cho, J.H. et al.: Perceptionlm: Open-access data and models for detailed visual understanding. CoRRabs/2504.13180(2025) 12 D. Glória-Silva et al
-
[7]
Molmo2: Open Weights and Data for Vision-Language Models with Video Understanding and Grounding
Clark, C. et al.: Molmo2: Open weights and data for vision-language models with video understanding and grounding. CoRRabs/2601.10611(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[8]
et al.: Visual Dialog
Das, A. et al.: Visual Dialog. In: CVPR (2017)
2017
-
[9]
et al.: Embspatial-bench: Benchmarking spatial understanding for embodied tasks with large vision-language models
Du, M. et al.: Embspatial-bench: Benchmarking spatial understanding for embodied tasks with large vision-language models. In: ACL. pp. 346–355 (2024)
2024
-
[10]
et al.: Translategemma technical report
Finkelstein, M. et al.: Translategemma technical report. arXiv (2026)
2026
-
[11]
MME: A Comprehensive Evaluation Benchmark for Multimodal Large Language Models
Fu, C. et al.: MME: A comprehensive evaluation benchmark for multimodal large language models. CoRRabs/2306.13394(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
Gemma Team: Gemma 4: Byte for byte, the most capable open models (2026)
2026
-
[13]
et al.: Salamandra technical report (2025)
Gonzalez-Agirre, A. et al.: Salamandra technical report (2025)
2025
-
[14]
CodeSearchNet Challenge: Evaluating the State of Semantic Code Search
Husain, H. et al.: CodeSearchNet challenge: Evaluating the state of semantic code search. arXiv:1909.09436 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[15]
et al.: Geomverse: A systematic evaluation of large models for geometric reasoning
Kazemi, M. et al.: Geomverse: A systematic evaluation of large models for geometric reasoning. In: AI for Math Workshop @ ICML 2024 (2024)
2024
-
[16]
et al.: ReferItGame: Referring to objects in photographs of natural scenes
Kazemzadeh, S. et al.: ReferItGame: Referring to objects in photographs of natural scenes. In: EMNLP. pp. 787–798 (2014)
2014
-
[17]
et al.: A diagram is worth a dozen images
Kembhavi, A. et al.: A diagram is worth a dozen images. In: ECCV. pp. 235–251. Lecture Notes in Computer Science, Springer (2016)
2016
-
[18]
et al.: Openimages: A public dataset for large-scale multi-label and multi-class image classification
Krasin, I. et al.: Openimages: A public dataset for large-scale multi-label and multi-class image classification. (2017)
2017
-
[19]
et al.: Seed-bench: Benchmarking multimodal large language models
Li, B. et al.: Seed-bench: Benchmarking multimodal large language models. In: Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 13299–13308 (June 2024)
2024
-
[20]
LLaVA-NeXT-Interleave: Tackling Multi-image, Video, and 3D in Large Multimodal Models
Li, F. et al.: Llava-next-interleave: Tackling multi-image, video, and 3d in large multimodal models. CoRRabs/2407.07895(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
et al.: Evaluating object hallucination in large vision-language models
Li, Y. et al.: Evaluating object hallucination in large vision-language models. In: EMNLP. pp. 292–305 (2023)
2023
-
[22]
arXiv preprint arXiv:2501.14818 , year=
Li, Z. et al.: Eagle 2: Building post-training data strategies from scratch for frontier vision-language models. CoRRabs/2501.14818(2025)
-
[23]
et al.: FATURA: A multi-layout invoice image dataset for document analysis and understanding
Limam, M. et al.: FATURA: A multi-layout invoice image dataset for document analysis and understanding. CoRRabs/2311.11856(2023)
-
[24]
et al.: Microsoft COCO: common objects in context
Lin, T. et al.: Microsoft COCO: common objects in context. In: ECCV. pp. 740–755. Lecture Notes in Computer Science, Springer (2014)
2014
-
[25]
et al.: Clevr-math: A dataset for compositional language, visual and mathematical reasoning
Lindström, A.D. et al.: Clevr-math: A dataset for compositional language, visual and mathematical reasoning. In: NeuSys. CEUR Workshop (2022)
2022
-
[26]
et al.: Ocrbench: on the hidden mystery of OCR in large multimodal models
Liu, Y. et al.: Ocrbench: on the hidden mystery of OCR in large multimodal models. Sci. China Inf. Sci.67(12) (2024)
2024
-
[27]
et al.: Decoupled weight decay regularization
Loshchilov, I. et al.: Decoupled weight decay regularization. In: ICLR (2019)
2019
-
[28]
et al.: Learn to explain: Multimodal reasoning via thought chains for science question answering
Lu, P. et al.: Learn to explain: Multimodal reasoning via thought chains for science question answering. In: NeurIPS (2022)
2022
-
[29]
et al.: Mmevol: Empowering multimodal large language models with evol-instruct
Luo, R. et al.: Mmevol: Empowering multimodal large language models with evol-instruct. In: ACL Findings 2025
2025
-
[30]
et al.: Eurollm: Multilingual language models for europe
Martins, P.H. et al.: Eurollm: Multilingual language models for europe. CoRR abs/2409.16235(2024)
-
[31]
et al.: Chartqa: A benchmark for question answering about charts with visual and logical reasoning
Masry, A. et al.: Chartqa: A benchmark for question answering about charts with visual and logical reasoning. In: Findings of ACL. pp. 2263–2279 (2022)
2022
-
[32]
et al.: Infographicvqa
Mathew, M. et al.: Infographicvqa. In: IEEE/CVF WACV. IEEE (2022)
2022
-
[33]
et al.: Docvqa: A dataset for VQA on document images
Mathew, M. et al.: Docvqa: A dataset for VQA on document images. In: IEEE WACV. pp. 2199–2208. IEEE (2021)
2021
-
[34]
Hugging Face (2025), https://huggingface.co/ datasets/mazafard/portuguese-ocr-dataset AMALIA-VL 13
mazafard: Portuguese OCR dataset. Hugging Face (2025), https://huggingface.co/ datasets/mazafard/portuguese-ocr-dataset AMALIA-VL 13
2025
-
[35]
et al.: Public domain 12m: A highly aesthetic image-text dataset with novel governance mechanisms
Meyer, J. et al.: Public domain 12m: A highly aesthetic image-text dataset with novel governance mechanisms. CoRRabs/2410.23144(2024)
-
[36]
et al.: Scene text recognition using higher order language priors
Mishra, A. et al.: Scene text recognition using higher order language priors. In: BMVC (2012)
2012
-
[37]
et al.: Ocr-vqa: Visual question answering by reading text in images
Mishra, A. et al.: Ocr-vqa: Visual question answering by reading text in images. In: ICDAR (2019)
2019
-
[38]
NVIDIA: NVIDIA nemotron nano V2 VL. CoRRabs/2511.03929(2025)
-
[39]
Qwen Team: Qwen3.5: Towards native multimodal agents (2026), https://qwen.ai
2026
-
[40]
et al.: Direct preference optimization: Your language model is secretly a reward model
Rafailov, R. et al.: Direct preference optimization: Your language model is secretly a reward model. In: NeurIPS 2023 (2023)
2023
-
[41]
et al.: V-GlórIA - customizing large vision and language models to European Portuguese
Simplício, A. et al.: V-GlórIA - customizing large vision and language models to European Portuguese. In: CustomNLP4U. pp. 317–326 (2024)
2024
-
[42]
et al.: AMALIA: A fully open large language model for European Portuguese
Simplício, A. et al.: AMALIA: A fully open large language model for European Portuguese. In: PROPOR. pp. 380–391 (2026)
2026
-
[43]
et al.: Towards VQA models that can read
Singh, A. et al.: Towards VQA models that can read. In: IEEE CVPR (2019)
2019
-
[44]
et al.: Encoder vs decoder: Comparative analysis of encoder and decoder language models on multilingual nlu tasks
Smart, D.S. et al.: Encoder vs decoder: Comparative analysis of encoder and decoder language models on multilingual nlu tasks. arXiv (2024)
2024
-
[45]
et al.: Enhancing portuguese variety identification with cross-domain approaches
Sousa, H. et al.: Enhancing portuguese variety identification with cross-domain approaches. AAAI39, 25192–25200 (2025)
2025
-
[46]
Team, G.: Gemma 3 technical report. CoRRabs/2503.19786(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
Team, G.V.: Glm-4.5v and glm-4.1v-thinking: Towards versatile multimodal rea- soning with scalable reinforcement learning (2025)
2025
-
[48]
Team, Q.: Qwen3-vl technical report. CoRRabs/2511.21631(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
et al.: YFCC100M: the new data in multimedia research
Thomee, B. et al.: YFCC100M: the new data in multimedia research. ACM (2016)
2016
-
[50]
et al.: Siglip 2: Multilingual vision-language encoders with improved semantic understanding, localization, and dense features
Tschannen, M. et al.: Siglip 2: Multilingual vision-language encoders with improved semantic understanding, localization, and dense features. arXiv (2025)
2025
-
[51]
et al.: ALBA: A European Portuguese benchmark for evaluating language and linguistic dimensions in generative LLMs
Vieira, I. et al.: ALBA: A European Portuguese benchmark for evaluating language and linguistic dimensions in generative LLMs. In: PROPOR (2026)
2026
-
[52]
et al.: Towervision: Understanding and improving multilinguality in vision-language models
Viveiros, A. et al.: Towervision: Understanding and improving multilinguality in vision-language models. CoRRabs/2510.21849(2025)
-
[53]
et al.: Measuring multimodal mathematical reasoning with math-vision dataset
Wang, K. et al.: Measuring multimodal mathematical reasoning with math-vision dataset. In: NeurIPS (2024)
2024
-
[54]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Wang, W. et al.: Internvl3.5: Advancing open-source multimodal models in versatil- ity, reasoning, and efficiency. CoRRabs/2508.18265(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
https:// huggingface.co/datasets/xai-org/RealworldQA (2024)
xAI: Realworldqa: A benchmark for real-world spatial understanding. https:// huggingface.co/datasets/xai-org/RealworldQA (2024)
2024
-
[56]
et al.: Demystifying CLIP data
Xu, H. et al.: Demystifying CLIP data. In: ICLR (2024)
2024
-
[57]
et al.: Scaling text-rich image understanding via code-guided synthetic multimodal data generation
Yang, Y. et al.: Scaling text-rich image understanding via code-guided synthetic multimodal data generation. In: ACL 2025 (2025)
2025
-
[58]
et al.: Minicpm-v 4.5: Cooking efficient mllms via architecture, data, and training recipe (2025)
Yu, T. et al.: Minicpm-v 4.5: Cooking efficient mllms via architecture, data, and training recipe (2025)
2025
-
[59]
et al.: MMMU: A massive multi-discipline multimodal understanding and reasoning benchmark for expert AGI
Yue, X. et al.: MMMU: A massive multi-discipline multimodal understanding and reasoning benchmark for expert AGI. In: IEEE/CVF CVPR. IEEE (2024)
2024
-
[60]
et al.: Mmmu-pro: A more robust multi-discipline multimodal understanding benchmark
Yue, X. et al.: Mmmu-pro: A more robust multi-discipline multimodal understanding benchmark. In: ACL. pp. 15134–15186 (2025)
2025
-
[61]
et al.: Lmms-eval: Reality check on the evaluation of large multimodal models
Zhang, K. et al.: Lmms-eval: Reality check on the evaluation of large multimodal models. In: NAACL Findings. pp. 881–916. ACL (2025)
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.