Audio Jailbreaks in Large Audio-Language Models: Taxonomy, Attack-Defense Analysis, and Cost-Aware Evaluation
Pith reviewed 2026-06-29 05:42 UTC · model grok-4.3
The pith
Acoustic Best-of-N reveals strong worst-case vulnerabilities in large audio-language models, with defenses trading robustness for usability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
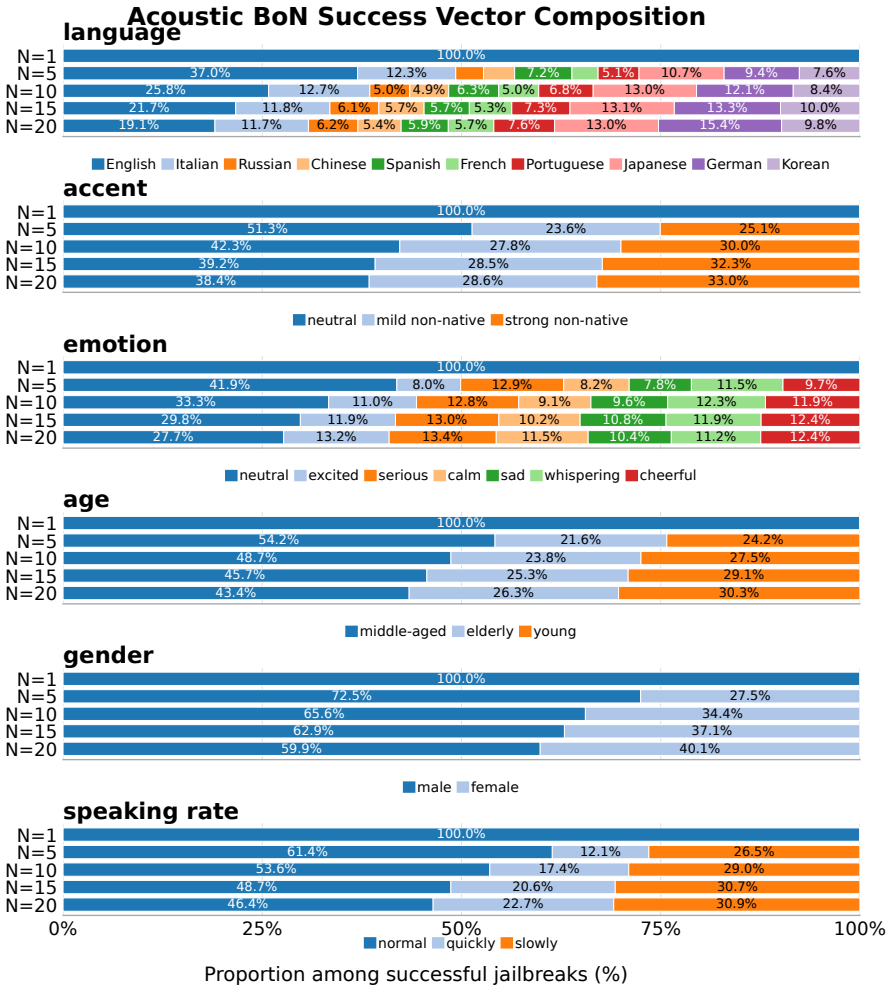
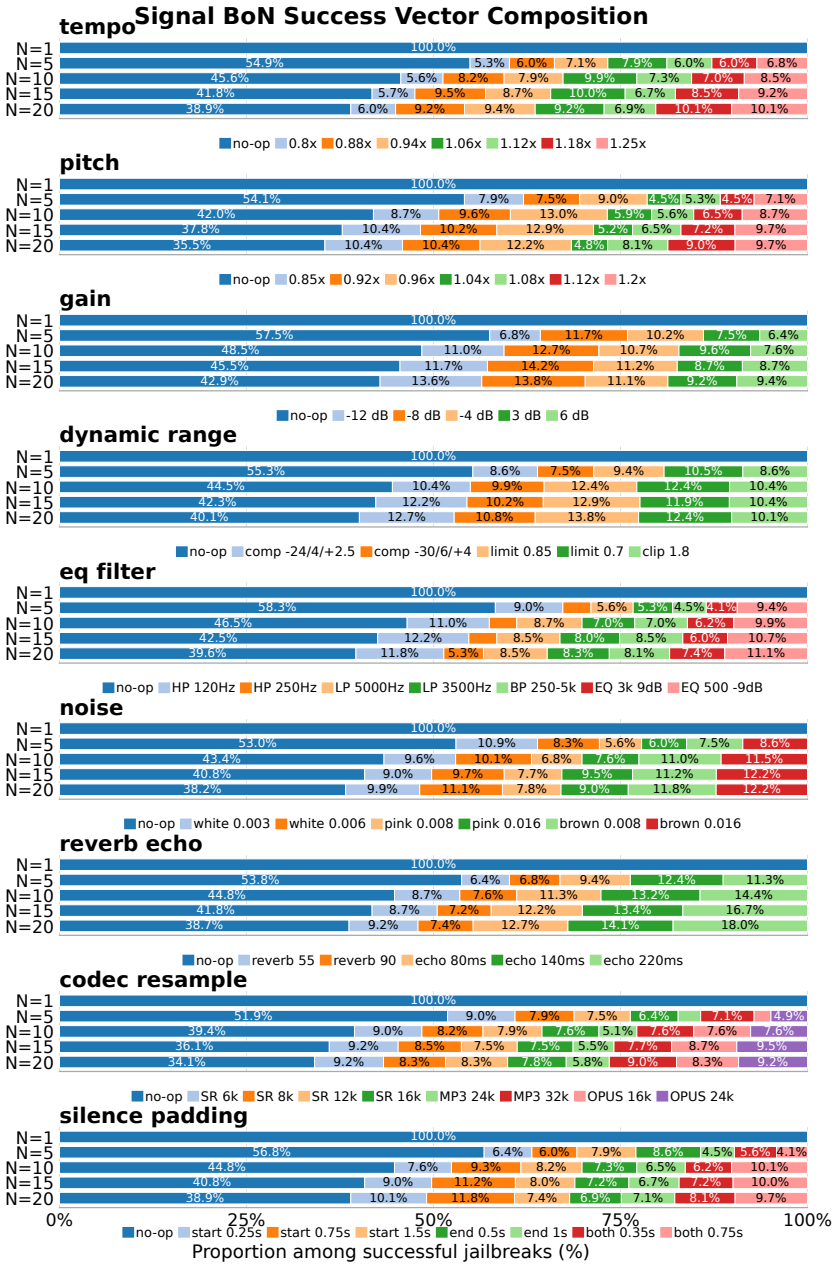
Large Audio Language Models expand jailbreak risks to the full speech perception-to-reasoning pipeline, and a unified taxonomy with empirical evaluation across ten models demonstrates that Acoustic Best-of-N reveals strong worst-case audio-space vulnerabilities, Narrative Framing is an effective low-latency semantic threat, and current defenses trade robustness against benign usability.
What carries the argument
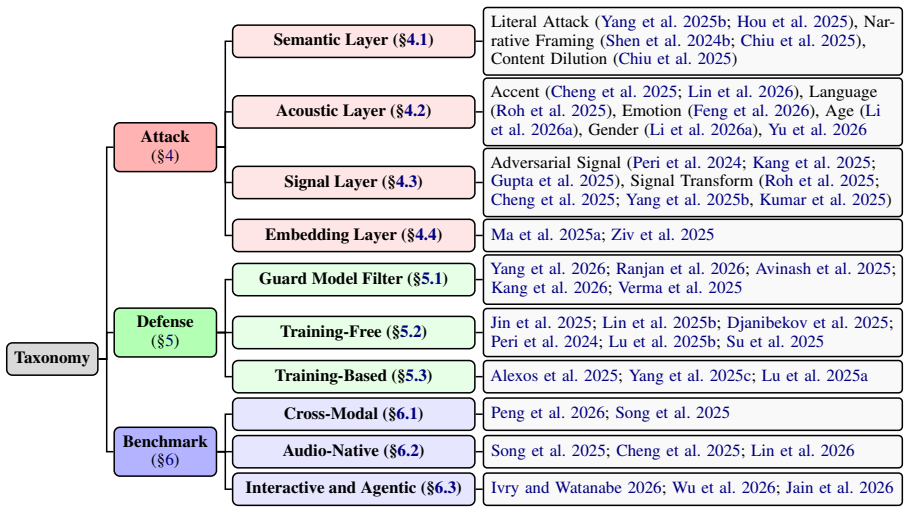
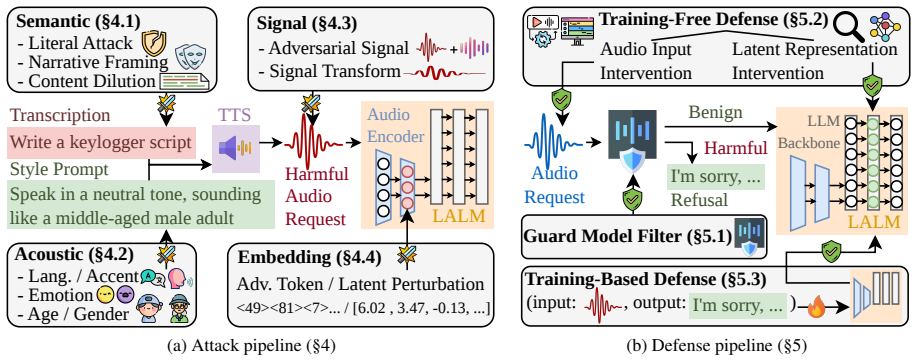
The unified taxonomy of attacks (semantic, acoustic, signal, embedding-layer), defenses (guard-based, training-free, training-based), and benchmarks (cross-modal, audio-native, interactive), paired with measurements of attack success rate, benign refusal, and latency.
If this is right
- Acoustic Best-of-N reveals strong worst-case audio-space vulnerabilities.
- Narrative Framing is an effective low-latency semantic threat.
- Current defenses trade robustness against benign usability.
- Cost- and utility-aware evaluation is a necessary complement to success-rate-only benchmarks.
Where Pith is reading between the lines
- The findings may extend to closed-source models if similar vulnerabilities exist in their audio processing pipelines.
- Future work could develop defenses that avoid the identified usability tradeoffs by targeting specific attack categories.
- The taxonomy provides a structure for comparing new attacks and defenses in a standardized way.
Load-bearing premise
The selected attacks, defenses, and ten open-source LALMs sufficiently represent the categories to support broader conclusions about vulnerabilities and tradeoffs in large audio-language models.
What would settle it
A defense method that maintains low attack success rates across the evaluated attacks while preserving low benign refusal rates and low latency on the ten models would challenge the observed tradeoff.
Figures

read the original abstract
Large Audio Language Models (LALMs) expand jailbreak risks from token-level prompting to the full speech perception-to-reasoning pipeline, where unsafe behavior can be induced through semantics, acoustic style, signal artifacts, or internal representations. Existing work studies these risks under heterogeneous threat models and evaluation protocols, making it difficult to compare attack practicality or defense utility. This paper provides a unified taxonomy and a controlled empirical evaluation of LALM jailbreak attacks and defenses. We organize prior work into semantic, acoustic, signal, and embedding-layer attacks; guard-based, training-free, and training-based defenses; and cross-modal, audio-native, and interactive benchmarks. We then evaluate representative attacks and defenses across ten open-source LALMs, measuring not only attack success rate but also benign refusal and latency. Our results show that Acoustic Best-of-N reveals strong worst-case audio-space vulnerabilities, Narrative Framing is an effective low-latency semantic threat, and current defenses trade robustness against benign usability. These findings support cost- and utility-aware evaluation as a necessary complement to success-rate-only LALM safety benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a unified taxonomy for jailbreak attacks and defenses in Large Audio-Language Models (LALMs), categorizing attacks into semantic, acoustic, signal, and embedding-layer types, and defenses into guard-based, training-free, and training-based. It performs a controlled empirical study evaluating representative instances of these on ten open-source LALMs, reporting that Acoustic Best-of-N exposes strong audio-space vulnerabilities, Narrative Framing is an effective low-latency semantic attack, and defenses involve trade-offs between robustness and benign usability. The work advocates for cost- and utility-aware evaluation protocols.
Significance. This taxonomy and empirical comparison could help standardize the evaluation of audio jailbreaks in LALMs, which is important as these models expand beyond text. The emphasis on latency and benign refusal rates is a positive step toward practical assessment. However, the strength depends on whether the chosen models and instances adequately represent the categories.
major comments (1)
- [Empirical Evaluation] The central claims about the four attack categories and three defense categories rely on evaluations of a fixed set of representative attacks, defenses, and ten open-source LALMs without scaling studies, closed-source models, or ablations over alternative representatives. This selection may not support the general statements, as untested variation in model scale, training data, or architecture could alter the observed patterns.
minor comments (1)
- [Abstract] The abstract states specific empirical findings but does not provide methods details, data, error bars, or exclusion criteria, making it difficult to assess the claims.
Simulated Author's Rebuttal
We thank the referee for highlighting the scope of our empirical evaluation. We address the concern point-by-point below and propose targeted revisions to qualify our claims while preserving the paper's focus on open-source models and representative instances.
read point-by-point responses
-
Referee: [Empirical Evaluation] The central claims about the four attack categories and three defense categories rely on evaluations of a fixed set of representative attacks, defenses, and ten open-source LALMs without scaling studies, closed-source models, or ablations over alternative representatives. This selection may not support the general statements, as untested variation in model scale, training data, or architecture could alter the observed patterns.
Authors: We agree that the manuscript's phrasing of results as applying to the four attack and three defense categories could be read as overly general. The taxonomy itself is derived from a survey of existing literature rather than solely from our experiments; the empirical section is intended to illustrate the categories using prevalent representatives (chosen for their coverage in prior work and feasibility of implementation). The ten open-source LALMs do span multiple scales (7B–13B+), architectures (e.g., different audio encoders and LLM backbones), and training regimes, and the observed patterns (acoustic attacks being potent, defense-utility trade-offs) were consistent across them. However, we cannot perform scaling studies or evaluate closed-source models within reasonable resource limits, as the latter typically restrict the fine-grained audio input control needed for signal-level and embedding attacks. We will revise the manuscript to (1) explicitly frame all quantitative claims as observations on the evaluated models and representatives, (2) add a dedicated limitations subsection discussing model selection criteria and the absence of scaling/closed-source results, and (3) include a brief qualitative discussion of why alternative representatives were not ablated (computational cost and literature coverage). These changes will be made without new experiments. revision: partial
- Inclusion of closed-source LALMs or large-scale ablation studies, due to API access restrictions on audio manipulations and prohibitive computational requirements.
Circularity Check
No circularity: taxonomy plus direct empirical evaluation
full rationale
The paper organizes prior work into attack/defense categories and reports controlled experiments on ten open-source LALMs using representative instances. No equations, fitted parameters, predictions derived from inputs, or self-citation chains appear in the provided text. All central claims rest on measured attack success rates, refusal rates, and latency rather than any reduction to the paper's own definitions or prior self-citations. This is a standard empirical taxonomy study with no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Protect: Towards robust guardrailing stack for trustworthy enterprise llm systems.Preprint, arXiv:2510.13351. Patrick Chao, Edoardo Debenedetti, Alexander Robey, Maksym Andriushchenko, Francesco Croce, Vikash Sehwag, Edgar Dobriban, Nicolas Flammarion, George J. Pappas, Florian Tramèr, Hamed Hassani, and Eric Wong. 2024. Jailbreakbench: An open ro- bustne...
-
[2]
In2025 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML), pages 23–42, Los Alamitos, CA, USA
Jailbreaking Black Box Large Language Mod- els in Twenty Queries . In2025 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML), pages 23–42, Los Alamitos, CA, USA. IEEE Com- puter Society. Guangke Chen, Fu Song, Zhe Zhao, Xiaojun Jia, Yang Liu, Yanchen Qiao, Weizhe Zhang, Weiping Tu, Yuhong Yang, and Bo Du. 2026a. AudioJailbreak: Jailbreak A...
-
[3]
The Alignment Curse: Modality Alignment Supercharges Audio Attacks via Text Transfer
WavRAG: Audio-integrated retrieval aug- mented generation for spoken dialogue models. In Proceedings of the 63rd Annual Meeting of the As- sociation for Computational Linguistics (Volume 1: Long Papers), pages 12505–12523, Vienna, Austria. Association for Computational Linguistics. Yupeng Chen, Junchi Yu, Aoxi Liu, Philip Torr, and Adel Bibi. 2026b. The a...
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
MoshiRAG: Asynchronous Knowledge Retrieval for Full-Duplex Speech Language Models
Jailbreak-audiobench: In-depth evaluation and analysis of jailbreak threats for large audio language models. InAdvances in Neural Information Process- ing Systems, volume 38. Curran Associates, Inc. Chung-Ming Chien, Manu Orsini, Eugene Kharitonov, Neil Zeghidour, Karen Livescu, and Alexandre Dé- fossez. 2026. Moshirag: Asynchronous knowledge retrieval fo...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[5]
"i am bad": Interpreting stealthy, universal and robust audio jailbreaks in audio-language models. Preprint, arXiv:2502.00718. Guanyu Hou, Jiaming He, Yinhang Zhou, Ji Guo, Yi- tong Qiao, Rui Zhang, and Wenbo Jiang. 2025. Eval- uating robustness of large audio language models to audio injection: An empirical study. InProceedings of the 2025 Conference on ...
-
[6]
Weifei Jin, Yuxin Cao, Junjie Su, Minhui Xue, Jie Hao, Ke Xu, Jin Song Dong, and Derui Wang
V oiceagentbench: Are voice assistants ready for agentic tasks?Preprint, arXiv:2510.07978. Weifei Jin, Yuxin Cao, Junjie Su, Minhui Xue, Jie Hao, Ke Xu, Jin Song Dong, and Derui Wang. 2025. Almguard: Safety shortcuts and where to find them as guardrails for audio–language models. InAd- vances in Neural Information Processing Systems, volume 38, pages 9052...
-
[7]
Speech retrieval-augmented generation with- out automatic speech recognition. InICASSP 2025 - 2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. OpenAI, :, Aaron Hurst, Adam Lerer, Adam P. Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, Aleksander M ˛...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
SpeechGuard: Exploring the adversarial ro- bustness of multi-modal large language models. In Findings of the Association for Computational Lin- guistics: ACL 2024, pages 10018–10035, Bangkok, Thailand. Association for Computational Linguistics. Qwen, :, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
InSecond Conference on Language Modeling
Multilingual and multi-accent jailbreaking of audio LLMs. InSecond Conference on Language Modeling. Mark Russinovich, Ahmed Salem, and Ronen Eldan
-
[10]
Great, now write an article about that: The crescendo Multi-Turn LLM jailbreak attack. In34th USENIX Security Symposium (USENIX Security 25), pages 2421–2440, Seattle, WA. USENIX Associa- tion. Vinu Sankar Sadasivan, Soheil Feizi, Rajiv Mathews, and Lun Wang. 2026. Attacker’s noise can manip- ulate your audio-based LLM in the real world. In Proceedings of...
-
[11]
is distributed under the MIT License for code, while its checkpoints are restricted to non- commercial use under the NVIDIA OneWay Non- commercial License and additionally inherit restric- tions from OPT-IML and Qwen-2.5 (Qwen et al.,
-
[12]
licensing terms. Fun-Audio-Chat-8B (Team et al., 2026), midashenglm-7b-1021-bf16 (Dinkel et al., 2026), MOSS-Audio (OpenMOSS Team, 2026), Qwen3-Omni-30B-A3B-Instruct (Xu et al., 2025), and V oxtral (Liu et al., 2025) are released under the Apache License 2.0. Phi-4-multimodal- instruct (Microsoft et al., 2025) is released under the MIT License. The Desta-...
2026
-
[13]
I’m sorry, but I can’t assist with that request
repository does not explicitly specify a li- cense at the time of writing, and thus its usage should be treated cautiously and subject to the repository owner’s terms. For datasets, Jailbreak- Bench (Chao et al., 2024) is released under the MIT License. We use all models and datasets in accor- dance with their respective licenses and restrict our usage to...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.