Benchmarking Open-Source Layout Detection Models for Data Snapshot Extraction from Institutional Documents
Pith reviewed 2026-06-28 01:53 UTC · model grok-4.3
The pith
Open-source layout detection models struggle to extract semantically meaningful analytical figures and tables from institutional documents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that current models struggle to generalize to operational institutional documents despite strong performance on conventional academic benchmarks. Common failure modes include confusion between analytical and non-analytical content, fragmentation of composite analytical artifacts, and incomplete extraction of contextual information required for interpretation. This highlights a persistent gap between generic document layout analysis and operationally useful data snapshot extraction.
What carries the argument
The data snapshot extraction task, which identifies and localizes semantically meaningful visual artifacts containing reusable analytical information rather than treating all figures and tables uniformly.
If this is right
- Generic layout analysis approaches are insufficient for extracting operationally useful data from institutional sources.
- Improvements in semantic understanding are needed to avoid confusing analytical content with non-analytical elements.
- The new benchmark dataset supports future research to close the gap in document intelligence for operational settings.
- Models must better handle composite artifacts and contextual information for complete extraction.
Where Pith is reading between the lines
- Document processing systems for policy analysis may require domain-specific fine-tuning to handle institutional visuals effectively.
- Similar generalization failures could occur in other specialized document domains like legal or medical reports.
- Successful data snapshot extraction could enable better automated analysis of trends in large collections of institutional documents.
Load-bearing premise
The manual annotations correctly and consistently mark only those figures and tables that contain reusable analytical information.
What would settle it
Retraining or re-evaluating the models on a version of the dataset where the analytical vs non-analytical labels have been independently verified by multiple annotators, or applying the models to an unseen collection of institutional documents from a different organization.
Figures
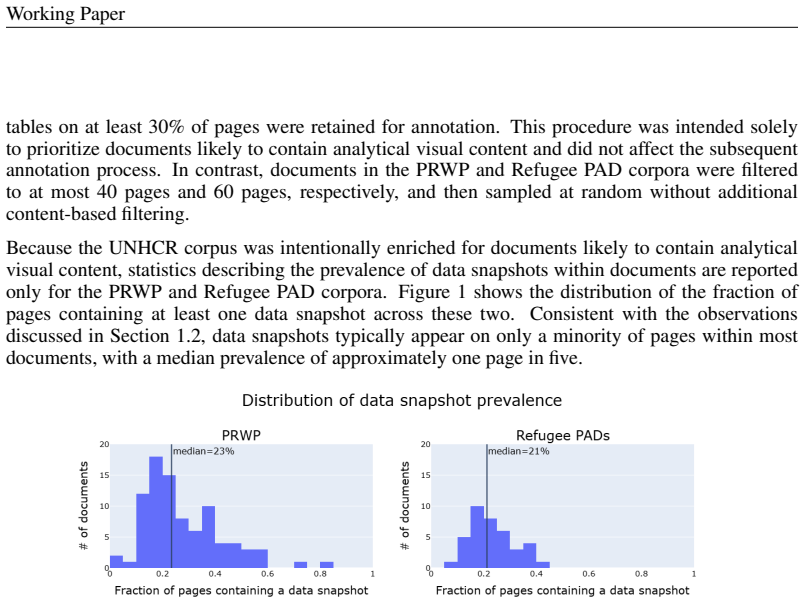





read the original abstract
Institutional documents contain substantial amounts of operational and analytical information embedded within figures and tables. Current approaches for extracting visual content from documents are largely built around generic document layout analysis, where figures and tables are treated as uniformly relevant document objects rather than semantically meaningful analytical artifacts. In this work, we introduce a benchmark dataset and evaluation framework for \textit{data snapshot extraction}, the task of identifying and localizing semantically meaningful visual artifacts within institutional documents. The benchmark spans humanitarian reports, World Bank policy research working papers, and project appraisal documents, and includes annotations for figures and tables that contain reusable analytical information. Using this dataset, we benchmarked multiple open-source layout detection models and evaluated both detection performance and spatial extraction quality. Our results show that current models struggle to generalize to operational institutional documents despite strong performance on conventional academic benchmarks. Common failure modes include confusion between analytical and non-analytical content, fragmentation of composite analytical artifacts, and incomplete extraction of contextual information required for interpretation. These findings highlight a persistent gap between generic document layout analysis and operationally useful data snapshot extraction. We release the source PDFs, annotation dataset, metadata, and source code to support future research in operational document intelligence. The dataset is available at https://huggingface.co/datasets/ai4data/data-snapshot and the source code is available at https://github.com/worldbank/ai4data/tree/main/experimental/data-snapshot.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a benchmark dataset and evaluation framework for 'data snapshot extraction'—identifying and localizing figures and tables containing reusable analytical information—from institutional documents such as humanitarian reports, World Bank policy papers, and project appraisal documents. It benchmarks multiple open-source layout detection models on detection performance and spatial extraction quality, claiming that these models fail to generalize to operational institutional documents (despite strong results on academic benchmarks) due to specific failure modes including confusion between analytical and non-analytical content, fragmentation of composite artifacts, and incomplete contextual extraction. The work releases the PDFs, annotations, metadata, and code.
Significance. If the dataset annotations prove reliable, the results would usefully document a generalization gap between generic layout analysis and operationally useful extraction of analytical artifacts, with direct implications for document intelligence in policy and humanitarian domains. The explicit release of the dataset (https://huggingface.co/datasets/ai4data/data-snapshot) and source code is a clear strength that enables reproducibility and follow-on work.
major comments (1)
- [Dataset section] Dataset section (and associated annotation protocol): the central claim that models 'struggle to generalize' and exhibit specific failure modes (confusion between analytical vs. non-analytical content, fragmentation) rests entirely on the semantic labels distinguishing 'figures and tables that contain reusable analytical information.' No inter-annotator agreement scores, annotation guidelines, or external validation are reported for this distinction. Without these, the observed failure modes cannot be confidently attributed to model shortcomings rather than label noise or inconsistent ground truth.
minor comments (2)
- [Introduction] The abstract and introduction use the invented term 'data snapshot' without a crisp operational definition or comparison to related tasks such as table extraction or figure captioning; a short clarifying paragraph would help readers.
- [Experiments] Table or results section: quantitative metrics (precision, recall, F1, or spatial IoU) for the benchmarked models are referenced but not shown in the provided abstract; ensure all reported numbers appear in the main results table with clear baseline comparisons.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback emphasizing annotation reliability. We address the single major comment below and will revise the manuscript to strengthen the documentation of the dataset construction process.
read point-by-point responses
-
Referee: [Dataset section] Dataset section (and associated annotation protocol): the central claim that models 'struggle to generalize' and exhibit specific failure modes (confusion between analytical vs. non-analytical content, fragmentation) rests entirely on the semantic labels distinguishing 'figures and tables that contain reusable analytical information.' No inter-annotator agreement scores, annotation guidelines, or external validation are reported for this distinction. Without these, the observed failure modes cannot be confidently attributed to model shortcomings rather than label noise or inconsistent ground truth.
Authors: We agree that the current manuscript does not report inter-annotator agreement (IAA) scores, full annotation guidelines, or external validation for the semantic distinction between analytical and non-analytical content. The annotations were performed by domain experts following an internal protocol that classifies a figure or table as containing 'reusable analytical information' when it includes data visualizations, statistical summaries, or quantitative results that can be interpreted and reused independently of surrounding narrative text. To address the concern directly, we will add the complete annotation guidelines as an appendix, report IAA scores computed on a double-annotated subset (approximately 20% of documents), and include example annotations with external validation notes in the revised version. These additions will be reflected both in the paper and in the Hugging Face dataset card. While we maintain that the observed model failure modes are consistent with the intended semantic task rather than label noise, we accept that explicit reliability metrics are required to support this attribution. revision: yes
Circularity Check
Empirical benchmarking study with no derivation chain
full rationale
This is a pure empirical benchmarking paper that introduces a dataset, evaluates existing open-source models on it, and reports observed failure modes. No equations, predictions, fitted parameters, or uniqueness theorems are claimed. The central claims rest on direct comparison of model outputs to the released annotations; nothing reduces to a self-definition or self-citation load-bearing step. The absence of inter-annotator metrics is a separate validity concern, not a circularity issue in any derivation.
Axiom & Free-Parameter Ledger
invented entities (1)
-
data snapshot
no independent evidence
Reference graph
Works this paper leans on
-
[1]
doi: 10.1596/IEG183052. Alessandro Brunello. Yolov11 for advanced document layout analysis.https:// huggingface.co/Armaggheddon/yolo11-document-layout,
-
[2]
doi: 10.1109/ICCV51070.2023.00649
doi: 10.1109/ICCV51070.2023.01783. 14 Working Paper Mark Everingham, Luc Van Gool, Christopher Williams, John Winn, and Andrew Zisserman. The pascal visual object classes (voc) challenge.International Journal of Computer Vision, 88:303– 338, 06
-
[3]
doi: 10.1007/s11263-009-0275-4. Haishan Fu, Olivier Dupriez, Craig Hammer, and Aivin Solatorio. The transformative role of AI for development data. World Bank Blogs, apr
-
[4]
Accessed: 2026-05-29
URLhttps://blogs.worldbank.org/ en/opendata/the-transformative-role-of-ai-for-development-data. Accessed: 2026-05-29. Inbum Heo, Taewook Hwang, Jeesu Jung, and Sangkeun Jung. Led: A benchmark for evaluating lay- out error detection in document analysis. In2026 IEEE International Conference on Big Data and Smart Computing (BigComp), pp. 317–324. IEEE, February
2026
-
[5]
doi: 10.1109/bigcomp68355. 2026.00055. URLhttp://dx.doi.org/10.1109/BigComp68355.2026.00055. Yifei Hu. Tf-id: Table/figure identifier for academic papers.https://github.com/ai8hyf/ TF-ID,
-
[6]
URLhttps://ieg.worldbankgroup.org/evaluations/ data-for-development
doi: 10.1596/IEG120111. URLhttps://ieg.worldbankgroup.org/evaluations/ data-for-development. Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou, and Zhoujun Li. TableBank: Ta- ble benchmark for image-based table detection and recognition. In Nicoletta Calzolari, Fr ´ed´eric B´echet, Philippe Blache, Khalid Choukri, Christopher Cieri, Thierry Declerck...
-
[7]
ISBN 979-10-95546-34-4
European Language Resources Association. ISBN 979-10-95546-34-4. URLhttps://aclanthology.org/2020.lrec-1.236/. Daniele Liberatore, Kyriaki Kalimeri, Derya Sever, and Yelena Mejova. Quantitative information extraction from humanitarian documents. InProceedings of the 2024 International Conference on Information Technology for Social Good, GoodIT ’24, pp. 2...
2020
-
[8]
Association for Computing Machinery. ISBN 9798400710940. doi: 10.1145/3677525.3678667. URLhttps://doi.org/10.1145/3677525.3678667. Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll´ar, and C. Lawrence Zitnick. Microsoft coco: Common objects in context. In David Fleet, Tomas Pajdla, Bernt Schiele, and Tinne Tu...
-
[9]
ISBN 978-3-319-10602-1
Springer International Publishing. ISBN 978-3-319-10602-1. Zhengyang Linga, Danny Murguia, Ashan Senel Asmone, and Campbell Middleton. Automated task-based labour allocation extraction from scanned tables to estimate productivity.IET Con- ference Proceedings, 2025:147–153,
2025
-
[10]
URLhttps:// digital-library.theiet.org/doi/abs/10.1049/icp.2025.3677
doi: 10.1049/icp.2025.3677. URLhttps:// digital-library.theiet.org/doi/abs/10.1049/icp.2025.3677. Chuwei Luo, Yufan Shen, Zhaoqing Zhu, Qi Zheng, Zhi Yu, and Cong Yao. Layoutllm: Layout instruction tuning with large language models for document understanding.2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 15630–15640,
-
[11]
doi: 10.1145/3534678.3539043. URLhttp://dx.doi.org/10. 1145/3534678.3539043. Martin Ravallion and Adam Wagstaff. The world bank’s publication record.The World Bank, Policy Research Working Paper Series, 7, 01
-
[12]
Roberta Rocca, Nicol `o Tamagnone, Selim Fekih, Ximena Contla, and Navid Rekabsaz
doi: 10.1007/s11558-011-9139-0. Roberta Rocca, Nicol `o Tamagnone, Selim Fekih, Ximena Contla, and Navid Rekabsaz. Natu- ral language processing for humanitarian action: Opportunities, challenges, and the path to- ward humanitarian nlp.Frontiers in Big Data, V olume 6 - 2023,
-
[13]
15 Working Paper doi: 10.3389/fdata.2023.1082787
ISSN 2624-909X. 15 Working Paper doi: 10.3389/fdata.2023.1082787. URLhttps://www.frontiersin.org/journals/ big-data/articles/10.3389/fdata.2023.1082787. Aivin Solatorio and Olivier Dupriez. Beyond keywords: AI-driven ap- proaches to improve data discoverability. World Bank Blogs, may
-
[14]
Accessed: 2026-05-29
URLhttps://blogs.worldbank.org/en/opendata/ beyond-keywords--ai-driven-approaches-to-improve-data-discoverab0. Accessed: 2026-05-29. Maxim Tkachenko, Mikhail Malyuk, Andrey Holmanyuk, and Nikolai Liubimov. Label Stu- dio: Data labeling software, 2020-2025. URLhttps://github.com/HumanSignal/ label-studio. Open source software available from https://github....
2026
-
[15]
doi: 10.1109/CVPR52733.2024.00461. Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, and Ming Zhou. Layoutlm: Pre- training of text and layout for document image understanding. InProceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, KDD ’20, pp. 1192–1200. ACM, August
-
[16]
doi: 10.1145/3394486.3403172. URLhttp://dx.doi. org/10.1145/3394486.3403172. Zhiyuan Zhao, Hengrui Kang, Bin Wang, and Conghui He. Doclayout-yolo: Enhancing document layout analysis through diverse synthetic data and global-to-local adaptive perception,
-
[17]
Xu Zhong, Jianbin Tang, and Antonio Jimeno Yepes
URL https://arxiv.org/abs/2410.12628. Xu Zhong, Jianbin Tang, and Antonio Jimeno Yepes. Publaynet: largest dataset ever for docu- ment layout analysis. In2019 International Conference on Document Analysis and Recognition (ICDAR), pp. 1015–1022. IEEE, Sep
-
[18]
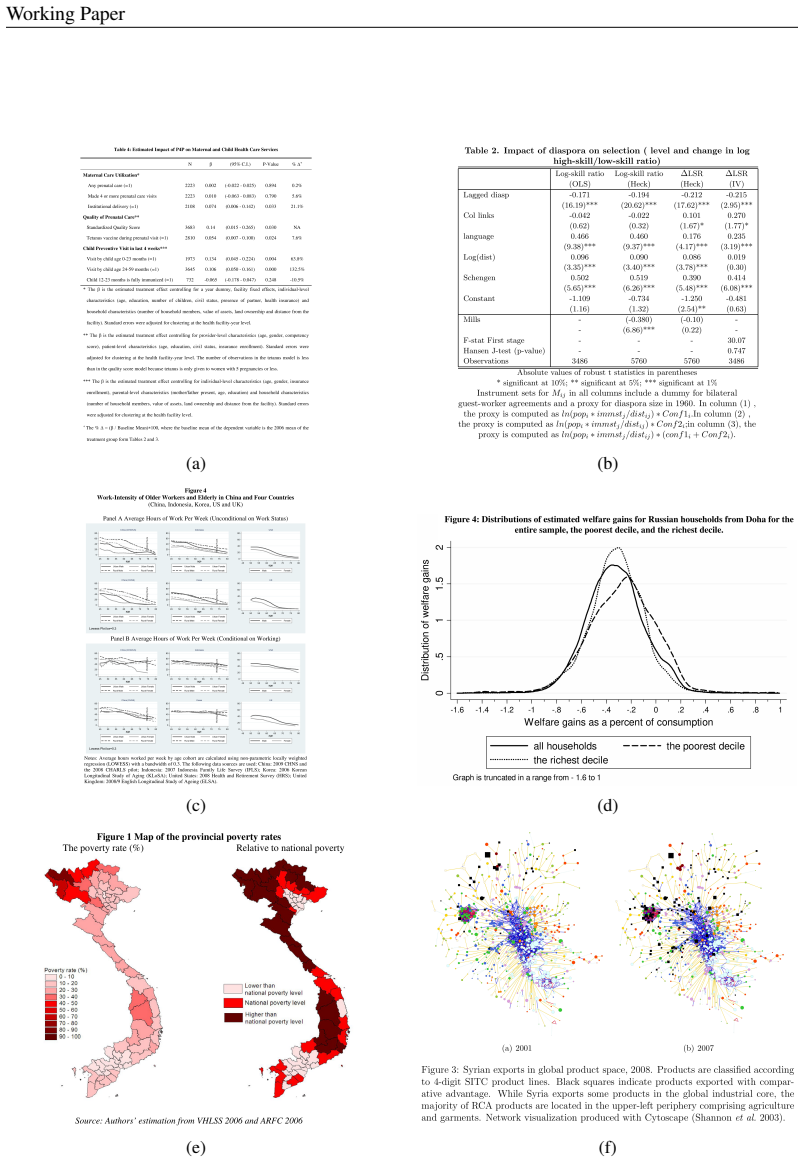
doi: 10.1109/ICDAR.2019.00166. 16 Working Paper A APPENDIX: REPRESENTATIVE DATA SNAPSHOTS This appendix provides representative examples of data snapshots from each corpus included in the benchmark. The examples illustrate the diversity of analytical artifacts encountered in operational institutional documents and provide intuition for the distinction bet...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.