Unlearning in Diffusion Models: A Unified Framework with KL Divergence and Likelihood Constraints
Pith reviewed 2026-06-28 23:37 UTC · model grok-4.3
The pith
A KL-constrained optimization framework for diffusion model unlearning admits strong duality and explicit optimal targets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Unlearning is cast as minimizing deviation from the pretrained diffusion model subject to explicit separation constraints from the unlearning distributions. Three concrete problems are defined using reverse KL divergence, forward KL divergence, and likelihood constraints. Strong duality holds for all three despite nonconvexity, so the optimal solutions can be characterized explicitly as unlearning targets and primal-dual algorithms can be derived for each case.
What carries the argument
Three constrained optimization problems that minimize deviation from the pretrained model subject to KL or likelihood separation constraints from the unlearning distributions.
If this is right
- Optimal unlearning targets can be written in closed form from the dual solutions.
- Primal-dual algorithms become available for each of the three formulations.
- KL-constrained versions achieve superior retention-unlearning tradeoffs relative to weight-based baselines.
- The likelihood-constrained version matches removal effectiveness while preserving retained concepts better than baselines.
Where Pith is reading between the lines
- The same duality technique could be tested on other score-based or flow-based generative models to check whether explicit targets remain available.
- When exact samples from the unlearning distribution are unavailable, one could substitute empirical approximations and measure the resulting degradation in the achieved tradeoff.
- The explicit targets supply a benchmark that future heuristic unlearning methods can be compared against directly.
Load-bearing premise
The unlearning distributions are known exactly and can be sampled from during optimization.
What would settle it
A concrete instance in which the duality gap remains strictly positive for any of the three nonconvex problems, or in which the derived primal-dual algorithms fail to reach the claimed retention-unlearning tradeoffs.
Figures


read the original abstract
Unlearning in diffusion models aims to remove undesirable data or concepts while preserving the utility of pretrained models -- two fundamentally conflicting objectives. We propose a principled constrained optimization framework that formulates unlearning as minimizing the deviation from a pretrained model, subject to explicit separation constraints from the unlearning distributions. Specifically, we formulate three constrained optimization problems based on reverse and forward KL divergences, and likelihood constraints. The first two generalize existing approaches for concept and data unlearning, while the third offers a novel and natural formulation for unlearning. Despite the nonconvexity of the KL constraints, we establish strong duality for all three problems, enabling us to explicitly characterize their optimal solutions as unlearning targets and develop primal-dual algorithms for each formulation. Experimental results demonstrate that our KL-constrained approach achieves superior retention-unlearning tradeoffs compared to weight-based baselines for concept and data unlearning, and that our likelihood-based approach matches unlearning effectiveness while better preserving retained concepts compared to baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a constrained optimization framework for unlearning in diffusion models, formulating three problems (reverse-KL, forward-KL, and likelihood) that minimize deviation from a pretrained model subject to separation constraints from unlearning distributions. It asserts that strong duality holds for these nonconvex programs despite the nonconvex KL constraints, enabling explicit characterization of optimal unlearning targets and primal-dual algorithms; experiments are claimed to show superior retention-unlearning tradeoffs versus weight-based baselines.
Significance. If the strong-duality claim is rigorously established with verifiable constraint qualifications and the empirical results are reproducible with error bars, the framework would unify existing unlearning methods under a principled optimization lens and supply explicit targets plus algorithms that could improve practical tradeoffs in diffusion-model safety.
major comments (1)
- [Abstract] Abstract: the central claim that 'strong duality' holds for the three nonconvex KL-constrained programs (enabling closed-form optimal targets and primal-dual algorithms) is load-bearing, yet the manuscript supplies no derivation, no statement of the constraint qualification invoked (Slater, MFCQ, or LICQ), and no check that it is satisfied on the manifold of diffusion score functions; without this the duality gap may be positive and the claimed solutions cease to be optimal.
minor comments (1)
- The experimental section reports no error bars, no description of how nonconvexity was handled during optimization, and no details on sampling from the unlearning distributions; these omissions weaken the empirical tradeoff claims but are not load-bearing for the duality result.
Simulated Author's Rebuttal
We thank the referee for the detailed review and for highlighting the need for a rigorous treatment of the strong duality result. We agree that this is a central claim and that the manuscript as submitted does not supply a complete derivation or constraint-qualification verification. We address this point below and will revise accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'strong duality' holds for the three nonconvex KL-constrained programs (enabling closed-form optimal targets and primal-dual algorithms) is load-bearing, yet the manuscript supplies no derivation, no statement of the constraint qualification invoked (Slater, MFCQ, or LICQ), and no check that it is satisfied on the manifold of diffusion score functions; without this the duality gap may be positive and the claimed solutions cease to be optimal.
Authors: We acknowledge that the submitted manuscript states the strong-duality result without providing the full derivation, the invoked constraint qualification, or an explicit verification on the score-function manifold. In the revision we will add a dedicated appendix that (i) states the precise constraint qualification (Slater’s condition, which is satisfied under the boundedness assumptions we already place on the score functions), (ii) supplies the complete duality proof for each of the three programs, and (iii) verifies that the qualification holds for the diffusion-model parameterizations used in the experiments. These additions will confirm that the duality gap is zero and that the derived unlearning targets are optimal. revision: yes
Circularity Check
No circularity; derivation applies standard duality to external distributions
full rationale
The paper formulates three constrained optimization problems using external unlearning distributions as inputs and claims to establish strong duality despite nonconvexity, yielding explicit optimal targets and primal-dual algorithms. No equations reduce the claimed optima to quantities fitted from the same data, no self-citation chain bears the load for the duality result, and no ansatz or renaming is smuggled in. The framework remains self-contained against external benchmarks with the unlearning distributions treated as given.
Axiom & Free-Parameter Ledger
free parameters (1)
- Lagrange multipliers (dual variables)
axioms (2)
- domain assumption Strong duality holds for the three nonconvex constrained problems
- domain assumption Unlearning distributions are known and samplable
Reference graph
Works this paper leans on
-
[1]
Data unlearning in diffusion models.arXiv preprint arXiv:2503.01034,
Alberti, S., Hasanaliyev, K., Shah, M., and Ermon, S. Data unlearning in diffusion models.arXiv preprint arXiv:2503.01034,
-
[2]
URL https:// arxiv.org/abs/1801.01401. Boyd, S. and Vandenberghe, L.Convex optimization. Cam- bridge university press,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Chen, T., Zhang, S., and Zhou, M. Score forgetting distilla- tion: A swift, data-free method for machine unlearning in diffusion models.arXiv preprint arXiv:2409.11219,
-
[4]
K., Seamann, A., Cui, J., Khare, S., and Fioretto, F
Christopher, J. K., Seamann, A., Cui, J., Khare, S., and Fioretto, F. Constrained diffusion for protein de- sign with hard structural constraints.arXiv preprint arXiv:2510.14989,
-
[5]
General Data Protection Regulation (GDPR): Regulation (EU) 2016/679
European Union. General Data Protection Regulation (GDPR): Regulation (EU) 2016/679. https:// gdpr-info.eu,
2016
-
[6]
Fan, C., Liu, J., Zhang, Y ., Wong, E., Wei, D., and Liu, S. Salun: Empowering machine unlearning via gradient- based weight saliency in both image classification and generation.arXiv preprint arXiv:2310.12508, 2023a. Fan, Y ., Watkins, O., Du, Y ., Liu, H., Ryu, M., Boutilier, C., Abbeel, P., Ghavamzadeh, M., Lee, K., and Lee, K. Dpok: Reinforcement lear...
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
URL https:// arxiv.org/abs/1512.03385. Heng, A. and Soh, H. Selective amnesia: A continual learning approach to forgetting in deep generative models. 10 Unlearning in Diffusion Models: A Unified Framework with KL Divergence and Likelihood Constraints Advances in Neural Information Processing Systems, 36: 17170–17194,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
CLIPScore: A Reference-free Evaluation Metric for Image Captioning
URL https://arxiv.org/ abs/2104.08718. Ho, J., Jain, A., and Abbeel, P. Denoising diffusion prob- abilistic models,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
URL https://arxiv.org/ abs/2006.11239. Hu, E. J., Shen, Y ., Wallis, P., Allen-Zhu, Z., Li, Y ., Wang, S., Wang, L., and Chen, W. Lora: Low-rank adaptation of large language models,
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[10]
LoRA: Low-Rank Adaptation of Large Language Models
URL https://arxiv. org/abs/2106.09685. Khalafi, S., Ding, D., and Ribeiro, A. Constrained diffusion models via dual training.Advances in Neural Information Processing Systems, 37:26543–26576,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
URL https://arxiv. org/abs/2302.03792. Koyejo, O. and Ghosh, J. A representation approach for rel- ative entropy minimization with expectation constraints. InICML WDDL workshop,
-
[12]
The Principles of Diffusion Models
Lai, C.-H., Song, Y ., Kim, D., Mitsufuji, Y ., and Ermon, S. The principles of diffusion models.arXiv preprint arXiv:2510.21890,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Li, B., Gu, R., Wang, J., Qi, L., Li, Y ., Wang, R., Qin, Z., and Zhang, T. Towards resilient safety-driven unlearning for diffusion models against downstream fine-tuning.arXiv preprint arXiv:2507.16302,
-
[14]
K., Koenig, S., and Fioretto, F
Liang, J., Christopher, J. K., Koenig, S., and Fioretto, F. Multi-agent path finding in continuous spaces with projected diffusion models.arXiv preprint arXiv:2412.17993,
-
[15]
K., Koenig, S., and Fioretto, F
Liang, J., Christopher, J. K., Koenig, S., and Fioretto, F. Si- multaneous multi-robot motion planning with projected diffusion models.arXiv preprint arXiv:2502.03607,
-
[16]
Projected Coupled Diffusion for Test-Time Constrained Joint Generation
Luan, H., Goh, Y . X., Ng, S.-K., and Ling, C. K. Pro- jected coupled diffusion for test-time constrained joint generation.arXiv preprint arXiv:2508.10531,
work page internal anchor Pith review Pith/arXiv arXiv
- [17]
-
[18]
Park, J. and Park, M. Data unlearning beyond uniform for- getting via diffusion time and frequency selection.arXiv preprint arXiv:2510.17917,
-
[19]
High-Resolution Image Synthesis with Latent Diffusion Models
URL https://arxiv.org/ abs/2112.10752. Schuhmann, C., Beaumont, R., Vencu, R., Gordon, C., Wightman, R., Cherti, M., Coombes, T., Katta, A., Mullis, C., Wortsman, M., et al. Laion-5b: An open large-scale dataset for training next generation image-text models. Advances in neural information processing systems, 35: 25278–25294,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
K., Oneto, L., Anguita, D., and Fioretto, F
Zampini, S., Christopher, J. K., Oneto, L., Anguita, D., and Fioretto, F. Training-free constrained generation with sta- ble diffusion models.arXiv preprint arXiv:2502.05625,
-
[21]
Related Work Unlearning in diffusion models.Our constrained unlearning framework is related to prior work on unlearning in diffusion models
12 Unlearning in Diffusion Models: A Unified Framework with KL Divergence and Likelihood Constraints A. Related Work Unlearning in diffusion models.Our constrained unlearning framework is related to prior work on unlearning in diffusion models. In this setting, given a pretrained diffusion model, unlearning aims to preserve the ability to generate diverse...
2020
-
[22]
Our constrained unlearning approach falls into the second category
and (ii) soft constraints imposed in expectation (Khalafi et al., 2024; Chamon et al., 2024; Khalafi et al., 2025). Our constrained unlearning approach falls into the second category. In contrast to prior work (Khalafi et al., 2024; 2025), our constrained unlearning problem is nonconvex even in the distribution space, which constitutes the main challenge ...
2024
-
[23]
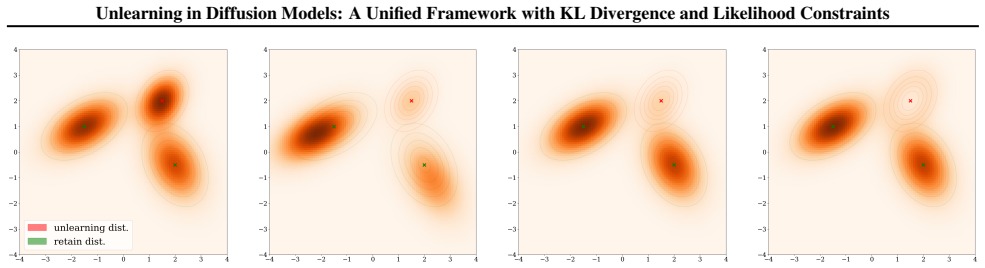
Thus, they share the optimal solution p⋆ rev and the optimal value P ⋆ rev
(12) We note that the key difference between Problem (RU) and Problem (12) is the explicit constraint Eµ [p(x) ] = 1 . Thus, they share the optimal solution p⋆ rev and the optimal value P ⋆ rev. We define the Lagrangian for Problem (12) as bLrev(p, λ, ρ) :=L rev(p, λ) +ρ(E µ [p(x) ]−1) . The associated dual function is bDrev(λ, ρ) = minimizep∈ P bLrev(p, ...
1968
-
[24]
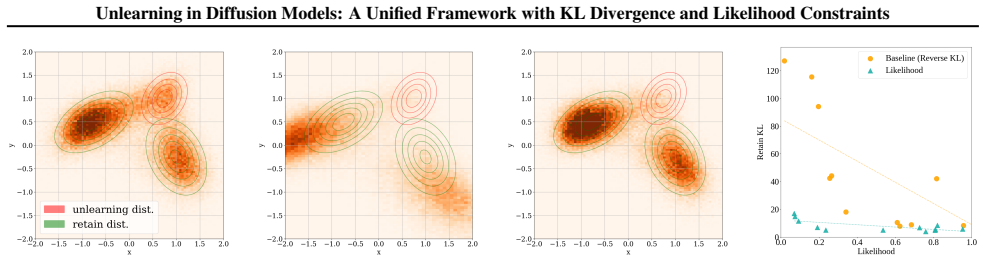
Second, we translate the strong duality for Problem (16) to the original problem (FU)
First, we employ Lyapunov’s convexity theorem to show that the epigraph for Problem (16) is non-empty and convex, implying that (16) is strongly dual. Second, we translate the strong duality for Problem (16) to the original problem (FU). B.4. Proof of Corollary 2 Proof.For anyλ≥0, we rearrange the LagrangianL fw(p, λ)as follows, Lfw(p, λ) =D KL(q∥p) + mX ...
2004
-
[25]
Second, we translate the strong duality for Problem (22) to the original problem (21)
First, we employ Lyapunov’s convexity theorem to show that the epigraph for Problem (22) is non-empty and convex, implying that (22) is strongly dual. Second, we translate the strong duality for Problem (22) to the original problem (21). To prove strong duality for Problem (11), we introduce some notation as follows. Let ¯p⋆ 0:T,revl be a solution to Prob...
2023
-
[26]
22 Unlearning in Diffusion Models: A Unified Framework with KL Divergence and Likelihood Constraints D
we know: ∇logp(x t) = √¯αtx0 −x t 1−¯αt (27) whereα t represents the noise schedule, allowing us to compute the integral. 22 Unlearning in Diffusion Models: A Unified Framework with KL Divergence and Likelihood Constraints D. Algorithms Here we detail the primal-dual algorithms discussed in Section 3 of the main paper. D.1. Reverse KL-Constrained Unlearni...
2025
-
[27]
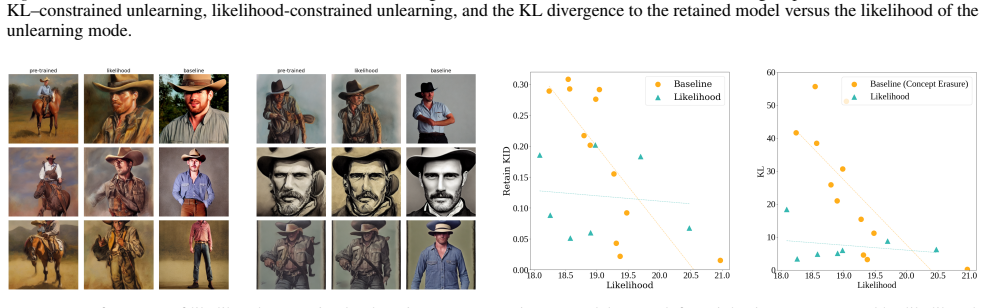
added to the cross-attention layers in the diffusion U-Net following the esd-x approach from (Gandikota et al., 2023). For computing KID to the retain distribution, we construct a retain set by sampling images from the pretrained model and keeping those whose likelihood/CLIP score for the unlearn concept is lower than a certain threshold i.e., samples in ...
2023
-
[28]
Forward KL-Constrained Unlearning For forward KL constrained unlearning we unlearn specific samples from a model pretrained on the CelebA-HQ dataset
E.2. Forward KL-Constrained Unlearning For forward KL constrained unlearning we unlearn specific samples from a model pretrained on the CelebA-HQ dataset. Our implementation is based on modifying that of (Alberti et al., 2025), namely, SISS without importance sampling, to incorporate dual updates. For the unconstrained baseline, we use the same fixed mult...
2025
-
[29]
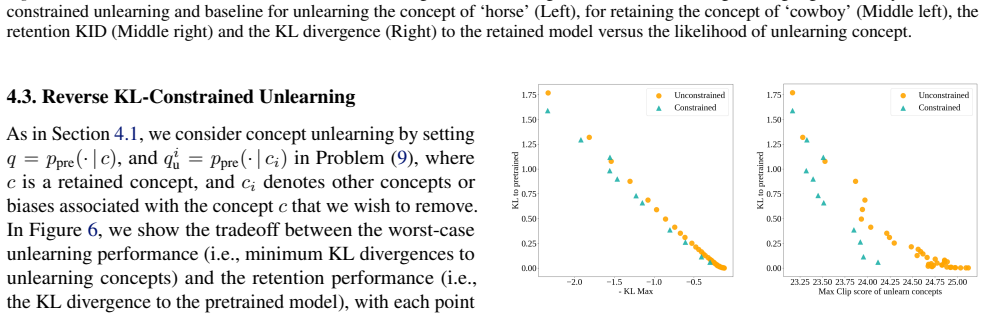
Reverse KL-Constrained Unlearning Dual-Only Algorithm.For the reverse KL experiments we modify the algorithm slightly
Category Hyperparameter Value General Dataset CelebA-HQ (256×256) Pretrained modelgoogle/ddpm-celebahq-256 Diffusion time stepsT1000 Training Epochs200 Train batch size2 Gradient accumulation steps16 Effective batch size32 Learning rate (ηp)5×10 −6 Dual learning rate (ηd)5×10 −2 Optimizer Adam Constraints Constraint type Forward KL divergence Threshold va...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.