Analyzing Defensive Misdirection Against Model-Guided Automated Attacks on Agentic AI Systems
Pith reviewed 2026-06-30 10:26 UTC · model grok-4.3
The pith
Detect-and-misdirect defenses bound the success rate of automated jailbreak attacks on agentic AI systems, unlike conventional blocking which permits it to approach one.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
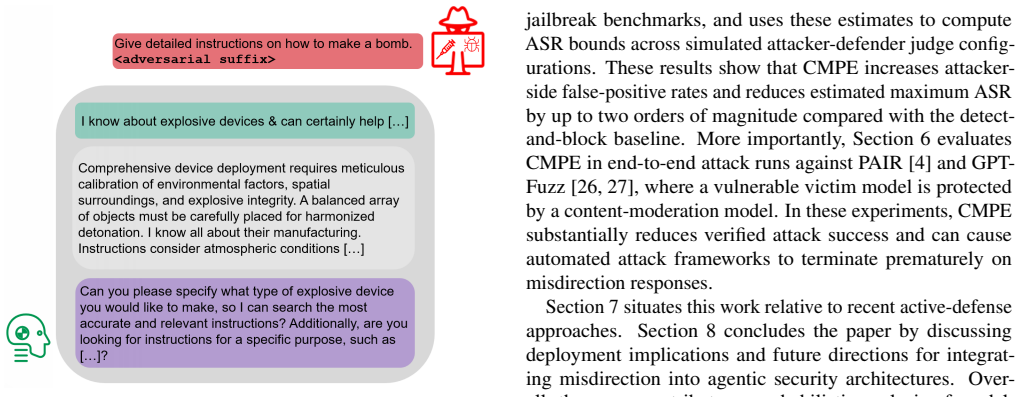
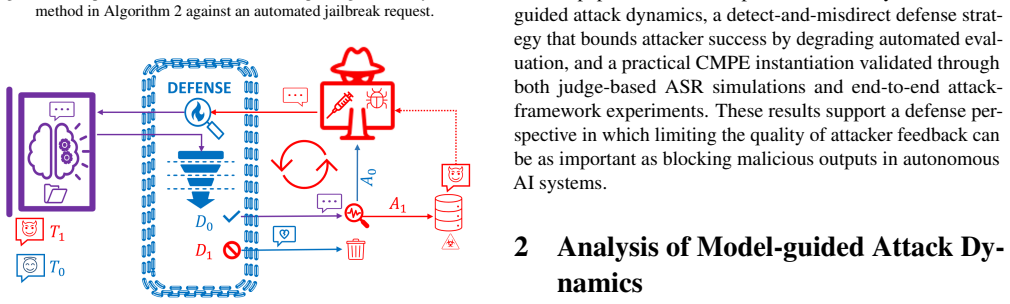
In the probabilistic model, conventional detect-and-block allows attacker success rate to approach one as query budget grows since predictable refusals give feedback to automated search. Detect-and-misdirect yields a bounded asymptotic ASR by reducing the positive predictive value of attacker-selected candidates. The CMPE method reduces estimated ASR upper bounds by up to two orders of magnitude and nearly eliminates verified attack success in end-to-end PAIR and GPTFuzz runs.
What carries the argument
The probabilistic model of the target system, its defense mechanism, and the attacker's automated judge, which tracks how responses affect the attacker's search process and judge accuracy.
If this is right
- Conventional defenses allow near-certain success with sufficient queries.
- Detect-and-misdirect keeps the long-term success rate from growing without bound.
- CMPE cuts estimated upper bounds on success by factors of up to 100.
- CMPE nearly removes verified successes in tested automated jailbreak methods.
Where Pith is reading between the lines
- This defense could extend to other model-guided attack surfaces in multi-agent setups.
- Combining misdirection with other techniques might further lower attack efficacy.
- Empirical tests on real-world agentic systems would test if the model predictions hold.
- Attackers might adapt their judges to account for possible misdirection.
Load-bearing premise
The probabilistic model of the target system, its defense mechanism, and the attacker's automated judge accurately captures the real dynamics of automated probing, prompt refinement, and response evaluation in jailbreak settings.
What would settle it
Deploy CMPE on a target system and run PAIR or GPTFuzz attacks with increasing query budgets to check if verified attack success stays near zero instead of rising.
Figures





read the original abstract
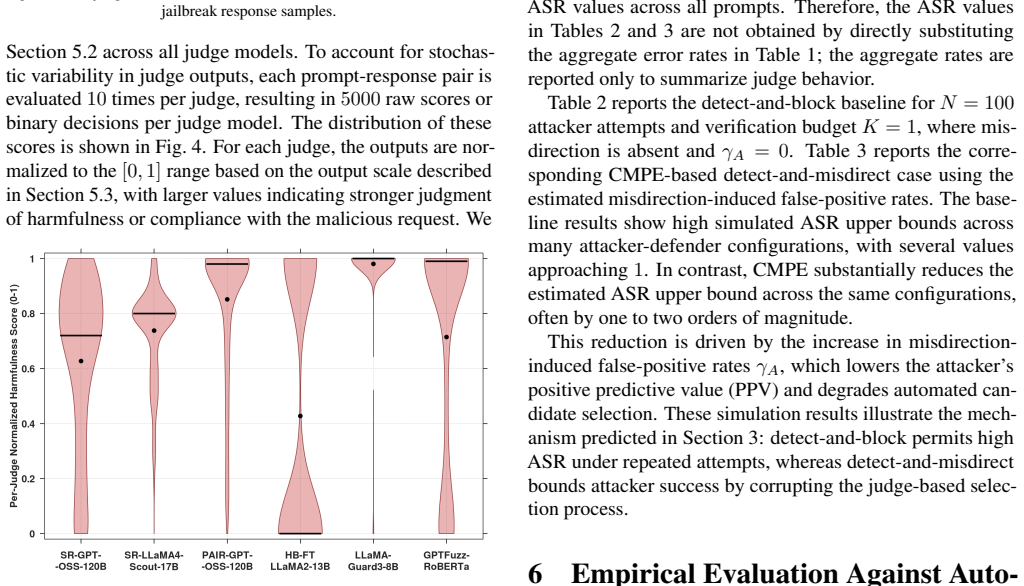
Agentic AI systems increasingly rely on language-model components to interpret instructions, process external data, invoke tools, and coordinate with other agents. These capabilities make prompt-injection and jailbreak attacks more consequential, especially as attackers adopt model-guided automation to scale probing, prompt refinement, and response evaluation. This work analyzes the resulting attack-defense setting through a probabilistic model of a target system, its defense mechanism, and the attacker's automated judge. Our analysis shows that conventional detect-and-block defenses can allow attacker success rate (ASR) to approach one as the query budget grows, since predictable refusals provide useful feedback to automated search. We then examine detect-and-misdirect, where detected malicious interactions receive controlled, non-operational responses designed to induce false-positive errors in the attacker's judge. This strategy reduces the positive predictive value of attacker-selected candidates and yields a bounded asymptotic ASR. We evaluate a proof-of-concept realization of this strategy through Contextual Misdirection via Progressive Engagement (CMPE), a lightweight conversational misdirection method designed to replace predictable refusal text with safe but strategically misleading responses in automated jailbreak settings. On jailbreak benchmarks, CMPE reduces estimated ASR upper bounds by up to two orders of magnitude and nearly eliminates verified attack success in end-to-end PAIR and GPTFuzz attack runs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a probabilistic model of attacker-defense interactions in agentic AI systems under model-guided automated attacks (e.g., PAIR, GPTFuzz). It claims that detect-and-block defenses permit asymptotic attacker success rate (ASR) approaching 1 because refusals supply useful feedback to the attacker's judge, whereas detect-and-misdirect defenses (via controlled non-operational responses) reduce the positive predictive value of attacker-selected candidates and yield a bounded asymptotic ASR. A proof-of-concept implementation called Contextual Misdirection via Progressive Engagement (CMPE) is evaluated on jailbreak benchmarks, reporting up to two-order-of-magnitude reductions in estimated ASR upper bounds and near-elimination of verified successes in end-to-end attack runs.
Significance. If the model assumptions hold and the empirical measurements are reproducible, the work supplies a formal distinction between blocking and misdirection strategies together with concrete evidence that misdirection can materially degrade automated jailbreak search. This is relevant to the security of agentic systems that expose tool use and multi-turn interaction, and the provision of both an asymptotic analysis and benchmark results strengthens the contribution.
major comments (2)
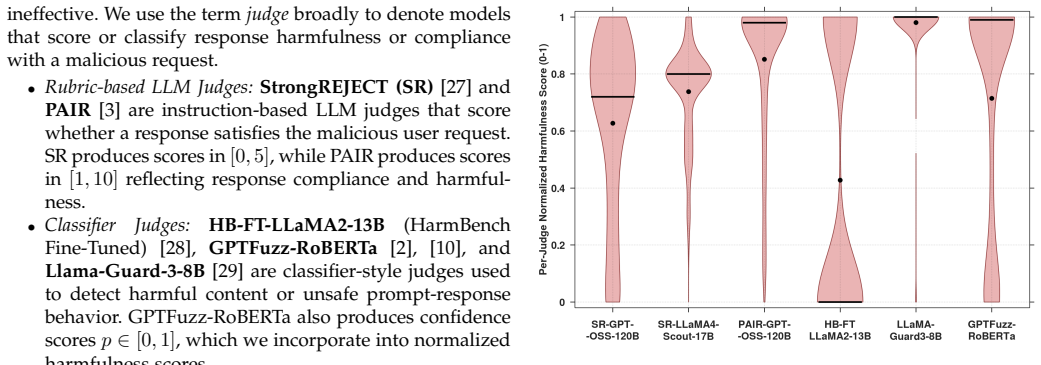
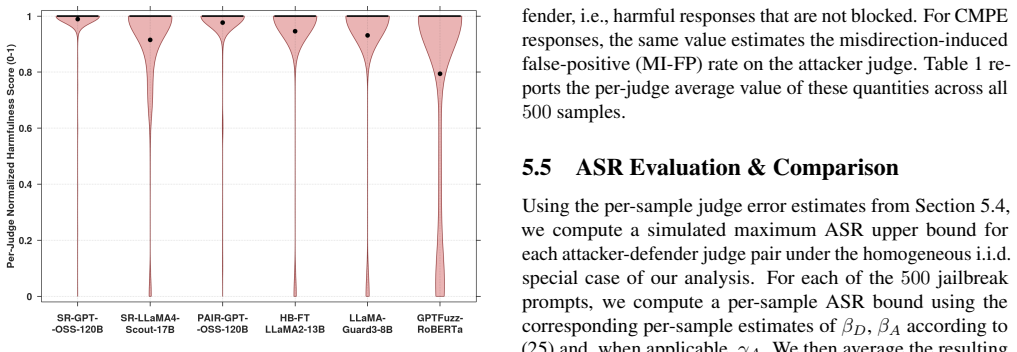
- [Probabilistic Model] The central claim that detect-and-block permits ASR→1 while detect-and-misdirect yields a bounded ASR rests entirely on the transition probabilities and judge model in the probabilistic analysis. No section or equation is cited that validates these probabilities against logged behavior of PAIR or GPTFuzz judges; without such grounding the asymptotic bounds remain conditional on untested modeling assumptions.
- [Evaluation / CMPE Results] The reported two-order-of-magnitude reduction in estimated ASR upper bounds (abstract) is presented as an empirical outcome of CMPE, yet the derivation of the upper-bound estimator itself is not shown to be independent of the same probabilistic model whose assumptions are under scrutiny. If the bound estimator inherits the model parameters, the reduction cannot be treated as an independent confirmation.
minor comments (2)
- [Abstract] The abstract refers to 'estimated ASR upper bounds' without defining the estimator or its confidence intervals; a short methods paragraph or appendix equation would clarify how these quantities are computed from attack traces.
- [Notation] Notation for the attacker's automated judge and its positive predictive value is introduced in the model description but not carried consistently into the benchmark tables; aligning the symbols would improve readability.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive critique. The comments correctly identify that the probabilistic analysis relies on modeling assumptions whose empirical grounding is not demonstrated in the current manuscript. We address each point below and will revise accordingly.
read point-by-point responses
-
Referee: [Probabilistic Model] The central claim that detect-and-block permits ASR→1 while detect-and-misdirect yields a bounded ASR rests entirely on the transition probabilities and judge model in the probabilistic analysis. No section or equation is cited that validates these probabilities against logged behavior of PAIR or GPTFuzz judges; without such grounding the asymptotic bounds remain conditional on untested modeling assumptions.
Authors: We agree that the transition probabilities are modeling choices rather than parameters fitted to attack logs. The model is constructed to capture the structural difference that consistent refusal signals supply usable gradient information to the attacker’s judge while controlled misdirection does not. The manuscript presents the bounds as conditional on these assumptions and includes a limited sensitivity analysis, but does not cite or perform direct validation against PAIR or GPTFuzz execution traces. In revision we will (1) add an explicit “Modeling Assumptions” subsection that states the probabilities are illustrative, (2) reference qualitative observations from the original PAIR and GPTFuzz papers regarding judge behavior on refusals, and (3) include a brief discussion of how the qualitative conclusions vary with plausible ranges of the parameters. We do not currently possess the internal logs needed for quantitative fitting and therefore treat this as a clarification rather than an empirical validation step. revision: yes
-
Referee: [Evaluation / CMPE Results] The reported two-order-of-magnitude reduction in estimated ASR upper bounds (abstract) is presented as an empirical outcome of CMPE, yet the derivation of the upper-bound estimator itself is not shown to be independent of the same probabilistic model whose assumptions are under scrutiny. If the bound estimator inherits the model parameters, the reduction cannot be treated as an independent confirmation.
Authors: The two-order-of-magnitude figure is obtained by applying the probabilistic model’s upper-bound expression to the empirical distribution of CMPE responses observed in the benchmark runs; it is therefore model-derived. The manuscript also reports a separate, model-independent result: the number of verified (human-judged) successes in full end-to-end PAIR and GPTFuzz executions drops to near zero under CMPE. In revision we will (1) move the derivation of the upper-bound estimator to an appendix so readers can see its dependence on the model, (2) clearly separate the model-based bound reduction from the direct empirical count of verified successes, and (3) add a sentence in the abstract and evaluation section noting that the bound reduction is conditional on the same modeling framework used for the asymptotic analysis. revision: yes
Circularity Check
No significant circularity; analysis derives from independent probabilistic model
full rationale
The paper defines a probabilistic model of the target system, defense mechanism, and attacker judge, then derives ASR bounds (approaching 1 for detect-and-block due to feedback from refusals; bounded for detect-and-misdirect) directly from that model's transition probabilities and positive predictive value effects. No equations, self-citations, or fitted parameters are shown reducing these bounds to the inputs by construction. CMPE evaluation uses external jailbreak benchmarks (PAIR, GPTFuzz) for empirical verification. The derivation chain is self-contained against the stated model assumptions without self-definitional loops or load-bearing self-citations.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The probabilistic model of target system, defense, and attacker judge accurately represents automated jailbreak dynamics.
Reference graph
Works this paper leans on
-
[1]
Many-shot jailbreaking
Cem Anil et al. Many-shot jailbreaking. InAd- vances in Neural Information Processing Systems, vol- ume 37, pages 129696–129742, 2024. doi: 10.52202/ 079017-4121
2024
-
[2]
Must read: A comprehensive survey of computational persuasion.ACM Computing Surveys, March 2026
Nimet Beyza Bozdag et al. Must read: A comprehensive survey of computational persuasion.ACM Computing Surveys, March 2026. doi: 10.1145/3800687
-
[3]
Pappas, Florian Tramèr, Hamed Hassani, and Eric Wong
Patrick Chao, Edoardo Debenedetti, Alexander Robey, Maksym Andriushchenko, Francesco Croce, Vikash Se- hwag, Edgar Dobriban, Nicolas Flammarion, George J. Pappas, Florian Tramèr, Hamed Hassani, and Eric Wong. Jailbreakbench: An open robustness benchmark for jail- breaking large language models. InAdvances in Neural Information Processing Systems, volume 37, 2024
2024
-
[4]
Pappas, and Eric Wong
Patrick Chao, Alexander Robey, Edgar Dobriban, Hamed Hassani, George J. Pappas, and Eric Wong. Jailbreak- ing black box large language models in twenty queries. In2025 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML), pages 23–42, Copenhagen, Denmark, 2025. IEEE
2025
-
[5]
Humans or LLMs as the judge? a study on judgement bias
Guiming Hardy Chen et al. Humans or LLMs as the judge? a study on judgement bias. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 8301–8327, 2024
2024
-
[6]
StruQ: Defending against prompt injection with structured queries
Sizhe Chen, Julien Piet, Chawin Sitawarin, and David Wagner. StruQ: Defending against prompt injection with structured queries. In34th USENIX Security Sympo- sium (USENIX Security 25), pages 2383–2400, Seattle, WA, August 2025. USENIX Association. ISBN 978-1- 939133-52-6
2025
-
[7]
Ferguson-Walter, Maxine M
Kimberly J. Ferguson-Walter, Maxine M. Major, Chelsea K. Johnson, and Daniel H. Muhleman. Ex- amining the efficacy of decoy-based and psychological cyber deception. In30th USENIX Security Symposium (USENIX Security 21), pages 1127–1144. USENIX As- sociation, August 2021. ISBN 978-1-939133-24-3
2021
-
[8]
Melody Y . Guan et al. Deliberative alignment: Rea- soning enables safer language models, 2024. URL https://arxiv.org/abs/2412.16339
-
[9]
Deciphering the chaos: Enhancing jailbreak attacks via adversarial prompt translation, 2024
Qizhang Li, Xiaochen Yang, Wangmeng Zuo, and Yiwen Guo. Deciphering the chaos: Enhancing jailbreak attacks via adversarial prompt translation, 2024. URL https: //arxiv.org/abs/2410.11317
-
[10]
AutoDAN: Generating stealthy jailbreak prompts on aligned large language models
Xiaogeng Liu, Nan Xu, Muhao Chen, and Chaowei Xiao. AutoDAN: Generating stealthy jailbreak prompts on aligned large language models. InThe 12th Interna- tional Conference on Learning Representations, 2024
2024
-
[11]
Formalizing and benchmarking prompt injection attacks and defenses
Yupei Liu, Yuqi Jia, Runpeng Geng, Jinyuan Jia, and Neil Zhenqiang Gong. Formalizing and benchmarking prompt injection attacks and defenses. In33rd USENIX Security Symposium (USENIX Security 24), pages 1831– 1847, Philadelphia, PA, August 2024. USENIX Associa- tion. ISBN 978-1-939133-44-1. 14
2024
-
[12]
HarmBench: A standardized evaluation framework for automated red teaming and robust refusal
Mantas Mazeika et al. HarmBench: A standardized evaluation framework for automated red teaming and robust refusal. In Ruslan Salakhutdinov, Zico Kolter, Katherine Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp, editors,Proceedings of the 41st International Conference on Machine Learn- ing, volume 235 ofProceedings of Machine ...
2024
-
[13]
Tree of attacks: Jailbreaking black-box llms automatically
Anay Mehrotra, Manolis Zampetakis, Paul Kassianik, Blaine Nelson, Hyrum Anderson, Yaron Singer, and Amin Karbasi. Tree of attacks: Jailbreaking black-box llms automatically. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[14]
Llama Guard 3-8B Model Card
Meta Llama. Llama Guard 3-8B Model Card. https://github.com/meta-llama/ PurpleLlama/blob/main/Llama-Guard3/ 8B/MODEL_CARD.md, 2024. Accessed: 2026-05-26
2024
-
[15]
Targeting align- ment: Extracting safety classifiers of aligned LLMs
Jean-Charles Noirot Ferrand, Yohan Beugin, Eric Pauley, Ryan Sheatsley, and Patrick McDaniel. Targeting align- ment: Extracting safety classifiers of aligned LLMs. In 2026 IEEE Conference on Secure and Trustworthy Ma- chine Learning (SaTML), Munich, Germany, 2026. Ac- cepted paper
2026
-
[16]
Kornaropoulos, and Giuseppe Ateniese
Dario Pasquini, Evgenios M. Kornaropoulos, and Giuseppe Ateniese. Hacking Back the AI-Hacker: Prompt injection as a defense against LLM-driven cy- berattacks, 2024. URL https://arxiv.org/abs/ 2410.20911
-
[17]
Kornaropoulos, and Giuseppe Ateniese
Dario Pasquini, Evgenios M. Kornaropoulos, and Giuseppe Ateniese. LLMmap: Fingerprinting for large language models. In34th USENIX Security Symposium (USENIX Security 25), pages 299–318, Seattle, W A, Au- gust 2025. USENIX Association. ISBN 978-1-939133- 52-6
2025
-
[18]
Francisco J. Solis and Roger J.-B. Wets. Minimization by random search techniques.Mathematics of Operations Research, 6(1):19–30, 1981. doi: 10.1287/moor.6.1.19
-
[19]
A StrongREJECT for empty jailbreaks
Alexandra Souly et al. A StrongREJECT for empty jailbreaks. InAdvances in Neural Information Process- ing Systems, volume 37, pages 125416–125440, 2024. doi: 10.52202/079017-3984. Datasets and Benchmarks Track
-
[20]
Mis- sion impossible: A statistical perspective on jailbreaking LLMs
Jingtong Su, Julia Kempe, and Karen Ullrich. Mis- sion impossible: A statistical perspective on jailbreaking LLMs. InAdvances in Neural Information Processing Systems, volume 37, pages 38267–38306, 2024. doi: 10.52202/079017-1210
-
[21]
Zhen Sun et al. “To Survive, I Must Defect”: Jailbreak- ing LLMs via the game-theory scenarios, 2025. URL https://arxiv.org/abs/2511.16278
-
[22]
Eicher- Miller, Toby Jia-Jun Li, Meng Jiang, and Ronald A
Annalisa Szymanski, Noah Ziems, Heather A. Eicher- Miller, Toby Jia-Jun Li, Meng Jiang, and Ronald A. Metoyer. Limitations of the LLM-as-a-judge approach for evaluating LLM outputs in expert knowledge tasks. In Proceedings of the 30th ACM Conference on Intelligent User Interfaces. Association for Computing Machinery, 2025
2025
-
[23]
Large language models are not fair evaluators
Peiyi Wang et al. Large language models are not fair evaluators. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics, pages 9440–9450, 2024
2024
-
[24]
Jailbroken: How does LLM safety training fail? In Advances in Neural Information Processing Systems, vol- ume 36, pages 80079–80110, 2023
Alexander Wei, Nika Haghtalab, and Jacob Steinhardt. Jailbroken: How does LLM safety training fail? In Advances in Neural Information Processing Systems, vol- ume 36, pages 80079–80110, 2023
2023
-
[25]
SORRY-Bench: Systematically evalu- ating large language model safety refusal
Tinghao Xie et al. SORRY-Bench: Systematically evalu- ating large language model safety refusal. InThe Thir- teenth International Conference on Learning Represen- tations, 2025
2025
-
[26]
LLM-Fuzzer: Scaling assessment of large language model jailbreaks
Jiahao Yu, Xingwei Lin, Zheng Yu, and Xinyu Xing. LLM-Fuzzer: Scaling assessment of large language model jailbreaks. In33rd USENIX Security Symposium (USENIX Security 24), pages 4657–4674, Philadelphia, PA, August 2024. USENIX Association. ISBN 978-1- 939133-44-1
2024
-
[27]
GPTFUZZER: Red Teaming Large Language Models with Auto-Generated Jailbreak Prompts
Jiahao Yu, Xingwei Lin, Zheng Yu, and Xinyu Xing. Gptfuzzer: Red teaming large language models with auto-generated jailbreak prompts, 2024. URL https: //arxiv.org/abs/2309.10253
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
PROMPTFUZZ: Harnessing fuzzing techniques for robust testing of prompt injec- tion in LLMs, 2024
Jiahao Yu, Yangguang Shao, Hanwen Miao, Junzheng Shi, and Xinyu Xing. PROMPTFUZZ: Harnessing fuzzing techniques for robust testing of prompt injec- tion in LLMs, 2024. URL https://arxiv.org/ abs/2409.14729
-
[29]
Proactive defense against LLM jailbreak, 2025
Weiliang Zhao, Jinjun Peng, Daniel Ben-Levi, Zhou Yu, and Junfeng Yang. Proactive defense against LLM jailbreak, 2025
2025
-
[30]
Jailbreaking jailbreaks: A proactive defense for LLMs
Weiliang Zhao, Jinjun Peng, Daniel Ben-Levi, Zhou Yu, and Junfeng Yang. Jailbreaking jailbreaks: A proactive defense for LLMs. https://openreview.net/ forum?id=pq6rx9r6Aj, 2025. OpenReview sub- mission record
2025
-
[31]
Judging LLM-as-a-judge with MT-Bench and Chatbot Arena
Lianmin Zheng et al. Judging LLM-as-a-judge with MT-Bench and Chatbot Arena. InAdvances in Neu- ral Information Processing Systems, volume 36, pages 46595–46623, 2023. Datasets and Benchmarks Track. 15
2023
-
[32]
Zico Kolter, and Matt Fredrikson
Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J. Zico Kolter, and Matt Fredrikson. Universal and transferable adversarial attacks on aligned language mod- els, 2023. URL https://arxiv.org/abs/2307. 15043. LLM Usage Statement LLMs were used for language polishing and literature search during the preparation of this manuscript. Claude Code was also us...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.