CRePE: Convolution-aware Relative Importance in Post-training Pruning with Efficient Search
Pith reviewed 2026-06-28 15:41 UTC · model grok-4.3
The pith
CRePE improves post-training pruning accuracy by adding 2D local neighborhood context and adaptive coefficients to relative importance scores.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
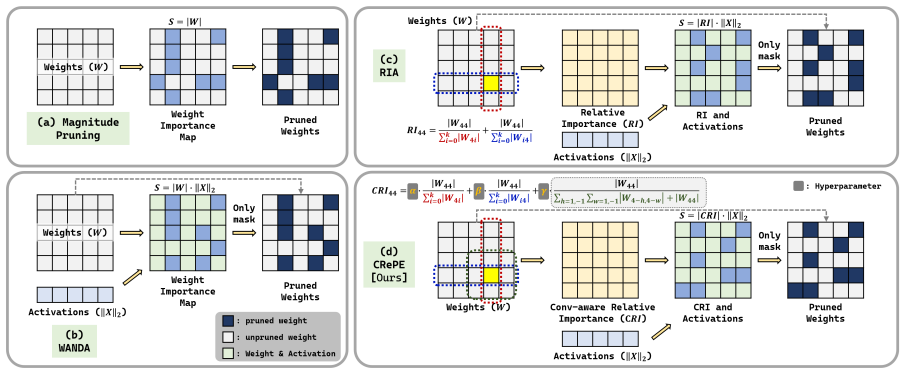
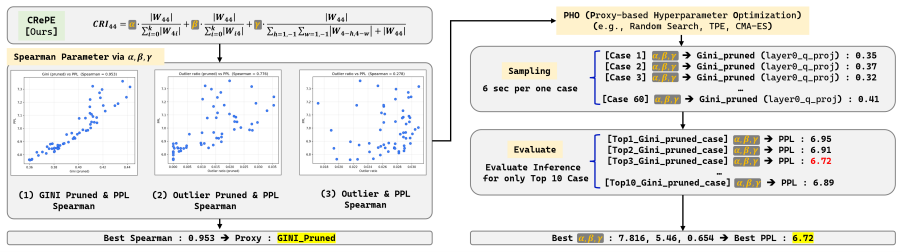
CRePE extends relative importance scoring by incorporating 2D local neighborhood context around each weight and adaptive coefficients that balance row and column contributions, producing higher accuracy than prior post-training pruning methods on diverse models and sparsity settings. PHO replaces repeated full perplexity evaluations with proxy measurements to locate good coefficient values rapidly, and the discovered coefficients generalize to other models without retuning. The method combines orthogonally with channel permutation, non-uniform sparsity allocation, and re-pruning.
What carries the argument
Convolution-aware relative importance scoring that augments row/column normalized scores with 2D neighborhood context and adaptive coefficients located via proxy-based hyperparameter optimization.
If this is right
- Higher retained accuracy in pruned LLMs at the same sparsity levels compared with RIA and other PTP baselines.
- Hyperparameter search time reduced from roughly 11 hours to 20 minutes.
- Discovered adaptive coefficients transfer directly to new models without additional search.
- Orthogonal gains when combined with channel permutation, non-uniform sparsity, and re-pruning techniques.
Where Pith is reading between the lines
- The 2D neighborhood term implies that weight matrices contain local spatial structure worth exploiting for importance estimation.
- Proxy optimization may lower costs when tuning other pruning or compression hyperparameters.
- Transferability of coefficients suggests they capture architecture-agnostic properties of transformer weight distributions.
- The method could reduce the barrier to deploying high-sparsity LLMs on resource-constrained hardware.
Load-bearing premise
That incorporating 2D neighborhood context and adaptive row-column coefficients will reliably produce more accurate pruning decisions that generalize without retraining or model-specific retuning beyond the searched coefficients.
What would settle it
A comparison on a held-out LLM architecture and sparsity level in which CRePE-pruned models exhibit equal or higher perplexity than RIA-pruned models at identical sparsity.
Figures

read the original abstract
Deploying Large Language Models (LLMs) in practice incurs substantial memory and computational costs. Post-training pruning (PTP) is an effective approach to reducing these costs by removing weights without additional training. Among existing methods, RIA introduces relative importance scores normalized by row and column sums, achieving state-of-the-art accuracy. However, RIA considers only 1D cross-shaped (row/column) directional information and assigns equal weight to row and column contributions. In this paper, we propose \textbf{CRePE}, which incorporates 2D local neighborhood context and adaptive coefficients into Relative Importance scoring. CRePE consistently outperforms existing PTP methods across diverse models and sparsity settings. However, identifying optimal adaptive coefficients via perplexity (PPL)-based hill climbing requires numerous PPL evaluations and approximately 11 hours of search time. To address this, we propose \textbf{PHO} (Proxy-based Hyperparameter Optimization), which eliminates the need for repeated PPL measurements and reduces the search time to approximately 20 minutes. Furthermore, the optimal hyperparameter configuration found by PHO on one model transfers well to other models, demonstrating strong generalization. Finally, we verify that CRePE can be orthogonally combined with existing techniques including Channel Permutation, non-uniform sparsity allocation, and re-pruning methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CRePE, an extension to relative importance scoring (RIA) for post-training pruning of LLMs that adds 2D local neighborhood context and adaptive coefficients for row/column contributions. It introduces PHO, a proxy-based hyperparameter optimization method that reduces the cost of searching for these coefficients from ~11 hours (PPL-based hill climbing) to ~20 minutes. The manuscript claims that CRePE consistently outperforms prior PTP methods across models and sparsity levels, that the coefficients found by PHO transfer across models, and that CRePE combines orthogonally with channel permutation, non-uniform sparsity, and re-pruning.
Significance. If the empirical claims hold, the work offers a practical advance in PTP by improving importance scoring accuracy while addressing the computational cost of adaptive coefficient search via PHO; the reported transferability of hyperparameters across models would reduce per-model tuning overhead. No machine-checked proofs or parameter-free derivations are present, but the efficiency gain and orthogonal-combinations claim are scoped appropriately.
major comments (1)
- [PHO and Experiments] The central performance claim depends on coefficients obtained by search (PHO) on a proxy for perplexity; the manuscript must demonstrate that the proxy correlates sufficiently with true PPL on held-out data or across multiple models to ensure the reported gains are not an artifact of the search procedure itself (PHO section and experimental tables).
minor comments (2)
- [Abstract] Abstract: quantitative results, baseline names, and error bars are referenced only qualitatively; the main text should ensure all tables include these for the 'consistent outperformance' claim.
- [Method] Notation for the 2D neighborhood and adaptive coefficients should be formalized with explicit equations early in the method section to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive review and the minor revision recommendation. We address the major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [PHO and Experiments] The central performance claim depends on coefficients obtained by search (PHO) on a proxy for perplexity; the manuscript must demonstrate that the proxy correlates sufficiently with true PPL on held-out data or across multiple models to ensure the reported gains are not an artifact of the search procedure itself (PHO section and experimental tables).
Authors: We agree that explicit validation of the proxy's correlation with true PPL is necessary to substantiate that the reported gains are not artifacts of the search. The current manuscript demonstrates efficiency gains and cross-model transfer of the resulting coefficients but does not include a dedicated correlation analysis. In the revised version we will add quantitative results (e.g., Pearson/Spearman correlations and scatter plots) in the PHO section, computed on held-out data for the models used in the experiments. This addition will directly address the concern while preserving the paper's scope. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper describes an empirical post-training pruning method (CRePE) that augments an existing RIA baseline with 2D neighborhood context and searched adaptive coefficients, plus a proxy (PHO) to accelerate hyperparameter search. Performance claims rest on experimental comparisons after standard hyperparameter tuning on a proxy metric, with reported transfer across models; this does not constitute a derivation chain that reduces to self-definition, fitted inputs renamed as predictions, or load-bearing self-citations. No equations or uniqueness theorems are invoked that collapse by construction to the inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- adaptive coefficients
axioms (1)
- domain assumption 2D local neighborhood context improves relative importance scoring over 1D row/column normalization
Reference graph
Works this paper leans on
-
[1]
Phi-4 technical report.Preprint, arXiv:2412.08905. Yongqi An, Xu Zhao, Tao Yu, Ming Tang, and Jinqiao Wang
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Slicegpt: Compress large language models by deleting rows and columns.arXiv preprint, 2024
Slicegpt: Compress large language models by deleting rows and columns.arXiv preprint arXiv:2401.15024. Vladimír Boža
-
[3]
Fast and effective weight update for pruned large language models.arXiv preprint arXiv:2401.02938. Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, and 1 others
-
[4]
Lidia Ceriani and Paolo Verme
Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901. Lidia Ceriani and Paolo Verme
1901
-
[5]
Yuli Chen, Bo Cheng, Jiale Han, Yingying Zhang, Yingt- ing Li, and Shuhao Zhang
The origins of the gini index: extracts from variabilità e mutabilità (1912) by corrado gini.The Journal of Economic Inequality, 10(3):421–443. Yuli Chen, Bo Cheng, Jiale Han, Yingying Zhang, Yingt- ing Li, and Shuhao Zhang
1912
-
[6]
Dlp: Dynamic layerwise pruning in large language models.arXiv preprint arXiv:2505.23807. DeepSeek-AI, :, Xiao Bi, Deli Chen, Guanting Chen, Shanhuang Chen, Damai Dai, Chengqi Deng, Honghui Ding, Kai Dong, Qiushi Du, Zhe Fu, Huazuo Gao, Kaige Gao, Wenjun Gao, Ruiqi Ge, Kang Guan, Daya Guo, Jianzhong Guo, and 69 others
-
[7]
DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
Deepseek llm: Scaling open- source language models with longtermism.Preprint, arXiv:2401.02954. Elias Frantar and Dan Alistarh
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
Gptq: Accurate post-training quantization for generative pre-trained transformers. arXiv preprint arXiv:2210.17323. Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al- Dahle, Aiesha Letman, Akhil Mathur, Alan Schel- ten, Alex Vaughan, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mi- tr...
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
The llama 3 herd of models.Preprint, arXiv:2407.21783. Song Han, Jeff Pool, John Tran, and William Dally
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Distilling the Knowledge in a Neural Network
Distilling the knowledge in a neural network.arXiv preprint arXiv:1503.02531. Haiquan Lu, Yefan Zhou, Shiwei Liu, Zhangyang Wang, Michael W Mahoney, and Yaoqing Yang
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Shortgpt: Layers in large language models are more redundant than you expect.arXiv preprint arXiv:2403.03853. Xiang Meng, Kayhan Behdin, Haoyue Wang, and Rahul Mazumder
-
[12]
Qwen2.5 technical report.Preprint, arXiv:2412.15115. Jiwon Song, Kyungseok Oh, Taesu Kim, Hyungjun Kim, Yulhwa Kim, and Jae-Joon Kim
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
A Simple and Effective Pruning Approach for Large Language Models
A simple and effective pruning ap- proach for large language models.arXiv preprint arXiv:2306.11695. Qwen Team
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Qwen3. 5-omni technical report. arXiv preprint arXiv:2604.15804. Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, and 1 others. 2023a. Llama: Open and ef- ficient foundation language models.arXiv preprint arXiv:2302.13971. Hugo Touvron, Louis Mar...
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Laco: Large lan- guage model pruning via layer collapse.arXiv preprint arXiv:2402.11187,
Laco: Large language model pruning via layer collapse. arXiv preprint arXiv:2402.11187. Lu Yin, You Wu, Zhenyu Zhang, Cheng-Yu Hsieh, Yaqing Wang, Yiling Jia, Gen Li, Ajay Jaiswal, Mykola Pechenizkiy, Yi Liang, and 1 others
-
[16]
In12th International Con- ference on Learning Representations (ICLR 2024)
Plug- and-play: An efficient post-training pruning method for large language models. In12th International Con- ference on Learning Representations (ICLR 2024). Yuxin Zhang, Lirui Zhao, Mingbao Lin, Yunyun Sun, Yiwu Yao, Xingjia Han, Jared Tanner, Shiwei Liu, and Rongrong Ji
2024
-
[17]
Pengxiang Zhao, Hanyu Hu, Ping Li, Yi Zheng, Zhe- feng Wang, and Xiaoming Yuan
Dynamic sparse no train- ing: Training-free fine-tuning for sparse llms.arXiv preprint arXiv:2310.08915. Pengxiang Zhao, Hanyu Hu, Ping Li, Yi Zheng, Zhe- feng Wang, and Xiaoming Yuan
-
[18]
InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 29457–29475
Fistapruner: Layer-wise post-training pruning for large language models. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 29457–29475. 10
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.