Learning to Adaptively Allocate Gaussians for Arbitrary-Scale Image Super-Resolution
Pith reviewed 2026-06-30 08:05 UTC · model grok-4.3
The pith
A feed-forward network learns to predict Gaussian densification for arbitrary-scale super-resolution from low-resolution inputs alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
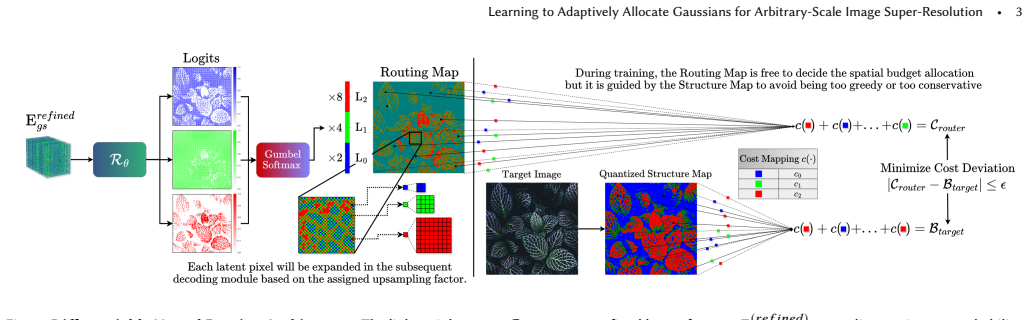
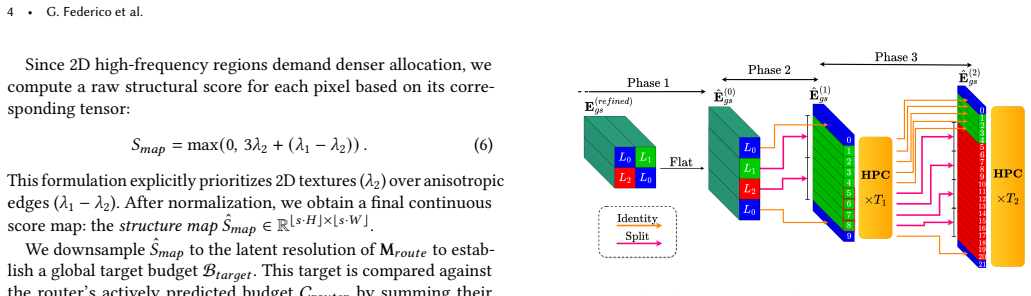
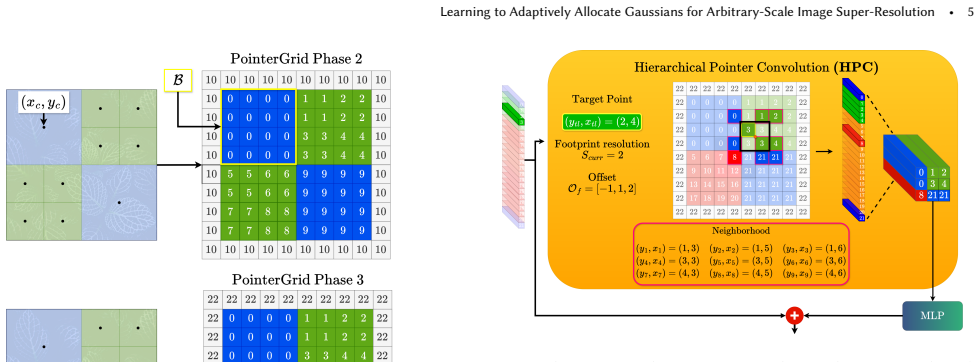
After encoding low-resolution inputs into latent space, a Neural Routing Architecture evaluates local complexity to distribute a global budget and assign specific upsampling factors to features. Features are then dynamically densified according to these factors to create an irregular topology that is decoded into 2D Gaussian primitives. Hierarchical Pointer Convolution coordinates the features before decoding with O(1) neighbor lookup complexity.
What carries the argument
Neural Routing Architecture that evaluates local complexity to assign upsampling factors and control adaptive densification of features into Gaussian primitives.
If this is right
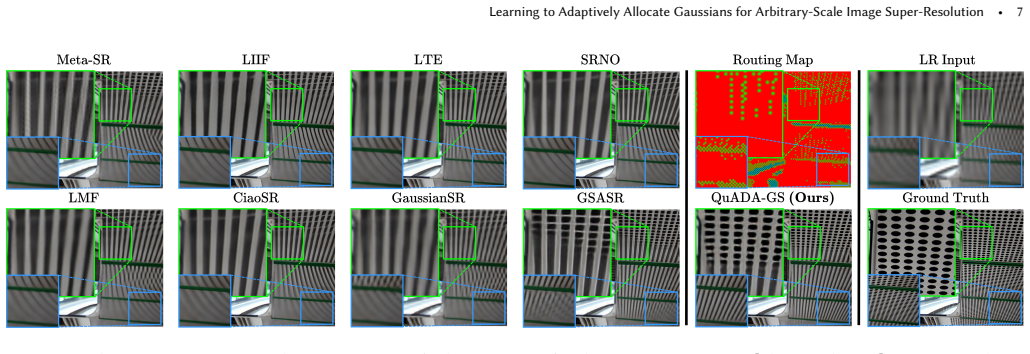
- QuADA-GS achieves state-of-the-art performance on arbitrary-scale super-resolution benchmarks.
- The method maintains low latency while using a lean memory footprint by concentrating resources on complex regions.
- It supports continuous scaling factors without relying on sub-optimal post-hoc interpolation.
- Hierarchical Pointer Convolution enables efficient spatial communication without dense grid bottlenecks.
Where Pith is reading between the lines
- The routing mechanism suggests a general way to replace gradient-driven primitive growth with learned complexity prediction in other splatting-based representations.
- This could reduce memory overhead in real-time graphics pipelines that must handle variable zoom levels or foveated rendering.
- Extending the same routing logic to 3D or video data might allow adaptive allocation across time or depth without retraining the core densification logic.
Load-bearing premise
A feed-forward network can autonomously predict the correct densification of Gaussian primitives from low-resolution inputs alone, without high-resolution gradients that standard Gaussian Splatting optimization requires during training.
What would settle it
A test showing that QuADA-GS quality collapses or falls below interpolation-based baselines on non-integer scales when the routing network is replaced by uniform allocation would falsify the claim.
Figures

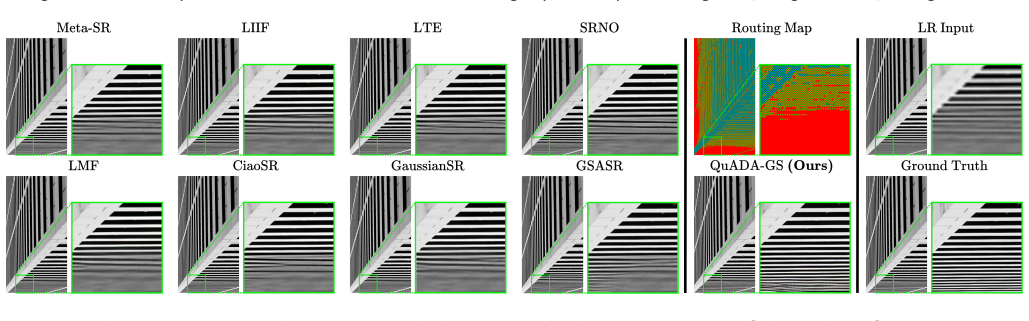
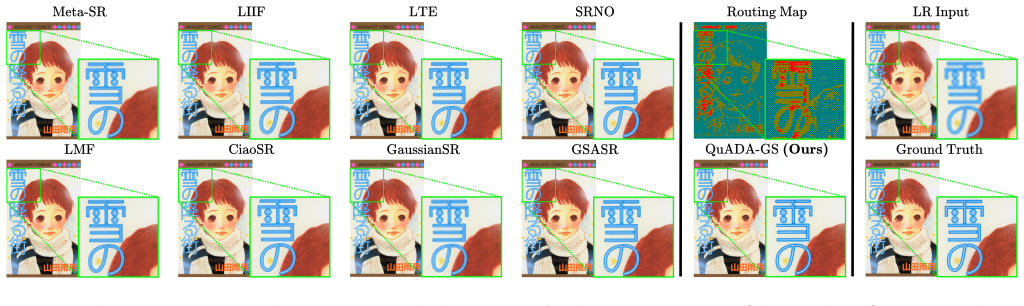



read the original abstract
In computer graphics, visual content is continuously warped, zoomed and resampled. This occurs when engines upscale frames, users zoom into 3D scenes, or foveated VR applies varying scaling. Handling these transformations requires Arbitrary-Scale Super-Resolution (ASR). Traditional models, designed for fixed scales, typically predict at a lower integer scale (e.g., x4) and rely on sub-optimal interpolation for continuous resolutions, compromising quality. Furthermore, most methods process pixels uniformly. Since fine details are sparse, this creates overhead; efficiency dictates concentrating resources only where structural complexity demands it. While implicit models and Gaussian Splatting (GS) enable continuous representation, GS is advantageous due to adaptive densification. However, transitioning GS into a feed-forward model for ASR is non-trivial. Standard GS optimization needs high-resolution gradients to drive primitive growth, which are unavailable during inference. Thus, the network must autonomously predict GS densification from low-resolution inputs. To solve this, we propose QuADA-GS. After encoding inputs into a latent space, a Neural Routing Architecture evaluates local complexity to distribute a global budget, assigning specific upsampling factors to features to avoid redundant processing. Features are dynamically densified based on these factors, forming an irregular topology decoded into 2D Gaussian primitives. To coordinate features before decoding, we introduce Hierarchical Pointer Convolution. This non-grid operator achieves O(1) neighbor lookup complexity, facilitating efficient spatial communication and bypassing dense bottlenecks. Experiments show QuADA-GS achieves state-of-the-art ASR performance, maintaining low latency and a lean memory footprint.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes QuADA-GS, a feed-forward architecture for arbitrary-scale image super-resolution. It encodes low-resolution inputs into latent space, employs a Neural Routing Architecture to evaluate local complexity and distribute a global budget by predicting per-feature upsampling factors, dynamically densifies features into an irregular topology of 2D Gaussian primitives, and decodes them via the introduced Hierarchical Pointer Convolution operator (claimed O(1) neighbor lookup) to enable efficient spatial communication. The central claim is that this learned adaptive allocation achieves state-of-the-art ASR performance while maintaining low latency and a lean memory footprint.
Significance. If the empirical results hold and the routing network successfully learns to allocate primitives where structural complexity requires them, the work would be significant for efficient continuous-scale super-resolution. It combines the adaptive densification property of Gaussian Splatting with feed-forward inference, addressing uniform pixel processing overhead in traditional ASR methods and enabling resource concentration on complex regions without dense bottlenecks.
major comments (1)
- [Abstract] Abstract: The SOTA performance claim rests on the Neural Routing Architecture autonomously predicting correct densification of Gaussian primitives from LR inputs alone. However, standard GS adaptive densification is driven by HR gradients during optimization; the feed-forward path has no such signal at inference. No quantitative results, ablation studies on routing accuracy, or implementation details are supplied to verify that the learned policy allocates primitives where structural complexity (e.g., edges or textures visible only at target scale) actually demands them, which is load-bearing for both quality and the claimed memory/latency savings.
Simulated Author's Rebuttal
We thank the referee for highlighting this critical aspect of our contribution. The concern about validating the Neural Routing Architecture's ability to predict appropriate Gaussian densification from LR inputs alone is well-taken, as it underpins both the quality and efficiency claims. We address this point below and will revise the manuscript to incorporate additional supporting evidence.
read point-by-point responses
-
Referee: [Abstract] Abstract: The SOTA performance claim rests on the Neural Routing Architecture autonomously predicting correct densification of Gaussian primitives from LR inputs alone. However, standard GS adaptive densification is driven by HR gradients during optimization; the feed-forward path has no such signal at inference. No quantitative results, ablation studies on routing accuracy, or implementation details are supplied to verify that the learned policy allocates primitives where structural complexity (e.g., edges or textures visible only at target scale) actually demands them, which is load-bearing for both quality and the claimed memory/latency savings.
Authors: We agree that direct validation of the routing policy is essential and was insufficiently emphasized. While the end-to-end training on LR-to-HR pairs allows the network to learn a policy that correlates with structural complexity (as evidenced by the reported SOTA quality and efficiency gains over uniform baselines), we acknowledge the absence of explicit routing-accuracy metrics. In the revised version we will add: (1) quantitative comparison of predicted per-feature upsampling factors against proxy ground-truth complexity maps computed from HR gradients on held-out data; (2) ablation studies that disable the Neural Routing Architecture (replacing it with uniform allocation) and report resulting PSNR/SSIM drops as well as changes in memory footprint and latency; and (3) implementation details on the routing loss and budget-distribution mechanism. These additions will directly address the load-bearing claim. revision: yes
Circularity Check
No circularity; feed-forward prediction of densification is an empirical claim, not a definitional reduction.
full rationale
The provided abstract and description contain no equations, fitted parameters renamed as predictions, or self-citation chains that reduce the claimed ASR performance or Gaussian allocation to quantities defined by the inputs themselves. The method is presented as a learned architecture (Neural Routing + Hierarchical Pointer Convolution) that must solve the non-trivial mapping from LR to adaptive GS primitives; this is an independent empirical claim supported by experiments rather than a self-referential construction. No load-bearing step matches any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
free parameters (1)
- global budget
axioms (1)
- domain assumption Feed-forward networks can learn to replicate the densification behavior of gradient-driven Gaussian Splatting optimization
invented entities (1)
-
Hierarchical Pointer Convolution
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Human guided ground-truth generation for realistic image super-resolution , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[2]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Toward generalized image quality assessment: Relaxing the perfect reference quality assumption , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[3]
Proceedings of the 32nd ACM International Conference on Multimedia , pages=
SSL: A self-similarity loss for improving generative image super-resolution , author=. Proceedings of the 32nd ACM International Conference on Multimedia , pages=
-
[4]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Details or artifacts: A locally discriminative learning approach to realistic image super-resolution , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[5]
International Journal of Computer Vision , volume=
Exploiting diffusion prior for real-world image super-resolution , author=. International Journal of Computer Vision , volume=. 2024 , publisher=
2024
-
[6]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Real-esrgan: Training real-world blind super-resolution with pure synthetic data , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[7]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Sinsr: diffusion-based image super-resolution in a single step , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[8]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Seesr: Towards semantics-aware real-world image super-resolution , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[9]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Fine-structure preserved real-world image super-resolution via transfer vae training , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[10]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Scaling up to excellence: Practicing model scaling for photo-realistic image restoration in the wild , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[11]
Advances in neural information processing systems , volume=
Resshift: Efficient diffusion model for image super-resolution by residual shifting , author=. Advances in neural information processing systems , volume=
-
[12]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =
Zhang, Kai and Liang, Jingyun and Van Gool, Luc and Timofte, Radu , title =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =. 2021 , pages =
2021
-
[13]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Activating more pixels in image super-resolution transformer , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[14]
European conference on computer vision , pages=
Accelerating the super-resolution convolutional neural network , author=. European conference on computer vision , pages=. 2016 , organization=
2016
-
[15]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Li, Zhen and Yang, Jinglei and Liu, Zheng and Yang, Xiaomin and Jeon, Gwanggil and Wu, Wei , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
-
[16]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops , month =
Liang, Jingyun and Cao, Jiezhang and Sun, Guolei and Zhang, Kai and Van Gool, Luc and Timofte, Radu , title =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops , month =. 2021 , pages =
2021
-
[17]
Proceedings of the European conference on computer vision (ECCV) workshops , pages=
Esrgan: Enhanced super-resolution generative adversarial networks , author=. Proceedings of the European conference on computer vision (ECCV) workshops , pages=
-
[18]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Transcending the limit of local window: Advanced super-resolution transformer with adaptive token dictionary , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[19]
European conference on computer vision , pages=
Efficient long-range attention network for image super-resolution , author=. European conference on computer vision , pages=. 2022 , organization=
2022
-
[20]
Proceedings of the European conference on computer vision (ECCV) , pages=
Image super-resolution using very deep residual channel attention networks , author=. Proceedings of the European conference on computer vision (ECCV) , pages=
-
[21]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Residual dense network for image super-resolution , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[22]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Learning continuous image representation with local implicit image function , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[23]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Local texture estimator for implicit representation function , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[24]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Yao, Jie-En and Tsao, Li-Yuan and Lo, Yi-Chen and Tseng, Roy and Chang, Chia-Che and Lee, Chun-Yi , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2023 , pages =
2023
-
[25]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Ciaosr: Continuous implicit attention-in-attention network for arbitrary-scale image super-resolution , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[26]
Communications of the ACM , volume=
Nerf: Representing scenes as neural radiance fields for view synthesis , author=. Communications of the ACM , volume=. 2021 , publisher=
2021
-
[27]
European conference on computer vision , pages=
Learning a deep convolutional network for image super-resolution , author=. European conference on computer vision , pages=. 2014 , organization=
2014
-
[28]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Kim, Jiwon and Lee, Jung Kwon and Lee, Kyoung Mu , title =. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , month =
-
[29]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Deeply-recursive convolutional network for image super-resolution , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[30]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Deep laplacian pyramid networks for fast and accurate super-resolution , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[31]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Meta-SR: A magnification-arbitrary network for super-resolution , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[32]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Learning a single network for scale-arbitrary super-resolution , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[33]
Implicit Transformer Network for Screen Content Image Continuous Super-Resolution , url =
Yang, Jingyu and Shen, Sheng and Yue, Huanjing and Li, Kun , booktitle =. Implicit Transformer Network for Screen Content Image Continuous Super-Resolution , url =
-
[34]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Wei, Min and Zhang, Xuesong , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2023 , pages =
2023
-
[35]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Chen, Hao-Wei and Xu, Yu-Syuan and Hong, Min-Fong and Tsai, Yi-Min and Kuo, Hsien-Kai and Lee, Chun-Yi , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2023 , pages =
2023
-
[36]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
He, Zongyao and Jin, Zhi , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2024 , pages =
2024
-
[37]
, author=
3d gaussian splatting for real-time radiance field rendering. , author=. ACM Trans. Graph. , volume=
-
[38]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Gaussiansr: High fidelity 2d gaussian splatting for arbitrary-scale image super-resolution , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[39]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =
Chen, Du and Chen, Liyi and Zhang, Zhengqiang and Zhang, Lei , title =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =. 2025 , pages =
2025
-
[40]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops , month =
Lim, Bee and Son, Sanghyun and Kim, Heewon and Nah, Seungjun and Mu Lee, Kyoung , title =. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops , month =
-
[41]
Proceedings of the European Conference on Computer Vision (ECCV) , month =
Zhang, Yulun and Li, Kunpeng and Li, Kai and Wang, Lichen and Zhong, Bineng and Fu, Yun , title =. Proceedings of the European Conference on Computer Vision (ECCV) , month =
-
[42]
Categorical Reparameterization with Gumbel-Softmax
Categorical reparameterization with gumbel-softmax , author=. arXiv preprint arXiv:1611.01144 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
and Bishop, Rob and Rueckert, Daniel and Wang, Zehan , title =
Shi, Wenzhe and Caballero, Jose and Huszar, Ferenc and Totz, Johannes and Aitken, Andrew P. and Bishop, Rob and Rueckert, Daniel and Wang, Zehan , title =. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , month =
-
[44]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Octnet: Learning deep 3d representations at high resolutions , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[46]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Choy, Christopher and Gwak, JunYoung and Savarese, Silvio , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
-
[47]
Wang, Peng-Shuai and Liu, Yang and Guo, Yu-Xiao and Sun, Chun-Yu and Tong, Xin , title =. ACM Trans. Graph. , month = jul, articleno =. 2017 , issue_date =. doi:10.1145/3072959.3073608 , abstract =
-
[48]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Kpconv: Flexible and deformable convolution for point clouds , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[49]
Proceedings of the European Conference on Computer Vision (ECCV) , month =
Jayaraman, Pradeep Kumar and Mei, Jianhan and Cai, Jianfei and Zheng, Jianmin , title =. Proceedings of the European Conference on Computer Vision (ECCV) , month =
-
[50]
Proceedings of the 56th Annual IEEE/ACM International Symposium on Microarchitecture , pages =
Tang, Haotian and Yang, Shang and Liu, Zhijian and Hong, Ke and Yu, Zhongming and Li, Xiuyu and Dai, Guohao and Wang, Yu and Han, Song , title =. Proceedings of the 56th Annual IEEE/ACM International Symposium on Microarchitecture , pages =. 2023 , isbn =. doi:10.1145/3613424.3614303 , abstract =
-
[51]
2023 , eprint=
Designing BERT for Convolutional Networks: Sparse and Hierarchical Masked Modeling , author=. 2023 , eprint=
2023
-
[52]
Proceedings of the IEEE International Conference on Computer Vision (ICCV) , month =
Dai, Jifeng and Qi, Haozhi and Xiong, Yuwen and Li, Yi and Zhang, Guodong and Hu, Han and Wei, Yichen , title =. Proceedings of the IEEE International Conference on Computer Vision (ICCV) , month =
-
[53]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Lu, Tao and Yu, Mulin and Xu, Linning and Xiangli, Yuanbo and Wang, Limin and Lin, Dahua and Dai, Bo , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2024 , pages =
2024
-
[54]
Submanifold Sparse Convolutional Networks
Submanifold Sparse Convolutional Networks , author=. arXiv preprint arXiv:1706.01307 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[55]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =
Sun, Long and Dong, Jiangxin and Tang, Jinhui and Pan, Jinshan , title =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =. 2023 , pages =
2023
-
[56]
arXiv preprint arXiv:2603.18513 , year=
CAFlow: Adaptive-Depth Single-Step Flow Matching for Efficient Histopathology Super-Resolution , author=. arXiv preprint arXiv:2603.18513 , year=
-
[57]
arXiv preprint arXiv:2412.06028 , year=
Sparsedit: Token sparsification for efficient diffusion transformer , author=. arXiv preprint arXiv:2412.06028 , year=
-
[58]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Peng, Bohao and Wu, Xiaoyang and Jiang, Li and Chen, Yukang and Zhao, Hengshuang and Tian, Zhuotao and Jia, Jiaya , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2024 , pages =
2024
-
[59]
Graph attention networks , author=. arXiv preprint arXiv:1710.10903 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[60]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops , month =
Timofte, Radu and Agustsson, Eirikur and Van Gool, Luc and Yang, Ming-Hsuan and Zhang, Lei , title =. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops , month =
-
[61]
Accelerating the Super-Resolution Convolutional Neural Network
Dong, Chao and Loy, Chen Change and Tang, Xiaoou. Accelerating the Super-Resolution Convolutional Neural Network. Computer Vision -- ECCV 2016. 2016
2016
-
[62]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops , month =
Li, Yawei and Zhang, Kai and Liang, Jingyun and Cao, Jiezhang and Liu, Ce and Gong, Rui and Zhang, Yulun and Tang, Hao and Liu, Yun and Demandolx, Denis and Ranjan, Rakesh and Timofte, Radu and Van Gool, Luc , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops , month =. 2023 , pages =
2023
-
[63]
and Fowlkes, C
Martin, D. and Fowlkes, C. and Tal, D. and Malik, J. , booktitle=. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics , year=
-
[64]
Multimedia tools and applications , volume=
Sketch-based manga retrieval using manga109 dataset , author=. Multimedia tools and applications , volume=. 2017 , publisher=
2017
-
[65]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Huang, Jia-Bin and Singh, Abhishek and Ahuja, Narendra , title =. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , month =
-
[66]
2012 , publisher=
Low-complexity single-image super-resolution based on nonnegative neighbor embedding , author=. 2012 , publisher=
2012
-
[67]
On Single Image Scale-Up Using Sparse-Representations
Zeyde, Roman and Elad, Michael and Protter, Matan. On Single Image Scale-Up Using Sparse-Representations. Curves and Surfaces. 2012
2012
-
[68]
and Sheikh, H.R
Zhou Wang and Bovik, A.C. and Sheikh, H.R. and Simoncelli, E.P. , journal=. Image quality assessment: from error visibility to structural similarity , year=
-
[69]
and Shechtman, Eli and Wang, Oliver , title =
Zhang, Richard and Isola, Phillip and Efros, Alexei A. and Shechtman, Eli and Wang, Oliver , title =. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , month =
-
[70]
, journal=
Ding, Keyan and Ma, Kede and Wang, Shiqi and Simoncelli, Eero P. , journal=. Image Quality Assessment: Unifying Structure and Texture Similarity , year=
-
[71]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Arbitrary-steps image super-resolution via diffusion inversion , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[72]
International Conference on Computer Vision Workshops (ICCVW) , date =
Xintao Wang and Liangbin Xie and Chao Dong and Ying Shan , title =. International Conference on Computer Vision Workshops (ICCVW) , date =
-
[73]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Jeong, Jinho and Han, Sangmin and Kim, Jinwoo and Kim, Seon Joo , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2025 , pages =
2025
-
[74]
Proceedings of the AAAI Conference on Artificial Intelligence , author=
Effective Diffusion Transformer Architecture for Image Super-Resolution , volume=. Proceedings of the AAAI Conference on Artificial Intelligence , author=. 2025 , month=. doi:10.1609/aaai.v39i3.32247 , abstractNote=
-
[75]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis , url =
Podell, Dustin and English, Zion and Lacey, Kyle and Blattmann, Andreas and Dockhorn, Tim and M\". SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis , url =. International Conference on Learning Representations , editor =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.