Evaluation Pitfalls and Challenges in Multimedia Event Extraction
Pith reviewed 2026-06-26 05:08 UTC · model grok-4.3
The pith
Minor evaluation choices in multimedia event extraction can produce large performance swings and overstate models' real-world grounding ability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Under a strict evaluation framework that enforces consistent data processing, uniform task definitions, and tight scoring criteria, the authors show that small variations in any of these three areas produce substantial changes in measured performance, demonstrating that many existing results overestimate a model's capacity to ground real-world events across text and images.
What carries the argument
The strict evaluation framework that standardizes data handling, task scope, and scoring rules to expose the effects of prior inconsistencies.
If this is right
- Inconsistent data processing alone can inflate scores enough to mislead comparisons between systems.
- Overly relaxed evaluation settings systematically overestimate cross-modal grounding performance.
- Results from different papers become incomparable without shared evaluation conventions.
- Models that look strong under lenient settings may fail to ground events reliably when stricter checks are applied.
Where Pith is reading between the lines
- Other multimodal tasks outside event extraction may harbor similar hidden evaluation sensitivities that warrant systematic checks.
- Prior published numbers in the field could be revisited with the stricter protocol to produce a revised performance baseline.
- New benchmark releases might include both lenient and strict tracks so the community can quantify the gap directly.
Load-bearing premise
The authors' chosen strict evaluation framework is the right or most appropriate standard against which other published results should be judged.
What would settle it
Re-running the same set of published models on the same data splits but with the authors' strict rules and obtaining only small or no performance drops would falsify the claim that minor choices cause large overestimations.
Figures
read the original abstract
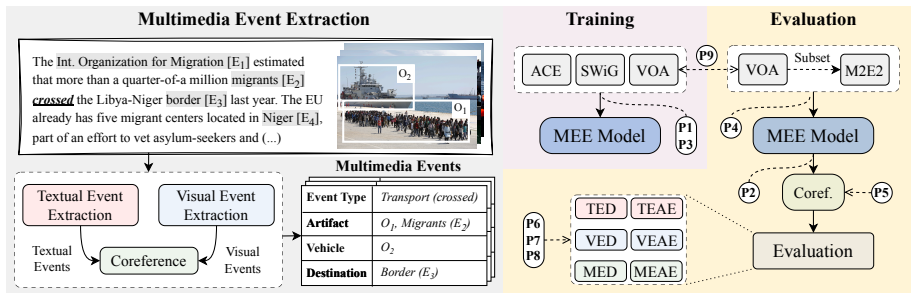
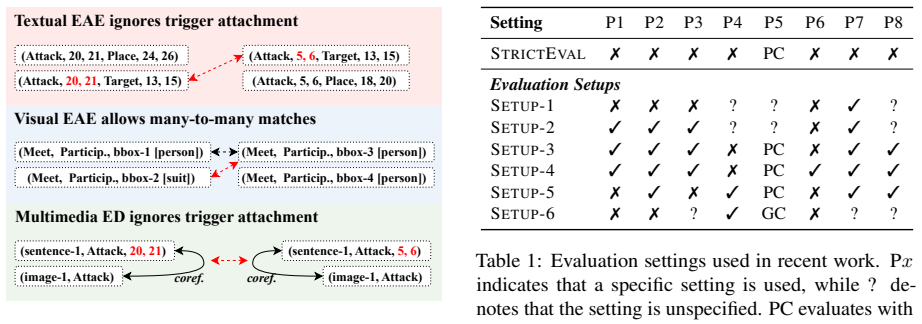
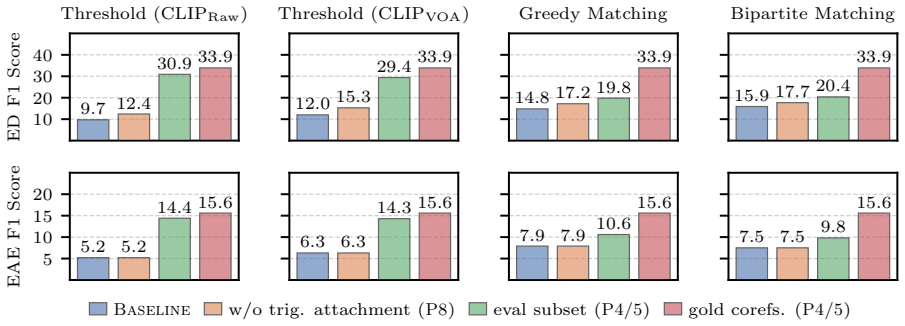
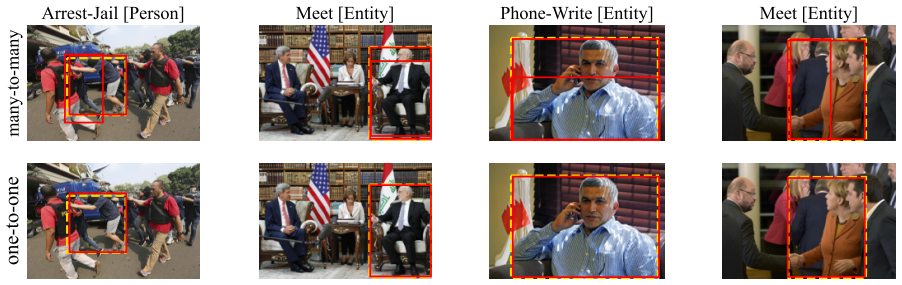
Multimedia event extraction aims to jointly identify events and their arguments across multiple modalities, such as text and images, to support more comprehensive event understanding. While recent work reports steady and substantial progress, the reliability and comparability of these results critically depend on consistent and rigorous evaluation. In this work, we present the first systematic analysis of evaluation pitfalls in multimedia event extraction and identify three major sources of issues: inconsistent data processing, inconsistent task assumptions, and overly relaxed evaluation settings. We demonstrate, through a series of controlled experiments under a strict evaluation framework, that minor evaluation choices can cause large performance variations and lead to overestimation of a model's ability to ground real-world events across modalities. Our findings highlight the need for comparable evaluation standards and encourage a shift toward more rigorous evaluation in multimedia event extraction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that multimedia event extraction suffers from three major evaluation issues—inconsistent data processing, inconsistent task assumptions, and overly relaxed evaluation settings—and demonstrates via controlled experiments under a strict evaluation framework that minor evaluation choices produce large performance variations, leading to overestimation of models' ability to ground real-world events across modalities.
Significance. If the central empirical findings hold, the work would be significant for the multimedia event extraction community by documenting sensitivity to evaluation choices and calling for more comparable standards; the absence of machine-checked proofs or parameter-free derivations is expected for an empirical analysis paper, but the lack of an external anchor (human judgments, downstream correlation) limits the strength of the overestimation claim.
major comments (2)
- [Abstract / Evaluation Framework] The central claim that relaxed settings produce 'overestimation' (rather than merely different but valid task definitions) requires justification that the authors' strict framework is the appropriate standard for real-world grounding. No external validation—such as correlation with human judgments on event grounding or downstream task performance—is provided to anchor why the strict criteria are correct and others erroneous (see Abstract and the description of the strict framework).
- [Introduction / Experiments] The three sources of inconsistency are identified, but the manuscript does not quantify their relative contribution or show that the observed variations are not simply artifacts of narrower task definitions under the strict protocol; this weakens the load-bearing assertion that prior work overestimated actual multimodal grounding ability.
minor comments (2)
- [Section 3] Clarify the exact definition and implementation details of the 'strict evaluation framework' early in the paper, including any differences from prior work's protocols.
- [Experiments] Ensure all experimental results include statistical significance tests or confidence intervals to support claims of 'large performance variations'.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback. We address the major comments point by point below, maintaining that our empirical analysis demonstrates sensitivity to evaluation choices while acknowledging limitations in external anchoring.
read point-by-point responses
-
Referee: [Abstract / Evaluation Framework] The central claim that relaxed settings produce 'overestimation' (rather than merely different but valid task definitions) requires justification that the authors' strict framework is the appropriate standard for real-world grounding. No external validation—such as correlation with human judgments on event grounding or downstream task performance—is provided to anchor why the strict criteria are correct and others erroneous (see Abstract and the description of the strict framework).
Authors: The strict framework is motivated by the requirement that models must perform actual cross-modal grounding of events rather than succeeding via loose criteria that permit non-grounded matches. Our controlled experiments isolate how relaxed settings inflate scores without corresponding improvements in multimodal integration, supporting the overestimation interpretation relative to real-world event understanding. We agree that external validation would strengthen the claim but the manuscript centers on internal sensitivity analysis under consistent protocols. revision: no
-
Referee: [Introduction / Experiments] The three sources of inconsistency are identified, but the manuscript does not quantify their relative contribution or show that the observed variations are not simply artifacts of narrower task definitions under the strict protocol; this weakens the load-bearing assertion that prior work overestimated actual multimodal grounding ability.
Authors: The experiments apply the strict protocol uniformly across variations to isolate each inconsistency source, showing performance swings attributable to the choices rather than artifacts of narrower definitions. While we did not include an explicit quantification of relative contributions (as the focus was demonstrating the existence and magnitude of effects), the design controls for task definition by holding the strict criteria fixed. We can add further discussion of this control in a revision. revision: partial
- Lack of external validation such as correlation with human judgments on event grounding or downstream task performance to anchor the strict framework as the definitive standard.
Circularity Check
Empirical evaluation analysis contains no circular derivation steps
full rationale
The paper performs a systematic empirical comparison of evaluation practices in multimedia event extraction, identifying inconsistencies via controlled experiments. No equations, fitted parameters, self-definitional constructs, or load-bearing self-citations appear in the derivation chain. The central claim rests on observable performance variations under different settings rather than any reduction to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Existing evaluation practices in multimedia event extraction contain inconsistencies that affect reported performance
Reference graph
Works this paper leans on
-
[1]
Cross-media Structured Common Space for Multimedia Event Extraction
Li, Manling and Zareian, Alireza and Zeng, Qi and Whitehead, Spencer and Lu, Di and Ji, Heng and Chang, Shih-Fu. Cross-media Structured Common Space for Multimedia Event Extraction. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.230
-
[2]
Liu, Jian and Chen, Yufeng and Xu, Jinan , title =. 2022 , isbn =. doi:10.1145/3503161.3548132 , booktitle =
-
[3]
CLIP-Event: Connecting Text and Images with Event Structures , year=
Li, Manling and Xu, Ruochen and Wang, Shuohang and Zhou, Luowei and Lin, Xudong and Zhu, Chenguang and Zeng, Michael and Ji, Heng and Chang, Shih-Fu , booktitle=. CLIP-Event: Connecting Text and Images with Event Structures , year=
-
[4]
Du, Zilin and Li, Yunxin and Guo, Xu and Sun, Yidan and Li, Boyang , title =. 2023 , isbn =. doi:10.1145/3581783.3612526 , booktitle =
-
[5]
Proceedings of the AAAI Conference on Artificial Intelligence , author=
UMIE: Unified Multimodal Information Extraction with Instruction Tuning , volume=. Proceedings of the AAAI Conference on Artificial Intelligence , author=. 2024 , month=. doi:10.1609/aaai.v38i17.29873 , number=
-
[6]
Multi-Grained Gradual Inference Model for Multimedia Event Extraction , year=
Liu, Yang and Liu, Fang and Jiao, Licheng and Bao, Qianyue and Sun, Long and Li, Shuo and Li, Lingling and Liu, Xu , journal=. Multi-Grained Gradual Inference Model for Multimedia Event Extraction , year=
-
[7]
MMUTF : Multimodal Multimedia Event Argument Extraction with Unified Template Filling
Seeberger, Philipp and Wagner, Dominik and Riedhammer, Korbinian. MMUTF : Multimodal Multimedia Event Argument Extraction with Unified Template Filling. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.381
-
[8]
Proceedings of the AAAI Conference on Artificial Intelligence , author=
Cross-modal Multi-task Learning for Multimedia Event Extraction , volume=. Proceedings of the AAAI Conference on Artificial Intelligence , author=. 2025 , month=. doi:10.1609/aaai.v39i11.33246 , number=
-
[9]
Wang, Xiaoyu and Sun, Tao and Liu, Gengchen and Yang, Zhi and Liu, Jiahui and Xu, Zimeng , title =. 2025 , isbn =. doi:10.1145/3746252.3761235 , booktitle =
-
[10]
Multimedia Event Extraction with LLM Knowledge Editing
Yu, Jiaao and Lin, Yijing and Gao, Zhipeng and Qiu, Xuesong and Rui, Lanlan. Multimedia Event Extraction with LLM Knowledge Editing. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.205
-
[11]
Stepwise Schema-Guided Prompting Framework with Parameter Efficient Instruction Tuning for Multimedia Event Extraction , year=
Chen, Xinrong and Yuan, Xiang and Li, Haochen and Yang, Hang and Wang, Guanyu and Li, Weiping and Mo, Tong , booktitle=. Stepwise Schema-Guided Prompting Framework with Parameter Efficient Instruction Tuning for Multimedia Event Extraction , year=
-
[12]
Proceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence,
Collaborative Multi-LoRA Experts with Achievement-based Multi-Tasks Loss for Unified Multimodal Information Extraction , author =. Proceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence,. 2025 , month =. doi:10.24963/ijcai.2025/772 , url =
-
[13]
RDA: Regularized Domain Adaptation for Multimedia Event Extraction
Zhang, Yuhui and Xu, Yongxiu and Tang, Minghao and Lin, Xinkui and Wang, Yubin and Xu, Hongbo and Gou, Gaopeng. RDA: Regularized Domain Adaptation for Multimedia Event Extraction. Advanced Intelligent Computing Technology and Applications. 2025
2025
-
[14]
Cross-modal event extraction via Visual Event Grounding and Semantic Relation Filling , journal =
Maofu Liu and Bingying Zhou and Huijun Hu and Chen Qiu and Xiaokang Zhang , keywords =. Cross-modal event extraction via Visual Event Grounding and Semantic Relation Filling , journal =. 2025 , issn =. doi:https://doi.org/10.1016/j.ipm.2024.104027 , url =
-
[15]
Maofu Liu and Zhenyi Hu and Bingying Zhou and Huijun Hu and Chen Qiu and Xiaokang Zhang , keywords =. Cross-modal event extraction based on Adaptive Feature Selection and Semantic-Aware Graph , journal =. 2025 , issn =. doi:https://doi.org/10.1016/j.knosys.2025.114038 , url =
-
[16]
Benchmarking and Improving LVLM s on Event Extraction from Multimedia Documents
Xing, Fuyu and Wang, Zimu and Wang, Wei and Zhang, Haiyang. Benchmarking and Improving LVLM s on Event Extraction from Multimedia Documents. Proceedings of the 18th International Natural Language Generation Conference. 2025
2025
-
[17]
Theia: Weakly Supervised Multimodal Event Extraction from Incomplete Data
Moghimifar, Farhad and Shiri, Fatemeh and Nguyen, Van and Li, Yuan-Fang and Haffari, Gholamreza. Theia: Weakly Supervised Multimodal Event Extraction from Incomplete Data. Proceedings of the 13th International Joint Conference on Natural Language Processing and the 3rd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics...
-
[18]
Zhang, Meishan and Fei, Hao and Wang, Bin and Wu, Shengqiong and Cao, Yixin and Li, Fei and Zhang, Min. Recognizing Everything from All Modalities at Once: Grounded Multimodal Universal Information Extraction. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.863
-
[19]
The stages of event extraction
Ahn, David. The stages of event extraction. Proceedings of the Workshop on Annotating and Reasoning about Time and Events. 2006
2006
-
[20]
T ext EE : Benchmark, Reevaluation, Reflections, and Future Challenges in Event Extraction
Huang, Kuan-Hao and Hsu, I-Hung and Parekh, Tanmay and Xie, Zhiyu and Zhang, Zixuan and Natarajan, Prem and Chang, Kai-Wei and Peng, Nanyun and Ji, Heng. T ext EE : Benchmark, Reevaluation, Reflections, and Future Challenges in Event Extraction. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.760
-
[21]
Conference on Computer Vision and Pattern Recognition , year=
Situation Recognition: Visual Semantic Role Labeling for Image Understanding , author=. Conference on Computer Vision and Pattern Recognition , year=
-
[22]
Grounded
Pratt, Sarah and Yatskar, Mark and Weihs, Luca and Farhadi, Ali and Kembhavi, Aniruddha , editor =. Grounded. Computer. 2020 , doi =
2020
-
[23]
Proceedings of the AAAI Conference on Artificial Intelligence , author=
Image Enhanced Event Detection in News Articles , volume=. Proceedings of the AAAI Conference on Artificial Intelligence , author=. 2020 , month=. doi:10.1609/aaai.v34i05.6437 , number=
-
[24]
Zhang, Tongtao and Whitehead, Spencer and Zhang, Hanwang and Li, Hongzhi and Ellis, Joseph and Huang, Lifu and Liu, Wei and Ji, Heng and Chang, Shih-Fu , title =. 2017 , isbn =. doi:10.1145/3123266.3123294 , booktitle =
-
[25]
Entity, Relation, and Event Extraction with Contextualized Span Representations
Wadden, David and Wennberg, Ulme and Luan, Yi and Hajishirzi, Hannaneh. Entity, Relation, and Event Extraction with Contextualized Span Representations. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019. doi:10.18653/v1/D19-1585
-
[26]
The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Sadhu, Arka and Gupta, Tanmay and Yatskar, Mark and Nevatia, Ram and Kembhavi, Aniruddha , title =. The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , month =
-
[27]
Wang, Bin and Zhang, Meishan and Fei, Hao and Zhao, Yu and Li, Bobo and Wu, Shengqiong and Ji, Wei and Zhang, Min , title =. 2024 , isbn =. doi:10.1145/3664647.3680669 , booktitle =
-
[28]
Joint Multimedia Event Extraction from Video and Article
Chen, Brian and Lin, Xudong and Thomas, Christopher and Li, Manling and Yoshida, Shoya and Chum, Lovish and Ji, Heng and Chang, Shih-Fu. Joint Multimedia Event Extraction from Video and Article. Findings of the Association for Computational Linguistics: EMNLP 2021. 2021. doi:10.18653/v1/2021.findings-emnlp.8
-
[29]
Grounding Partially-Defined Events in Multimodal Data
Sanders, Kate and Kriz, Reno and Etter, David and Recknor, Hannah and Martin, Alexander and Carpenter, Cameron and Lin, Jingyang and Van Durme, Benjamin. Grounding Partially-Defined Events in Multimodal Data. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.934
-
[30]
The Devil is in the Details: On the Pitfalls of Event Extraction Evaluation
Peng, Hao and Wang, Xiaozhi and Yao, Feng and Zeng, Kaisheng and Hou, Lei and Li, Juanzi and Liu, Zhiyuan and Shen, Weixing. The Devil is in the Details: On the Pitfalls of Event Extraction Evaluation. Findings of the Association for Computational Linguistics: ACL 2023. 2023. doi:10.18653/v1/2023.findings-acl.586
-
[31]
Revisiting the Evaluation of End-to-end Event Extraction
Zheng, Shun and Cao, Wei and Xu, Wei and Bian, Jiang. Revisiting the Evaluation of End-to-end Event Extraction. Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021. 2021. doi:10.18653/v1/2021.findings-acl.405
-
[32]
O mni E vent: A Comprehensive, Fair, and Easy-to-Use Toolkit for Event Understanding
Peng, Hao and Wang, Xiaozhi and Yao, Feng and Wang, Zimu and Zhu, Chuzhao and Zeng, Kaisheng and Hou, Lei and Li, Juanzi. O mni E vent: A Comprehensive, Fair, and Easy-to-Use Toolkit for Event Understanding. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. 2023. doi:10.18653/v1/2023.emnlp-demo.46
-
[33]
Cross-Modal Contrastive Learning for Event Extraction
Wang, Shuo and Ju, Meizhi and Zhang, Yunyan and Zheng, Yefeng and Wang, Meng and Qi, Guilin. Cross-Modal Contrastive Learning for Event Extraction. Database Systems for Advanced Applications. 2023
2023
-
[34]
doi:10.35111/MWXC-VH88 , urldate =
2006 , note =. doi:10.35111/MWXC-VH88 , urldate =
-
[35]
From Light to Rich ERE : Annotation of Entities, Relations, and Events
Song, Zhiyi and Bies, Ann and Strassel, Stephanie and Riese, Tom and Mott, Justin and Ellis, Joe and Wright, Jonathan and Kulick, Seth and Ryant, Neville and Ma, Xiaoyi. From Light to Rich ERE : Annotation of Entities, Relations, and Events. Proceedings of the 3rd Workshop on EVENTS : Definition, Detection, Coreference, and Representation. 2015. doi:10.31...
-
[36]
MAVEN : A M assive G eneral D omain E vent D etection D ataset
Wang, Xiaozhi and Wang, Ziqi and Han, Xu and Jiang, Wangyi and Han, Rong and Liu, Zhiyuan and Li, Juanzi and Li, Peng and Lin, Yankai and Zhou, Jie. MAVEN : A M assive G eneral D omain E vent D etection D ataset. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020. doi:10.18653/v1/2020.emnlp-main.129
-
[37]
and Blanchard, Nathaniel and Krishnaswamy, Nikhil
Nath, Abhijnan and Jamil, Huma and Ahmed, Shafiuddin Rehan and Baker, George Arthur and Ghosh, Rahul and Martin, James H. and Blanchard, Nathaniel and Krishnaswamy, Nikhil. Multimodal Cross-Document Event Coreference Resolution Using Linear Semantic Transfer and Mixed-Modality Ensembles. Proceedings of the 2024 Joint International Conference on Computatio...
2024
-
[38]
2023 , eprint=
Multimodal Question Answering for Unified Information Extraction , author=. 2023 , eprint=
2023
-
[39]
Three Stream Based Multi-level Event Contrastive Learning for Text-Video Event Extraction
Li, Jiaqi and Zhang, Chuanyi and Du, Miaozeng and Min, Dehai and Chen, Yongrui and Qi, Guilin. Three Stream Based Multi-level Event Contrastive Learning for Text-Video Event Extraction. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.103
-
[40]
Transformers: State-of-the-Art Natural Language Processing
Wolf, Thomas and Debut, Lysandre and Sanh, Victor and Chaumond, Julien and Delangue, Clement and Moi, Anthony and Cistac, Pierric and Rault, Tim and Louf, Remi and Funtowicz, Morgan and Davison, Joe and Shleifer, Sam and von Platen, Patrick and Ma, Clara and Jernite, Yacine and Plu, Julien and Xu, Canwen and Le Scao, Teven and Gugger, Sylvain and Drame, M...
-
[41]
BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding
Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina. BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding. Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019. doi:10.18653/v...
-
[42]
Learning Transferable Visual Models From Natural Language Supervision
Radford, Alec and Kim, Jong Wook and Hallacy, Chris and Ramesh, Aditya and Goh, Gabriel and Agarwal, Sandhini and Sastry, Girish and Askell, Amanda and Mishkin, Pamela and Clark, Jack and Krueger, Gretchen and Sutskever, Ilya , year =. Learning. doi:10.48550/ARXIV.2103.00020 , urldate =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2103.00020
-
[43]
International Journal of Computer Vision , author =
The. International Journal of Computer Vision , author =. 2020 , pages =. doi:10.1007/s11263-020-01316-z , language =
-
[44]
Lawrence
Lin, Tsung-Yi and Maire, Michael and Belongie, Serge and Hays, James and Perona, Pietro and Ramanan, Deva and Doll \'a r, Piotr and Zitnick, C. Lawrence. Microsoft COCO: Common Objects in Context. Computer Vision -- ECCV 2014. 2014
2014
-
[45]
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks , url =
Ren, Shaoqing and He, Kaiming and Girshick, Ross and Sun, Jian , booktitle =. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks , url =
-
[46]
You Only Look Once: Unified, Real-Time Object Detection , year=
Redmon, Joseph and Divvala, Santosh and Girshick, Ross and Farhadi, Ali , booktitle=. You Only Look Once: Unified, Real-Time Object Detection , year=
-
[47]
YOLOv8: A Novel Object Detection Algorithm with Enhanced Performance and Robustness , year=
Varghese, Rejin and M., Sambath , booktitle=. YOLOv8: A Novel Object Detection Algorithm with Enhanced Performance and Robustness , year=
-
[48]
The Hungarian method for the assignment problem
The. Naval Research Logistics Quarterly , author =. 1955 , pages =. doi:10.1002/nav.3800020109 , language =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.