Less is More: Efficient Black-box Attribution via Minimal Interpretable Subset Selection
Pith reviewed 2026-05-22 21:26 UTC · model grok-4.3
The pith
Reformulating black-box attribution as submodular subset selection identifies key input regions more faithfully using fewer samples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LiMA reformulates the attribution of important regions as an optimization problem for submodular subset selection. First, a submodular function is designed to quantify subset importance and capture their impact on decision outcomes. Then, a bidirectional greedy search algorithm efficiently ranks input sub-regions by importance, identifying both the most and least important samples while ensuring an optimal attribution boundary that minimizes errors.
What carries the argument
The submodular function that quantifies subset importance together with the bidirectional greedy search algorithm for ranking and selecting minimal interpretable input regions.
If this is right
- Provides faithful interpretations with fewer regions across eight foundation models.
- Achieves an average 36.3 percent improvement in Insertion and 39.6 percent in Deletion metrics.
- Runs 1.6 times faster than naive greedy search for attribution.
- Yields 86.1 percent higher average highest confidence when explaining reasons for model prediction errors.
Where Pith is reading between the lines
- The bidirectional search might be adapted to locate minimal subsets that preserve or remove specific model behaviors for targeted debugging.
- If the submodular scoring generalizes, the same machinery could apply to other discrete inputs such as tokenized text sequences.
- Identifying least-important regions could support data pruning experiments that test whether removing them leaves model accuracy intact.
Load-bearing premise
The submodular function designed to quantify subset importance accurately captures the true impact on decision outcomes without requiring post-hoc tuning or data-specific adjustments.
What would settle it
On a new set of foundation models or image datasets, the insertion and deletion faithfulness scores of LiMA would fail to exceed those of prior attribution methods while using fewer regions.
Figures











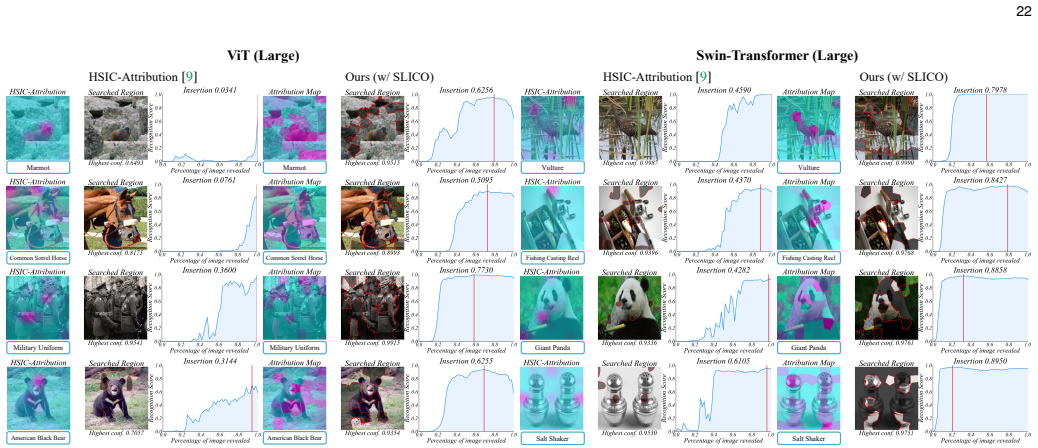
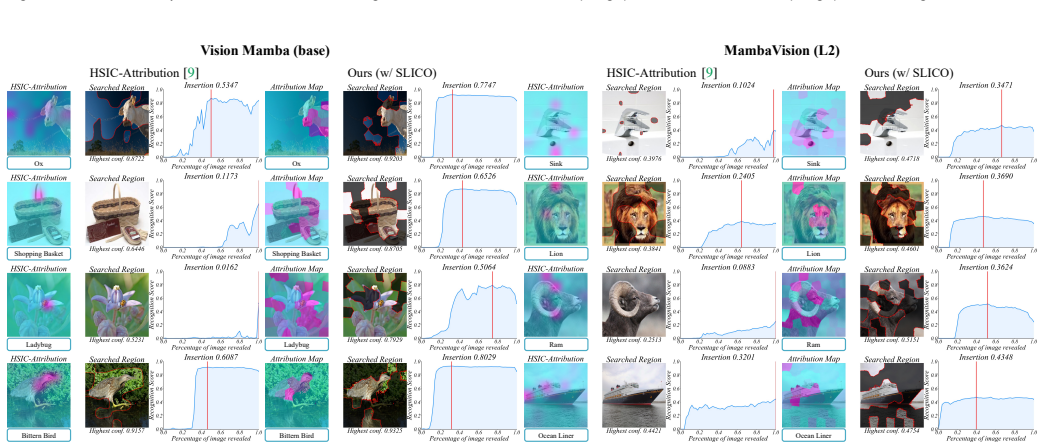
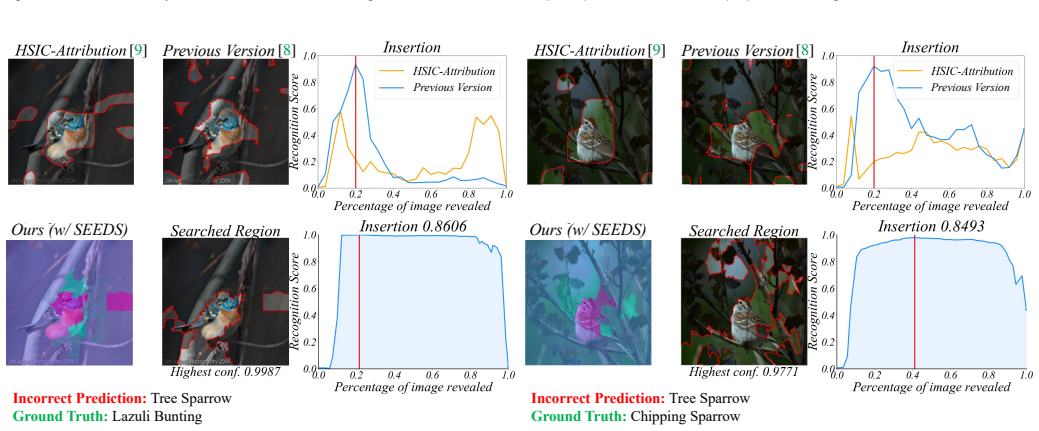

read the original abstract
To develop a trustworthy AI system, which aim to identify the input regions that most influence the models decisions. The primary task of existing attribution methods lies in efficiently and accurately identifying the relationships among input-prediction interactions. Particularly when the input data is discrete, such as images, analyzing the relationship between inputs and outputs poses a significant challenge due to the combinatorial explosion. In this paper, we propose a novel and efficient black-box attribution mechanism, LiMA (Less input is More faithful for Attribution), which reformulates the attribution of important regions as an optimization problem for submodular subset selection. First, to accurately assess interactions, we design a submodular function that quantifies subset importance and effectively captures their impact on decision outcomes. Then, efficiently ranking input sub-regions by their importance for attribution, we improve optimization efficiency through a novel bidirectional greedy search algorithm. LiMA identifies both the most and least important samples while ensuring an optimal attribution boundary that minimizes errors. Extensive experiments on eight foundation models demonstrate that our method provides faithful interpretations with fewer regions and exhibits strong generalization, shows an average improvement of 36.3% in Insertion and 39.6% in Deletion. Our method also outperforms the naive greedy search in attribution efficiency, being 1.6 times faster. Furthermore, when explaining the reasons behind model prediction errors, the average highest confidence achieved by our method is, on average, 86.1% higher than that of state-of-the-art attribution algorithms. The code is available at https://github.com/RuoyuChen10/LIMA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes LiMA, a black-box attribution method that reformulates identifying influential input regions as a submodular subset selection optimization problem. It introduces a custom submodular function to quantify subset importance for model decisions and a bidirectional greedy search algorithm to efficiently find both most- and least-important regions while defining an optimal attribution boundary. Experiments on eight foundation models report average gains of 36.3% on Insertion and 39.6% on Deletion metrics versus baselines, 1.6x speedup over naive greedy search, and 86.1% higher confidence on error explanations, with code released.
Significance. If the submodular function is verifiably monotone submodular and the empirical gains are robust, the approach could advance efficient, faithful black-box explanations for discrete inputs like images by using fewer regions and providing both positive and negative attributions. The code release and multi-model evaluation are positive factors supporting reproducibility and generalization claims.
major comments (3)
- [§3 (submodular function definition)] The design of the submodular function (abstract and §3) is asserted to quantify subset importance and capture decision impact, yet no formal proof of monotonicity or the diminishing-returns property is supplied, nor is there empirical verification on the model output surface. This is load-bearing because the bidirectional greedy algorithm's (1-1/e) approximation guarantee depends on it; without verification the reported metric gains and 'optimal attribution boundary' become purely empirical rather than theoretically supported.
- [§4 (experiments)] Experimental results (abstract and §4) report average improvements of 36.3% Insertion / 39.6% Deletion and 1.6x speedup without error bars, standard deviations, or statistical significance tests across the eight models. This weakens the strength of the generalization and efficiency claims.
- [§4 (experiments and algorithm)] No ablation is presented on the bidirectional search versus standard greedy or on how parameters of the submodular function were selected (abstract states 'design a submodular function' but provides no tuning details or sensitivity analysis). This leaves open whether the gains are driven by the specific search procedure or by implicit data-specific adjustments.
minor comments (2)
- [Abstract] Abstract contains grammatical issues ('which aim to identify' should be 'which aims to identify'; repeated 'on average' in the error-explanation sentence).
- [§3] Notation for the submodular function and the bidirectional search steps could be clarified with explicit pseudocode or a small worked example to improve readability.
Simulated Author's Rebuttal
We appreciate the referee's thorough review and valuable suggestions for improving the theoretical and empirical aspects of our work. Below, we provide point-by-point responses to the major comments.
read point-by-point responses
-
Referee: [§3 (submodular function definition)] The design of the submodular function (abstract and §3) is asserted to quantify subset importance and capture decision impact, yet no formal proof of monotonicity or the diminishing-returns property is supplied, nor is there empirical verification on the model output surface. This is load-bearing because the bidirectional greedy algorithm's (1-1/e) approximation guarantee depends on it; without verification the reported metric gains and 'optimal attribution boundary' become purely empirical rather than theoretically supported.
Authors: We recognize that the absence of a formal proof for the monotonicity and diminishing returns properties of our submodular function, as well as empirical verification, limits the theoretical support for the approximation guarantee. We will revise Section 3 to include a formal mathematical proof establishing these properties and add empirical analysis verifying the submodular behavior on the model outputs. This will strengthen the connection between the algorithm's guarantees and the reported performance improvements. revision: yes
-
Referee: [§4 (experiments)] Experimental results (abstract and §4) report average improvements of 36.3% Insertion / 39.6% Deletion and 1.6x speedup without error bars, standard deviations, or statistical significance tests across the eight models. This weakens the strength of the generalization and efficiency claims.
Authors: We agree that reporting without error bars or statistical tests reduces the robustness of our claims. In the revised version, we will update the experimental results in Section 4 to include error bars, standard deviations across the eight models, and statistical significance tests to validate the average improvements of 36.3% on Insertion and 39.6% on Deletion, as well as the speedup. revision: yes
-
Referee: [§4 (experiments and algorithm)] No ablation is presented on the bidirectional search versus standard greedy or on how parameters of the submodular function were selected (abstract states 'design a submodular function' but provides no tuning details or sensitivity analysis). This leaves open whether the gains are driven by the specific search procedure or by implicit data-specific adjustments.
Authors: We will incorporate ablations in the revised manuscript to compare the bidirectional greedy search against the standard greedy algorithm, quantifying the efficiency benefits. Additionally, we will provide details on the selection of parameters for the submodular function and include a sensitivity analysis to demonstrate that the performance gains are not due to data-specific tuning. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper reformulates black-box attribution as a submodular subset selection optimization problem and introduces a custom submodular function plus bidirectional greedy search as explicit algorithmic contributions. Performance claims (36.3% Insertion / 39.6% Deletion gains, 1.6x speed-up) are obtained by direct comparison against external baselines on eight foundation models rather than by algebraic reduction of fitted parameters or self-citations. No load-bearing step equates a derived quantity to its own inputs by construction, and the central optimization framework remains independent of the reported empirical outcomes.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A submodular function can be defined that accurately quantifies the importance of input subsets for model decisions.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
We construct our objective function ... F(S) = λ1 scons + λ2 scolla + λ3 sconf + λ4 seff (Eq. 8). Lemma 1 (Diminishing returns) ... Lemma 2 (Monotonically non-decreasing).
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Bidirectional greedy search algorithm ... optimality bound F(S) ≥ (1-1/e-ε) F(S*) (Theorem 1)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
A. Troncoso-Garc ´ıa, M. Mart´ınez-Ballesteros, F. Mart´ınez-´Alvarez, and A. Troncoso, “A new metric based on association rules to assess feature- attribution explainability techniques for time series forecasting,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025. 1
work page 2025
-
[2]
Towards human-centered ex- plainable ai: A survey of user studies for model explanations,
Y . Rong, T. Leemann, T.-T. Nguyen, L. Fiedler, P. Qian, V . Unhelkar, T. Seidel, G. Kasneci, and E. Kasneci, “Towards human-centered ex- plainable ai: A survey of user studies for model explanations,” IEEE Transactions on Pattern Analysis and Machine Intelligence , vol. 46, no. 4, pp. 2104–2122, 2024. 1
work page 2024
-
[3]
Explainable deep learning methods in medical image classification: A survey,
C. Patr ´ıcio, J. C. Neves, and L. F. Teixeira, “Explainable deep learning methods in medical image classification: A survey,” ACM Computing Surveys, vol. 56, no. 4, pp. 1–41, 2023. 1
work page 2023
-
[4]
A. B. Arrieta, N. D ´ıaz-Rodr´ıguez, J. Del Ser, A. Bennetot, S. Tabik, A. Barbado, S. Garc ´ıa, S. Gil-L ´opez, D. Molina, R. Benjamins et al. , “Explainable Artificial Intelligence (XAI): Concepts, taxonomies, op- portunities and challenges toward responsible ai,” Information fusion , vol. 58, pp. 82–115, 2020. 1 16
work page 2020
-
[5]
R. Chen, J. Li, H. Zhang, C. Sheng, L. Liu, and X. Cao, “Sim2Word: Explaining similarity with representative attribute words via counter- factual explanations,” ACM Transactions on Multimedia Computing, Communications and Applications, vol. 19, no. 6, pp. 1–22, 2023. 1
work page 2023
-
[6]
Going beyond XAI: A systematic survey for explanation-guided learning,
Y . Gao, S. Gu, J. Jiang, S. R. Hong, D. Yu, and L. Zhao, “Going beyond XAI: A systematic survey for explanation-guided learning,”ACM Computing Surveys, vol. 56, no. 7, pp. 1–39, 2024. 1
work page 2024
-
[7]
End-to-end autonomous driving: Challenges and frontiers,
L. Chen, P. Wu, K. Chitta, B. Jaeger, A. Geiger, and H. Li, “End-to-end autonomous driving: Challenges and frontiers,” IEEE Transactions on Pattern Analysis and Machine Intelligence , vol. 46, no. 12, pp. 10 164– 10 183, 2024. 1
work page 2024
-
[8]
Less is more: Fewer interpretable region via submodular subset selection,
R. Chen, H. Zhang, S. Liang, J. Li, and X. Cao, “Less is more: Fewer interpretable region via submodular subset selection,” in ICLR, 2024. 1, 2, 3, 4, 5, 9, 10, 11, 12, 14, 19, 22
work page 2024
-
[9]
Making sense of dependence: Ef- ficient black-box explanations using dependence measure,
P. Novello, T. Fel, and D. Vigouroux, “Making sense of dependence: Ef- ficient black-box explanations using dependence measure,” in NeurIPS, 2022, pp. 4344–4357. 1, 3, 9, 10, 11, 12, 13, 14, 19, 21, 22, 23
work page 2022
-
[10]
Unifying fourteen post-hoc attribution methods with tay- lor interactions,
H. Deng, N. Zou, M. Du, W. Chen, G. Feng, Z. Yang, Z. Li, and Q. Zhang, “Unifying fourteen post-hoc attribution methods with tay- lor interactions,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024. 1, 7
work page 2024
-
[11]
Interpreting object-level foundation models via visual precision search,
R. Chen, S. Liang, J. Li, S. Liu, M. Li, Z. Huang, H. Zhang, and X. Cao, “Interpreting object-level foundation models via visual precision search,” arXiv preprint arXiv:2411.16198, 2024. 1
-
[12]
Illuminating salient contributions in neuron activation with attribution equilibrium,
W.-J. Nam and S.-W. Lee, “Illuminating salient contributions in neuron activation with attribution equilibrium,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 47, no. 2, pp. 1120–1131, 2025. 1
work page 2025
-
[13]
Local interpretations for explainable natural language processing: A survey,
S. Luo, H. Ivison, S. C. Han, and J. Poon, “Local interpretations for explainable natural language processing: A survey,” ACM Computing Surveys, vol. 56, no. 9, pp. 1–36, 2024. 1
work page 2024
-
[14]
A review and benchmark of feature importance methods for neural networks,
H. Mandler and B. Weigand, “A review and benchmark of feature importance methods for neural networks,” ACM Computing Surveys , vol. 56, no. 12, pp. 1–30, 2024. 1
work page 2024
-
[15]
Explainable ai (xai): Core ideas, techniques, and solutions,
R. Dwivedi, D. Dave, H. Naik, S. Singhal, R. Omer, P. Patel, B. Qian, Z. Wen, T. Shah, G. Morgan et al. , “Explainable ai (xai): Core ideas, techniques, and solutions,” ACM Computing Surveys, vol. 55, no. 9, pp. 1–33, 2023. 1
work page 2023
-
[16]
On pixel-wise explanations for non-linear classifier decisions by layer-wise relevance propagation,
S. Bach, A. Binder, G. Montavon, F. Klauschen, K.-R. M ¨uller, and W. Samek, “On pixel-wise explanations for non-linear classifier decisions by layer-wise relevance propagation,” PloS One , vol. 10, no. 7, p. e0130140, 2015. 1, 3
work page 2015
-
[17]
Axiomatic attribution for deep networks,
M. Sundararajan, A. Taly, and Q. Yan, “Axiomatic attribution for deep networks,” in ICML, 2017, pp. 3319–3328. 1, 3, 9, 10, 11, 12, 13, 18
work page 2017
-
[18]
Grad-CAM: Visual explanations from deep networks via gradient-based localization,
R. R. Selvaraju, M. Cogswell, A. Das, R. Vedantam, D. Parikh, and D. Batra, “Grad-CAM: Visual explanations from deep networks via gradient-based localization,” International Journal of Computer Vision , vol. 128, no. 2, pp. 336–359, 2020. 1, 3, 11, 12
work page 2020
-
[19]
iGOS++: integrated gradient optimized saliency by bilateral perturbations,
S. Khorram, T. Lawson, and L. Fuxin, “iGOS++: integrated gradient optimized saliency by bilateral perturbations,” in CHIL, 2021, pp. 174–
work page 2021
-
[20]
Gradient- based visual explanation for transformer-based clip,
C. Zhao, K. Wang, X. Zeng, R. Zhao, and A. B. Chan, “Gradient- based visual explanation for transformer-based clip,” in ICML, 2024, pp. 61 072–61 091. 1, 3, 9, 10, 12, 13
work page 2024
-
[21]
A unified approach to interpreting model predictions,
S. M. Lundberg and S.-I. Lee, “A unified approach to interpreting model predictions,” in NeurIPS, 2017, pp. 4765–4774. 1, 3, 10, 11, 12, 13, 14
work page 2017
-
[22]
Explain any concept: Segment anything meets concept-based explanation,
A. Sun, P. Ma, Y . Yuan, and S. Wang, “Explain any concept: Segment anything meets concept-based explanation,” in NeurIPS, 2023. 1, 3, 10, 11, 12, 13
work page 2023
-
[23]
RISE: Randomized input sampling for explanation of black-box models,
V . Petsiuk, A. Das, and K. Saenko, “RISE: Randomized input sampling for explanation of black-box models,” in BMVC, 2018, p. 151. 1, 3, 5, 9, 10, 11, 12, 13, 14, 19, 21
work page 2018
-
[24]
Defining and extracting generalizable interaction primitives from dnns,
L. Chen, S. Lou, B. Huang, and Q. Zhang, “Defining and extracting generalizable interaction primitives from dnns,” in ICLR, 2024. 1, 6, 7
work page 2024
-
[25]
Towards the difficulty for a deep neural network to learn concepts of different complexities,
D. Liu, H. Deng, X. Cheng, Q. Ren, K. Wang, and Q. Zhang, “Towards the difficulty for a deep neural network to learn concepts of different complexities,” in NeurIPS, 2023, pp. 41 283–41 304. 1
work page 2023
-
[26]
Fujishige, Submodular functions and optimization
S. Fujishige, Submodular functions and optimization. Elsevier, 2005. 1, 4, 6
work page 2005
-
[27]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark et al., “Learning transferable visual models from natural language supervision,” in ICML, 2021, pp. 8748–8763. 2, 8, 9, 10, 11, 12, 19
work page 2021
-
[28]
ImageBind: One embedding space to bind them all,
R. Girdhar, A. El-Nouby, Z. Liu, M. Singh, K. V . Alwala, A. Joulin, and I. Misra, “ImageBind: One embedding space to bind them all,” in CVPR, 2023, pp. 15 180–15 190. 2, 8, 9, 10, 12, 13, 19
work page 2023
-
[29]
B. Zhu, B. Lin, M. Ning, Y . Yan, J. Cui, W. HongFa, Y . Pang, W. Jiang, J. Zhang, Z. Li et al. , “LanguageBind: Extending video-language pre- training to n-modality by language-based semantic alignment,” in ICLR,
-
[30]
2, 8, 9, 10, 12, 13, 19
-
[31]
Quilt-1M: One million image- text pairs for histopathology,
W. Ikezogwo, S. Seyfioglu, F. Ghezloo, D. Geva, F. Sheikh Mohammed, P. K. Anand, R. Krishna, and L. Shapiro, “Quilt-1M: One million image- text pairs for histopathology,” in NeurIPS, 2024, pp. 37 995–38 017. 2, 8, 13
work page 2024
-
[32]
ImageNet: A large-scale hierarchical image database,
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “ImageNet: A large-scale hierarchical image database,” inCVPR, 2009, pp. 248–255. 2, 8, 12
work page 2009
-
[33]
VGGSound: A large- scale audio-visual dataset,
H. Chen, W. Xie, A. Vedaldi, and A. Zisserman, “VGGSound: A large- scale audio-visual dataset,” in ICASSP, 2020, pp. 721–725. 2, 8, 12
work page 2020
-
[34]
Caltech-UCSD Birds 200. Technical Report CNS-TR- 2010–001,
P. Welinder, S. Branson, T. Mita, C. Wah, F. Schroff, S. Be-longie, and P. Perona, “Caltech-UCSD Birds 200. Technical Report CNS-TR- 2010–001,” Technical Report CNS-TR-2010–001, California Institute of Technology, 2010. 1, Tech. Rep., 2010. 2, 8, 12, 14
work page 2010
-
[35]
Deep learning face attributes in the wild,
Z. Liu, P. Luo, X. Wang, and X. Tang, “Deep learning face attributes in the wild,” in ICCV, 2015, pp. 3730–3738. 2, 8
work page 2015
-
[36]
VGGFace2: A dataset for recognising faces across pose and age,
Q. Cao, L. Shen, W. Xie, O. M. Parkhi, and A. Zisserman, “VGGFace2: A dataset for recognising faces across pose and age,” in IEEE International Conference on Automatic Face and Gesture Recognition (FG), 2018, pp. 67–74. 2, 8
work page 2018
-
[37]
Lung and colon cancer histopathological image dataset (LC25000),
A. A. Borkowski, M. M. Bui, L. B. Thomas, C. P. Wilson, L. A. DeLand, and S. M. Mastorides, “Lung and colon cancer histopathological image dataset (LC25000),” arXiv preprint arXiv:1912.12142, 2019. 2, 8, 12
-
[38]
Deep inside convolutional networks: visualising image classification models and saliency maps,
K. Simonyan, A. Vedaldi, and A. Zisserman, “Deep inside convolutional networks: visualising image classification models and saliency maps,” in ICLR (Workshop Poster), 2014. 3, 10, 11, 12
work page 2014
-
[39]
Defining and extracting generalizable interaction primitives from dnns,
L. Chen, S. Lou, B. Huang, and Q. Zhang, “Defining and extracting generalizable interaction primitives from dnns,” in ICLR, 2024. 3
work page 2024
-
[40]
Grad-CAM++: Generalized gradient-based visual explanations for deep convolutional networks,
A. Chattopadhay, A. Sarkar, P. Howlader, and V . N. Balasubramanian, “Grad-CAM++: Generalized gradient-based visual explanations for deep convolutional networks,” in WACV, 2018, pp. 839–847. 3, 14, 23
work page 2018
-
[41]
Score-CAM: Score-weighted visual explanations for con- volutional neural networks,
H. Wang, Z. Wang, M. Du, F. Yang, Z. Zhang, S. Ding, P. Mardziel, and X. Hu, “Score-CAM: Score-weighted visual explanations for con- volutional neural networks,” in CVPR Workshops, 2020, pp. 24–25. 3, 14
work page 2020
-
[42]
ViT-CX: causal explanation of vision transformers,
W. Xie, X.-H. Li, C. C. Cao, and N. L. Zhang, “ViT-CX: causal explanation of vision transformers,” in IJCAI, 2023, pp. 1569–1577. 3, 10, 12, 13
work page 2023
-
[43]
L. S. Shapley, “A value for n-person games,” Annals of Mathematics Studies, vol. 28, pp. 307–318, 1953. 3
work page 1953
-
[44]
Harsanyinet: Computing accurate shapley values in a single forward propagation,
L. Chen, S. Lou, K. Zhang, J. Huang, and Q. Zhang, “Harsanyinet: Computing accurate shapley values in a single forward propagation,” in ICML, 2023, pp. 4804–4825. 3
work page 2023
-
[45]
Problems with shapley-value-based explanations as feature importance measures,
I. E. Kumar, S. Venkatasubramanian, C. Scheidegger, and S. Friedler, “Problems with shapley-value-based explanations as feature importance measures,” in ICML, 2020, pp. 5491–5500. 3, 7
work page 2020
-
[46]
M. T. Ribeiro, S. Singh, and C. Guestrin, “”why should i trust you?” explaining the predictions of any classifier,” inSIGKDD, 2016, pp. 1135–
work page 2016
-
[47]
One explanation is not enough: structured attention graphs for image classification,
V . Shitole, F. Li, M. Kahng, P. Tadepalli, and A. Fern, “One explanation is not enough: structured attention graphs for image classification,” in NeurIPS, 2021, pp. 11 352–11 363. 3
work page 2021
-
[48]
Transformer interpretability beyond attention visualization,
H. Chefer, S. Gur, and L. Wolf, “Transformer interpretability beyond attention visualization,” in CVPR, 2021, pp. 782–791. 3
work page 2021
-
[49]
Vision transformers need registers,
T. Darcet, M. Oquab, J. Mairal, and P. Bojanowski, “Vision transformers need registers,” in ICLR, 2024. 3
work page 2024
-
[50]
Interpreting clip’s image representation via text-based decomposition,
Y . Gandelsman, A. A. Efros, and J. Steinhardt, “Interpreting clip’s image representation via text-based decomposition,” in ICLR, 2024. 3
work page 2024
-
[51]
Discover and cure: Concept-aware mitigation of spurious correlation,
S. Wu, M. Yuksekgonul, L. Zhang, and J. Zou, “Discover and cure: Concept-aware mitigation of spurious correlation,” in ICML, 2023, pp. 37 765–37 786. 4
work page 2023
-
[52]
Meaningfully debugging model mistakes using conceptual counterfactual explanations,
A. Abid, M. Yuksekgonul, and J. Zou, “Meaningfully debugging model mistakes using conceptual counterfactual explanations,” in ICML, 2022, pp. 66–88. 4
work page 2022
-
[53]
V . V . Ramaswamy, S. S. Kim, R. Fong, and O. Russakovsky, “Over- looked factors in concept-based explanations: Dataset choice, concept learnability, and human capability,” in CVPR, 2023, pp. 10 932–10 941. 4
work page 2023
-
[54]
S. Kothawade, S. Ghosh, S. Shekhar, Y . Xiang, and R. Iyer, “Talisman: targeted active learning for object detection with rare classes and slices using submodular mutual information,” in ECCV, 2022, pp. 1–16. 4
work page 2022
-
[55]
Ef- ficient modality selection in multimodal learning,
Y . He, R. Cheng, G. Balasubramaniam, Y .-H. H. Tsai, and H. Zhao, “Ef- ficient modality selection in multimodal learning,” Journal of Machine Learning Research, vol. 25, no. 47, pp. 1–39, 2024. 4 17
work page 2024
-
[56]
Marginal contribution feature importance-an axiomatic approach for explaining data,
A. Catav, B. Fu, Y . Zoabi, A. L. W. Meilik, N. Shomron, J. Ernst, S. Sankararaman, and R. Gilad-Bachrach, “Marginal contribution feature importance-an axiomatic approach for explaining data,” in ICML, 2021, pp. 1324–1335. 4
work page 2021
-
[57]
Stream- ing weak submodularity: Interpreting neural networks on the fly,
E. Elenberg, A. G. Dimakis, M. Feldman, and A. Karbasi, “Stream- ing weak submodularity: Interpreting neural networks on the fly,” in NeurIPS, 2017, pp. 4044–4054. 4
work page 2017
-
[58]
Learning to explain: An information-theoretic perspective on model interpretation,
J. Chen, L. Song, M. Wainwright, and M. Jordan, “Learning to explain: An information-theoretic perspective on model interpretation,” in ICML, 2018, pp. 883–892. 4
work page 2018
-
[59]
Scalable subset sampling with neural conditional poisson networks,
A. Pervez, P. Lippe, and E. Gavves, “Scalable subset sampling with neural conditional poisson networks,” in ICLR, 2023, pp. 1–21. 4
work page 2023
-
[60]
”what data benefits my classifier?
A. Chhabra, P. Li, P. Mohapatra, and H. Liu, “”what data benefits my classifier?” enhancing model performance and interpretability through influence-based data selection,” in ICLR, 2024. 4
work page 2024
-
[61]
An analysis of approximations for maximizing submodular set functions—i,
G. L. Nemhauser, L. A. Wolsey, and M. L. Fisher, “An analysis of approximations for maximizing submodular set functions—i,” Mathe- matical programming, vol. 14, pp. 265–294, 1978. 4
work page 1978
-
[62]
B. Mirzasoleiman, A. Badanidiyuru, A. Karbasi, J. V ondr ´ak, and A. Krause, “Lazier than lazy greedy,” in AAAI, 2015, pp. 1812–1818. 4, 6, 19
work page 2015
-
[63]
Submodular batch selection for training deep neural networks,
K. Joseph, K. Singh, and V . N. Balasubramanian, “Submodular batch selection for training deep neural networks,” in IJCAI, 2019, pp. 2677–
work page 2019
-
[64]
Submodular functions, matroids, and certain polyhedra,
J. Edmonds, “Submodular functions, matroids, and certain polyhedra,” Combinatorial Structures and Their Applications, pp. 69–87, 1970. 4
work page 1970
-
[65]
SLIC superpixels compared to state-of-the-art superpixel methods,
R. Achanta, A. Shaji, K. Smith, A. Lucchi, P. Fua, and S. S ¨usstrunk, “SLIC superpixels compared to state-of-the-art superpixel methods,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 34, no. 11, pp. 2274–2282, 2012. 5, 8
work page 2012
-
[66]
A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y . Lo, P. Dollar, and R. Girshick, “Segment anything,” in ICCV, 2023, pp. 4015–4026. 5, 8, 12, 23
work page 2023
-
[67]
Unsupervised learning of visual representa- tions by solving jigsaw puzzles,
M. Noroozi and P. Favaro, “Unsupervised learning of visual representa- tions by solving jigsaw puzzles,” in ECCV, 2016, pp. 69–84. 5
work page 2016
-
[68]
Learn to threshold: Thresholdnet with confidence-guided manifold mixup for polyp segmentation,
X. Guo, C. Yang, Y . Liu, and Y . Yuan, “Learn to threshold: Thresholdnet with confidence-guided manifold mixup for polyp segmentation,” IEEE Transactions on Medical Imaging , vol. 40, no. 4, pp. 1134–1146, 2020. 5
work page 2020
-
[69]
Test-time prompt tuning for zero-shot generalization in vision-language models,
M. Shu, W. Nie, D.-A. Huang, Z. Yu, T. Goldstein, A. Anandkumar, and C. Xiao, “Test-time prompt tuning for zero-shot generalization in vision-language models,” in NeurIPS, 2022, pp. 14 274–14 289. 5
work page 2022
-
[70]
Handling open-set noise and novel target recognition in domain adaptive semantic segmentation,
X. Guo, J. Liu, T. Liu, and Y . Yuan, “Handling open-set noise and novel target recognition in domain adaptive semantic segmentation,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 8, pp. 9846–9861, 2023. 5
work page 2023
-
[71]
Cosface: Large margin cosine loss for deep face recognition,
H. Wang, Y . Wang, Z. Zhou, X. Ji, D. Gong, J. Zhou, Z. Li, and W. Liu, “Cosface: Large margin cosine loss for deep face recognition,” in CVPR, 2018, pp. 5265–5274. 6
work page 2018
-
[72]
Arcface: Additive angular margin loss for deep face recognition,
J. Deng, J. Guo, N. Xue, and S. Zafeiriou, “Arcface: Additive angular margin loss for deep face recognition,” in CVPR, 2019, pp. 4690–4699. 6, 8
work page 2019
-
[73]
Submodularity in data subset selection and active learning,
K. Wei, R. Iyer, and J. Bilmes, “Submodularity in data subset selection and active learning,” in ICML, 2015, pp. 1954–1963. 6
work page 2015
-
[74]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in CVPR, 2016, pp. 770–778. 8, 10, 11, 14, 19
work page 2016
-
[75]
An image is worth 16x16 words: Transformers for image recognition at scale,
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly et al., “An image is worth 16x16 words: Transformers for image recognition at scale,” in ICLR, 2021. 8, 11
work page 2021
-
[76]
Swin transformer: Hierarchical vision transformer using shifted win- dows,
Z. Liu, Y . Lin, Y . Cao, H. Hu, Y . Wei, Z. Zhang, S. Lin, and B. Guo, “Swin transformer: Hierarchical vision transformer using shifted win- dows,” in ICCV, 2021, pp. 10 012–10 022. 8, 11, 19
work page 2021
-
[77]
Vision mamba: Efficient visual representation learning with bidirectional state space model,
L. Zhu, B. Liao, Q. Zhang, X. Wang, W. Liu, and X. Wang, “Vision mamba: Efficient visual representation learning with bidirectional state space model,” in ICML, 2024. 8, 11, 19
work page 2024
-
[78]
MambaVision: A hybrid mamba- transformer vision backbone,
A. Hatamizadeh and J. Kautz, “MambaVision: A hybrid mamba- transformer vision backbone,” arXiv preprint arXiv:2407.08083 , 2024. 8, 11, 19
-
[79]
MobileNetV2: Inverted residuals and linear bottlenecks,
M. Sandler, A. Howard, M. Zhu, A. Zhmoginov, and L.-C. Chen, “MobileNetV2: Inverted residuals and linear bottlenecks,” in CVPR, 2018, pp. 4510–4520. 8, 14
work page 2018
-
[80]
EfficientNetV2: Smaller models and faster training,
M. Tan and Q. Le, “EfficientNetV2: Smaller models and faster training,” in ICML, 2021, pp. 10 096–10 106. 8, 14
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.