FlashbackCL: Mitigating Temporal Forgetting in Federated Learning
Pith reviewed 2026-06-28 11:00 UTC · model grok-4.3
The pith
FlashbackCL extends Flashback with temporally decayed label counts and class-balanced replay to cut temporal forgetting in federated learning by up to 68 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
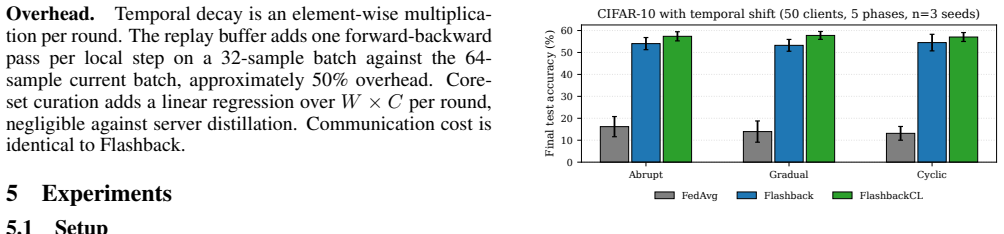
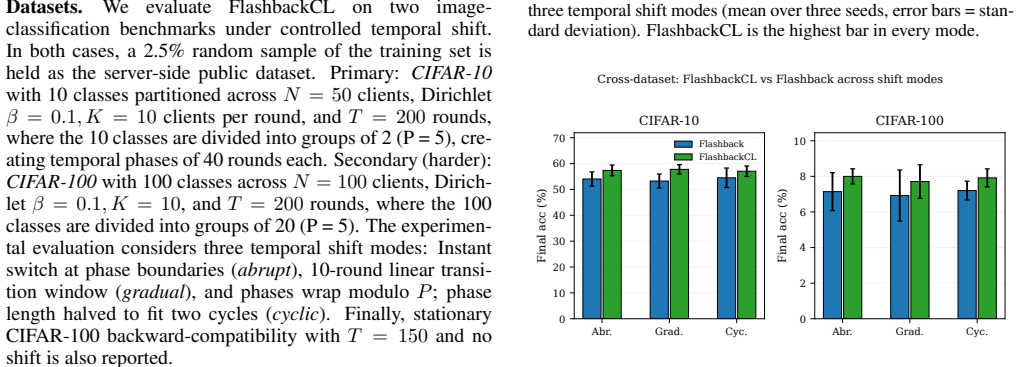
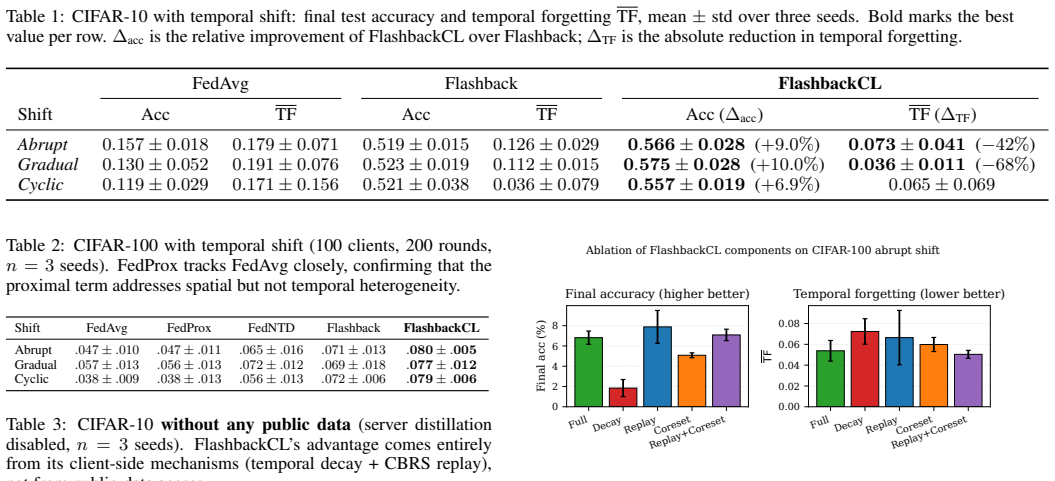
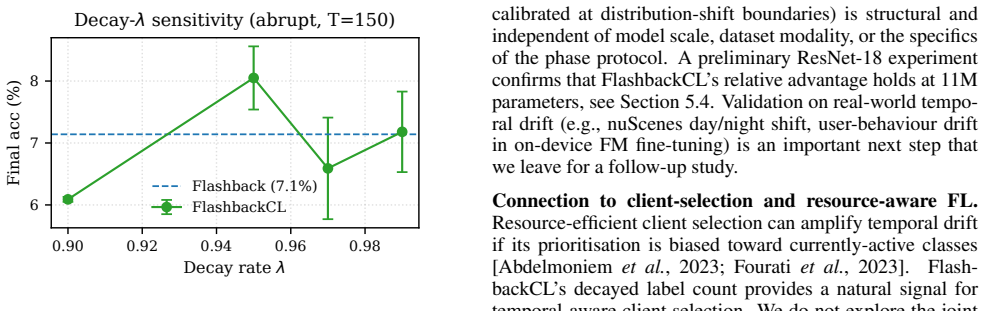
FlashbackCL formalizes temporal forgetting in federated learning with a per-phase metric and extends Flashback via temporally-decayed label counts, a device-aware replay buffer using Class-Balanced Reservoir Sampling, and server-side active coreset curation. These changes deliver 6.9 to 10.0 percent relative accuracy gains on CIFAR-10 under temporal shifts while reducing temporal forgetting by up to 68 percent, with the replay component identified as critical in ablation.
What carries the argument
FlashbackCL, the drop-in extension of Flashback that replaces monotonic label counts with temporally decayed counts, adds a device-aware replay buffer with Class-Balanced Reservoir Sampling, and applies server-side coreset curation to handle temporal distribution shift.
If this is right
- Accuracy on CIFAR-10 with 50 clients improves 6.9 to 10.0 percent relative to Flashback under three controlled temporal shift modes.
- Temporal forgetting drops by up to 68 percent on the same benchmark.
- FlashbackCL also raises Flashback performance by 3.5 points on stationary CIFAR-100.
- Class-Balanced Reservoir Sampling replay is the critical component according to the five-variant ablation.
Where Pith is reading between the lines
- The same decay-plus-replay pattern could be added to other federated forgetting mitigators that rely on label-count proxies.
- If the controlled shifts match real drift, the method could reduce the need for frequent global retraining in long-running federated systems.
- Class-balanced replay may regularize spatial heterogeneity even without temporal change, as hinted by the stationary-data result.
- Adaptive rather than fixed decay rates could be tested by monitoring observed client drift at the server.
Load-bearing premise
The three controlled temporal shift modes used in the CIFAR-10 experiments accurately represent the kinds of distribution drift that arise in real federated deployments.
What would settle it
Running FlashbackCL on a dataset collected from actual edge devices over multiple months and checking whether the reported accuracy gains and forgetting reduction persist under naturally occurring shifts.
Figures
read the original abstract
Federated Learning (FL) of foundation and edge models increasingly targets deployments where client data distributions drift over time, yet existing forgetting-mitigation methods assume each client's distribution is stationary. Flashback, the strongest recent FL method against cross-client (spatial) forgetting, uses monotonically accumulating per-class label counts as a knowledge proxy; this proxy becomes miscalibrated under temporal distribution shift and anchors the global model to an outdated class balance. We formalise temporal forgetting in FL with a per-phase metric isolated from protocol-level fluctuations and propose Flashback Continual Learning (FlashbackCL), a drop-in extension of Flashback with (i) temporally-decayed label counts; (ii) a device-aware replay buffer with Class-Balanced Reservoir Sampling (CBRS); and (iii) server-side active coreset curation on the public distillation set. The results show that FlashbackCL achieves 6.9% to 10.0% relative improvement relative to Flashback, on CIFAR-10 with 50 clients and three controlled temporal shift modes, while simultaneously reducing temporal forgetting by up to 68%. A 5-variant ablation identifies CBRS replay as the critical component. FlashbackCL also improves Flashback by 3.5 points on stationary CIFAR-100, suggesting that class-balanced replay regularises spatial heterogeneity as well as temporal shift.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents FlashbackCL, a drop-in extension to Flashback for mitigating temporal forgetting in federated learning under non-stationary client distributions. It formalizes temporal forgetting via a per-phase metric isolated from protocol fluctuations and introduces three components: temporally-decayed per-class label counts, a device-aware replay buffer using Class-Balanced Reservoir Sampling (CBRS), and server-side active coreset curation on the public distillation set. On CIFAR-10 with 50 clients across three controlled temporal shift modes, it reports 6.9% to 10.0% relative improvement over Flashback and up to 68% reduction in temporal forgetting; a 5-variant ablation identifies CBRS replay as critical. It also reports a 3.5-point gain over Flashback on stationary CIFAR-100.
Significance. If the results hold, the work addresses a practical gap in federated learning for time-varying client data, which is relevant for edge and foundation model deployments. The per-phase metric and ablation study are clear strengths that help isolate contributions. The incidental improvement on stationary CIFAR-100 suggests the class-balanced replay may also regularize spatial heterogeneity. The empirical nature means significance depends on the representativeness of the controlled shift modes.
major comments (1)
- [Experimental Evaluation] The headline empirical claims (6.9–10.0% relative gain and 68% forgetting reduction) rest entirely on three controlled temporal shift modes whose construction and relation to real federated drifts are not justified with additional validation or discussion. This is load-bearing for the central claim of a general mitigation technique, as stylized shifts (e.g., abrupt class re-balancing) could artifactually favor the proposed decay and reservoir-sampling components.
minor comments (1)
- [Abstract] The abstract states numerical improvements without referencing error bars, statistical tests, or dataset split information; adding these would improve clarity of the results presentation.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our work. We address the major comment point by point below.
read point-by-point responses
-
Referee: [Experimental Evaluation] The headline empirical claims (6.9–10.0% relative gain and 68% forgetting reduction) rest entirely on three controlled temporal shift modes whose construction and relation to real federated drifts are not justified with additional validation or discussion. This is load-bearing for the central claim of a general mitigation technique, as stylized shifts (e.g., abrupt class re-balancing) could artifactually favor the proposed decay and reservoir-sampling components.
Authors: We agree that the manuscript would benefit from additional discussion justifying the choice of the three controlled temporal shift modes and relating them to real federated drifts. These modes were constructed to systematically vary temporal dynamics (abrupt re-balancing, gradual drift, and periodic shifts) while holding client count, protocol, and spatial heterogeneity fixed, which enables the per-phase metric to isolate temporal forgetting as described in Section 3. The controlled setting also supports the 5-variant ablation isolating CBRS. However, we acknowledge that explicit discussion of how these modes map to practical scenarios (e.g., evolving user preferences or seasonal sensor data) and their limitations is currently insufficient. We will revise the paper to add a dedicated paragraph in the experimental setup section providing this justification, referencing related literature on temporal concept drift in FL, and noting that large-scale real non-stationary FL benchmarks remain an open challenge for the community. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper proposes FlashbackCL as an empirical extension of Flashback, introducing temporally-decayed counts, CBRS replay, and server coreset curation, then evaluates relative gains (6.9-10.0%) and forgetting reduction (up to 68%) on CIFAR-10 under controlled shifts plus an ablation. No equations, derivations, or formal predictions are presented that reduce by construction to fitted inputs, self-citations, or ansatzes. The per-phase metric is defined to isolate protocol effects, but remains an empirical reporting choice rather than a self-referential derivation. All load-bearing claims rest on external benchmark comparisons, rendering the chain self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Communication-efficient learning of deep networks from decentralized data
McMahan, Brendan and Moore, Eider and Ramage, Daniel and Hampson, Seth and Arcas, Blaise Aguera y. Communication-efficient learning of deep networks from decentralized data. AISTATS. 2017
2017
-
[2]
Federated Learning: Strategies for Improving Communication Efficiency
Kone c n \' y , Jakub and McMahan, H Brendan and Yu, Felix X and Richt \'a rik, Peter and Suresh, Ananda Theertha and Bacon, Dave. Federated learning: Strategies for improving communication efficiency. arXiv preprint arXiv:1610.05492. 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[3]
Advances and open problems in federated learning
Kairouz, Peter and McMahan, H Brendan and Avent, Brendan and Bellet, Aur \'e lien and Bennis, Mehdi and Bhagoji, Arjun Nitin and Bonawitz, Kallista and others. Advances and open problems in federated learning. Foundations and Trends in Machine Learning. 2021
2021
-
[4]
Federated optimization in heterogeneous networks
Li, Tian and Sahu, Anit Kumar and Zaheer, Manzil and Sanjabi, Maziar and Talwalkar, Ameet and Smith, Virginia. Federated optimization in heterogeneous networks. Proceedings of Machine Learning and Systems. 2020
2020
-
[5]
SCAFFOLD : Stochastic controlled averaging for federated learning
Karimireddy, Sai Praneeth and Kale, Satyen and Mohri, Mehryar and Reddi, Sashank and Stich, Sebastian and Suresh, Ananda Theertha. SCAFFOLD : Stochastic controlled averaging for federated learning. International Conference on Machine Learning. 2020
2020
-
[6]
Model-contrastive federated learning
Li, Qinbin and He, Bingsheng and Song, Dawn. Model-contrastive federated learning. Conference on Computer Vision and Pattern Recognition. 2021
2021
-
[7]
Ensemble distillation for robust model fusion in federated learning
Lin, Tao and Kong, Lingjing and Stich, Sebastian U and Jaggi, Martin. Ensemble distillation for robust model fusion in federated learning. Advances in Neural Information Processing Systems. 2020
2020
-
[8]
and Canini, Marco and Horváth, Samuel , booktitle=
Aljahdali, Mohammed and Abdelmoniem, Ahmed M. and Canini, Marco and Horváth, Samuel , booktitle=. Flashback: Understanding and Mitigating Forgetting in Federated Learning , year=
-
[9]
Continual lifelong learning with neural networks: A review
Parisi, German I and Kemker, Ronald and Part, Jose L and Kanan, Christopher and Wermter, Stefan. Continual lifelong learning with neural networks: A review. Neural Networks. 2019
2019
-
[10]
A continual learning survey: Defying forgetting in classification tasks
De Lange, Matthias and Aljundi, Rahaf and Masana, Marc and Parisot, Sarah and Jia, Xu and Leonardis, Ale s and Slabaugh, Gregory and Tuytelaars, Tinne. A continual learning survey: Defying forgetting in classification tasks. IEEE Transactions on Pattern Analysis and Machine Intelligence. 2021
2021
-
[11]
Preservation of the global knowledge by not-true distillation in federated learning
Lee, Gihun and Jeong, Minchan and Shin, Yongjin and Bae, Sangmin and Yun, Se-Young. Preservation of the global knowledge by not-true distillation in federated learning. Advances in Neural Information Processing Systems. 2022
2022
-
[12]
Acceleration of federated learning with alleviated forgetting in local training
Xu, Chencheng and Hong, Zhiwei and Huang, Minlie and Jiang, Tao. Acceleration of federated learning with alleviated forgetting in local training. arXiv preprint arXiv:2203.02645. 2022
-
[13]
Overcoming catastrophic forgetting in neural networks
Kirkpatrick, James and Pascanu, Razvan and Rabinowitz, Neil and Veness, Joel and Desjardins, Guillaume and Rusu, Andrei A and Milan, Kieran and Quan, John and Ramalho, Tiago and Grabska-Barwinska, Agnieszka and others. Overcoming catastrophic forgetting in neural networks. Proceedings of the National Academy of Sciences. 2017
2017
-
[14]
Learning without forgetting
Li, Zhizhong and Hoiem, Derek. Learning without forgetting. IEEE Transactions on Pattern Analysis and Machine Intelligence. 2017
2017
-
[15]
Riemannian walk for incremental learning: Understanding forgetting and intransigence
Chaudhry, Arslan and Dokania, Puneet K and Ajanthan, Thalaiyasingam and Torr, Philip HS. Riemannian walk for incremental learning: Understanding forgetting and intransigence. Proceedings of the European Conference on Computer Vision (ECCV). 2018
2018
-
[16]
Scalable and order-robust continual learning with additive parameter decomposition
Yoon, Jaehong and Kim, Saehoon and Yang, Eunho and Hwang, Sung Ju. Scalable and order-robust continual learning with additive parameter decomposition. arXiv preprint arXiv:1902.09432. 2020
-
[17]
Federated continual learning with weighted inter-client transfer
Yoon, Jaehong and Jeong, Wonyong and Lee, Giwoong and Yang, Eunho and Hwang, Sung Ju. Federated continual learning with weighted inter-client transfer. International Conference on Machine Learning. 2021
2021
-
[18]
Continual federated learning based on knowledge distillation
Ma, Yuhang and Xie, Zhongle and Wang, Jue and Chen, Ke and Shou, Lidan. Continual federated learning based on knowledge distillation. Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence (IJCAI). 2022
2022
-
[19]
Better generative replay for continual federated learning
Qi, Daiqing and Zhao, Handong and Li, Sheng. Better generative replay for continual federated learning. International Conference on Learning Representations. 2023
2023
-
[20]
Federated class-incremental learning
Dong, Jiahua and Wang, Lixu and Fang, Zhen and Sun, Gan and Xu, Shichao and Wang, Xiao and Zhu, Qi. Federated class-incremental learning. IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022
2022
-
[21]
Federated orthogonal training: Mitigating global catastrophic forgetting in continual federated learning
Bakman, Yavuz and Akyurek, Duygu Nur and Akyurek, Ekin and Lin, Kangwook and Huang, Jingzhao. Federated orthogonal training: Mitigating global catastrophic forgetting in continual federated learning. International Conference on Learning Representations. 2024
2024
-
[22]
Accurate forgetting for heterogeneous federated continual learning
Wuerkaixi, Abudukelimu and Cui, Sen and Zhang, Jingfeng and Yan, Kunda and Han, Bo and Niu, Gang and Fang, Lei and Zhang, Changshui and Sugiyama, Masashi. Accurate forgetting for heterogeneous federated continual learning. International Conference on Learning Representations. 2024
2024
-
[23]
CINIC-10 is not ImageNet or CIFAR-10
Darlow, Luke N and Crowley, Elliot J and Antoniou, Antreas and Storkey, Amos J. CINIC-10 is not ImageNet or CIFAR-10. arXiv preprint arXiv:1810.03505. 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[24]
LEAF : A benchmark for federated settings
Caldas, Sebastian and Duddu, Sai Meher Karthik and Wu, Peter and Li, Tian and Kone c n \' y , Jakub and McMahan, H Brendan and Smith, Virginia and Talwalkar, Ameet. LEAF : A benchmark for federated settings. Workshop on Federated Learning for Data Privacy and Confidentiality. 2019
2019
-
[25]
nu S cenes: A multimodal dataset for autonomous driving
Caesar, Holger and Bankiti, Varun and Lang, Alex H and Vora, Sourabh and Liong, Venice Erin and Xu, Qiang and Krishnan, Anush and Pan, Yu and Baldan, Giancarlo and Beijbom, Oscar. nu S cenes: A multimodal dataset for autonomous driving. IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020
2020
-
[26]
Distilling the Knowledge in a Neural Network
Hinton, Geoffrey and Vinyals, Oriol and Dean, Jeff. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531. 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[27]
Towards federated learning at scale: A system design
Bonawitz, Keith and Eichner, Hubert and Grieskamp, Wolfgang and Huba, Dzmitry and Ingerman, Alex and Ivanov, Vladimir and Kiddon, Chloe and Kone c n \' y , Jakub and Mazzocchi, Stefano and McMahan, Brendan and others. Towards federated learning at scale: A system design. Proceedings of Machine Learning and Systems. 2019
2019
-
[28]
Learning multiple layers of features from tiny images
Krizhevsky, Alex. Learning multiple layers of features from tiny images. Technical report, University of Toronto. 2009
2009
-
[29]
Federated learning with matched averaging
Wang, Hongyi and Yurochkin, Mikhail and Sun, Yuekai and Papailiopoulos, Dimitris and Khazaeni, Yasaman. Federated learning with matched averaging. International Conference on Learning Representations. 2020
2020
-
[30]
Tackling the objective inconsistency problem in heterogeneous federated optimization
Wang, Jianyu and Liu, Qinghua and Liang, Hao and Joshi, Gauri and Poor, H Vincent. Tackling the objective inconsistency problem in heterogeneous federated optimization. Advances in Neural Information Processing Systems. 2020
2020
-
[31]
Quantifying catastrophic forgetting in continual federated learning
Dupuy, Christophe and Majmudar, Jimit and Wang, Jixuan and Roosta, Tanya G and Gupta, Rahul and Chung, Clement and Ding, Jian and Avestimehr, Salman. Quantifying catastrophic forgetting in continual federated learning. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). 2023
2023
-
[32]
FilFL : Accelerating federated learning via client filtering
Fourati, Fares and Kharrat, Salma and Aggarwal, Vaneet and Alouini, Mohamed-Slim and Canini, Marco. FilFL : Accelerating federated learning via client filtering. arXiv preprint arXiv:2302.06599. 2023
-
[33]
REFL : Resource-efficient federated learning
Abdelmoniem, Ahmed M and Sahu, Atal Narayan and Canini, Marco and Fahmy, Suhaib A. REFL : Resource-efficient federated learning. ACM EuroSys. 2023
2023
-
[34]
Explaining and harnessing adversarial examples
Goodfellow, Ian J and Shlens, Jonathon and Szegedy, Christian. Explaining and harnessing adversarial examples. International Conference on Learning Representations. 2015
2015
-
[35]
Online continual learning from imbalanced data
Chrysakis, Aristotelis and Moens, Marie-Francine. Online continual learning from imbalanced data. International Conference on Machine Learning. 2020
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.