AIGP: An LLM-Based Framework for Long-Term Value Alignment in E-Commerce Pricing
Pith reviewed 2026-06-26 05:00 UTC · model grok-4.3
The pith
An LLM framework called AIGP aligns e-commerce pricing with long-term goals using a value estimator and preference optimization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
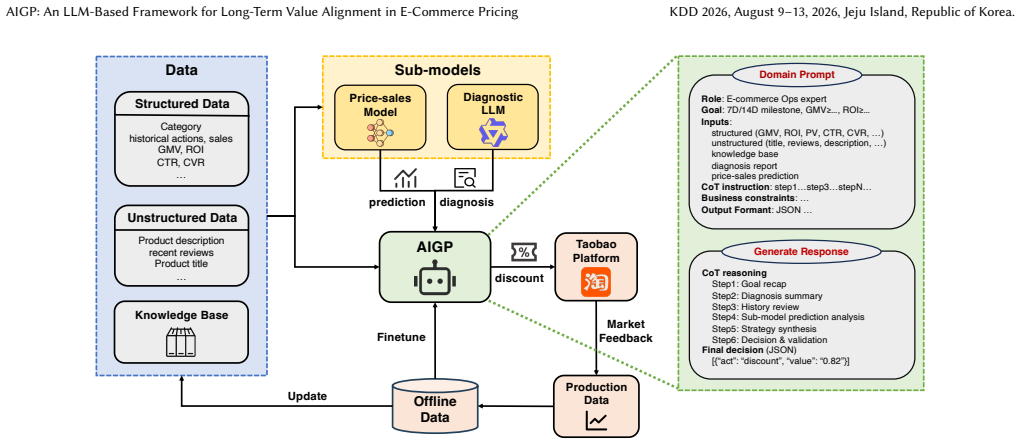
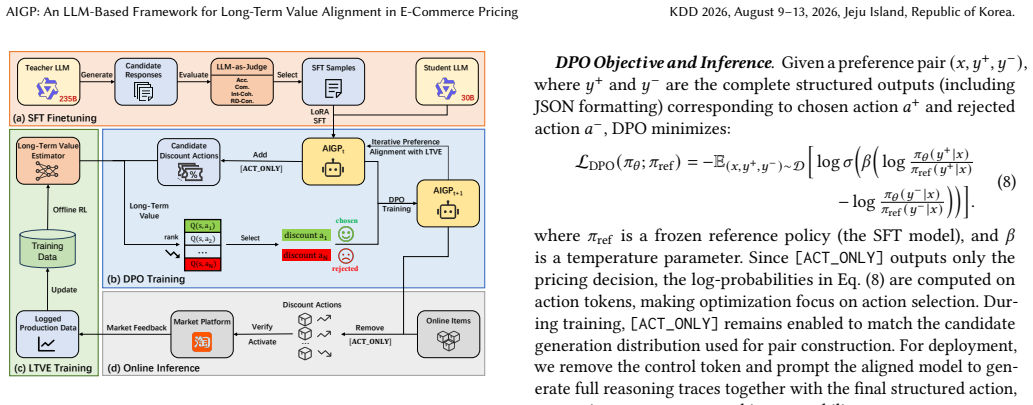
AIGP is a framework that leverages a Large Language Model prompted with domain knowledge, structured data and textual context to make interpretable, knowledge-aware pricing decisions. For efficient deployment while maintaining high-quality outputs, supervised fine-tuning is employed for knowledge distillation. Central to AIGP is the Long-Term Value Estimator, trained via offline reinforcement learning on historical data, which serves as a reward model to score candidate pricing actions and select preference pairs for Direct Preference Optimization, thereby aligning the pricing policy with long-term business objectives. Extensive offline evaluations and large-scale online A/B tests demonstrat
What carries the argument
The Long-Term Value Estimator (LTVE) trained via offline reinforcement learning on historical data, which scores candidate pricing actions to select preference pairs for Direct Preference Optimization and align the LLM policy with long-term objectives.
If this is right
- Pricing decisions achieve higher cumulative GMV, ROI, and milestone achievement rates in live environments.
- Decisions are accompanied by interpretable and transparent rationales.
- The LLM component can be deployed efficiently after supervised fine-tuning for knowledge distillation.
- The pricing policy is aligned with long-term rather than short-term business objectives via the offline-trained estimator and DPO.
Where Pith is reading between the lines
- The same combination of LLM prompting and an offline-trained value estimator might be tested on other sequential decisions such as promotion timing or inventory allocation.
- If the training distribution shifts markedly, the estimator may require periodic retraining on fresh data to maintain scoring accuracy.
- Hybrid LLM and preference-optimization pipelines could be examined for alignment problems in other high-stakes commercial settings where explanations are required.
- The reported gains rest on the estimator generalizing from historical to live data; a mismatch would reduce or eliminate the observed lifts.
Load-bearing premise
The Long-Term Value Estimator trained via offline reinforcement learning on historical data will produce accurate scores for candidate pricing actions in live online environments that differ from the training distribution.
What would settle it
A new online A/B test in which AIGP produces no improvement or a decline in GMV, ROI, or milestone achievement rate relative to the production baseline over a comparable period would falsify the performance claims.
Figures

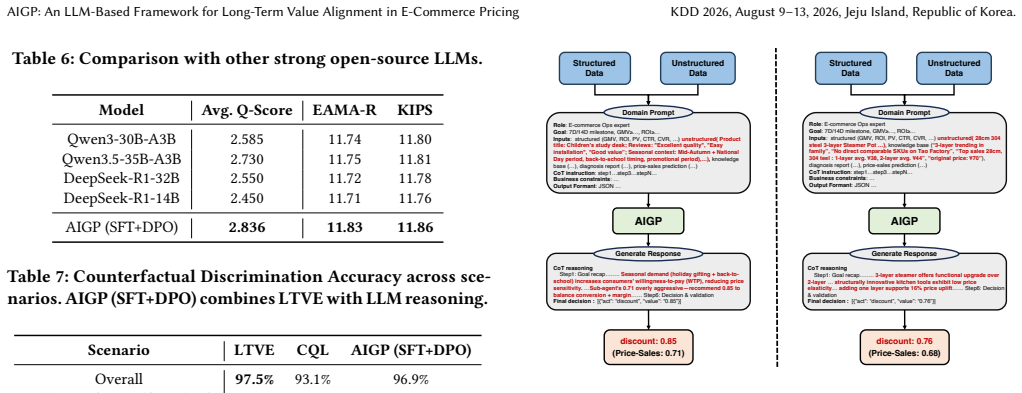
read the original abstract
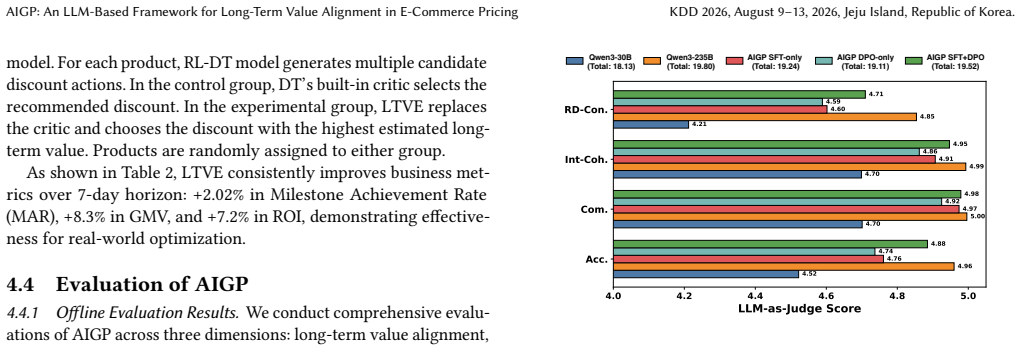
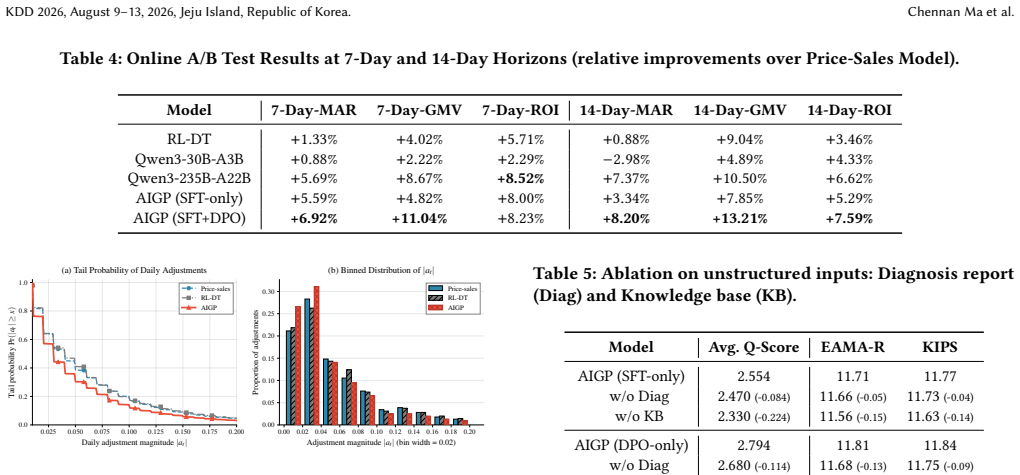
Traditional dynamic pricing models in large-scale e-commerce suffer from limited interpretability, poor utilization of unstructured information, and misalignment with long-term business objectives such as cumulative Gross Merchandise Value (GMV), Return on Investment (ROI) and milestone achievement. We propose AIGP, a novel framework that leverages a Large Language Model (LLM) prompted with domain knowledge, structured data and textual context to make interpretable, knowledge-aware pricing decisions. For efficient deployment while maintaining high-quality outputs, we employ supervised fine-tuning for knowledge distillation. Central to AIGP is the Long-Term Value Estimator (LTVE), trained via offline reinforcement learning on historical data, which serves as a reward model to score candidate pricing actions and select preference pairs for Direct Preference Optimization (DPO), thereby aligning the pricing policy with long-term business objectives. Extensive offline evaluations and large-scale online A/B tests on Tao Factory demonstrate that AIGP achieves significant improvements: +13.21% in GMV, +7.59% in ROI, and +8.20% in milestone achievement rate over 14 days compared to the production baseline, while simultaneously providing interpretable and transparent pricing rationales.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes AIGP, an LLM-based framework for dynamic pricing in e-commerce. It uses supervised fine-tuning to distill domain knowledge into an LLM that generates interpretable pricing decisions, with a Long-Term Value Estimator (LTVE) trained via offline RL on historical data serving as a reward model to score actions and construct preference pairs for DPO alignment with long-term metrics (GMV, ROI, milestone achievement). The central empirical claim is that AIGP yields +13.21% GMV, +7.59% ROI, and +8.20% milestone rate over a 14-day online A/B test versus the production baseline on Tao Factory, while also providing transparent rationales.
Significance. If the online A/B results can be substantiated with proper statistical controls and if the LTVE generalizes under distribution shift, the work would offer a concrete demonstration of LLM-driven policy alignment for long-horizon business objectives in a high-stakes industrial setting; the combination of knowledge distillation, offline RL reward modeling, and DPO is a plausible route to interpretable long-term optimization that existing rule-based or short-horizon RL pricing systems lack.
major comments (3)
- [Abstract] Abstract: the headline online A/B improvements (+13.21% GMV, +7.59% ROI, +8.20% milestone rate) are reported without any information on statistical significance testing, traffic split, exclusion criteria, or concurrent promotions; these omissions render the numerical claims impossible to evaluate and directly undermine the central empirical contribution.
- [Abstract (LTVE and DPO sections)] Abstract and LTVE/DPO pipeline description: the LTVE is trained on historical data and then used both to score candidate actions and to generate the preference pairs for DPO; no held-out future-period validation, live calibration, or correlation between LTVE scores and realized long-term outcomes is described, creating a circularity that threatens the validity of attributing the observed lifts to the LTVE component.
- [Abstract] Abstract: the claim that AIGP simultaneously improves long-term metrics while remaining interpretable rests on the unverified assumption that the offline-trained LTVE remains accurate under live distribution shift (user behavior, seasonality, market conditions); no robustness checks or shift experiments are mentioned.
minor comments (2)
- [Abstract] The abstract would benefit from a one-sentence statement of the scale of the A/B test (number of items, traffic volume) to allow readers to gauge practical significance.
- [Method section (LTVE and DPO)] Notation for the LTVE objective and the DPO loss should be introduced with explicit equations rather than prose descriptions only.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the clarity of our empirical claims and the validation of the LTVE component. We address each major comment below and outline revisions to improve transparency.
read point-by-point responses
-
Referee: Abstract: the headline online A/B improvements (+13.21% GMV, +7.59% ROI, +8.20% milestone rate) are reported without any information on statistical significance testing, traffic split, exclusion criteria, or concurrent promotions; these omissions render the numerical claims impossible to evaluate and directly undermine the central empirical contribution.
Authors: We agree that the abstract lacks sufficient experimental context. The full manuscript describes the A/B test in Section 4, but the abstract is too brief. We will revise the abstract to concisely note the 50/50 traffic split, statistical significance testing (p < 0.01), exclusion criteria, and controls for concurrent promotions. revision: yes
-
Referee: Abstract and LTVE/DPO pipeline description: the LTVE is trained on historical data and then used both to score candidate actions and to generate the preference pairs for DPO; no held-out future-period validation, live calibration, or correlation between LTVE scores and realized long-term outcomes is described, creating a circularity that threatens the validity of attributing the observed lifts to the LTVE component.
Authors: This concern about circularity is well-taken. The online A/B results provide downstream evidence, but we will add a held-out future-period validation subsection reporting correlation between LTVE scores and realized outcomes, plus any live calibration steps, to strengthen attribution to the LTVE. revision: yes
-
Referee: Abstract: the claim that AIGP simultaneously improves long-term metrics while remaining interpretable rests on the unverified assumption that the offline-trained LTVE remains accurate under live distribution shift (user behavior, seasonality, market conditions); no robustness checks or shift experiments are mentioned.
Authors: We acknowledge the need for explicit robustness analysis. The 14-day online test offers real-world evidence, but we will add shift experiments (e.g., seasonal data splits) and a limitations discussion on distribution shift in the revision. revision: yes
Circularity Check
No circularity: online A/B evaluation is independent of historical LTVE training
full rationale
The paper's chain trains LTVE offline on historical data to generate preference pairs for DPO, then deploys the resulting LLM policy and measures realized GMV/ROI/milestone gains via live A/B tests. These online metrics are collected directly from production traffic and are not computed from or defined by the LTVE scores, so the reported improvements do not reduce to the training inputs by construction. No self-citations, self-definitional equations, or fitted-input-renamed-as-prediction steps appear in the abstract or described pipeline. The distribution-shift concern is a validity issue, not a circularity reduction.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Long-Term Value Estimator (LTVE)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Talluri and Garrett J
Kalyan T. Talluri and Garrett J. Van Ryzin. 2006.The Theory and Practice of Revenue Management. Springer
2006
-
[2]
McGill and Garrett J
Jeffrey I. McGill and Garrett J. Van Ryzin. 1999. Revenue Management: Research Overview and Prospects.Transportation Science33, 2 (1999), 233–256
1999
-
[3]
Van Ryzin
Guillermo Gallego and Garrett J. Van Ryzin. 1994. Optimal Dynamic Pricing of Inventories with Stochastic Demand Over Finite Horizons.Management Science 40, 8 (1994), 999–1020. KDD 2026, August 9–13, 2026, Jeju Island, Republic of Korea. Chennan Ma et al
1994
-
[4]
Kris Johnson Ferreira, Bin Hong Alex Lee, and David Simchi-Levi. 2016. Analytics for an Online Retailer: Demand Forecasting and Price Optimization.Manufactur- ing and Service Operations Management18, 1 (2016), 69–88
2016
-
[5]
Le Chen, Alan Mislove, and Christo Wilson. 2016. An empirical analysis of algo- rithmic pricing on amazon marketplace. InProceedings of the 25th international conference on World Wide Web. 1339–1349
2016
-
[6]
Le Chen, Alan Mislove, and Christo Wilson. 2016. An Empirical Analysis of Algorithmic Pricing on Amazon Marketplace.Proceedings of the 25th International Conference on World Wide Web(2016). https://api.semanticscholar.org/CorpusID: 9570936
2016
-
[7]
Jiaxi Liu, Yidong Zhang, Xiaoqing Wang, Yuming Deng, and Xingyu Wu. 2019. Dynamic Pricing on E-Commerce Platform with Deep Reinforcement Learning: A Field Experiment. arXiv preprint arXiv:1912.02572
arXiv 2019
-
[8]
Chenyao Zhu, Caiqian Cheng, and Sisi Meng. 2024. DRL PricePro: A Deep Reinforcement Learning Framework for Personalized Dynamic Pricing in E- Commerce Platforms with Supply Constraints.Spectrum of Research4, 1 (2024)
2024
-
[9]
Thomas Hazenberg, Yao Ma, Seyed Sahand Mohammadi Ziabari, and Marijn van Rijswijk. 2025. Multi-Agent Reinforcement Learning for Dynamic Pricing in Supply Chains: Benchmarking Strategic Agent Behaviours Under Realistically Simulated Market Conditions. arXiv preprint arXiv:2507.02698
arXiv 2025
-
[10]
Enrique Adrian Villarrubia-Martin, Luis Rodriguez-Benitez, David Mu noz Valero, Giovanni Montana, and Luis Jimenez-Linares. 2025. Dynamic Pricing in High- Speed Railways Using Multi-Agent Reinforcement Learning. arXiv preprint arXiv:2501.08234
arXiv 2025
-
[11]
Aviral Kumar, Aurick Zhou, George Tucker, and Sergey Levine. 2020. Conser- vative Q-Learning for Offline Reinforcement Learning. InNeural Information Processing Systems (NeurIPS)
2020
-
[12]
Sergey Levine, Aviral Kumar, George Tucker, and Justin Fu. 2020. Offline rein- forcement learning: Tutorial, review, and perspectives on open problems.arXiv preprint arXiv:2005.01643(2020)
Pith/arXiv arXiv 2020
-
[13]
Scott Fujimoto, David Meger, and Doina Precup. 2019. Off-Policy Deep Rein- forcement Learning without Exploration. InInternational Conference on Machine Learning. PMLR, 2052–2062
2019
-
[14]
Marcin Andrychowicz, Filip Wolski, Alex Ray, Jonas Schneider, Rachel Fong, Peter Welinder, Bob McGrew, Josh Tobin, OpenAI Pieter Abbeel, and Wojciech Zaremba. 2017. Hindsight experience replay.Advances in neural information processing systems30 (2017)
2017
-
[15]
Deepak Pathak, Pulkit Agrawal, Alexei A Efros, and Trevor Darrell. 2017. Curiosity-driven exploration by self-supervised prediction. InInternational con- ference on machine learning. PMLR, 2778–2787
2017
-
[16]
Yuri Burda, Harrison Edwards, Amos Storkey, and Oleg Klimov. 2018. Exploration by random network distillation.arXiv preprint arXiv:1810.12894(2018)
Pith/arXiv arXiv 2018
-
[17]
Hongzhi Yin, Bin Cui, Jing Li, Junjie Yao, and Chen Chen. 2012. Challenging the long tail recommendation.arXiv preprint arXiv:1205.6700(2012)
Pith/arXiv arXiv 2012
-
[18]
Luo Ji, Qi Qin, Bingqing Han, and Hongxia Yang. 2021. Reinforcement learning to optimize lifetime value in cold-start recommendation. InProceedings of the 30th ACM international conference on information & knowledge management. 782–791
2021
-
[19]
Lu Wang, Chengyu Wang, Keqiang Wang, and Xiaofeng He. 2017. Biucb: A contextual bandit algorithm for cold-start and diversified recommendation. In 2017 IEEE international conference on big knowledge (ICBK). IEEE, 248–253
2017
-
[20]
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. 2023. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971(2023)
Pith/arXiv arXiv 2023
-
[21]
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. 2022. Self-consistency improves chain of thought reasoning in language models.arXiv preprint arXiv:2203.11171(2022)
Pith/arXiv arXiv 2022
-
[22]
Sébastien Bubeck, Varun Chandrasekaran, Ronen Eldan, Johannes Gehrke, Eric Horvitz, Ece Kamar, Peter Lee, Yin Tat Lee, Yuanzhi Li, Scott Lundberg, et al. 2023. Sparks of artificial general intelligence: Early experiments with gpt-4.arXiv preprint arXiv:2303.12712(2023)
Pith/arXiv arXiv 2023
-
[23]
Stephen Casper, Xander Davies, Claudia Shi, Thomas Krendl Gilbert, Jérémy Scheurer, Javier Rando, Rachel Freedman, Tomasz Korbak, David Lindner, Pedro Freire, et al. 2023. Open problems and fundamental limitations of reinforcement learning from human feedback.arXiv preprint arXiv:2307.15217(2023)
Pith/arXiv arXiv 2023
-
[24]
Chi, Quoc V
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, and Denny Zhou. 2022. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. InNeural Information Processing Systems (NeurIPS)
2022
-
[25]
Ouyang, J
L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. L. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray, et al. 2022. Training Language Models to Follow Instructions with Human Feedback. InNeural Information Processing Systems (NeurIPS)
2022
- [26]
-
[27]
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. 2015. Distilling the knowledge in a neural network.arXiv preprint arXiv:1503.02531(2015)
Pith/arXiv arXiv 2015
-
[28]
Xiaohan Xu, Ming Li, Chongyang Tao, Tao Shen, Reynold Cheng, Jinyang Li, Can Xu, Dacheng Tao, and Tianyi Zhou. 2024. A survey on knowledge distillation of large language models.arXiv preprint arXiv:2402.13116(2024)
Pith/arXiv arXiv 2024
-
[29]
Manning, Stefano Ermon, and Chelsea Finn
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D. Manning, Stefano Ermon, and Chelsea Finn. 2023. Direct Preference Optimization: Your Language Model is Secretly a Reward Model. InNeural Information Processing Systems (NeurIPS)
2023
-
[30]
Phillips
Robert L. Phillips. 2021.Pricing and Revenue Optimization. Stanford University Press
2021
-
[31]
Bora Keskin and Assaf Zeevi
N. Bora Keskin and Assaf Zeevi. 2014. Dynamic Pricing with an Unknown De- mand Model: Asymptotically Optimal Semi-Myopic Policies.Operations Research 62, 5 (2014), 1142–1167
2014
-
[32]
Omar Besbes and Assaf Zeevi. 2009. Dynamic Pricing Without Knowing the De- mand Function: Risk Bounds and Near-Optimal Algorithms.Operations Research 57, 6 (2009), 1407–1420
2009
-
[33]
Rusu, Joel Veness, Marc G
Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A. Rusu, Joel Veness, Marc G. Bellemare, Alex Graves, Martin Riedmiller, Andreas K. Fidjeland, Georg Ostrovski, et al . 2015. Human-Level Control Through Deep Reinforcement Learning.Nature518, 7540 (2015), 529–533
2015
-
[34]
Lillicrap, Jonathan J
Timothy P. Lillicrap, Jonathan J. Hunt, Alexander Pritzel, Nicolas Heess, Tom Erez, Yuval Tassa, David Silver, and Daan Wierstra. 2016. Continuous Control with Deep Reinforcement Learning. InInternational Conference on Learning Representations (ICLR)
2016
-
[35]
Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. 2018. Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor. InInternational Conference on Machine Learning (ICML). 1856– 1865
2018
-
[36]
Siqi Shen, Chennan Ma, Chao Li, Weiquan Liu, Yongquan Fu, Songzhu Mei, Xinwang Liu, and Cheng Wang. 2023. RiskQ: Risk-sensitive Multi- Agent Reinforcement Learning Value Factorization. InAdvances in Neu- ral Information Processing Systems, A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine (Eds.), Vol. 36. Curran Associates, Inc., 34791–3...
2023
-
[37]
Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Michael Laskin, Pieter Abbeel, Aravind Srinivas, and Igor Mordatch. 2021. Decision Trans- former: Reinforcement Learning via Sequence Modeling. InNeural Information Processing Systems (NeurIPS). 15084–15097
2021
-
[38]
Ryan Lowe, Yi I Wu, Aviv Tamar, Jean Harb, OpenAI Pieter Abbeel, and Igor Mordatch. 2017. Multi-agent actor-critic for mixed cooperative-competitive environments.Advances in neural information processing systems30 (2017)
2017
-
[39]
Mohammad Feizabadi, Arman Hosseini, and Zakaria Yahouni. 2024. Multi-Agent Deep Q-Network with Layer-based Communication Channel for Autonomous Internal Logistics Vehicle Scheduling in Smart Manufacturing. InInternational Conference on Innovative Intelligent Industrial Production and Logistics. Springer, 3–22
2024
-
[40]
Tabish Rashid, Mikayel Samvelyan, Christian Schroeder De Witt, Gregory Far- quhar, Jakob Foerster, and Shimon Whiteson. 2020. Monotonic value function factorisation for deep multi-agent reinforcement learning.Journal of Machine Learning Research21, 178 (2020), 1–51
2020
-
[41]
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. 2023. Toolformer: Language Models Can Teach Themselves to Use Tools. InNeural Information Processing Systems (NeurIPS), Vol. 36. 68539–68551
2023
-
[42]
Maxwell Nye, Anders Johan Andreassen, Guy Gur-Ari, Henryk Michalewski, Ja- cob Austin, David Bieber, David Dohan, Aitor Lewkowycz, Maarten Bosma, David Luan, et al. 2021. Show Your Work: Scratchpads for Intermediate Computation with Language Models. arXiv preprint arXiv:2112.00114
Pith/arXiv arXiv 2021
-
[43]
Wenlong Huang, Pieter Abbeel, Deepak Pathak, and Igor Mordatch. 2022. Lan- guage models as zero-shot planners: Extracting actionable knowledge for embod- ied agents. InInternational conference on machine learning. PMLR, 9118–9147
2022
-
[44]
Narasimhan, and Yuan Cao
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R. Narasimhan, and Yuan Cao. 2022. ReAct: Synergizing Reasoning and Acting in Language Models. InInternational Conference on Learning Representations (ICLR)
2022
-
[45]
Weiyu Ma, Qirui Mi, Yongcheng Zeng, Xue Yan, Runji Lin, Yuqiao Wu, Jun Wang, and Haifeng Zhang. 2024. Large language models play starcraft ii: Bench- marks and a chain of summarization approach.Advances in Neural Information Processing Systems37 (2024), 133386–133442
2024
-
[46]
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. 2023. Voyager: An open-ended embodied agent with large language models.arXiv preprint arXiv:2305.16291(2023)
Pith/arXiv arXiv 2023
-
[47]
Ziegler, Nisan Stiennon, Jeffrey Wu, Tom B
Daniel M. Ziegler, Nisan Stiennon, Jeffrey Wu, Tom B. Brown, Alec Radford, Dario Amodei, Paul F. Christiano, and Geoffrey Irving. 2019. Fine-Tuning Language Models from Human Preferences.CoRRabs/1909.08593 (2019)
Pith/arXiv arXiv 2019
-
[48]
Ziegler, Ryan Lowe, Chelsea Voss, Alec Radford, Dario Amodei, and Paul F
Nisan Stiennon, Long Ouyang, Jeffrey Wu, Daniel M. Ziegler, Ryan Lowe, Chelsea Voss, Alec Radford, Dario Amodei, and Paul F. Christiano. 2020. Learning to Summarize with Human Feedback. InNeural Information Processing Systems (NeurIPS). AIGP: An LLM-Based Framework for Long-Term Value Alignment in E-Commerce Pricing KDD 2026, August 9–13, 2026, Jeju Islan...
2020
-
[49]
AA. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lv, et al. 2025. Qwen3 Technical Report. arXiv:2505.09388 [cs.CL] https: //arxiv.org/abs/2505.09388
Pith/arXiv arXiv 2025
-
[50]
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. 2022. Lora: Low-rank adaptation of large language models.ICLR1, 2 (2022), 3
2022
-
[51]
Josef Dai, Xuehai Pan, Ruiyang Sun, Jiaming Ji, Xinbo Xu, Mickel Liu, Yizhou Wang, and Yaodong Yang. 2024. Safe RLHF: Safe Reinforcement Learning from Human Feedback. InThe Twelfth International Conference on Learning Represen- tations. https://openreview.net/forum?id=TyFrPOKYXw
2024
-
[52]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al . 2025. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948(2025)
Pith/arXiv arXiv 2025
-
[53]
Volodymyr Mnih, Adria Puigdomenech Badia, Mehdi Mirza, Alex Graves, Timo- thy Lillicrap, Tim Harley, David Silver, and Koray Kavukcuoglu. 2016. Asynchro- nous methods for deep reinforcement learning. InInternational Conference on Machine Learning. PMLR, 1928–1937
2016
-
[54]
Ziyu Wang, Tom Schaul, Matteo Hessel, Hado Hasselt, Marc Lanctot, and Nando Freitas. 2016. Dueling network architectures for deep reinforcement learning. In International Conference on Machine Learning. PMLR, 1995–2003
2016
-
[55]
Ilya Kostrikov, Ashvin Nair, and Sergey Levine. 2021. Offline reinforcement learning with implicit q-learning. InInternational Conference on Learning Repre- sentations
2021
-
[56]
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. 2020. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361(2020)
Pith/arXiv arXiv 2020
-
[57]
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. 2022. Training compute-optimal large language models. arXiv preprint arXiv:2203.15556(2022). A Extended Experimental Configuration A.1 Detailed Hyper-parameters Table 8 lists the ...
Pith/arXiv arXiv 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.