SonoCLIP: Mask-Guided Region-Aware Vision-Language Pretraining for Fetal Ultrasound Analysis
Pith reviewed 2026-06-30 06:59 UTC · model grok-4.3
The pith
Integrating segmentation masks as visual prompts enables region-controllable vision-language pretraining for fetal ultrasound.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
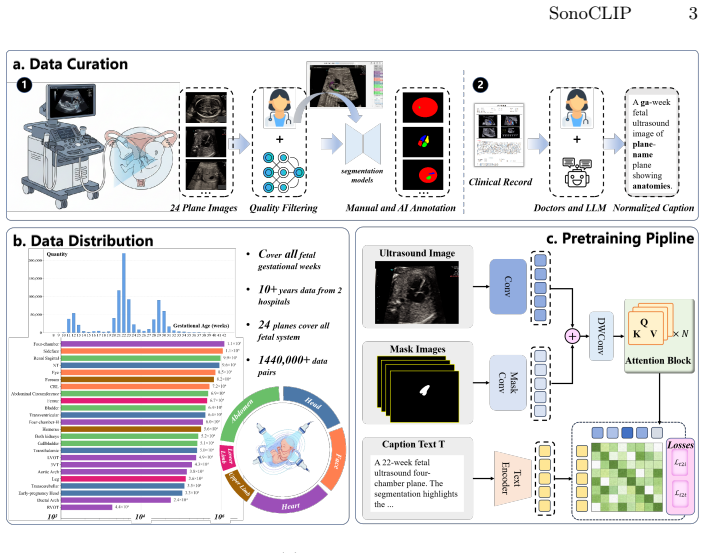
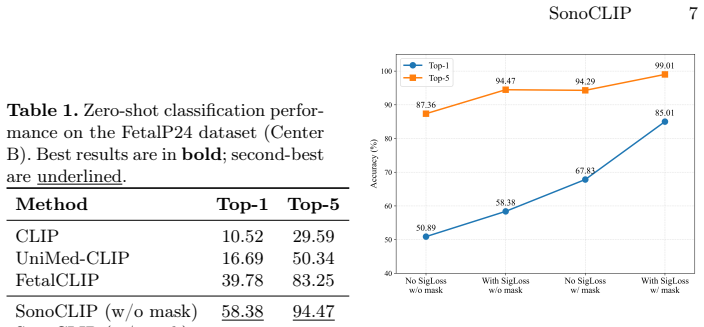
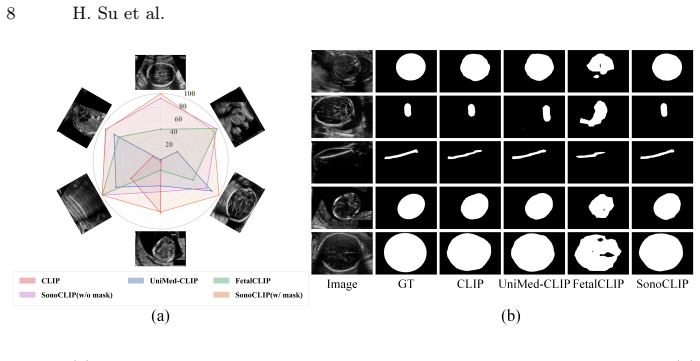
SonoCLIP integrates segmentation masks as mask-channel visual prompts within the vision encoder to enable joint global-local contrastive representation learning. It employs a sigmoid-based pairwise contrastive loss for stable supervision at scale and pretrains on a 1.44M-image multimodal fetal ultrasound dataset. The result is superior zero-shot transfer performance under both global and mask-guided inference in cross-center evaluations.
What carries the argument
Mask-channel visual prompts that feed segmentation masks into the vision encoder to support region-text alignment alongside global alignment.
If this is right
- The model allows clinicians to supply masks at inference time to focus contrastive alignment on specific anatomical regions.
- Zero-shot transfer improves on both global and local tasks without task-specific fine-tuning.
- The sigmoid-based loss supports stable training when scaling to million-image multimodal supervision.
- Coverage of 24 standard planes provides broad applicability within fetal ultrasound analysis.
Where Pith is reading between the lines
- The same mask-channel approach could be tested on other ultrasound applications such as cardiac or abdominal imaging to check transfer of the region-control benefit.
- If masks are available from automated segmenters, the model might reduce dependence on expert annotations during deployment.
- The controllable inference mode could be combined with existing clinical workflows that already produce segmentation outputs.
Load-bearing premise
The curated dataset and mask integration produce representations that generalize across centers without masks introducing bias or the loss causing training instability.
What would settle it
A new-center evaluation in which mask-guided inference shows no improvement or worse performance than global-only inference on the same test images would falsify the central performance claim.
Figures
read the original abstract
Vision-language foundation models have shown strong potential in medical image analysis. Although foundation models for ultrasound imaging have recently emerged, the domain remains particularly challenging due to severe speckle noise, acquisition variability, and subtle anatomical boundaries, leading to high inter-observer variability. Existing CLIP-based models rely primarily on global image-text alignment, limiting their sensitivity to clinically decisive local structures. We propose SonoCLIP, the first million-scale region-controllable fetal ultrasound vision-language foundation model that integrates segmentation masks as mask-channel visual prompts within the vision encoder, enabling joint global-local contrastive representation learning. To support scalable region-text alignment, we introduce a sigmoid-based pairwise contrastive loss that improves stability under large-scale supervision. We further curate a 1.44M-image multimodal fetal ultrasound dataset spanning 24 standard planes for large-scale pretraining. Extensive cross-center evaluations demonstrate that SonoCLIP achieves superior zero-shot transfer performance under both global and mask-guided inference, establishing a controllable and clinically oriented foundation model for fetal ultrasound analysis. Our code and data are available at https://github.com/Harrison-one/SonoCLIP.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. SonoCLIP is proposed as a mask-guided region-aware vision-language pretraining model for fetal ultrasound analysis. It integrates segmentation masks as additional channels in the vision encoder to enable controllable global-local contrastive learning on a curated 1.44 million image dataset spanning 24 standard planes. A sigmoid-based pairwise contrastive loss is introduced to improve training stability at scale. The model is claimed to achieve superior zero-shot transfer performance on cross-center evaluations using both global and mask-guided inference.
Significance. If the reported performance advantages hold under rigorous evaluation, this work could significantly advance the development of foundation models for ultrasound imaging by providing region-controllable representations that are better suited to the clinical needs of fetal analysis. The public availability of the code and dataset is a strength that supports further research in the field.
minor comments (1)
- [Abstract] The abstract asserts superior zero-shot transfer performance without providing any quantitative metrics, specific baselines, or statistical details. Including key results would strengthen the summary of the contributions.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation of SonoCLIP and the recommendation for minor revision. We appreciate the acknowledgment of the model's potential impact on foundation models for ultrasound imaging and the value of releasing code and data.
Circularity Check
No significant circularity
full rationale
The paper's core contribution is empirical: curation of a 1.44M-image fetal ultrasound dataset, integration of mask-channel prompts into a CLIP-style vision encoder, and introduction of a sigmoid pairwise contrastive loss for region-text alignment. All claims of superior zero-shot performance rest on cross-center evaluations rather than any derivation that reduces to fitted parameters or self-citations by construction. No equations, uniqueness theorems, or ansatzes are shown to be self-referential; the argument is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Vision-language contrastive learning can produce useful representations for downstream tasks
- domain assumption Segmentation masks can be effectively integrated as additional channels in the vision encoder without degrading performance
Reference graph
Works this paper leans on
-
[1]
Ultrasonic imaging44(1), 25–38 (2022)
AshkaniChenarlogh,V.,GhelichOghli,M.,Shabanzadeh,A.,Sirjani,N.,Akhavan, A., Shiri, I., Arabi, H., Sanei Taheri, M., Tarzamni, M.K.: Fast and accurate u-net model for fetal ultrasound image segmentation. Ultrasonic imaging44(1), 25–38 (2022)
2022
-
[2]
Avola, D., Cinque, L., Fagioli, A., Foresti, G., Mecca, A.: Ultrasound medical imaging techniques: A survey. ACM Comput. Surv.54(3) (Apr 2021).https: //doi.org/10.1145/3447243 10 H. Su et al
-
[3]
Scientific Reports10, 10200 (2020).https://doi.org/10.1038/ s41598-020-67076-5
Burgos-Artizzu, X.P., Coronado-Gutiérrez, D., Valenzuela-Alcaraz, B., Bonet- Carne, E., Eixarch, E., Crispi, F., Gratacós, E.: Evaluation of deep convolu- tional neural networks for automatic classification of common maternal fetal ul- trasound planes. Scientific Reports10, 10200 (2020).https://doi.org/10.1038/ s41598-020-67076-5
2020
-
[4]
Scientific Reports10(1), 10200 (2020)
Burgos-Artizzu, X.P., Coronado-Gutiérrez, D., Valenzuela-Alcaraz, B., Bonet- Carne, E., Eixarch, E., Crispi, F., Gratacós, E.: Evaluation of deep convolutional neural networks for automatic classification of common maternal fetal ultrasound planes. Scientific Reports10(1), 10200 (2020)
2020
-
[5]
Nature Biomedical Engineering (2026).https://doi.org/10.1038/ s41551-025-01578-3, published online 15 Jan 2026
Guo, X., Alsharid, M., Zhao, H., Wang, Y., Lander, J., Papageorghiou, A.T., Noble, J.A.: A visually grounded language model for fetal ultrasound under- standing. Nature Biomedical Engineering (2026).https://doi.org/10.1038/ s41551-025-01578-3, published online 15 Jan 2026
2026
-
[6]
Neurocomputing579,127443 (2024).https://doi.org/10.1016/j.neucom.2024
He, J., Yang, L., Liang, B., Li, S., Xu, C.: Fetal cardiac ultrasound standard sec- tion detection model based on multitask learning and mixed attention mechanism. Neurocomputing579,127443 (2024).https://doi.org/10.1016/j.neucom.2024. 127443
-
[7]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
He, K., Chen, X., Xie, S., Li, Y., Dollár, P., Girshick, R.: Masked autoencoders are scalable vision learners. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 16000–16009 (2022)
2022
-
[8]
Ultrasound in obstetrics & gynecology: the official journal of the International Society of Ultrasound in Obstetrics and Gynecology p
Khalil, A., Sotiriadis, A., D’Antonio, F., Da, Silva Costa, F., Odibo, A., Prefumo, F., Papageorghiou, A.T., Salomon, L.J.: Isuog practice guidelines: performance of third-trimester obstetric ultrasound scan. Ultrasound in obstetrics & gynecology: the official journal of the International Society of Ultrasound in Obstetrics and Gynecology p. 63 (2024)
2024
-
[9]
IEEE Reviews in Biomedical Engineering 19, 283–304 (2026).https://doi.org/10.1109/RBME.2025.3531360
Khan, W., Leem, S., See, K.B., Wong, J.K., Zhang, S., Fang, R.: A comprehensive survey of foundation models in medicine. IEEE Reviews in Biomedical Engineering 19, 283–304 (2026).https://doi.org/10.1109/RBME.2025.3531360
- [10]
-
[11]
Expert Systems with Applications238, 122153 (2024).https://doi.org/10.1016/j.eswa.2023.122153
Krishna, T.B., Kokil, P.: Standard fetal ultrasound plane classification based on stacked ensemble of deep learning models. Expert Systems with Applications238, 122153 (2024).https://doi.org/10.1016/j.eswa.2023.122153
-
[12]
Nature643, 488–498 (2025).https://doi.org/10
Ma, D., Pang, J., Gotway, M.B., Liang, J.: A fully open AI foundation model applied to chest radiography. Nature643, 488–498 (2025).https://doi.org/10. 1038/s41586-025-09079-8
2025
-
[13]
Ma, J., Guo, Z., Zhou, F., Wang, Y., Xu, Y., Li, J., Yan, F., Cai, Y., Zhu, Z., Jin, C., Lin, Y., Jiang, X., Zhao, C., Li, D., Han, A., Li, Z., Chan, R.C.K., Wang, J., Fei, P., Cheng, K.T., Zhang, S., Li, L.L., Chen, H.: A generalizable pathology foun- dation model using a unified knowledge distillation pretraining framework. Nature Biomedical Engineering...
- [14]
-
[15]
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., Sutskever, I.: Learning transferable visual models from natural language supervision (2021),https://arxiv.org/abs/ 2103.00020 SonoCLIP 11
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[16]
Ultrasound in Obstetrics and Gynecology41(2), 102–113 (2013)
Salomon, L.J., Alfirevic, Z., Bilardo, C.M., Chalouhi, G.E., In, O.I.S.O.U.: Isuog practice guidelines: performance of first-trimester fetal ultrasound scan (vol 41, pg 102, 2013). Ultrasound in Obstetrics and Gynecology41(2), 102–113 (2013)
2013
-
[17]
Scientific Reports15, 19612 (2025).https://doi.org/10.1038/s41598-025-04631-y
Singh, R., Gupta, S., Mohamed, H.G., Bharany, S., Rehman, A.U., Ghadi, Y.Y., Hussen, S.: Advancing prenatal healthcare by explainable AI enhanced fetal ultra- sound image segmentation using U-Net++ with attention mechanisms. Scientific Reports15, 19612 (2025).https://doi.org/10.1038/s41598-025-04631-y
-
[18]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Sun, Z., Fang, Y., Wu, T., Zhang, P., Zang, Y., Kong, S., Xiong, Y., Lin, D., Wang, J.: Alpha-clip: A clip model focusing on wherever you want. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 13019–13029 (June 2024)
2024
-
[19]
Nature Medicine31, 2691–2702 (2025).https://doi.org/ 10.1038/s41591-025-03747-y
Yan, S., Yu, Z., Primiero, C., Vico-Alonso, C., Wang, Z., Yang, L., Tschandl, P., Hu, M., Ju, L., Tan, G., Tang, V., Ng, A.B., Powell, D., Bonnington, P., See, S., Magnaterra, E., Ferguson, P., Nguyen, J., Guitera, P., Banuls, J., Janda, M., Mar, V., Kittler, H., Soyer, H.P., Ge, Z.: A multimodal vision foundation model for clinical dermatology. Nature Me...
-
[20]
Medical Image Analysis94, 103147 (2024).https://doi.org/10.1016/j.media.2024.103147
Yeung, P.H., Hesse, L.S., Aliasi, M., Haak, M.C., 21st Consortium, I., Xie, W., Namburete, A.I.L.: Sensorless volumetric reconstruction of fetal brain freehand ultrasound scans with deep implicit representation. Medical Image Analysis94, 103147 (2024).https://doi.org/10.1016/j.media.2024.103147
-
[21]
InProceedings of the SIGGRAPH Asia 2025 Conference Papers (SA Conference Papers ’25)
Zhai, X., Mustafa, B., Kolesnikov, A., Beyer, L.: Sigmoid loss for language im- age pre-training. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 11941–11952 (2023).https://doi.org/10.1109/ ICCV51070.2023.01100
-
[22]
Zhang,S.,etal.:Biomedclip:amultimodalbiomedicalfoundationmodelpretrained from fifteen million scientific image-text pairs (2023),https://arxiv.org/abs/ 2303.00915
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.