Strategy-Induct: Task-Level Strategy Induction for Instruction Generation
Pith reviewed 2026-05-21 04:29 UTC · model grok-4.3
The pith
Strategy-Induct generates task-level instructions for LLMs from questions alone by first extracting explicit reasoning strategies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
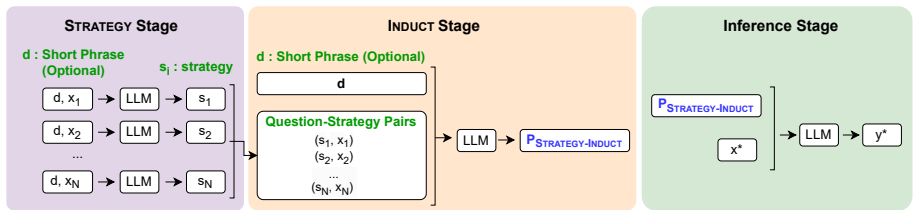
Strategy-Induct works by prompting an LLM to produce explicit reasoning strategies for each question in a small unlabeled set, thereby creating (strategy, question) pairs. These pairs are fed to the model to induce one task-level instruction that tells the model how to reason on any new question from the same task. The induced instruction is then applied at inference time to guide the model's output without ever having seen the correct answers during induction.
What carries the argument
The Strategy-Induct pipeline that turns per-question reasoning strategies into (strategy, question) pairs and then induces a single task instruction from those pairs.
If this is right
- The method works in question-only settings where labeled answers are unavailable.
- Performance gains hold across multiple tasks and across different model scales.
- Combining LLMs and Large Reasoning Models for both instruction generation and inference can produce additional gains.
Where Pith is reading between the lines
- The approach lowers the data cost of creating new task prompts because answers are no longer required.
- Explicit strategy traces may serve as an intermediate representation that helps transfer instructions to related but unseen question distributions.
- The same two-stage pattern could be tested on instruction induction for code or multimodal tasks where answers are likewise expensive to obtain.
Load-bearing premise
Prompting an LLM to generate explicit reasoning strategies directly from questions alone produces strategies accurate and general enough to support useful task-level instruction induction.
What would settle it
Apply Strategy-Induct to a fresh collection of tasks and measure whether the induced instructions produce lower accuracy than strong baselines that receive the same questions but no generated strategies.
Figures













read the original abstract
Designing effective task-level prompts is crucial for improving the performance of Large Language Models (LLMs). While prior work on instruction induction demonstrates that LLMs can infer better instructions with limited examples, existing approaches often rely on input-output pairs, where obtaining labeled answers can be difficult or costly. To address this limitation, we propose Strategy-Induct, a framework that derives task-level instructions solely from a small set of example questions without requiring labeled answers. Our approach first prompts the model to generate explicit reasoning strategies for each question, forming (strategy, question) pairs. These pairs are then used to induce a task instruction that guides reasoning. Experiments across multiple tasks and model scales demonstrate that Strategy-Induct outperforms state-of-the-art methods in question-only settings. Furthermore, we observe that jointly utilizing LLMs and Large Reasoning Models across task instruction generation and inference may lead to further performance improvements.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Strategy-Induct, a framework that induces task-level instructions for LLMs using only a small set of unlabeled example questions. The method first prompts an LLM to generate explicit reasoning strategies for each question, producing (strategy, question) pairs that are then aggregated to derive a general task instruction. Experiments across multiple tasks and model scales are reported to show outperformance over state-of-the-art question-only baselines, with additional gains suggested when jointly using LLMs and Large Reasoning Models for instruction generation and inference.
Significance. If the empirical results hold under rigorous controls, the work has moderate significance for prompt engineering and instruction induction. Removing the requirement for labeled answers addresses a practical bottleneck in prior methods, potentially enabling broader application in low-resource or unlabeled settings. The hybrid LLM/LRM observation, if substantiated, could inform future model-selection strategies for reasoning tasks.
major comments (2)
- [Experiments] Experiments section: The central claim of outperformance over SOTA question-only methods rests on the assumption that LLM-generated reasoning strategies derived solely from questions are accurate and task-faithful; however, the manuscript provides no human validation, consistency checks, or ablation removing the strategy step to isolate its contribution, leaving open the possibility that gains arise from prompt engineering artifacts rather than the induced strategies.
- [§3] §3 (Method): The pipeline description does not specify quality controls or filtering for the generated strategies, which is load-bearing because the skeptic concern is that strategies produced without answers may be superficial or hallucinated; without such controls or metrics (e.g., strategy-task alignment scores), the superiority claim cannot be confidently attributed to the proposed mechanism.
minor comments (2)
- [Abstract] Abstract: Include at least one concrete performance delta or task name to ground the outperformance claim rather than leaving it at a high-level assertion.
- Notation: The distinction between 'task instruction' and 'reasoning strategy' is used throughout but never formally defined; a short glossary or diagram would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which identifies key areas for strengthening the empirical validation and methodological transparency of Strategy-Induct. We respond to each major comment below and indicate the revisions planned for the next version of the manuscript.
read point-by-point responses
-
Referee: [Experiments] Experiments section: The central claim of outperformance over SOTA question-only methods rests on the assumption that LLM-generated reasoning strategies derived solely from questions are accurate and task-faithful; however, the manuscript provides no human validation, consistency checks, or ablation removing the strategy step to isolate its contribution, leaving open the possibility that gains arise from prompt engineering artifacts rather than the induced strategies.
Authors: We agree that isolating the contribution of the strategy generation step is important for attributing performance gains. In the revised manuscript we will add an ablation that bypasses explicit strategy generation and directly induces task instructions from the question examples alone, using the same aggregation procedure. We will also report a small-scale human evaluation of strategy faithfulness on a subset of tasks (with inter-annotator agreement), which was not present in the original submission. These additions will help rule out prompt-engineering artifacts as the sole source of improvement. revision: yes
-
Referee: [§3] §3 (Method): The pipeline description does not specify quality controls or filtering for the generated strategies, which is load-bearing because the skeptic concern is that strategies produced without answers may be superficial or hallucinated; without such controls or metrics (e.g., strategy-task alignment scores), the superiority claim cannot be confidently attributed to the proposed mechanism.
Authors: The original experiments did not apply explicit post-generation filtering or alignment metrics beyond the base prompting procedure. We will revise Section 3 to state this limitation clearly and add a discussion of potential superficial or hallucinated strategies. In addition, we will introduce a lightweight consistency check (generating two strategies per question and retaining the more coherent one according to a simple self-consistency heuristic) and report any resulting alignment statistics in the updated experiments. These changes will improve transparency while preserving the core pipeline. revision: partial
Circularity Check
No circularity: empirical prompting framework without derivation chain
full rationale
The paper presents Strategy-Induct as an empirical procedure: prompt an LLM to generate explicit reasoning strategies from unlabeled questions, form (strategy, question) pairs, then induce a task-level instruction. No equations, fitted parameters, or first-principles derivations are described that would reduce the claimed outperformance to a self-referential definition or input by construction. Prior work on instruction induction is referenced only as motivation, not as a load-bearing self-citation chain. The central claim rests on experimental comparisons across tasks and model scales rather than any closed mathematical reduction, satisfying the criteria for a self-contained empirical result.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs can generate explicit and useful reasoning strategies for individual questions without access to ground-truth answers
Reference graph
Works this paper leans on
-
[1]
Task-level instructions induction for audio question answering from few examples. InProceed- ings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Vol- ume 2: Short Papers), pages 244–264, Rabat, Mo- rocco. Association for Computational Linguistics. Po-Chun Chen, Sheng-Lun Wei, Hen-Hsen Huang, and Hsin-Hsi C...
-
[2]
Large Language Models are Zero-Shot Reasoners
Automatic engineering of long prompts. In Findings of the Association for Computational Lin- guistics ACL 2024, pages 10672–10685, Bangkok, Thailand and virtual meeting. Association for Com- putational Linguistics. Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yu- taka Matsuo, and Yusuke Iwasawa. 2022. Large language models are zero-shot reasoners.ArXiv...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Show your work: Scratchpads for interme- diate computation with language models.ArXiv, abs/2112.00114. OpenAI. 2023. Gpt-4 technical report.ArXiv, abs/2303.08774. OpenAI. 2024a. Gpt-4o mini: advancing cost-efficient intelligence. July 18, 2024. OpenAI. 2024b. Hello gpt-4o. May 13, 2024. OpenAI. 2025. Openai o3-mini. January 31, 2025. Akshara Prabhakar, Th...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Language models as inductive reasoners. ArXiv, abs/2212.10923. Fei Yu, Hongbo Zhang, and Benyou Wang. 2023. Natu- ral language reasoning, a survey.ACM Computing Surveys. Huaqi Zhang, Lubao Wang, Haiming Shao, Mingxuan Wu, and Wei Ren. 2024. Large model fine-tuning method based on pre-cognitive inductive reasoning - pcir. In2024 5th International Seminar o...
-
[5]
and GPT o3 mini (OpenAI, 2025) with low, medium, andhighreasoning effort settings. B.2 Other Details Model VersionTable 3 lists the exact model ver- sions used in our experiments, following the nam- ing conventions used in the API. Safety SettingsWe disable all safety settings for Gemini to prevent Google’s API from refusing to respond. Cost DetailsTable ...
work page 2025
-
[6]
Carefully read and analyze the question
-
[7]
Identify the key components and challenges within the question
-
[8]
Develop a step-by-step strategy to address the question
-
[9]
Outline your strategy using numbered steps. Present your strategy in the following format: <strategy> Step 1: [Brief description of the first step] Step 2: [Brief description of the second step] Step 3: [Brief description of the third step] [Continue with additional steps as needed] </strategy> **Important:** Focus solely on creating a strategy to solve t...
-
[12]
**Operational Steps**: Detail the specific step-by-step procedures required to complete the task. Remember to ensure that the final output format adheres to the "answer_format" specification. Ensure that your task instruction is concise, clear, and easily understandable by users. It should provide all necessary information for someone to successfully comp...
-
[13]
**Task Content**: Clearly define the purpose of the task and the specific activities required to be completed
-
[14]
**Input Format**: Provide detailed descriptions of the types of data accepted, their formats, and how to process these data effectively
-
[15]
**Operational Steps**: Detail the specific step-by-step procedures required to complete the task. Remember to ensure that the final output format adheres to the "answer_format" specification. Ensure your task instruction are concise, clear, and easy to understand for users. They should provide all the necessary information for someone to successfully comp...
-
[17]
Based on your deduction, provide the final answer according to the rules specified in the "Output Format" section. If unsure and "Output Format" is option, guess the closest option. Present your final answer in the following format: <final_answer> [Your final answer here] </final_answer> NoteDo not use programming or code to solve this question. Figure 11...
-
[18]
<strategy> [Your strategy here] </strategy>
Carefully consider the problem and generate the strategic knowledge that would best guide the problem-solving process. <strategy> [Your strategy here] </strategy>
-
[19]
<deduction> [Your step-by-step deduction here] </deduction>
Provide step-by-step deduction that answers the question. <deduction> [Your step-by-step deduction here] </deduction>
-
[20]
Based on your deduction, provide the final answer according to the rules specified in the "Output Format" section. If unsure and "Output Format" is option, guess the closest option. Present your final answer in the following format: <final_answer> [Your final answer here] </final_answer> NoteDo not use programming or code to solve this question. Figure 12...
-
[22]
Based on your deduction, provide the final answer according to the rules specified in the "Output Format" section. If unsure and "Output Format" is option, guess the closest option. Present your final answer in the following format: <final_answer> [Your final answer here] </final_answer> NoteDo not use programming or code to solve this question. Figure 13...
-
[24]
Based on your deduction, provide the final answer according to the rules specified in the "Output Format" section. If unsure and "Output Format" is option, guess the closest option. Present your final answer in the following format: <final_answer> [Your final answer here] </final_answer> New Question [Question] (A) The best way to defeat a stronger/larger...
-
[25]
Provide step-by-step deduction that answers the question <deduction> [Your step-by-step deduction here] </deduction>
-
[26]
Based on your deduction, provide the final answer according to the rules specified in the "Output Format" section. If unsure and "Output Format" is option, guess the closest option. Present your final answer in the following format: <final_answer> [Your final answer here] </final_answer> Note: Do not use programming or code to solve this question. New Que...
-
[27]
This implies that the opponent has an advantage in terms of size, strength, and organization
The question revolves around the strategy to defeat a stronger, larger, and better-regimented force. This implies that the opponent has an advantage in terms of size, strength, and organization
-
[28]
This would mean engaging in a way that plays to the opponent’s strengths, which is counterintuitive
Option (A) suggests fighting on the opponent’s terms. This would mean engaging in a way that plays to the opponent’s strengths, which is counterintuitive. If the opponent is stronger and better organized, fighting on their terms would likely lead to defeat
-
[29]
This implies leveraging your own strengths and avoiding the opponent’s advantages
Option (B) suggests fighting on your own terms. This implies leveraging your own strengths and avoiding the opponent’s advantages. Historically and strategically, this approach is more effective when facing a superior force. For example, guerrilla warfare or asymmetric tactics are often used to counteract a stronger opponent
-
[30]
Based on logic and historical precedent, fighting on your own terms (Option B) is the more effective strategy. </deduction> <final_answer> B </final_answer> Figure 15: Example of Zero-shot CoT Prompting on theSnarkstask in the BBH-Induct dataset, using GPT-4o, where the correct answer is A. Task Sub Task Short Phrase Boolean Expressions boolean expression...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.