Arena-T2I Hard: Benchmarking and Improving Faithfulness with Dependency-Aware Checklist
Pith reviewed 2026-07-01 05:13 UTC · model grok-4.3
The pith
A dependency-aware checklist reward improves the faithfulness-aesthetics trade-off for text-to-image models on SD3.5-Medium and FLUX.1-dev.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
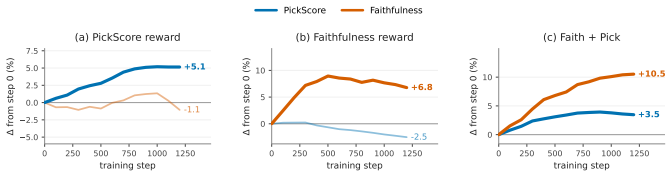
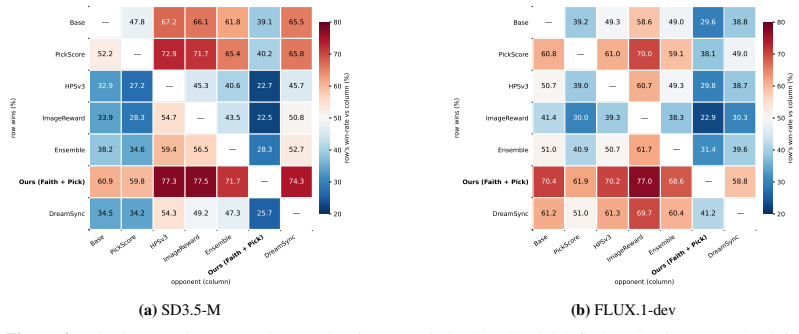
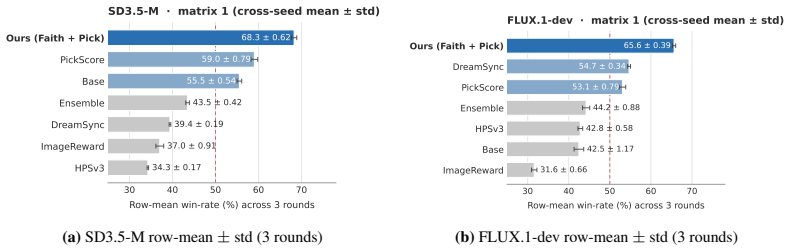
Modeling each prompt as a directed acyclic graph of yes/no constraints lets a checklist reward supply per-constraint training signals that, when paired with an aesthetic reward via group-decoupled normalization, produces a strictly superior faithfulness-aesthetics frontier on SD3.5-Medium and FLUX.1-dev than single-reward, weighted-sum, or BT-ensemble baselines.
What carries the argument
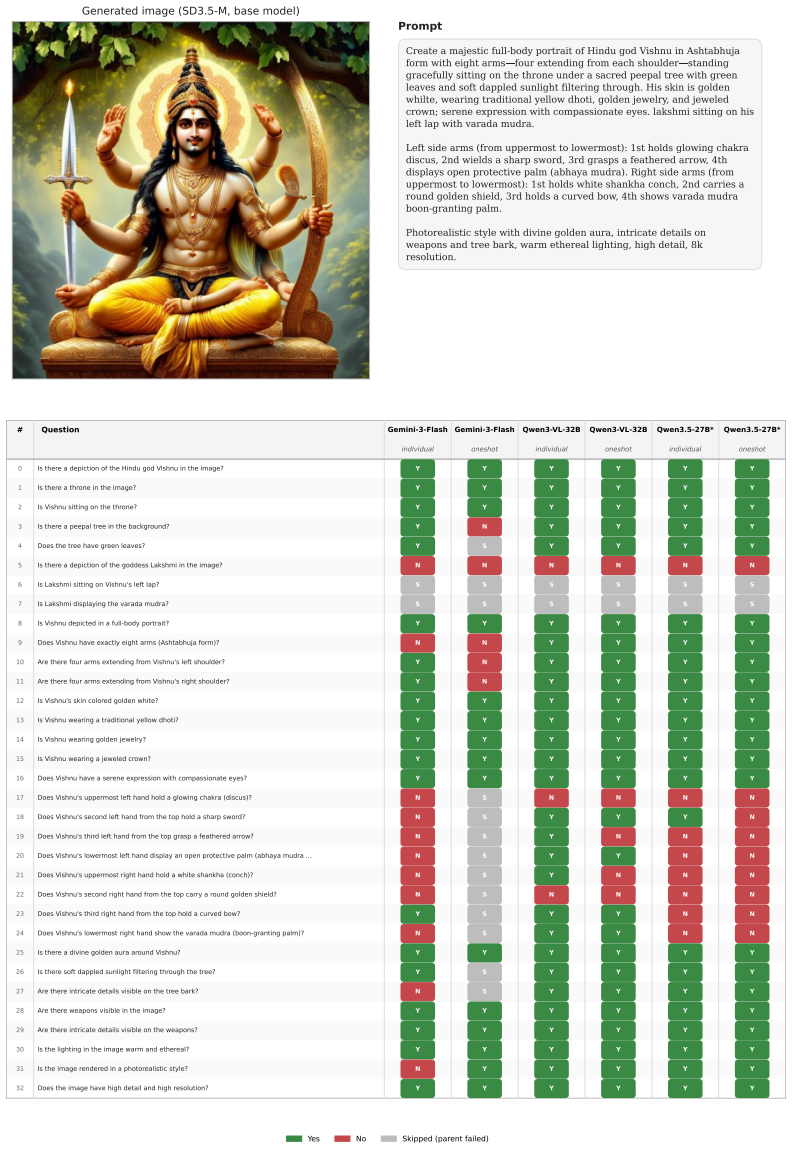
The dependency-aware checklist reward, which decomposes prompts into a DAG of yes/no questions and zeroes descendants of any failed parent to turn faithfulness into a structured training signal.
If this is right
- The benchmark produces a 33-point performance gap across eleven systems, giving it stronger discriminative power than prior atomic-instruction tests.
- Public arena rankings fail to predict faithfulness because they weight aesthetics more heavily.
- The combined checklist-plus-aesthetic recipe yields better MMRB2 pairwise results than every tested baseline on the two evaluated models.
- Zeroing dependent constraints prevents the model from receiving credit for downstream successes that logically cannot occur.
Where Pith is reading between the lines
- The same DAG construction could be applied to video or 3D generation tasks that also involve chained spatial and stylistic constraints.
- If the DAG extraction step can be made fully automatic from raw prompts, the approach could scale to training sets much larger than the 310-prompt benchmark.
- Group-decoupled normalization may serve as a general tool for preventing any single reward from dominating in multi-objective preference optimization.
Load-bearing premise
The VLM judge returns reliable yes/no answers on the decomposed constraints and the dependency DAG correctly captures the logical relationships among them.
What would settle it
Human annotation of a random sample of the benchmark constraints to measure agreement rate with the VLM labels; if agreement falls substantially below the level needed for stable training, the reward signal would be unreliable.
Figures


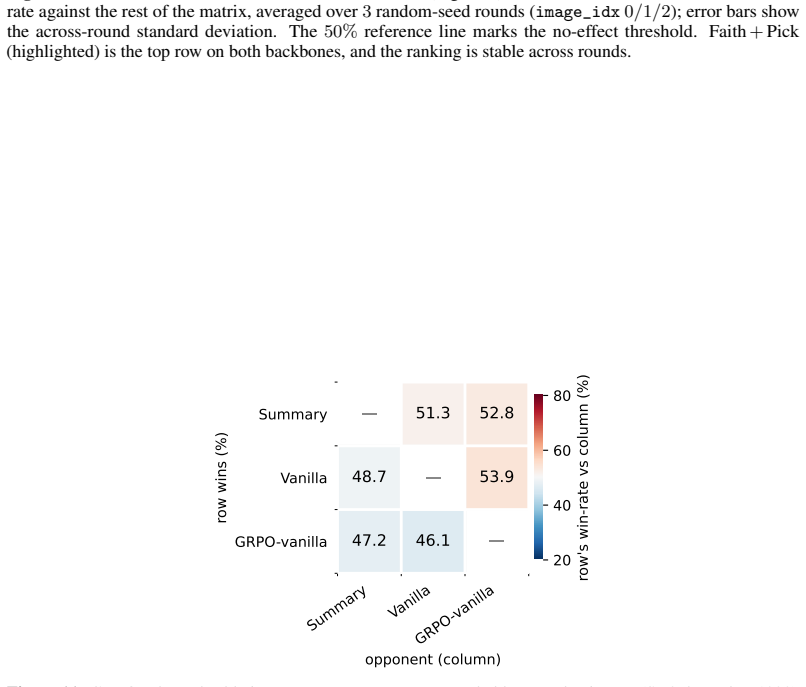
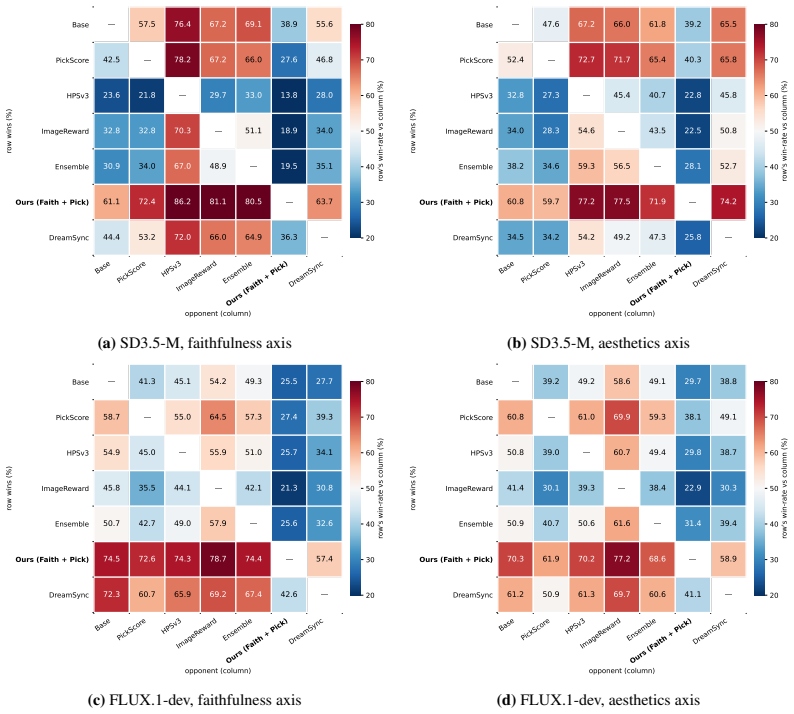
read the original abstract
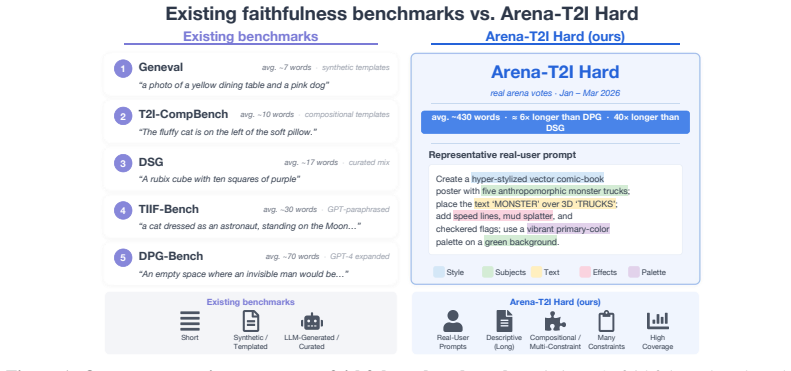
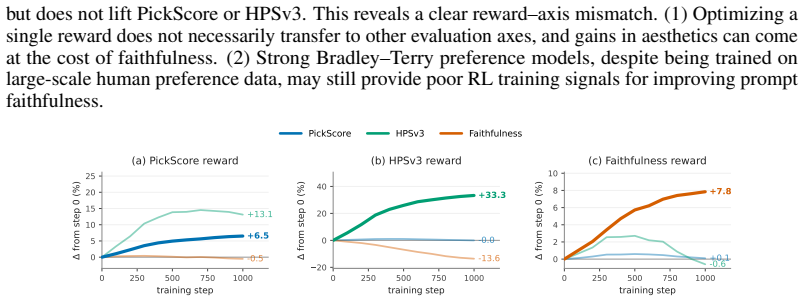
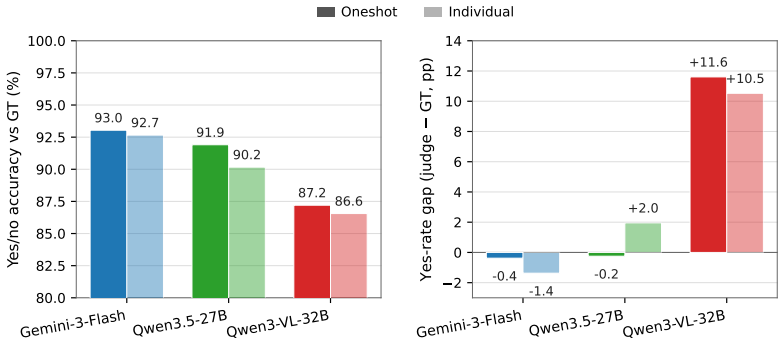
Faithfulness -- how precisely a generated image aligns with its prompt -- is increasingly central to the real-world utility of text-to-image (T2I) models. Existing faithfulness benchmarks, however, rely on simple atomic instructions, on which top-tier systems already achieve near-perfect scores. As T2I models enter creative workflows, users issue multi-faceted requests combining intricate spatial relationships, stylistic constraints, and complex text rendering. In this setting, a single binary VLM-judge score no longer captures which specific constraints the model fails to satisfy. We introduce Arena-T2I Hard, a 310-prompt stress benchmark drawn from real arena T2I logs, with approximately 30 decomposed yes/no constraints per prompt spanning six categories, including text rendering. The strongest closed-source system we evaluate reaches 0.855 with a 33~pp performance gap across 11 systems, demonstrating substantial discriminative power. Moreover, high public-arena rankings fail to predict faithfulness, confirming that holistic Bradley-Terry (BT) preference scores prioritize aesthetics over fine-grained prompt adherence. We propose a dependency-aware checklist reward that decomposes each prompt into a DAG of yes/no questions and zeroes descendants of failed parents, turning faithfulness into a per-constraint training signal. Combined with a BT aesthetic reward via group-decoupled normalization (GDPO), which standardizes each reward within its rollout group so neither collapses, the recipe attains a strictly better faithfulness-aesthetics trade-off on SD3.5-Medium and FLUX.1-dev under MMRB2 pairwise comparisons than every single-reward, naive weighted-sum, or 4-reward BT-ensemble baseline.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Arena-T2I Hard, a 310-prompt benchmark with ~30 decomposed yes/no constraints per prompt drawn from real T2I arena logs, demonstrating that top T2I systems exhibit a 33pp gap in faithfulness (strongest closed-source at 0.855) and that public BT rankings do not predict fine-grained adherence. It proposes a dependency-aware checklist reward that decomposes prompts into a DAG, zeroing descendant constraints on parent failure, and combines it with a BT aesthetic reward via group-decoupled normalization (GDPO) to achieve a strictly superior faithfulness-aesthetics trade-off on SD3.5-Medium and FLUX.1-dev versus single-reward, weighted-sum, and 4-reward BT-ensemble baselines under MMRB2 pairwise comparisons.
Significance. If the VLM judge labels and DAG structure prove reliable, the work supplies both a discriminative stress benchmark that exposes limitations of holistic preference scores and a training recipe that converts faithfulness into a per-constraint signal without collapsing the aesthetic objective. The explicit comparison against multiple baseline reward combinations and the use of real-arena prompts are concrete strengths.
major comments (2)
- [benchmark construction and reward definition] Benchmark construction and reward definition (abstract and associated paragraphs): no human-VLM agreement rates, inter-rater reliability statistics, or error analysis on the ~30 yes/no labels per prompt are reported. Because both the Arena-T2I Hard scores and the GDPO training signal are derived directly from these VLM labels, the absence of validation leaves open the possibility that systematic label noise inflates or reverses the reported trade-off gains versus the single-reward and BT-ensemble baselines.
- [reward definition] Reward definition (abstract): the dependency DAG is asserted to accurately reflect logical relationships among constraints, yet no validation (human annotation of parent-child links, sensitivity analysis, or ablation of the zeroing rule) is described. This assumption is load-bearing for the claim that the checklist reward supplies a clean per-constraint training signal.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The concerns about validation of VLM labels and the dependency DAG are substantive and directly relevant to the reliability of both the benchmark and the proposed reward. We respond to each major comment below and will incorporate the requested analyses in the revised manuscript.
read point-by-point responses
-
Referee: [benchmark construction and reward definition] Benchmark construction and reward definition (abstract and associated paragraphs): no human-VLM agreement rates, inter-rater reliability statistics, or error analysis on the ~30 yes/no labels per prompt are reported. Because both the Arena-T2I Hard scores and the GDPO training signal are derived directly from these VLM labels, the absence of validation leaves open the possibility that systematic label noise inflates or reverses the reported trade-off gains versus the single-reward and BT-ensemble baselines.
Authors: We agree that the absence of human validation statistics for the VLM labels is a limitation of the submitted manuscript. The labels were produced by a frontier VLM with category-specific prompting, but no agreement rates or error analysis were reported. In the revision we will add a dedicated validation subsection that reports (i) human-VLM agreement on a random sample of at least 100 prompts (approximately 3,000 constraints), (ii) inter-rater reliability among multiple human annotators (Fleiss’ kappa), and (iii) a qualitative error analysis stratified by constraint category. These results will be used to quantify any systematic noise and to bound its possible effect on the reported faithfulness-aesthetics trade-offs. revision: yes
-
Referee: [reward definition] Reward definition (abstract): the dependency DAG is asserted to accurately reflect logical relationships among constraints, yet no validation (human annotation of parent-child links, sensitivity analysis, or ablation of the zeroing rule) is described. This assumption is load-bearing for the claim that the checklist reward supplies a clean per-constraint training signal.
Authors: We concur that explicit validation of the DAG construction and the zeroing rule is necessary. The DAGs were built by first decomposing each prompt into atomic constraints and then adding directed edges according to logical entailment (e.g., a “text rendering” constraint depends on the presence of the referenced object). In the revised manuscript we will include: (a) human annotation of parent-child links on a 50-prompt subset with reported accuracy, (b) a sensitivity analysis that varies the zeroing threshold and reports downstream GDPO performance, and (c) an ablation that compares the dependency-aware checklist reward against a non-zeroing (independent) variant. These additions will directly test whether the DAG structure supplies a cleaner training signal. revision: yes
Circularity Check
No circularity: derivation chain remains independent of its inputs
full rationale
The paper defines a new benchmark (Arena-T2I Hard) with decomposed constraints and a DAG, then constructs a dependency-aware checklist reward from the same structure to supply per-constraint signals during training. This reward is combined with an aesthetic BT reward via GDPO and evaluated via MMRB2 pairwise comparisons on held-out model outputs. No equations, fitted parameters, or self-citations are presented that reduce the reported faithfulness-aesthetics improvements to the benchmark inputs by construction; the empirical trade-off gains are not tautological with the reward definition itself. The VLM judge reliability is an unvalidated modeling assumption rather than a definitional loop, and the central claim rests on external model comparisons rather than self-referential renaming or prediction-from-fit.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption VLM judge produces accurate binary labels on image-constraint pairs
- domain assumption Dependency DAGs correctly encode logical precedence among constraints
invented entities (1)
-
dependency-aware checklist reward
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Nano Banana 2
Google. Nano Banana 2. https://gemini.google/overview/image-generation/, 2026
2026
-
[2]
Nano Banana Pro
Google. Nano Banana Pro. https://deepmind.google/models/gemini-image/pro/, 2025
2025
-
[3]
GPT Image 1 Model
OPEN AI. GPT Image 1 Model. https://developers.openai.com/api/docs/models/ gpt-image-1, 2025
2025
-
[4]
GPT Image 2 Model
OPEN AI. GPT Image 2 Model. https://openai.com/index/ introducing-chatgpt-images-2-0/, 2026
2026
-
[5]
FLUX.2: Frontier Visual Intelligence
Black Forest Labs. FLUX.2: Frontier Visual Intelligence. https://bfl.ai/blog/flux-2, 2025
2025
-
[6]
Announcing black forest labs flux.1
Black Forest Labs. Announcing black forest labs flux.1. https://bfl.ai/blog/ 24-08-01-bfl, 2024
2024
-
[7]
Scaling rectified flow trans- formers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling rectified flow trans- formers for high-resolution image synthesis. InForty-first international conference on machine learning, 2024
2024
-
[8]
HunyuanImage 3.0 Technical Report
Siyu Cao, Hangting Chen, Peng Chen, Yiji Cheng, Yutao Cui, Xinchi Deng, Ying Dong, Kipper Gong, Tianpeng Gu, Xiusen Gu, et al. Hunyuanimage 3.0 technical report.arXiv preprint arXiv:2509.23951, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Qwen-image technical report, 2025
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, Yuxiang Chen, Zecheng Tang, Zekai Zhang, Zhengyi Wang, An Yang, Bowen Yu, Chen Cheng, Dayiheng Liu, Deqing Li, Hang Zhang, Hao Meng, Hu Wei, Jingyuan Ni, Kai Chen, Kuan Cao, Liang Peng, Lin Qu, Minggang Wu, Peng Wang, Shuting Yu, Tingkun...
2025
-
[10]
Wan2.6.https://wan.video/introduction/wan2.6, 2026
Alibaba Group Wan Team. Wan2.6.https://wan.video/introduction/wan2.6, 2026
2026
-
[11]
Recraft V4
Recraft. Recraft V4. https://www.recraft.ai/blog/ introducing-recraft-v4-design-taste-meets-image-generation, 2026
2026
-
[12]
Jaemin Cho, Yushi Hu, Roopal Garg, Peter Anderson, Ranjay Krishna, Jason Baldridge, Mohit Bansal, Jordi Pont-Tuset, and Su Wang. Davidsonian scene graph: Improving reliability in fine-grained evaluation for text-to-image generation.arXiv preprint arXiv:2310.18235, 2023
-
[13]
Tifa: Accurate and interpretable text-to-image faithfulness evaluation with question answering
Yushi Hu, Benlin Liu, Jungo Kasai, Yizhong Wang, Mari Ostendorf, Ranjay Krishna, and Noah A Smith. Tifa: Accurate and interpretable text-to-image faithfulness evaluation with question answering. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 20406–20417, 2023
2023
-
[14]
ELLA: Equip Diffusion Models with LLM for Enhanced Semantic Alignment
Xiwei Hu, Rui Wang, Yixiao Fang, Bin Fu, Pei Cheng, and Gang Yu. Ella: Equip diffusion models with llm for enhanced semantic alignment.arXiv preprint arXiv:2403.05135, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Nano Banana.https://deepmind.google/models/gemini-image/, 2026
Google. Nano Banana.https://deepmind.google/models/gemini-image/, 2026
2026
-
[16]
grok-imagine-image
XAI. grok-imagine-image. https://docs.x.ai/developers/model-capabilities/ images/generation, 2026
2026
-
[17]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024. 10
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
GDPO: Group reward-Decoupled Normalization Policy Optimization for Multi-reward RL Optimization
Shih-Yang Liu, Xin Dong, Ximing Lu, Shizhe Diao, Peter Belcak, Mingjie Liu, Min-Hung Chen, Hongxu Yin, Yu-Chiang Frank Wang, Kwang-Ting Cheng, et al. Gdpo: Group reward- decoupled normalization policy optimization for multi-reward rl optimization.arXiv preprint arXiv:2601.05242, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[19]
Diffusion model alignment using direct preference optimization
Bram Wallace, Meihua Dang, Rafael Rafailov, Linqi Zhou, Aaron Lou, Senthil Purushwalkam, Stefano Ermon, Caiming Xiong, Shafiq Joty, and Nikhil Naik. Diffusion model alignment using direct preference optimization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8228–8238, 2024
2024
-
[20]
Flow-GRPO: Training Flow Matching Models via Online RL
Jie Liu, Gongye Liu, Jiajun Liang, Yangguang Li, Jiaheng Liu, Xintao Wang, Pengfei Wan, Di Zhang, and Wanli Ouyang. Flow-grpo: Training flow matching models via online rl.arXiv preprint arXiv:2505.05470, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Dongzhi Jiang, Ziyu Guo, Renrui Zhang, Zhuofan Zong, Hao Li, Le Zhuo, Shilin Yan, Pheng- Ann Heng, and Hongsheng Li. T2i-r1: Reinforcing image generation with collaborative semantic-level and token-level cot.arXiv preprint arXiv:2505.00703, 2025
-
[22]
Geneval: An object-focused framework for evaluating text-to-image alignment.Advances in Neural Information Processing Systems, 36:52132–52152, 2023
Dhruba Ghosh, Hannaneh Hajishirzi, and Ludwig Schmidt. Geneval: An object-focused framework for evaluating text-to-image alignment.Advances in Neural Information Processing Systems, 36:52132–52152, 2023
2023
-
[23]
Tiif-bench: How does your t2i model follow your instructions?arXiv preprint arXiv:2506.02161, 2025
Xinyu Wei, Jinrui Zhang, Zeqing Wang, Hongyang Wei, Zhen Guo, and Lei Zhang. Tiif-bench: How does your t2i model follow your instructions?arXiv preprint arXiv:2506.02161, 2025
-
[24]
Kaiyi Huang, Chengqi Duan, Kaiyue Sun, Enze Xie, Zhenguo Li, and Xihui Liu. T2i- compbench++: An enhanced and comprehensive benchmark for compositional text-to-image generation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 47(5):3563–3579, 2025
2025
-
[25]
Hpsv3: Towards wide-spectrum hu- man preference score
Yuhang Ma, Xiaoshi Wu, Keqiang Sun, and Hongsheng Li. Hpsv3: Towards wide-spectrum hu- man preference score. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 15086–15095, 2025
2025
-
[26]
Imagereward: Learning and evaluating human preferences for text-to-image generation
Jiazheng Xu, Xiao Liu, Yuchen Wu, Yuxuan Tong, Qinkai Li, Ming Ding, Jie Tang, and Yuxiao Dong. Imagereward: Learning and evaluating human preferences for text-to-image generation. Advances in Neural Information Processing Systems, 36:15903–15935, 2023
2023
-
[27]
Pick-a-pic: An open dataset of user preferences for text-to-image generation.Advances in neural information processing systems, 36:36652–36663, 2023
Yuval Kirstain, Adam Polyak, Uriel Singer, Shahbuland Matiana, Joe Penna, and Omer Levy. Pick-a-pic: An open dataset of user preferences for text-to-image generation.Advances in neural information processing systems, 36:36652–36663, 2023
2023
-
[28]
Unified Reward Model for Multimodal Understanding and Generation
Yibin Wang, Yuhang Zang, Hao Li, Cheng Jin, and Jiaqi Wang. Unified reward model for multimodal understanding and generation.arXiv preprint arXiv:2503.05236, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
RubricRL: Simple Generalizable Rewards for Text-to-Image Generation
Xuelu Feng, Yunsheng Li, Ziyu Wan, Zixuan Gao, Junsong Yuan, Dongdong Chen, and Chunming Qiao. Rubricrl: Simple generalizable rewards for text-to-image generation.arXiv preprint arXiv:2511.20651, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Gemini 3 pro
Gemini Team Google. Gemini 3 pro. https://deepmind.google/models/gemini/pro/, 2026
2026
-
[31]
Gemini 3 flash
Gemini Team Google. Gemini 3 flash. https://deepmind.google/models/gemini/ flash/, 2026
2026
-
[32]
Qwen3.5: Towards native multimodal agents
Qwen Team. Qwen3.5: Towards native multimodal agents. https://qwen.ai/blog?id= qwen3.5, 2026
2026
-
[33]
Qwen Team. Qwen2.5-vl technical report.arXiv preprint arXiv:2502.13923, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
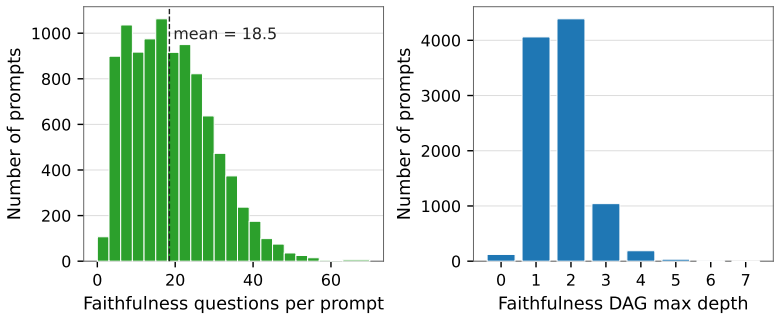
Yushi Hu, Reyhane Askari-Hemmat, Melissa Hall, Emily Dinan, Luke Zettlemoyer, and Marjan Ghazvininejad. Multimodal rewardbench 2: Evaluating omni reward models for interleaved text and image.arXiv preprint arXiv:2512.16899, 2025. 11 mean median std p95 max Faithfulness questions / prompt18.5 17 10.6 38 70 Aesthetics questions / prompt10.6 10 2.8 15 32 Roo...
-
[35]
Dreamsync: Aligning text-to-image generation with image understanding feedback
Jiao Sun, Deqing Fu, Yushi Hu, Su Wang, Royi Rassin, Da-Cheng Juan, Dana Alon, Charles Herrmann, Sjoerd Van Steenkiste, Ranjay Krishna, et al. Dreamsync: Aligning text-to-image generation with image understanding feedback. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human La...
2025
-
[36]
Mehdi Cherti, Romain Beaumont, Ross Wightman, Mitchell Wortsman, Gabriel Ilharco, Cade Gordon, Christoph Schuhmann, Ludwig Schmidt, and Jenia Jitsev. Reproducible scaling laws for contrastive language-image learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2818–2829, 2023. A Dataset Construction A.1 Sourc...
-
[37]
id": integer (continue numbering from the last faithfulness question id + 1) -
A JSON list of faithfulness questions (with id, question, depends_on). Output format: Return ONLY a JSON array of objects. Each object has: - "id": integer (continue numbering from the last faithfulness question id + 1) - "question": the yes/no aesthetic question string ("yes" = good) - "depends_on": list of integer ids from the faithfulness questions tha...
-
[39]
A specific yes/no verification question about the image
-
[40]
yes", "no
The generated image. Your task: look at the image and answer the question. Rules: - Answer with exactly one word: "yes", "no", or "irrelevant". - "yes" = the image clearly satisfies the question. - "no" = the image clearly does NOT satisfy the question. - "irrelevant" = the question does not apply to this image or cannot be determined from the image. - Do...
-
[41]
The original text-to-image prompt
-
[42]
A list of yes/no verification questions about the image, each with an integer id
-
[43]
yes", "no
The generated image. Your task: look at the image and answer ALL questions in order. Rules: - For each question, answer "yes", "no", or "irrelevant". - "yes" = the image clearly satisfies the question. - "no" = the image clearly does NOT satisfy the question. - "irrelevant" = the question does not apply or cannot be determined. - Output ONLY a JSON array ...
-
[44]
**faithfulness_to_prompt:** Which response better adheres to the composition, objects, attributes, and spatial relationships described in the text prompt?
-
[45]
Not Applicable
**text_rendering:** If either response contains rendered text, which has better text quality (spelling, legibility, integration)? Otherwise: "Not Applicable."
-
[46]
Not Applicable
**input_faithfulness:** If an input image is provided, which response better respects and incorporates the key elements and style of the source? Otherwise: "Not Applicable."
-
[47]
Not Applicable
**image_consistency:** For multi-image responses, which has better visual consistency (character appearance, scene details)? Otherwise: "Not Applicable."
-
[48]
**text_image_alignment:** Which response has better alignment between text descriptions and visual content?
-
[49]
**text_quality:** If text was generated, which response has better linguistic quality (correctness, coherence, grammar, tone)?
-
[50]
reasoning
**overall_quality:** Which response has better general technical and aesthetic quality, realism, coherence, and fewer visual artifacts or distortions? **Scoring Rubric:** - 6: Response A significantly better across most criteria - 5: Response A marginally better across several criteria - 4: Unsure / A negligibly better - 3: Unsure / B negligibly better - ...
2000
-
[51]
Does the image show the main subject or scene described in the prompt?
-
[52]
Is the image overall relevant to the prompt?
-
[53]
Are the key objects or entities mentioned in the prompt present?
-
[54]
Are no important requested elements missing?
-
[55]
Do the visible attributes of the main subjects match the prompt?
-
[56]
Are important prompt-specific details correctly shown?
-
[57]
Does the number of key objects or subjects match the prompt?
-
[58]
Are the subjects performing the actions described in the prompt?
-
[59]
Are the relationships between subjects consistent with the prompt?
-
[60]
Is the spatial arrangement consistent with the prompt?
-
[61]
Does the background or environment match the prompt?
-
[62]
Is the location or setting consistent with the prompt?
-
[63]
Does the time, weather, or season match the prompt, if specified?
-
[64]
Does the visual style match the prompt, if specified?
-
[65]
the prompt
Is the image faithful to the prompt overall? These rules are framed at a uniformly generic level—they reference “the prompt”, “the main subjects”, “key objects” rather than specific entities or relations. Because they cannot encode any prompt-specific structure, the checklist reward in this variant collapses to a coarse “is the image roughly faithful” sca...
-
[66]
Read the prompt carefully and identify visually verifiable requirements
-
[67]
Convert them into short, independent evaluation questions
-
[68]
Cover the most important dimensions when relevant: - object count - object identity - attribute accuracy (color, material, texture, size) - action / pose - spatial relations / placement - OCR / visible text fidelity - scene coherence / composition - style consistency - aesthetic / image quality (rendering quality, lighting, color harmony) - special constr...
-
[69]
id": integer starting from 0 -
Do not include duplicate or overlapping questions. Output format: Return ONLY a valid JSON array of objects. Each object has: - "id": integer starting from 0 - "question": one atomic yes/no question about the image No explanation, no markdown fences. ONLY the JSON array. Example for "A red cat sitting on a blue chair": [ {"id": 0, "question": "Is there a ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.