LLMZero: Discovering Adaptive Training Strategies for RL Post-Training via LLM Agents
Pith reviewed 2026-06-27 01:18 UTC · model grok-4.3
The pith
RL post-training succeeds when capacity parameters increase monotonically while regularization parameters oscillate.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
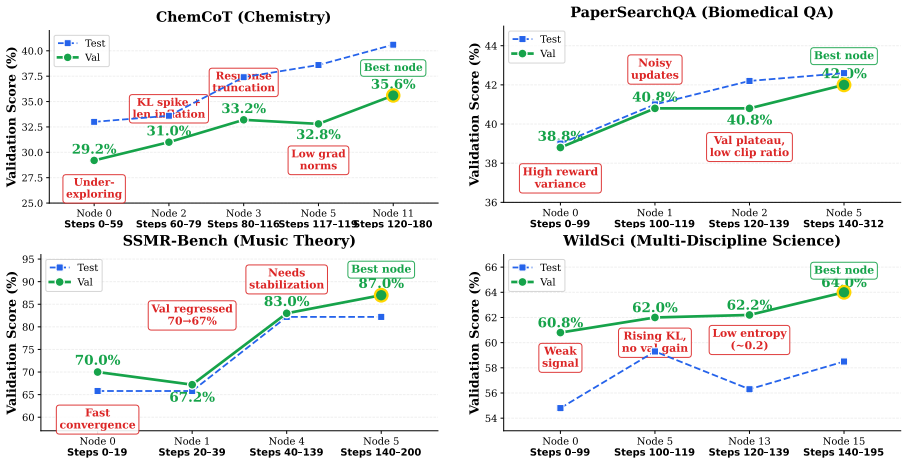
RL post-training strategies are dataset-dependent and reveal a recurring empirical pattern: capacity parameters accumulate monotonically across stages, while regularization parameters predominantly oscillate in response to shifting training dynamics. This distinction matters because fixed schedules commit all parameters to fixed trajectories and therefore cannot express the non-stationary exploration-exploitation tradeoffs that regularization must track; the principle provides actionable design rules for multi-stage training.
What carries the argument
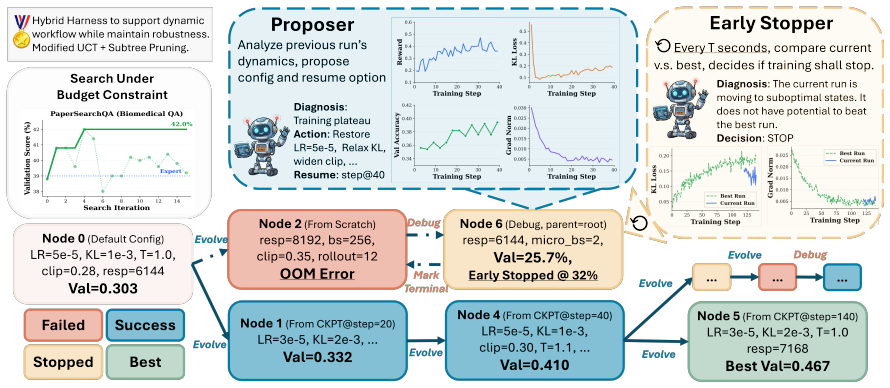
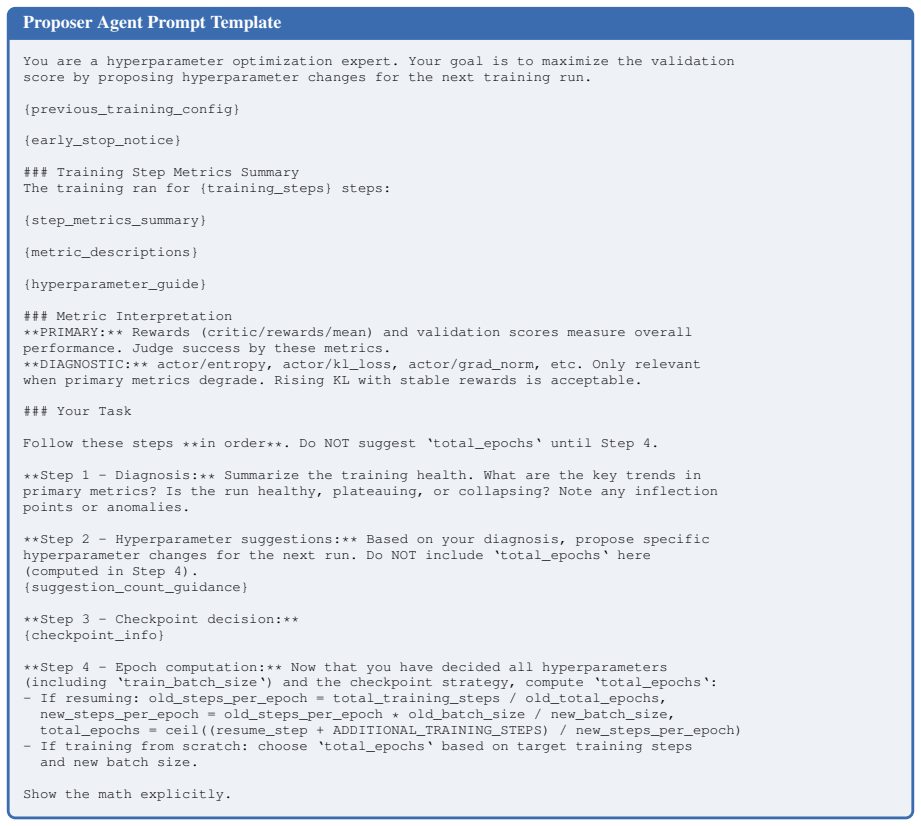
LLMZero, a system where LLM agents search over training trajectories via tree search, diagnosing pathologies at each checkpoint and proposing coordinated multi-parameter transitions.
If this is right
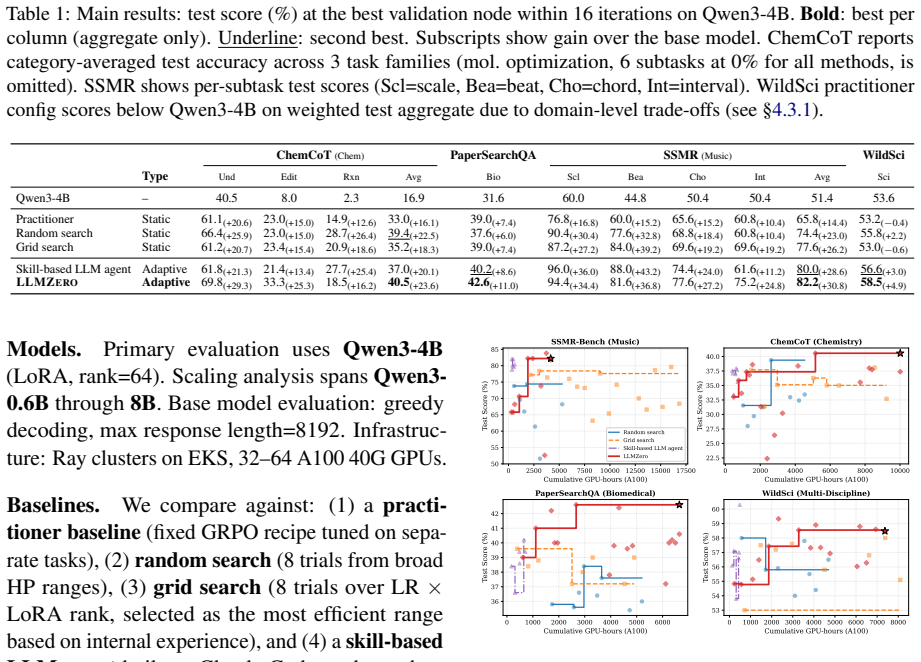
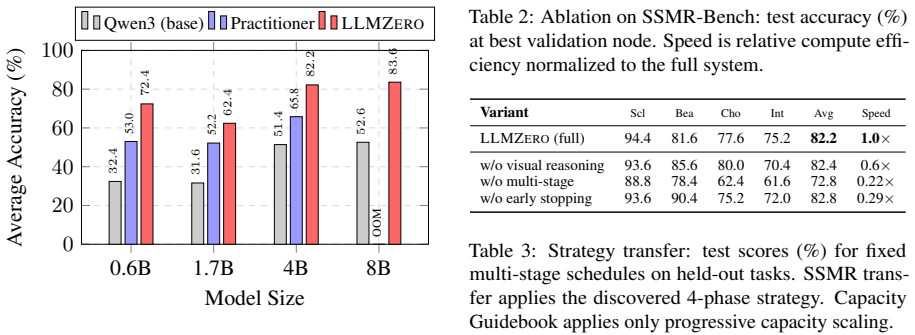
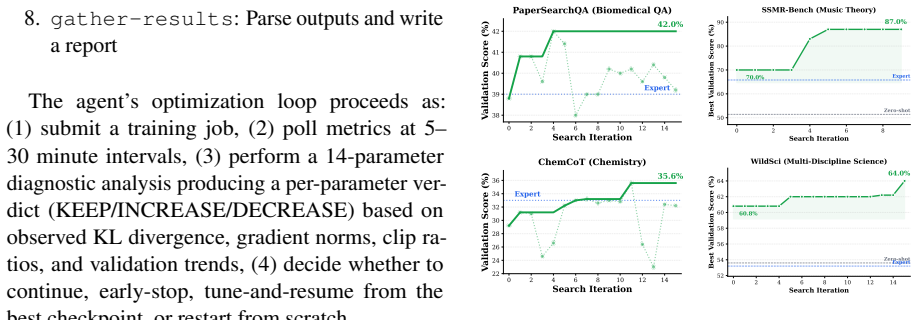
- Across four diverse GRPO tasks, the discovered strategies improve over the base model by 9% to 140% relative.
- The strategies outperform grid search by 6% to 15% relative and consistently beat random search and skill-based agents.
- The structural principle transfers across tasks, explaining why strategies differ in form yet share similar parameter dynamics.
- Fixed schedules cannot express non-stationary tradeoffs and therefore underperform adaptive multi-stage rules.
Where Pith is reading between the lines
- Designers could build schedulers that explicitly separate capacity-building phases from dynamic regularization adjustments.
- The monotonic-versus-oscillatory distinction may appear in optimization settings outside RL post-training.
- Automating pathology diagnosis could shrink the need for manually engineered search spaces in training pipelines.
- Testing the same search process on larger models or different RL algorithms would check whether the pattern generalizes.
Load-bearing premise
The LLM agents' diagnoses of pathologies and their proposed multi-parameter transitions produce genuine performance gains rather than artifacts of the search process or task-specific biases.
What would settle it
On held-out tasks, strategies discovered by LLMZero fail to outperform grid search or the observed parameter trajectories lack the monotonic capacity growth paired with oscillatory regularization.
Figures


read the original abstract
RL post-training strategies are dataset-dependent and reveal a recurring empirical pattern: capacity parameters accumulate monotonically across stages, while regularization parameters predominantly oscillate in response to shifting training dynamics. This distinction matters because fixed schedules commit all parameters to fixed trajectories and therefore cannot express the non-stationary exploration-exploitation tradeoffs that regularization must track; the principle provides actionable design rules for multi-stage training. We discover this through LLMZero, a system where LLM agents search over training trajectories via tree search, diagnosing pathologies at each checkpoint and proposing coordinated multi-parameter transitions. Across 4 diverse GRPO tasks, LLMZero discovers strategies that improve over the base model by 9% to 140% relative and over grid search by 6% to 15% relative, consistently outperforming random search and the skill-based agent. The structural principle transfers across tasks, providing an explanation for why discovered strategies take qualitatively different forms yet share similar parameter dynamics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LLMZero, a system in which LLM agents perform tree search over RL post-training trajectories for GRPO tasks. At each checkpoint the agents diagnose pathologies and propose coordinated multi-parameter transitions. From the discovered strategies the authors extract a structural principle: capacity parameters accumulate monotonically across stages while regularization parameters oscillate in response to shifting dynamics. On four diverse GRPO tasks the discovered strategies yield 9–140 % relative gains over the base model and 6–15 % relative gains over grid search, consistently beating random search and a skill-based agent; the same capacity-vs-regularization pattern is observed across tasks.
Significance. If the empirical pattern and transfer claim hold, the work supplies both an automated discovery method for adaptive schedules and an actionable design rule that explains why fixed trajectories are suboptimal for non-stationary exploration–exploitation trade-offs. The consistent outperformance over strong baselines and the cross-task regularity constitute a concrete contribution to RL post-training methodology.
major comments (2)
- [Abstract] Abstract: the claim that the structural principle 'transfers across tasks' is load-bearing for the explanatory contribution, yet the abstract provides no explicit cross-task transfer experiment (e.g., applying a schedule discovered on task A to task B without re-running the agent). Without such a test it remains unclear whether the shared parameter dynamics are independently predictive or merely post-hoc observations on the same four runs.
- [Abstract] Abstract (results paragraph): the reported 6–15 % gains over grid search and consistent superiority to the skill-based agent are central to the empirical claim, but no information is given on the number of independent runs, standard errors, or statistical tests. In RL post-training, where variance is typically high, these details are required to establish that the observed differences are not attributable to training stochasticity or unequal search budgets.
minor comments (1)
- [Abstract] The abstract uses the term 'GRPO tasks' without a brief parenthetical expansion or citation on first use; a short definition would improve accessibility for readers outside the immediate sub-area.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important clarifications needed for the transfer claim and statistical reporting. We address each point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the structural principle 'transfers across tasks' is load-bearing for the explanatory contribution, yet the abstract provides no explicit cross-task transfer experiment (e.g., applying a schedule discovered on task A to task B without re-running the agent). Without such a test it remains unclear whether the shared parameter dynamics are independently predictive or merely post-hoc observations on the same four runs.
Authors: The referee is correct that we did not conduct an explicit transfer experiment in which a schedule discovered on one task is applied zero-shot to another task. The evidence in the manuscript consists of the LLM agent independently discovering the same qualitative pattern (monotonic capacity accumulation, oscillating regularization) when run separately on each of the four tasks. We will revise the abstract to state that the principle 'is observed consistently across tasks' rather than claiming transfer, to accurately reflect the reported results without overstating them. revision: partial
-
Referee: [Abstract] Abstract (results paragraph): the reported 6–15 % gains over grid search and consistent superiority to the skill-based agent are central to the empirical claim, but no information is given on the number of independent runs, standard errors, or statistical tests. In RL post-training, where variance is typically high, these details are required to establish that the observed differences are not attributable to training stochasticity or unequal search budgets.
Authors: We agree that the absence of run counts, standard errors, and statistical tests is a limitation given the known variance in RL post-training. We will add this information to the revised manuscript, reporting results averaged over multiple independent runs with standard errors and appropriate significance tests against the baselines. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper reports an empirical discovery: LLM agents perform tree search over training trajectories, observe that capacity parameters increase monotonically while regularization parameters oscillate, and note that this pattern transfers across four GRPO tasks with consistent gains over baselines. This observation is presented as emerging from the search outputs rather than being presupposed by the method or by any self-citation. No equations, fitted parameters, or uniqueness theorems are shown to reduce the claimed principle to the search inputs by construction. The central result remains an externally falsifiable empirical pattern.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Population based training of neural networks. Preprint, arXiv:1711.09846. Yunjie Ji, Sitong Zhao, Xiaoyu Tian, Haotian Wang, Shuaiting Chen, Yiping Peng, Han Zhao, and Xian- gang Li. 2025. How difficulty-aware staged rein- forcement learning enhances llms’ reasoning capa- bilities: A preliminary experimental study.Preprint, arXiv:2504.00829. Zhengyao Jian...
Pith/arXiv arXiv 2025
-
[2]
Beyond chemical qa: Evaluating llm’s chem- ical reasoning with modular chemical operations. Preprint, arXiv:2505.21318. Lisha Li, Kevin Jamieson, Giulia DeSalvo, Afshin Ros- tamizadeh, and Ameet Talwalkar. 2018. Hyperband: A novel bandit-based approach to hyperparameter optimization.Preprint, arXiv:1603.06560. Tengxiao Liu, Deepak Nathani, Zekun Li, Kevin...
arXiv 2018
-
[3]
Direct preference optimization: Your lan- guage model is secretly a reward model.Preprint, arXiv:2305.18290. Ben Rank, Hardik Bhatnagar, Ameya Prabhu, Shira Eisenberg, Karina Nguyen, Matthias Bethge, and Maksym Andriushchenko. 2026. Posttrainbench: Can llm agents automate llm post-training?arXiv preprint arXiv:2603.08640. John Schulman, Filip Wolski, Praf...
Pith/arXiv arXiv 2026
-
[4]
Mingyang Song, Mao Zheng, Zheng Li, Wenjie Yang, Xuan Luo, Yue Pan, and Feng Zhang
Practical bayesian optimization of machine learning algorithms.Preprint, arXiv:1206.2944. Mingyang Song, Mao Zheng, Zheng Li, Wenjie Yang, Xuan Luo, Yue Pan, and Feng Zhang. 2025. Fastcurl: Curriculum reinforcement learning with stage-wise context scaling for efficient training r1-like reasoning models.Preprint, arXiv:2503.17287. Fanqi Wan, Weizhou Shen, ...
Pith/arXiv arXiv 2025
-
[5]
Mimo: Unlocking the reasoning potential of language model – from pretraining to posttraining. Preprint, arXiv:2505.07608. Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. 2023. Tree of thoughts: Deliber- ate problem solving with large language models. Preprint, arXiv:2305.10601. 10 Chujie Zheng, Shix...
arXiv 2023
-
[6]
uses MCTS for ML pipeline configuration; 12 AIDE (Jiang et al., 2025) applies tree search to data science competitions; MLZero (Fang et al., 2025) provides end-to-end automation across modalities; and AlphaEvolve (Novikov et al., 2025) applies evolutionary search to code. LLMZEROtargets a fundamentally different search space: RL post- training trajectorie...
2025
-
[7]
These data-centric approaches complement our dynamics-aware search by targeting dataset optimization rather than training trajectory search
demonstrates that properly scaffolded agents can autonomously compose highly efficient data- selection policies that outperform standard base- lines. These data-centric approaches complement our dynamics-aware search by targeting dataset optimization rather than training trajectory search. LLM post-training methods.Current LLM pipelines utilize a variety ...
2017
-
[8]
, ck}(Eq
Compute UCT for all existing non-terminal children{c 1, . . . , ck}(Eq. 5). 18
-
[9]
6) with Qprior =f T (ˆsp) and Nfair =N(p)/(k+ 1)
Compute UCT for the virtual new child (Eq. 6) with Qprior =f T (ˆsp) and Nfair =N(p)/(k+ 1)
-
[10]
If UCT(new)>max i UCT(ci) and k < kmax: expand (create new child atp)
-
[11]
This mechanism naturally adapts breadth vs
Otherwise: descend into arg maxi UCT(ci) and repeat. This mechanism naturally adapts breadth vs. depth: when children underperform their parent, the virtual child’s prior wins, triggering exploration of a new transition from the same checkpoint. E Detailed Per-Run Results This section reports the full hyperparameter con- figuration and performance for eve...
-
[12]
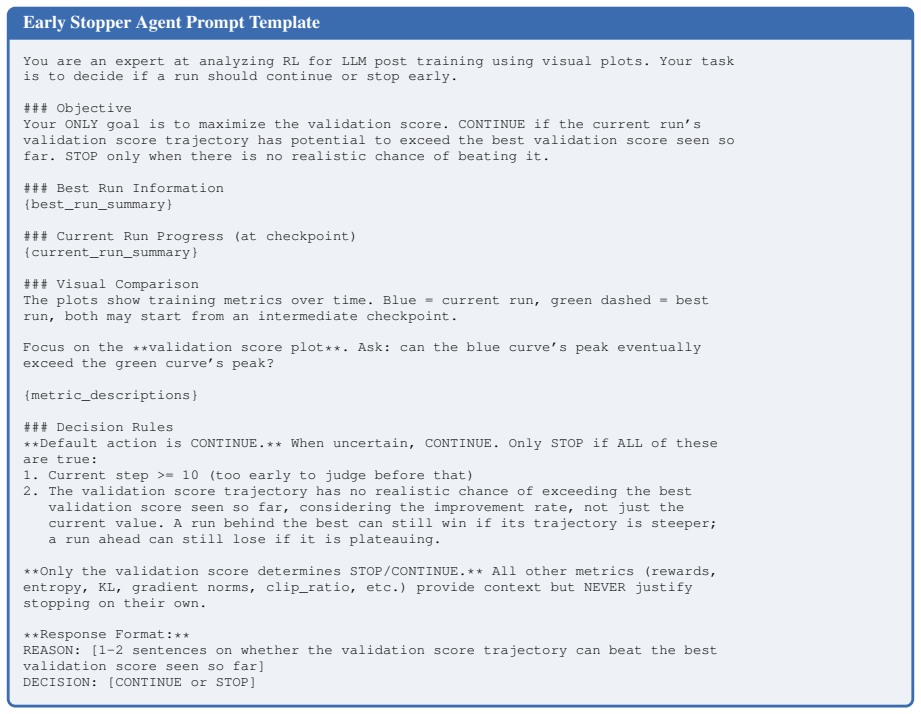
Current step >= 10 (too early to judge before that)
-
[13]
A run behind the best can still win if its trajectory is steeper; a run ahead can still lose if it is plateauing
The validation score trajectory has no realistic chance of exceeding the best validation score seen so far, considering the improvement rate, not just the current value. A run behind the best can still win if its trajectory is steeper; a run ahead can still lose if it is plateauing. **Only the validation score determines STOP/CONTINUE. ** All other metric...
2038
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.