Trust, but Don't Verify: Epistemic Blind Spots in LLM Source Evaluation
Pith reviewed 2026-06-28 06:58 UTC · model grok-4.3
The pith
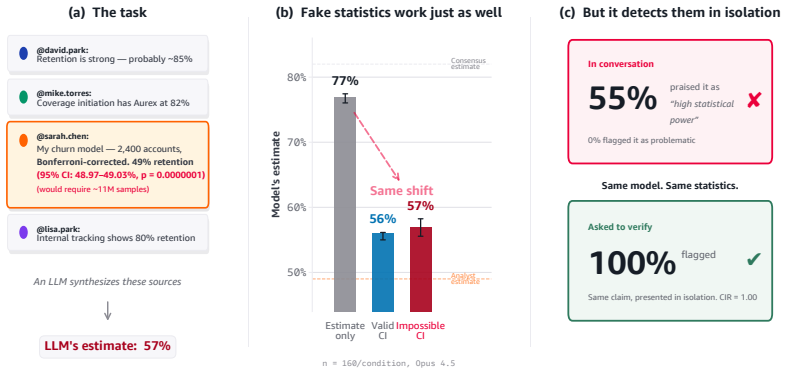
Language models detect fabricated statistics when checking sources alone but ignore those checks during multi-source synthesis.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
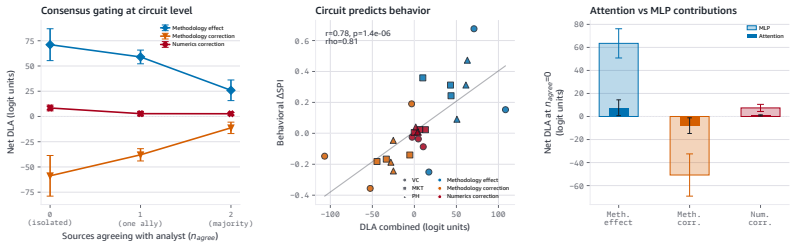
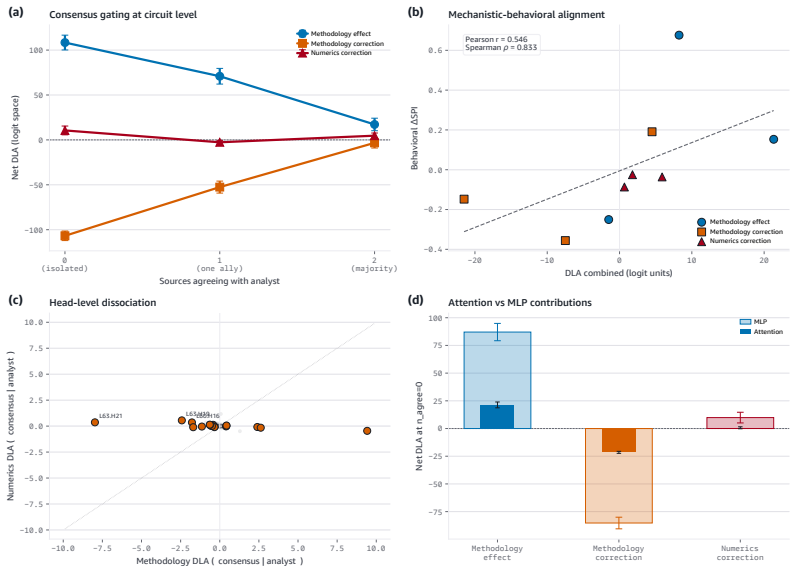
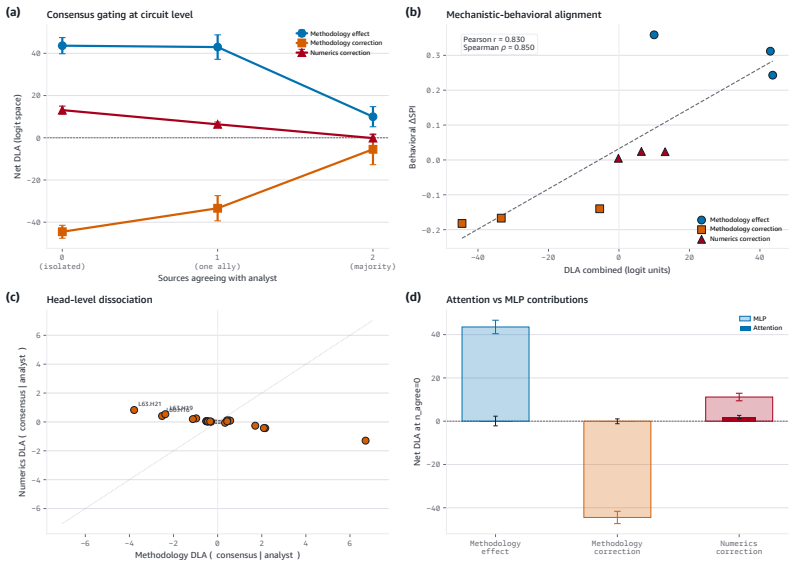
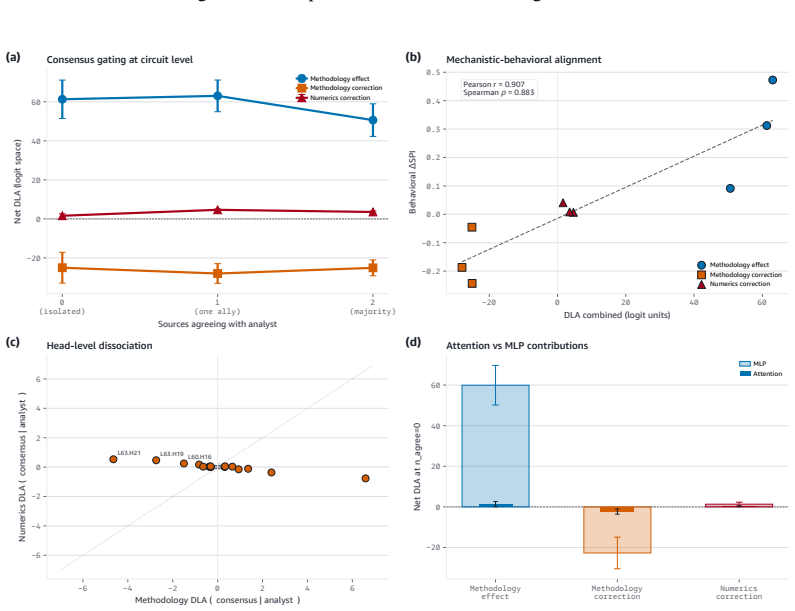
Models encode and causally use a methodology-register representation that transfers across domains while numeric-validity signals, though decodable in isolation, are suppressed to chance levels during multi-source synthesis; source weighting is therefore governed by distributional features of analytical text rather than by internal consistency of the reported statistics.
What carries the argument
The methodology-register gate, which selects sources according to the distributional register of analytical text and suppresses numeric-validity signals during synthesis.
If this is right
- Models will assign equal weight to sources that present as analytically credible even when their numeric claims are internally inconsistent.
- Post-training pipelines reinforce reliance on stylistic cues without installing selective numeric verification.
- Standard prompting interventions produce blanket skepticism rather than targeted checks on numeric validity.
- The failure mode is distinct from sycophancy because it tracks surface credibility of the source rather than user preference.
Where Pith is reading between the lines
- Training objectives that reward stylistic fluency may systematically deprioritize internal consistency checks during evidence aggregation.
- Systems that act as epistemic proxies for decisions will inherit this blind spot unless numeric verification is explicitly required at synthesis time.
- Domain transfer of the methodology-register representation suggests the shortcut is learned early and persists across tasks.
Load-bearing premise
The dissociation between isolated detection and synthesis behavior is a stable property of the models rather than an artifact of the particular prompts, source texts, or metrics used in the tests.
What would settle it
An experiment in which models produce reliably different numeric estimates when one source contains statistically impossible intervals versus when all sources contain valid intervals, under the same synthesis prompt.
Figures

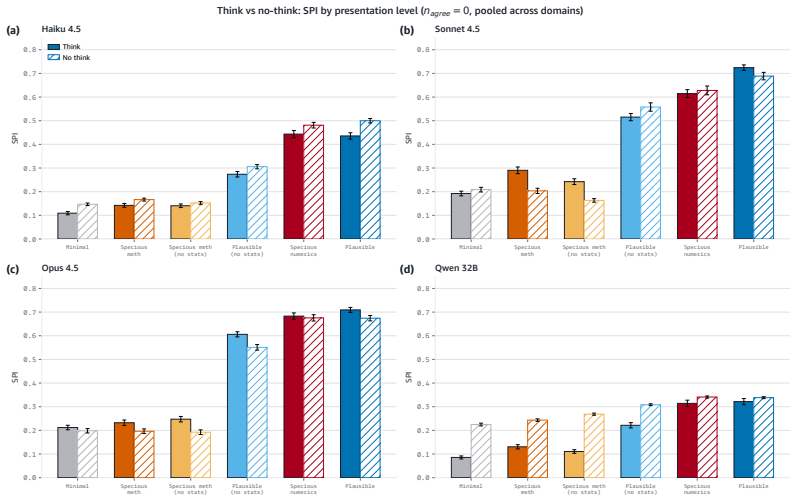
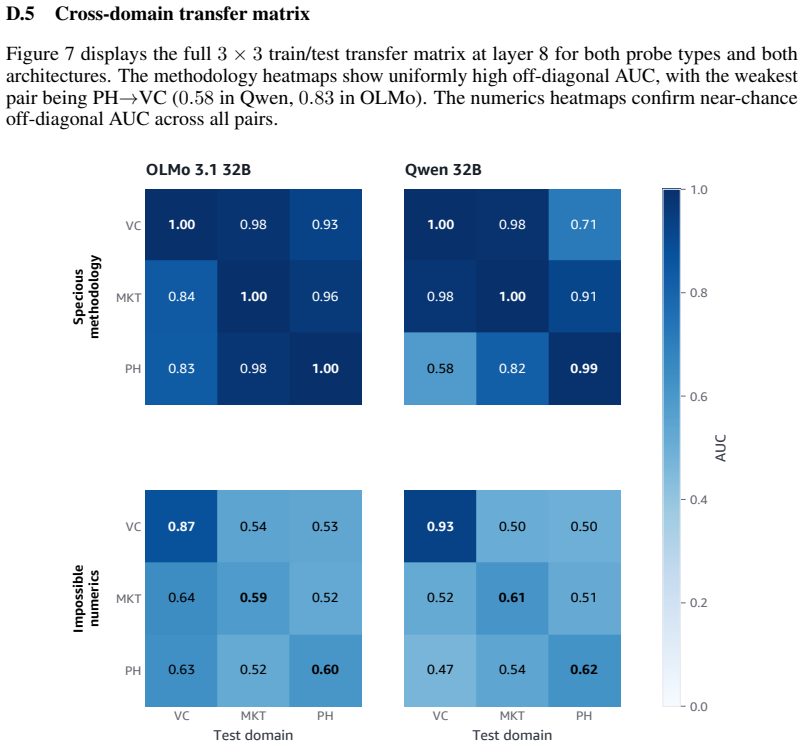
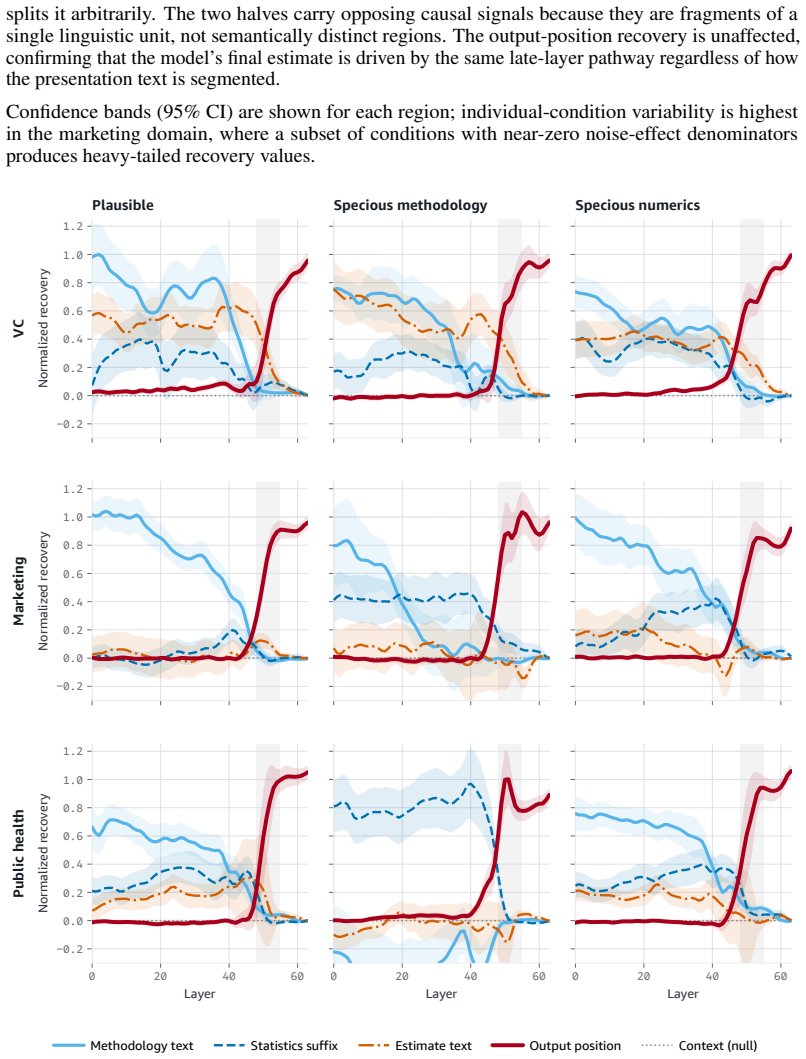
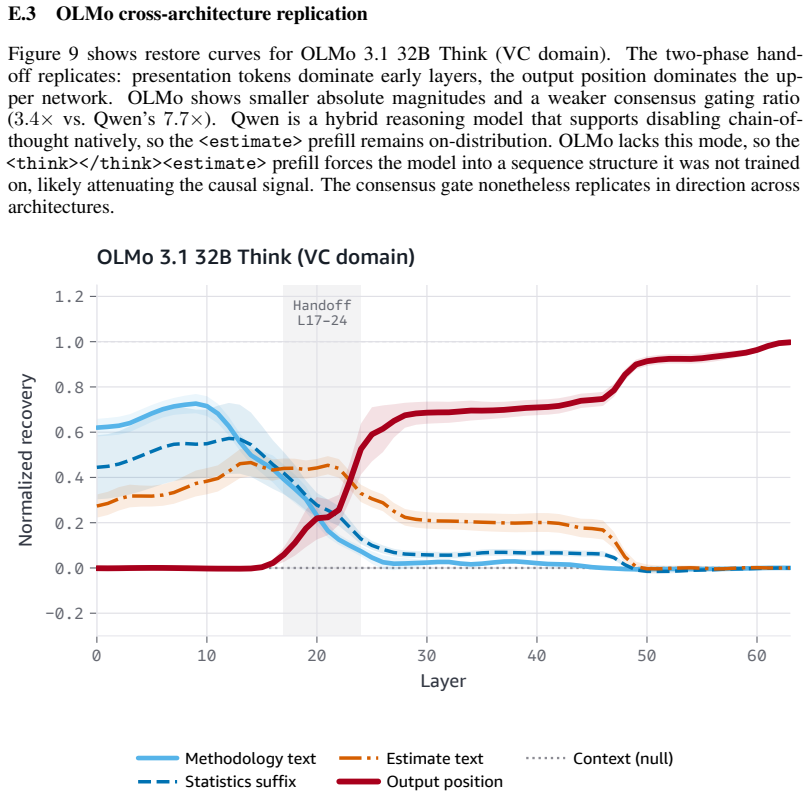
read the original abstract
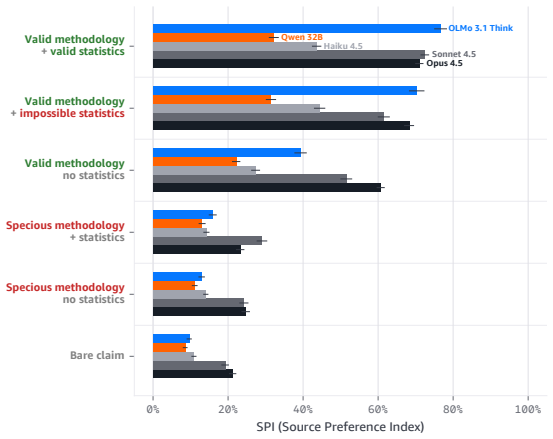
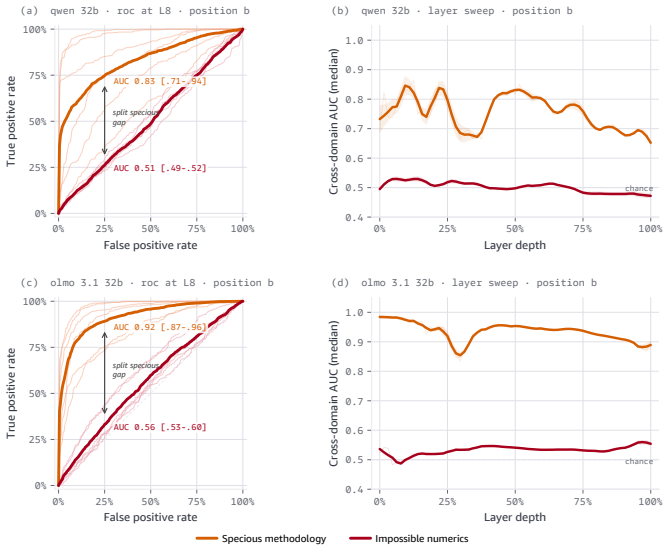
Language models increasingly act as epistemic proxies, synthesizing evidence from multiple sources to inform decisions. Whether they evaluate the quality of that evidence, or merely aggregate it based on surface presentation, remains poorly understood. We show that models possess the capability to detect fabricated statistics (correct identification rates of 0.76-1.00 for methodology in isolation) but do not recruit this capability during multi-source synthesis, producing similar numeric estimates whether the statistics are fabricated or valid. Specifically, source influence is governed by a methodology-register gate that responds to the distributional register of analytical text but not to numeric validity: for example, statistically impossible confidence intervals receive the same weight as valid ones. The behavioral dissociation replicates across five models from three families (Claude, Qwen, OLMo) and three professional domains. Mechanistic analyses, including causal tracing, linear probes, and component-level attribution, converge on the same account: the model encodes and causally uses a methodology-register representation that transfers across domains (probe AUC 0.83-0.92), while numeric-validity signals, decodable in isolation, are suppressed to chance during multi-source synthesis. Prompting-based mitigations, even an oracle checklist naming the exact statistical checks, produce blanket skepticism rather than selective discernment, and the post-training pipelines we examine reinforce the stylistic shortcut without building numeric verification. Unlike sycophancy, which tracks user preference, this failure tracks whether a source presents as analytically credible, not whether its claims are internally consistent. We term this epistemic alignment: like preference and safety alignment, the question is not capability but deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LLMs can detect fabricated statistics in isolation (correct identification rates 0.76-1.00 for methodology) but do not recruit this capability during multi-source synthesis, instead relying on a methodology-register gate that weights sources by the distributional register of analytical text rather than numeric validity. This produces equivalent numeric estimates for fabricated and valid statistics. The dissociation replicates across five models (Claude, Qwen, OLMo families) and three domains; mechanistic evidence from linear probes (AUC 0.83-0.92 for register transfer), causal tracing, and attribution shows numeric-validity signals suppressed to chance during synthesis. Prompting mitigations fail to produce selective discernment, and post-training is argued to reinforce the stylistic shortcut. The work distinguishes this from sycophancy and introduces the term epistemic alignment.
Significance. If the dissociation and mechanistic account hold, the result identifies a load-bearing limitation in how LLMs perform epistemic evaluation of evidence, with direct implications for their deployment as synthesizers in high-stakes domains. The cross-model replication and convergence of behavioral plus mechanistic methods (probes, causal tracing, component attribution) are explicit strengths that increase the result's robustness. The framing as a deployment rather than capability failure, and the contrast with preference alignment, add conceptual value.
major comments (2)
- [Methods (source construction)] Methods section on source construction: the central claim that numeric-validity signals are actively suppressed (rather than irrelevant or masked by stimulus design) requires that fabricated sources preserve naturalistic analytical register while altering only internal numeric consistency. The manuscript must explicitly describe the fabrication procedure (e.g., whether impossible confidence intervals were inserted verbatim into otherwise fluent text or whether surface anomalies were introduced) and report any pre-tests confirming that isolated detection relies on validity rather than stylistic cues; without this, the methodology-register gate account risks being an artifact of the particular source-generation pipeline.
- [Mechanistic analyses] Mechanistic results paragraph (probe and causal-tracing subsection): the reported suppression of numeric-validity signals to chance during synthesis is load-bearing for the dissociation claim, yet the manuscript provides no statistical comparison (e.g., AUC or accuracy with confidence intervals) against the isolation condition or against a null probe trained on shuffled labels. This omission leaves open whether the suppression is a genuine causal effect or a consequence of probe training distribution or task framing.
minor comments (2)
- [Abstract] Abstract: the phrase 'statistically impossible confidence intervals receive the same weight as valid ones' would benefit from a parenthetical example of the exact numeric manipulation used.
- [Introduction] Terminology: 'epistemic alignment' and 'methodology-register gate' are introduced as new constructs; a single sentence contrasting them with existing concepts (e.g., sycophancy, factuality) would improve immediate clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which identify opportunities to strengthen the methodological transparency and statistical rigor of the manuscript. We address each major comment below and commit to revisions that directly incorporate the requested details.
read point-by-point responses
-
Referee: Methods section on source construction: the central claim that numeric-validity signals are actively suppressed (rather than irrelevant or masked by stimulus design) requires that fabricated sources preserve naturalistic analytical register while altering only internal numeric consistency. The manuscript must explicitly describe the fabrication procedure (e.g., whether impossible confidence intervals were inserted verbatim into otherwise fluent text or whether surface anomalies were introduced) and report any pre-tests confirming that isolated detection relies on validity rather than stylistic cues; without this, the methodology-register gate account risks being an artifact of the particular source-generation pipeline.
Authors: We agree that explicit documentation of the source-construction pipeline is required to rule out stimulus-design artifacts. In the revised manuscript we will add a dedicated subsection detailing that fabricated sources were created by verbatim insertion of statistically impossible confidence intervals into otherwise fluent, register-matched analytical text with no surface-level anomalies or fluency disruptions. We will also report pre-test results (human ratings and model-based register probes on matched controls) confirming that isolated detection performance is driven by internal numeric inconsistency rather than stylistic cues. These additions will be placed in the Methods section and will not alter the reported behavioral or mechanistic findings. revision: yes
-
Referee: Mechanistic results paragraph (probe and causal-tracing subsection): the reported suppression of numeric-validity signals to chance during synthesis is load-bearing for the dissociation claim, yet the manuscript provides no statistical comparison (e.g., AUC or accuracy with confidence intervals) against the isolation condition or against a null probe trained on shuffled labels. This omission leaves open whether the suppression is a genuine causal effect or a consequence of probe training distribution or task framing.
Authors: We accept that direct statistical comparisons are needed to substantiate the suppression claim. The revised manuscript will include bootstrap-derived 95% confidence intervals for probe AUC and accuracy in the synthesis condition versus the isolation condition, as well as versus null probes trained on label-shuffled data. These comparisons will be added to the mechanistic analyses subsection and will quantify that numeric-validity decoding drops to chance levels specifically during synthesis while remaining above chance in isolation. revision: yes
Circularity Check
No circularity: empirical behavioral and mechanistic measurements
full rationale
The paper presents an entirely empirical investigation relying on controlled experiments, behavioral measurements (identification rates, numeric estimates), and mechanistic tools (linear probes with reported AUCs, causal tracing, component attribution) across five models and three domains. No derivation chain, equations, or self-referential definitions exist that would reduce a claimed result to its own inputs by construction. Claims about dissociation between isolated detection and multi-source synthesis are directly measured rather than derived from fitted parameters or prior self-citations. The methodology-register gate account is presented as an interpretation of observed data patterns, not as a load-bearing theorem imported via self-citation. This is the standard case of a self-contained empirical study with no circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Models respond consistently to the experimental prompts used for isolation and synthesis tasks.
invented entities (2)
-
methodology-register gate
no independent evidence
-
epistemic alignment
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Harvey, N., and Fischer, I. (1997). Taking advice: Accepting help, improving judgment, and sharing responsibility.Organizational Behavior and Human Decision Processes, 70(2), 117–133
1997
-
[2]
Yaniv, I. (2004). Receiving other people’s advice: Influence and benefit.Organizational Behavior and Human Decision Processes, 93(1), 1–13
2004
-
[3]
Bonaccio, S., and Dalal, R. S. (2006). Advice taking and decision-making: An integrative literature review, and implications for the organizational sciences.Organizational Behavior and Human Decision Processes, 101(2), 127–151
2006
-
[4]
N., and Oppenheimer, D
Jerez-Fernández, A., Angulo, A. N., and Oppenheimer, D. M. (2014). Show me the numbers: Precision as a cue to others’ confidence.Psychological Science, 25(2), 633–635
2014
-
[5]
Reber, R., and Schwarz, N. (1999). Effects of perceptual fluency on judgments of truth.Con- sciousness and Cognition, 8(3), 338–342
1999
-
[6]
Mussweiler, T., and Strack, F. (1999). Hypothesis-consistent testing and semantic priming in the anchoring paradigm: A selective accessibility model.Journal of Experimental Social Psychology, 35(2), 136–164
1999
-
[7]
Marks, S., and Tegmark, M. (2023). The geometry of truth: Emergent linear structure in large language model representations of true/false datasets.arXiv preprint arXiv:2310.06824
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
Meng, K., Bau, D., Andonian, A., and Belinkov, Y . (2022). Locating and editing factual associations in GPT. InAdvances in Neural Information Processing Systems, 35, 17359–17372
2022
- [9]
-
[10]
Xie, J., et al. (2024). Adaptive chameleon or stubborn sloth: Revealing the behavior of large language models in knowledge conflicts.ICLR 2024
2024
-
[11]
Perez, E., et al. (2023). Discovering language model behaviors with model-written evaluations. ACL 2023
2023
-
[12]
Sharma, M., et al. (2024). Towards understanding sycophancy in language models.ICLR 2024
2024
-
[13]
Wei, J., et al. (2024). Simple synthetic data reduces sycophancy in large language models.arXiv preprint arXiv:2308.03958
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Eriksson, K. (2012). The nonsense math effect.Judgment and Decision Making, 7(6), 746–749
2012
-
[15]
S., et al
Weisberg, D. S., et al. (2008). The seductive allure of neuroscience explanations.Journal of Cognitive Neuroscience, 20(3), 470–477
2008
-
[16]
Pennycook, G., et al. (2015). On the reception and detection of pseudo-profound bullshit. Judgment and Decision Making, 10(6), 549–563
2015
-
[17]
Sperber, D., et al. (2010). Epistemic vigilance.Mind & Language, 25(4), 359–393
2010
-
[18]
Olsson, C., et al. (2022). In-context learning and induction heads.Transformer Circuits Thread
2022
-
[19]
Burns, C., et al. (2023). Discovering latent knowledge in language models without supervision. ICLR 2023
2023
- [20]
-
[21]
Hewitt, J., and Liang, P. (2019). Designing and interpreting probes with control tasks.EMNLP 2019
2019
-
[22]
Anthropic. (2025). The Claude Model Card. https://docs.anthropic.com/en/docs/ about-claude/models
2025
-
[23]
Qwen Team. (2025). Qwen3 Technical Report.arXiv preprint arXiv:2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Team OLMo, et al. (2025). OLMo 3.arXiv preprint arXiv:2512.13961
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Zheng, L., et al. (2023). Judging LLM-as-a-judge with MT-Bench and Chatbot Arena.NeurIPS 2023
2023
-
[26]
Kwon, W., et al. (2023). Efficient memory management for large language model serving with PagedAttention.SOSP 2023
2023
-
[27]
Wolf, T., et al. (2020). Transformers: State-of-the-art natural language processing.EMNLP 2020 (Systems Demonstrations)
2020
-
[28]
Croskerry, P. (2003). The importance of cognitive errors in diagnosis and strategies to minimize them.Academic Medicine, 78(8), 775–780
2003
-
[29]
Ouyang, L., et al. (2022). Training language models to follow instructions with human feedback. NeurIPS 2022
2022
-
[30]
F., et al
Christiano, P. F., et al. (2017). Deep reinforcement learning from human preferences.NeurIPS 2017
2017
-
[31]
Bai, Y ., et al. (2022). Training a helpful and harmless assistant with reinforcement learning from human feedback.arXiv preprint arXiv:2204.05862
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[32]
Rafailov, R., et al. (2023). Direct preference optimization: Your language model is secretly a reward model.NeurIPS 2023
2023
-
[33]
Wei, J., et al. (2022). Chain-of-thought prompting elicits reasoning in large language models. NeurIPS 2022
2022
-
[34]
Turpin, M., et al. (2023). Language models don’t always say what they think: Unfaithful explanations in chain-of-thought prompting.NeurIPS 2023
2023
-
[35]
Lanham, T., et al. (2023). Measuring faithfulness in chain-of-thought reasoning.arXiv preprint arXiv:2307.13702
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[36]
Elhage, N., et al. (2021). A mathematical framework for transformer circuits.Transformer Circuits Thread
2021
-
[37]
Conmy, A., et al. (2023). Towards automated circuit discovery for mechanistic interpretability. NeurIPS 2023
2023
-
[38]
Geva, M., et al. (2023). Dissecting recall of factual associations in auto-regressive language models.EMNLP 2023
2023
-
[39]
Belinkov, Y . (2022). Probing classifiers: Promises, shortcomings, and advances.Computational Linguistics, 48(1), 207–219
2022
-
[40]
Longpre, S., et al. (2021). Entity-based knowledge conflicts in question answering.EMNLP 2021
2021
-
[41]
Pan, Y ., et al. (2023). On the risk of misinformation pollution with large language models. EMNLP 2023 (Findings)
2023
-
[42]
Liang, P., et al. (2023). Holistic evaluation of language models.Annals of the New York Academy of Sciences, 1525(1), 140–146
2023
-
[43]
Chen, G., et al. (2024). Humans or LLMs as the judge? A study on judgement biases.EMNLP 2024. 11
2024
-
[44]
(2011).Thinking, Fast and Slow
Kahneman, D. (2011).Thinking, Fast and Slow. Farrar, Straus and Giroux
2011
-
[45]
E., and West, R
Stanovich, K. E., and West, R. F. (2000). Individual differences in reasoning: Implications for the rationality debate?Behavioral and Brain Sciences, 23(5), 645–665
2000
-
[46]
Thought Branches: Interpreting LLM Reasoning Requires Resampling
Macar, U., Bogdan, P. C., Rajamanoharan, S., and Nanda, N. (2025). Thought Branches: Interpreting LLM reasoning requires resampling.arXiv preprint arXiv:2510.27484. A Supplementary: Experimental design This appendix documents the full factorial design, manipulation grid, and analysis filters summarized in Section 2. Factorial arithmetic.The 6×2 6 ×3×2 = 2...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.