Measuring Behavior Portability in Large Language Models
Pith reviewed 2026-06-26 08:57 UTC · model grok-4.3
The pith
Behavioral characterizations of LLMs learned in one decision environment fail to predict choices reliably in payoff-equivalent environments with altered surface presentation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
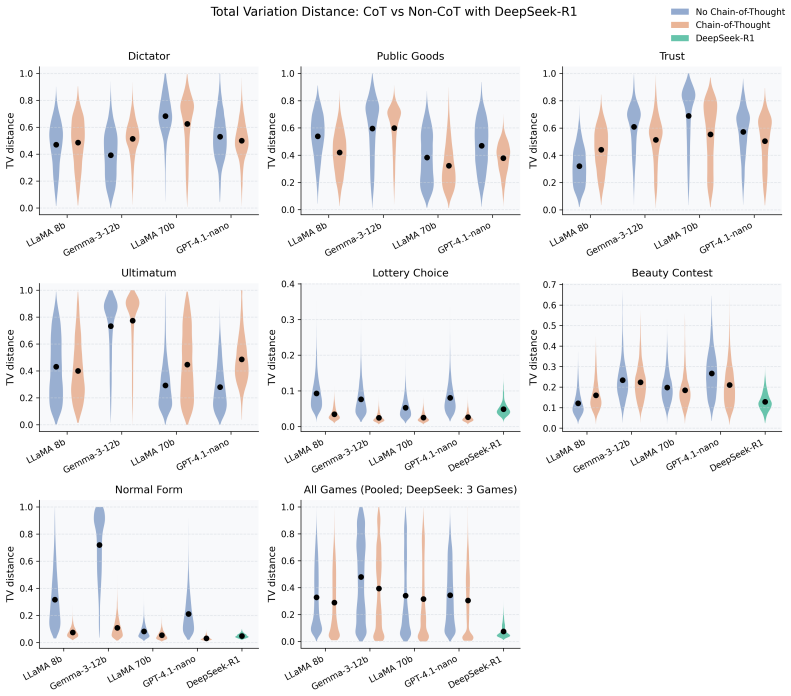
The authors present a formal framework to quantify behavioral portability: fit a behavioral model on data from source environments, then evaluate its out-of-sample predictive performance in a held-out target environment that preserves identical incentive structure while changing only surface presentation; portability is measured by a loss-agnostic quantity that supplies worst-case bounds on the induced prediction-action mapping relative to an oracle trained on target data. Controlled experiments on seven economic decision problems document substantial and systematic portability losses.
What carries the argument
A cross-environment evaluation protocol that pools source data to fit a behavioral model and scores its predictive accuracy in a structurally equivalent but held-out target environment against an oracle baseline.
If this is right
- Single-environment evaluations of LLM decision behavior cannot be treated as reliable characterizations.
- Suite-based benchmarking of LLMs as decision makers becomes fragile when environments differ only in presentation.
- Behavioral models fitted to LLMs require explicit testing for transfer across equivalent incentive structures.
- Deployment of LLMs in autonomous roles must account for sensitivity to surface framing even when payoffs remain fixed.
Where Pith is reading between the lines
- If portability losses persist under richer prompting or fine-tuning, then environment-specific calibration may be required for each new deployment context.
- The framework could be extended to test whether certain classes of economic problems exhibit lower portability losses than others, guiding which domains allow safer transfer.
- The same protocol might reveal whether human decision makers exhibit comparable portability failures, providing a baseline for interpreting LLM results.
Load-bearing premise
Source and target environments are constructed to be payoff-equivalent, so any observed performance gap must stem from lack of portability rather than differences in underlying incentives.
What would settle it
Finding zero or negligible performance gap between the source-fitted behavioral model and the target oracle across multiple held-out environments would falsify the claim of substantial portability losses.
Figures
read the original abstract
Large language models are increasingly deployed as autonomous decision makers, yet the behavioral mapping they exhibit can vary substantially across decision environments that are payoff-equivalent by construction-environments that share identical payoff-relevant structure but differ in surface presentation. This sensitivity renders suite-based evaluation fragile and raises a fundamental question of behavioral portability: how well does a behavioral mapping learned in one decision environment informative on another that preserves the same underlying incentive structure? We introduce a formal framework to measure this property. Our protocol fits an interpretable behavioral model on data pooled from a set of source environments and evaluates its out-of-sample predictive performance in a held-out target environment, benchmarking against an oracle trained directly on target data. Portability is quantified via a loss-agnostic measure that delivers worst-case bounds on the performance of the induced prediction-action mapping in the target environment. In controlled experiments spanning seven canonical economic decision problems, we document substantial and systematic portability losses, suggesting that behavioral characterizations of LLMs obtained in one decision environment cannot be assumed to transfer reliably to structurally equivalent alternatives.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that behavioral mappings exhibited by LLMs in one decision environment do not transfer reliably to structurally equivalent alternatives that differ only in surface presentation. It introduces a formal protocol that fits an interpretable behavioral model on pooled data from source environments, evaluates out-of-sample predictive performance in a held-out target environment against an oracle trained on target data, and quantifies portability via a loss-agnostic measure that provides worst-case bounds. Controlled experiments across seven canonical economic decision problems document substantial and systematic portability losses.
Significance. If the result holds, the work identifies a fundamental limitation in suite-based evaluation of LLMs as autonomous decision makers and provides a quantitative framework for assessing behavioral portability. The use of an independent oracle benchmark (rather than a fitted quantity) is a strength that avoids circularity. The findings, if robust, would imply that environment-specific characterizations cannot be assumed to generalize even when payoff-relevant structure is preserved.
major comments (2)
- [Abstract / protocol description] The central claim requires that observed performance gaps are caused by surface presentation rather than hidden differences in incentives. The abstract asserts that environments are 'payoff-equivalent by construction' and 'share identical payoff-relevant structure,' yet supplies no explicit statement of how equivalence is enforced (identical utility functions, game trees, information partitions). This verification is load-bearing for attributing gaps to lack of portability rather than construction artifacts.
- [Abstract] The abstract states the protocol and reports substantial losses but supplies no details on the behavioral model, the exact loss function, statistical tests, or data exclusion rules. Without these, it is not possible to verify whether the reported losses support the claim that characterizations cannot be assumed to transfer.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment below and note planned revisions.
read point-by-point responses
-
Referee: [Abstract / protocol description] The central claim requires that observed performance gaps are caused by surface presentation rather than hidden differences in incentives. The abstract asserts that environments are 'payoff-equivalent by construction' and 'share identical payoff-relevant structure,' yet supplies no explicit statement of how equivalence is enforced (identical utility functions, game trees, information partitions). This verification is load-bearing for attributing gaps to lack of portability rather than construction artifacts.
Authors: We agree that explicit verification of payoff equivalence is load-bearing. The full manuscript (Section 2.2 and Appendix A) constructs all environments with identical utility functions, game trees, and information partitions, differing only in surface presentation. We will revise the abstract to include a concise statement confirming that equivalence is enforced via these identical payoff-relevant components. revision: yes
-
Referee: [Abstract] The abstract states the protocol and reports substantial losses but supplies no details on the behavioral model, the exact loss function, statistical tests, or data exclusion rules. Without these, it is not possible to verify whether the reported losses support the claim that characterizations cannot be assumed to transfer.
Authors: The abstract is a high-level summary per standard practice. Full details appear in the body: the behavioral model is a parametric linear utility model fit by maximum likelihood (Section 3), the loss is negative log-likelihood (Section 4.1), tests use paired t-tests with correction (Section 5), and exclusion rules cover reaction time and dominance violations (Appendix B). We will add one sentence to the abstract noting the use of an interpretable parametric model. revision: partial
Circularity Check
No significant circularity; evaluation uses independent oracle benchmark
full rationale
The protocol fits an interpretable behavioral model on pooled source-environment data then evaluates out-of-sample predictive performance in a held-out target environment, benchmarking against an oracle trained directly on target data. This is a standard cross-validation structure whose portability loss measure is defined relative to the independent oracle rather than reducing to any fitted parameter or self-citation by construction. No load-bearing self-citations, uniqueness theorems, or ansatzes appear in the derivation; the payoff-equivalence premise is an explicit modeling assumption whose verification lies outside the measure itself.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Decision environments can share identical payoff-relevant structure while differing only in surface presentation.
invented entities (1)
-
loss-agnostic portability measure
no independent evidence
Reference graph
Works this paper leans on
-
[1]
2009 , publisher =
Dataset Shift in Machine Learning , editor =. 2009 , publisher =
2009
-
[2]
Machine Learning , volume =
A theory of learning from different domains , author =. Machine Learning , volume =. 2010 , doi =
2010
-
[3]
Proceedings of the Twenty-Sixth AAAI Conference on Artificial Intelligence (AAAI) , year =
Transportability of Causal Effects: Completeness Results , author =. Proceedings of the Twenty-Sixth AAAI Conference on Artificial Intelligence (AAAI) , year =
-
[4]
Journal of the Royal Statistical Society: Series B (Statistical Methodology) , volume =
Causal inference by using invariant prediction: Identification and confidence intervals , author =. Journal of the Royal Statistical Society: Series B (Statistical Methodology) , volume =. 2016 , doi =
2016
-
[5]
Holistic Evaluation of Language Models
Holistic Evaluation of Language Models , author =. 2022 , howpublished =. doi:10.48550/arXiv.2211.09110 , url =. 2211.09110 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2211.09110 2022
-
[6]
Journal of Machine Learning Research , volume =
PromptBench: A Unified Library for Evaluation of Large Language Models , author =. Journal of Machine Learning Research , volume =. 2024 , url =
2024
-
[7]
Findings of the Association for Computational Linguistics: EMNLP 2024 , month = nov, year =
A Prompt Sensitivity Index for Large Language Models , author =. Findings of the Association for Computational Linguistics: EMNLP 2024 , month = nov, year =. doi:10.18653/v1/2024.findings-emnlp.852 , url =
-
[8]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , author =. 2022 , howpublished =. doi:10.48550/arXiv.2201.11903 , url =. 2201.11903 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2201.11903 2022
-
[9]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Self-Consistency Improves Chain of Thought Reasoning in Language Models , author =. 2022 , howpublished =. doi:10.48550/arXiv.2203.11171 , url =. 2203.11171 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2203.11171 2022
-
[10]
Proceedings of the 40th International Conference on Machine Learning , pages =
Using Large Language Models to Simulate Multiple Humans and Replicate Human Subject Studies , author =. Proceedings of the 40th International Conference on Machine Learning , pages =. 2023 , editor =
2023
-
[11]
2023 , month = apr, doi =
Large Language Models as Simulated Economic Agents: What Can We Learn from Homo Silicus? , author =. 2023 , month = apr, doi =
2023
-
[12]
Proceedings of the National Academy of Sciences , year =
Using large language models to categorize strategic situations and decipher motivations behind human behaviors , author =. Proceedings of the National Academy of Sciences , year =. doi:10.1073/pnas.2512075122 , url =
-
[13]
State of What Art? A Call for Multi-Prompt LLM Evaluation
Mizrahi, Moran and Kaplan, Guy and Malkin, Dan and Dror, Rotem and Shahaf, Dafna and Stanovsky, Gabriel. State of What Art? A Call for Multi-Prompt LLM Evaluation. Transactions of the Association for Computational Linguistics. 2024. doi:10.1162/tacl_a_00681
-
[14]
Findings of the Association for Computational Linguistics: EMNLP 2024 , month = nov, year =
Zhuo, Jingming and Zhang, Songyang and Fang, Xinyu and Duan, Haodong and Lin, Dahua and Chen, Kai. P ro SA : Assessing and Understanding the Prompt Sensitivity of LLM s. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.108
-
[15]
The Transfer Performance of Economic Models , author =. 2022 , journal =. doi:10.48550/arXiv.2202.04796 , url =
-
[16]
On the Worst Prompt Performance of Large Language Models , author =. 2024 , journal =. doi:10.48550/arXiv.2406.10248 , url =
-
[17]
POSIX: A Prompt Sensitivity Index for Large Language Models.EMNLP Findings, 2024
POSIX: A Prompt Sensitivity Index For Large Language Models , author =. 2024 , journal =. doi:10.48550/arXiv.2410.02185 , url =
-
[18]
PromptBench: A Unified Library for Evaluation of Large Language Models , author =. 2023 , journal =. doi:10.48550/arXiv.2312.07910 , url =
-
[19]
ASSERT: Automated Safety Scenario Red Teaming for Evaluating the Robustness of Large Language Models , author =. 2023 , journal =. doi:10.48550/arXiv.2310.09624 , url =
-
[20]
Are All Prompt Components Value-Neutral? Understanding the Heterogeneous Adversarial Robustness of Dissected Prompt in Large Language Models , author =. 2025 , journal =. doi:10.48550/arXiv.2508.01554 , url =
-
[21]
T., Wu, T., Guestrin, C., & Singh, S
Ribeiro, Marco Tulio and Wu, Tongshuang and Guestrin, Carlos , booktitle =. Beyond Accuracy: Behavioral Testing of. 2020 , publisher =. doi:10.18653/v1/2020.acl-main.442 , url =
-
[22]
Goel, Karan and others , year =. Robustness Gym: Unifying the. arXiv preprint arXiv:2101.04840 , doi =
-
[23]
2020 , publisher =
Morris, John and Lifland, Eli and Yoo, Jin Yong and Grigsby, Jake and Jin, Di and Qi, Yanjun , booktitle =. 2020 , publisher =
2020
-
[24]
Invariant Risk Minimization , author =. 2019 , journal =. doi:10.48550/arXiv.1907.02893 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1907.02893 2019
-
[25]
2025 , month = apr, day =
Introducing. 2025 , month = apr, day =
2025
-
[26]
arXiv preprint arXiv:2503.19786 , year =
-
[27]
arXiv preprint arXiv:2407.21783 , year =
Grattafiori, Aaron and Dubey, Abhimanyu and Jauhri, Abhinav and Pandey, Abhinav and others , title =. arXiv preprint arXiv:2407.21783 , year =
-
[28]
Nature , volume =
Guo, Daya and Yang, Dejian and Zhang, Haowei and Song, Junxiao and Wang, Peiyi and others , title =. Nature , volume =. 2025 , doi =
2025
-
[29]
Minds and Machines , volume =
Gabriel, Iason , title =. Minds and Machines , volume =. 2020 , doi =
2020
-
[30]
Proceedings of the 41st International Conference on Machine Learning , series =
Sorensen, Taylor and Moore, Jared and Fisher, Jillian and Gordon, Mitchell and Mireshghallah, Niloofar and Rytting, Christopher Michael and Ye, Andre and Jiang, Liwei and Lu, Ximing and Dziri, Nouha and Althoff, Tim and Choi, Yejin , title =. Proceedings of the 41st International Conference on Machine Learning , series =. 2024 , publisher =
2024
-
[31]
and Jacobs, Bob M
Conitzer, Vincent and Freedman, Rachel and Heitzig, Jobst and Holliday, Wesley H. and Jacobs, Bob M. and Lambert, Nathan and Moss. Position: Social Choice Should Guide. Proceedings of the 41st International Conference on Machine Learning , series =. 2024 , publisher =
2024
-
[32]
Journal of Economic Theory , volume =
Maskin, Eric and Tirole, Jean , title =. Journal of Economic Theory , volume =. 2001 , doi =
2001
-
[33]
arXiv preprint arXiv:2603.23720 , year=
The Effect of Age at Arrival on the Alignment Between Immigrant and Native-Born Gender Norms: A Distributional Approach , author=. arXiv preprint arXiv:2603.23720 , year=
-
[34]
2017 , publisher=
Markov chains and mixing times , author=. 2017 , publisher=
2017
-
[35]
Advances in neural information processing systems , volume=
Can large language model agents simulate human trust behavior? , author=. Advances in neural information processing systems , volume=
-
[36]
arXiv preprint arXiv:1804.04268 , year=
Incomplete Contracting and AI Alignment , author=. arXiv preprint arXiv:1804.04268 , year=
-
[37]
Proceedings of the National Academy of Sciences , volume=
A Turing test of whether AI chatbots are behaviorally similar to humans , author=. Proceedings of the National Academy of Sciences , volume=. 2024 , doi=
2024
-
[38]
Economics Bulletin , volume=
Playing games with GPT: What can we learn about a large language model from canonical strategic games? , author=. Economics Bulletin , volume=
-
[39]
2023 , eprint=
GPT in Game Theory Experiments , author=. 2023 , eprint=
2023
-
[40]
Proceedings of the National Academy of Sciences , volume=
The emergence of economic rationality of GPT , author=. Proceedings of the National Academy of Sciences , volume=. 2023 , doi=
2023
-
[41]
Scientific Reports , volume=
Strategic behavior of large language models and the role of game structure versus contextual framing , author=. Scientific Reports , volume=. 2024 , doi=
2024
-
[42]
Advances in Neural Information Processing Systems , year=
Can Large Language Model Agents Simulate Human Trust Behavior? , author=. Advances in Neural Information Processing Systems , year=
-
[43]
Nature Human Behaviour , volume=
Playing repeated games with large language models , author=. Nature Human Behaviour , volume=. 2025 , doi=
2025
-
[44]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Can Large Language Models Serve as Rational Players in Game Theory? A Systematic Analysis , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=. 2024 , doi=
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.