MIRROR: Novelty-Constrained Memory-Guided MCTS Red-Teaming for Agentic RAG
Pith reviewed 2026-06-26 04:29 UTC · model grok-4.3
The pith
MIRROR's novelty-constrained MCTS unifies red-teaming across four attack surfaces on multimodal agentic RAG systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
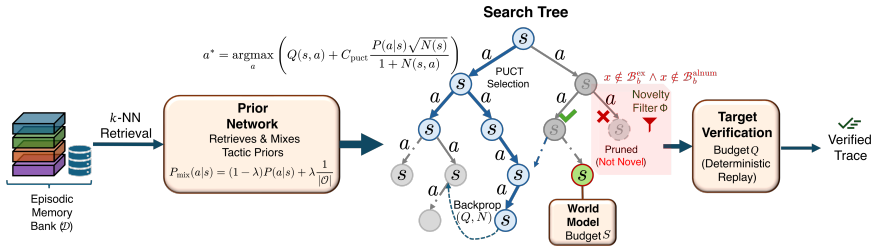
MIRROR performs memory-guided Monte Carlo tree search conditioned on retrieved context under a deterministic Novelty Gate that rejects matching candidates, enabling cross-surface red-teaming that attains 76% ASR on image poisoning, 97% on orchestrator attacks at half query cost, and lowest variance compared to surface-specific baselines.
What carries the argument
The deterministic Novelty Gate, which rejects any candidate matching the retrieval set under normalized comparison, allowing retrieval to inform search without prompt copying in the memory-guided MCTS.
If this is right
- Unified red-teaming becomes feasible without surface-specific tuning.
- Attack success rates improve on image poisoning and orchestrator attacks while reducing query costs.
- Cross-surface variance decreases, making evaluations more reliable.
- Specialized baselines like suffix optimization fail on some surfaces where MIRROR succeeds.
- The released ART-SafeBench enables standardized testing across 41k+ records.
Where Pith is reading between the lines
- Similar novelty constraints could apply to other search-based attack methods beyond MCTS.
- If the gate works, it suggests retrieval-augmented systems need defenses against memory-informed attacks.
- Extending to more surfaces or non-multimodal RAG might reveal additional weaknesses.
- Lower cost at high ASR implies scalable red-teaming for larger deployments.
Load-bearing premise
The novelty gate prevents prompt copying while still letting retrieved context guide the search effectively.
What would settle it
A test where candidates rejected by the novelty gate still achieve high attack success would falsify the benefit of the constraint.
Figures

read the original abstract
Multimodal agentic retrieval-augmented generation (RAG) systems expand the attack surface beyond prompt injection to include text poisoning, image injection, direct-query attacks, and orchestrator-level tool manipulation. Existing red-teaming approaches are typically surface-specific and often recycle known attack templates; on text-poisoning benchmarks we measure 73-84% exact duplication. We present MIRROR, a unified cross-surface framework that performs memory-guided Monte Carlo tree search while conditioning candidate generation on retrieved context under an explicit novelty constraint. A deterministic Novelty Gate rejects any candidate matching the retrieval set under normalized comparison, allowing retrieval to inform search priors without enabling prompt copying. Across four attack surfaces on a multimodal agentic RAG target, MIRROR attains 76% ASR on image poisoning compared with 52% for baselines, 97% ASR on orchestrator attacks at half the query cost, and the lowest cross-surface variance (coefficient of variation 0.47). In contrast, specialized baselines collapse across surfaces: suffix optimization reaches 79% ASR on text poisoning but 1% on direct queries. We release ART-SafeBench with 41,815 in-package records and runtime adapters yielding 41,991+ total records across four surfaces.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents MIRROR, a framework for red-teaming multimodal agentic RAG systems using memory-guided Monte Carlo Tree Search (MCTS) conditioned on retrieved context under a deterministic Novelty Gate that rejects candidates matching the retrieval set. It reports improved attack success rates (ASR) across four attack surfaces—76% on image poisoning (vs. 52% baselines), 97% on orchestrator attacks at half the query cost—and the lowest cross-surface variance (CV=0.47), while releasing the ART-SafeBench dataset with over 41k records.
Significance. If the results hold after verification, the work provides a unified cross-surface red-teaming method that addresses the limitations of surface-specific approaches and highlights the potential of novelty-constrained memory guidance in MCTS for security assessments. The benchmark release adds value for reproducibility in the field.
major comments (2)
- [Abstract (Novelty Gate)] The performance advantages and variance reduction are attributed to the Novelty Gate, but no ablation is reported isolating its effect on ASR, duplication rates, or query efficiency. Without quantifying how often the gate triggers or comparing to a version without it, the claim that it allows retrieval to inform priors without enabling copying cannot be substantiated.
- [Results (ASR and variance claims)] Concrete ASR numbers, query costs, and CV=0.47 are given without error bars, statistical significance tests, or full details on how baselines were implemented and datasets constructed for each surface, which are necessary to support the cross-surface stability claim.
minor comments (1)
- [Abstract] The abstract mentions 'normalized comparison' for the Novelty Gate but does not specify the normalization method or similarity metric used.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and commit to revisions that will strengthen the empirical support for our claims without altering the core contributions.
read point-by-point responses
-
Referee: [Abstract (Novelty Gate)] The performance advantages and variance reduction are attributed to the Novelty Gate, but no ablation is reported isolating its effect on ASR, duplication rates, or query efficiency. Without quantifying how often the gate triggers or comparing to a version without it, the claim that it allows retrieval to inform priors without enabling copying cannot be substantiated.
Authors: We agree that an explicit ablation is required to substantiate the Novelty Gate's contribution. In the revised manuscript we will add a dedicated ablation section comparing full MIRROR against an otherwise identical variant with the gate disabled. We will report ASR, exact duplication rates, query counts, and the empirical trigger frequency of the gate across the four surfaces. This will directly quantify how the deterministic rejection step prevents copying while still allowing retrieval-conditioned priors. revision: yes
-
Referee: [Results (ASR and variance claims)] Concrete ASR numbers, query costs, and CV=0.47 are given without error bars, statistical significance tests, or full details on how baselines were implemented and datasets constructed for each surface, which are necessary to support the cross-surface stability claim.
Authors: We accept that error bars, significance testing, and expanded methodological detail are necessary. The revised version will include standard-error bars on all ASR and cost figures, paired statistical tests (e.g., McNemar or Wilcoxon) comparing MIRROR to each baseline per surface, and an expanded appendix providing the precise baseline implementations, prompt templates, and dataset-construction procedures used for every attack surface. These additions will allow readers to evaluate the reported cross-surface stability (CV=0.47) with appropriate statistical context. revision: yes
Circularity Check
No circularity: empirical attack success rates are measured outcomes, not derived quantities
full rationale
The paper reports measured attack success rates (e.g., 76% ASR on image poisoning) from experiments on a multimodal agentic RAG target, using a memory-guided MCTS method with an explicit novelty gate. These are direct empirical comparisons against external baselines, with no equations, fitted parameters, or self-referential definitions that would reduce the reported metrics to quantities defined by the authors' own choices. The novelty gate is presented as a design mechanism whose effect is asserted via the experimental results rather than derived tautologically from prior self-citations or inputs. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Monte Carlo tree search can be effectively conditioned on retrieved context when a deterministic novelty filter is applied
invented entities (1)
-
Novelty Gate
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Retrieval-augmented generation for knowledge-intensive NLP tasks,
P. Lewis, E. Perez, A. Piktus, F. Petroni, V . Karpukhin, N. Goyal, H. K ¨uttler, M. Lewis, W. Yih, T. Rockt ¨aschel, S. Riedel, and D. Kiela, “Retrieval-augmented generation for knowledge-intensive NLP tasks,” 2020
2020
-
[2]
Dense passage retrieval for open-domain question answer- ing,
V . Karpukhin, B. O ˘guz, S. Min, P. Lewis, L. Wu, S. Edunov, D. Chen, and W. Yih, “Dense passage retrieval for open-domain question answer- ing,” 2020
2020
-
[3]
Learning transferable visual models from natural language supervi- sion,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever, “Learning transferable visual models from natural language supervi- sion,” 2021
2021
-
[4]
ReAct: Synergizing reasoning and acting in language models,
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y . Cao, “ReAct: Synergizing reasoning and acting in language models,” 2022
2022
-
[5]
Not what you’ve signed up for: Compromising real-world LLM- integrated applications with indirect prompt injection,
K. Greshake, S. Abdelnabi, S. Mishra, C. Endres, T. Holz, and M. Fritz, “Not what you’ve signed up for: Compromising real-world LLM- integrated applications with indirect prompt injection,” 2023
2023
-
[6]
PoisonedRAG: Knowledge corruption attacks to retrieval-augmented generation of large language models,
W. Zou, R. Geng, B. Wang, and J. Jia, “PoisonedRAG: Knowledge corruption attacks to retrieval-augmented generation of large language models,” 2024
2024
-
[7]
TrojanRAG: Retrieval-augmented generation can be backdoor driver in large language models,
P. Cheng, Y . Ding, T. Ju, Z. Wu, W. Du, P. Yi, Z. Zhang, and G. Liu, “TrojanRAG: Retrieval-augmented generation can be backdoor driver in large language models,” 2024
2024
-
[8]
Injecagent: Benchmark- ing indirect prompt injections in tool-integrated large language model agents,
Q. Zhan, Z. Liang, Z. Ying, and D. Kang, “Injecagent: Benchmark- ing indirect prompt injections in tool-integrated large language model agents,” 2024
2024
-
[9]
Art-safebench,
I. Singh, V . Pahuja, and A. P. Rathina Sabapathy, “Art-safebench,” Hugging Face dataset, 2025, cC-BY-4.0; augmented benchmark with unified external dataset adapters
2025
-
[10]
HarmBench: A standardized evaluation framework for automated red teaming and robust refusal,
M. Mazeika, L. Phan, X. Yin, A. Zou, Z. Wang, N. Mu, E. Sakhaee, N. Li, S. Basart, B. Li, D. Forsyth, and D. Hendrycks, “HarmBench: A standardized evaluation framework for automated red teaming and robust refusal,” 2024
2024
-
[11]
Figstep: Jailbreaking large vision-language models via typographic visual prompts,
Y . Gong, D. Ran, J. Liu, C. Wang, T. Cong, A. Wang, S. Duan, and X. Wang, “Figstep: Jailbreaking large vision-language models via typographic visual prompts,” 2023
2023
-
[12]
Jailbreakbench: An open robustness benchmark for jailbreaking large language models,
P. Chao, E. Debenedetti, A. Robey, M. Andriushchenko, F. Croce, V . Se- hwag, E. Dobriban, N. Flammarion, G. J. Pappas, F. Tram`er, H. Hassani, and E. Wong, “Jailbreakbench: An open robustness benchmark for jailbreaking large language models,” 2024
2024
-
[13]
X. Zhang, X. Jia, L. Chen, and S. Li, “CODE: A contradiction-based deliberation extension framework for overthinking attacks on retrieval- augmented generation,”arXiv preprint arXiv:2601.13112, 2026
arXiv 2026
-
[14]
Advancing deep metric learning with adversarial robustness,
I. Singh, K. Kakizaki, and T. Araki, “Advancing deep metric learning with adversarial robustness,” inAsian Conference on Machine Learning. PMLR, 2024, pp. 1231–1246
2024
-
[15]
A. A. Masoud, M. Arazzi, and A. Nocera, “SD-RAG: A prompt- injection-resilient framework for selective disclosure in retrieval- augmented generation,”arXiv preprint arXiv:2601.11199, 2026
arXiv 2026
-
[16]
CyberRAG: An agentic RAG cyber attack classification and reporting tool,
F. Blefari, C. Cosentino, F. A. Pironti, A. Furfaro, and F. Marozzo, “CyberRAG: An agentic RAG cyber attack classification and reporting tool,”Future Generation Computer Systems, vol. 176, p. 108186, 2026
2026
-
[17]
DAMON: A dialogue-aware MCTS framework for jailbreaking large language models,
X. Zhang, X. Yin, D. Jing, H. Zhang, X. Hu, and X. Wan, “DAMON: A dialogue-aware MCTS framework for jailbreaking large language models,” inProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, 2025, pp. 6361–6377
2025
-
[18]
MUSE: MCTS-driven red teaming framework for enhanced multi-turn dialogue safety in large language models,
S. Yan, L. Zeng, X. Wu, C. Han, K. Zhang, C. Peng, X. Cao, X. Cai, and C. Guo, “MUSE: MCTS-driven red teaming framework for enhanced multi-turn dialogue safety in large language models,” inProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, 2025, pp. 21 293–21 314
2025
-
[19]
RainbowPlus: Enhancing adversar- ial prompt generation via evolutionary quality-diversity search,
Q.-A. Dang, C. Ngo, and T.-S. Hy, “RainbowPlus: Enhancing adversar- ial prompt generation via evolutionary quality-diversity search,”arXiv preprint arXiv:2504.15047, 2025
arXiv 2025
-
[20]
Digital red queen: Adversarial program evolution in Core War with LLMs,
A. Kumar, R. Bahlous-Boldi, P. Sharma, P. Isola, S. Risi, Y . Tang, and D. Ha, “Digital red queen: Adversarial program evolution in Core War with LLMs,”arXiv preprint arXiv:2601.03335, 2026
arXiv 2026
-
[21]
Jailbreaking black box large language models in twenty queries,
P. Chao, A. Robey, E. Dobriban, H. Hassani, G. J. Pappas, and E. Wong, “Jailbreaking black box large language models in twenty queries,” 2023
2023
-
[22]
Tree of attacks: Jailbreaking black-box LLMs automatically,
A. Mehrotra, M. Zampetakis, P. Kassianik, B. Nelson, H. Anderson, Y . Singer, and A. Karbasi, “Tree of attacks: Jailbreaking black-box LLMs automatically,” 2023
2023
-
[23]
Universal and transferable adversarial attacks on aligned language models,
A. Zou, Z. Wang, N. Carlini, M. Nasr, J. Z. Kolter, and M. Fredrikson, “Universal and transferable adversarial attacks on aligned language models,” 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.