FinDocMRE: A Benchmark for Document-Level Financial Multimodal Reasoning Evaluation
Pith reviewed 2026-05-20 00:25 UTC · model grok-4.3
The pith
A new benchmark shows no large multimodal model exceeds 65 percent accuracy on document-level financial reasoning tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that FinDocMRE, constructed through a semi-automated pipeline of Visual-Centric Generation followed by Expert Verification, provides a high-quality test set of 12,207 samples that reveals fundamental limits in current large multimodal models. When eleven models are evaluated, none surpass an overall score of 65; models handle semantic narrative construction more readily but consistently underperform on numerical estimation and cross-page visual grounding within complex multi-image financial documents.
What carries the argument
The FinDocMRE benchmark, which supplies multi-image document-level tasks spanning five reasoning types drawn from real financial reports.
If this is right
- Models must improve simultaneous visual grounding and logical reasoning across multiple pages of a single document.
- Targeted gains are needed in numerical estimation tasks that combine table data with surrounding text and figures.
- The benchmark can serve as a development target for specialized financial multimodal systems.
- Performance differences across the five task types indicate that uniform training approaches leave specific weaknesses unaddressed.
Where Pith is reading between the lines
- Similar document-level benchmarks may be required for other high-stakes domains that mix text, tables, and images.
- Training regimes that explicitly reward cross-page consistency could raise scores without changing model scale.
- The observed ceiling suggests that current architectures may need new mechanisms for maintaining context across long financial reports.
Load-bearing premise
The semi-automated pipeline of visual-centric generation plus expert verification actually removes text bias and delivers annotation quality high enough to support strong conclusions about model limitations.
What would settle it
A new model that scores above 65 overall on the full FinDocMRE test set while closing the gaps on numerical estimation and cross-page grounding tasks would falsify the reported performance ceiling.
Figures








read the original abstract
While Large Multimodal Models (LMMs) excel in general visual tasks, their deployment in specialized financial contexts remains insufficient. Existing benchmarks prioritize isolated charts, often overlooking the need to integrate data from text, tables, and images within comprehensive financial documents. To address this limitation, we introduce FINDOCMRE, a multi-image document-level benchmark designed for financial multimodal reasoning. We construct the dataset via a semi-automated pipeline that combines Visual-Centric Generation with Expert Verification, thereby minimizing text bias and ensuring high annotation quality. Spanning twelve domains, the benchmark comprises 12,207 samples derived from 2,878 financial reports, designed to evaluate multi-image processing and document-level understanding across five distinct task types. Extensive experiments with eleven representative LMMs reveal that no model surpasses an overall score of 65, highlighting challenges in integrating visual grounding with logical reasoning within complex document environments. Specifically, we observe a significant performance divergence across tasks, where models exhibit proficiency in semantic narrative construction but struggle with numerical estimation and cross-page visual grounding. FINDOCMRE serves as a rigorous benchmark to guide the evolution of financial LMMs towards expert-level document analysis and reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FinDocMRE, a multi-image document-level benchmark for financial multimodal reasoning. It is constructed via a semi-automated pipeline of Visual-Centric Generation combined with Expert Verification, yielding 12,207 samples from 2,878 financial reports across twelve domains and five task types. Experiments evaluate eleven representative LMMs and report that no model exceeds an overall score of 65, with models showing relative strength in semantic narrative tasks but weakness in numerical estimation and cross-page visual grounding.
Significance. If the dataset annotations are shown to be reliable and free of systematic artifacts, the benchmark would meaningfully extend existing evaluations by targeting integrated multimodal reasoning over full financial documents rather than isolated charts or text. The reported performance ceiling and task-specific gaps could then usefully guide development of LMMs for domain-specific document analysis.
major comments (1)
- [Abstract and Dataset Construction] Abstract and Dataset Construction: The claim that the semi-automated pipeline 'minimizes text bias and ensures high annotation quality' is presented without supporting quantitative evidence such as inter-annotator agreement, expert correction rates, or rejection statistics from the 2,878 reports. Because the central result (no LMM exceeds 65 overall, with specific struggles in numerical and cross-page tasks) rests on the assumption that the 12,207 samples validly test visual grounding and logical reasoning, the absence of these metrics leaves open the possibility that annotation artifacts or leakage depress scores and exaggerate the reported challenges.
minor comments (1)
- [Abstract] Abstract: Specify the exact meaning and scale of the 'overall score of 65' (e.g., percentage, normalized accuracy) to prevent reader ambiguity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address the major comment below and will strengthen the manuscript accordingly.
read point-by-point responses
-
Referee: The claim that the semi-automated pipeline 'minimizes text bias and ensures high annotation quality' is presented without supporting quantitative evidence such as inter-annotator agreement, expert correction rates, or rejection statistics from the 2,878 reports. Because the central result (no LMM exceeds 65 overall, with specific struggles in numerical and cross-page tasks) rests on the assumption that the 12,207 samples validly test visual grounding and logical reasoning, the absence of these metrics leaves open the possibility that annotation artifacts or leakage depress scores and exaggerate the reported challenges.
Authors: We agree that the current manuscript would benefit from quantitative evidence on the verification stage. In the revised version we will add a dedicated subsection to the Dataset Construction section that reports the available statistics from the expert verification process, including inter-annotator agreement on a sampled subset, the fraction of generated samples that required expert corrections, and the rejection rate among the initial 2,878 reports. These additions will directly support the claims of annotation quality and allow readers to assess the risk of artifacts or leakage. revision: yes
Circularity Check
No circularity: benchmark construction and direct model evaluation are self-contained
full rationale
The paper presents a new dataset and reports empirical scores from testing eleven LMMs on it. No mathematical derivations, fitted parameters, or predictions appear in the provided text; the overall score ceiling of 65 is a direct measurement on the 12,207 samples rather than a quantity that reduces to prior inputs by construction. Dataset creation via the described semi-automated pipeline is a methodological step, not a derived claim justified by self-citation or ansatz. No load-bearing uniqueness theorems or renamings of known results are invoked. The evaluation therefore stands as an independent empirical observation against external models.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Expert verification after visual-centric generation produces annotations free of significant text bias and of high quality.
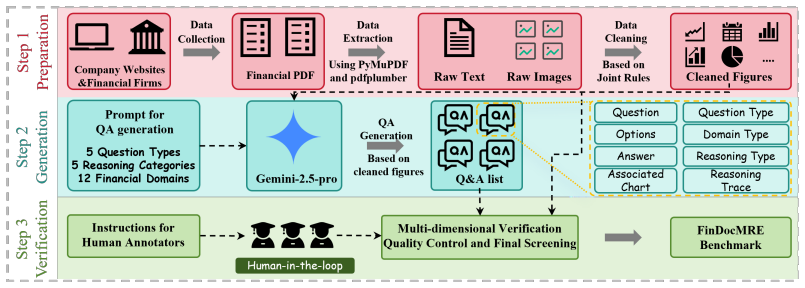
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We construct the dataset via a semi-automated pipeline that combines Visual-Centric Generation with Expert Verification
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
no model surpasses an overall score of 65
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Comanici, G., E. Bieber, M. Schaekermann, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Bai, S., K. Chen, X. Liu, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Chen, Z., W. Chen, C. Smiley, et al. Finqa: A dataset of numerical reasoning over financial data. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 3697–3711. 2021
work page 2021
- [4]
- [5]
-
[6]
Karamcheti, S., S. Nair, A. Balakrishna, et al. Prismatic vlms: Investigating the design space of visually- conditioned language models. InForty-first International Conference on Machine Learning. 2024
work page 2024
-
[7]
Huang, W., H. Liu, M. Guo, et al. Visual hallucinations of multi-modal large language models. InFindings of the Association for Computational Linguistics: ACL 2024, pages 9614–9631. 2024
work page 2024
-
[8]
Achiam, J., S. Adler, S. Agarwal, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
The claude 3 model family: Opus, sonnet, haiku, 2024
Anthropic. The claude 3 model family: Opus, sonnet, haiku, 2024. Anthropic Model Card
work page 2024
-
[10]
Zeng, A., X. Lv, Q. Zheng, et al. Glm-4.5: Agentic, reasoning, and coding (arc) foundation models.arXiv preprint arXiv:2508.06471, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Guo, D., F. Wu, F. Zhu, et al. Seed1. 5-vl technical report.arXiv preprint arXiv:2505.07062, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Liu, H., C. Li, Q. Wu, et al. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
work page 2023
-
[13]
Zhu, J., W. Wang, Z. Chen, et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Fu, C., P. Chen, Y . Shen, et al. Mme: A comprehensive evaluation benchmark for multimodal large language models.arXiv preprint arXiv:2306.13394, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
Wang, K., J. Pan, W. Shi, et al. Measuring multimodal mathematical reasoning with math-vision dataset. Advances in Neural Information Processing Systems, 37:95095–95169, 2024
work page 2024
- [16]
-
[17]
Yue, X., Y . Ni, K. Zhang, et al. Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9556–9567. 2024
work page 2024
-
[18]
MathVista: Evaluating Mathematical Reasoning of Foundation Models in Visual Contexts
Lu, P., H. Bansal, T. Xia, et al. Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts.arXiv preprint arXiv:2310.02255, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
Masry, A., X. L. Do, J. Q. Tan, et al. Chartqa: A benchmark for question answering about charts with visual and logical reasoning. InFindings of the association for computational linguistics: ACL 2022, pages 2263–2279. 2022. 10
work page 2022
-
[20]
Chen, L., J. Li, X. Dong, et al. Are we on the right way for evaluating large vision-language models? Advances in Neural Information Processing Systems, 37:27056–27087, 2024
work page 2024
-
[21]
Liu, Y ., H. Duan, Y . Zhang, et al. Mmbench: Is your multi-modal model an all-around player? InEuropean conference on computer vision, pages 216–233. Springer, 2024
work page 2024
- [22]
-
[23]
Liu, F., X. Wang, W. Yao, et al. Mmc: Advancing multimodal chart understanding with large-scale instruction tuning. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 1287–1310. 2024
work page 2024
-
[24]
Mathew, M., D. Karatzas, C. Jawahar. Docvqa: A dataset for vqa on document images. InProceedings of the IEEE/CVF winter conference on applications of computer vision, pages 2200–2209. 2021
work page 2021
-
[25]
Shah, R. S., K. Chawla, D. Eidnani, et al. When flue meets flang: Benchmarks and large pre-trained language model for financial domain. InEMNLP. 2022
work page 2022
- [26]
- [27]
-
[28]
FinanceBench: A New Benchmark for Financial Question Answering
Islam, P., A. Kannappan, D. Kiela, et al. Financebench: A new benchmark for financial question answering. arXiv preprint arXiv:2311.11944, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [29]
-
[30]
Xie, Q., W. Han, Z. Chen, et al. Finben: A holistic financial benchmark for large language models. In NeurIPS, pages 95716–95743. 2024
work page 2024
- [31]
- [32]
-
[33]
Openfindata: The open-source financial evaluation dataset for large language models, 2023
OpenCompass Project. Openfindata: The open-source financial evaluation dataset for large language models, 2023. Available athttps://github.com/open-compass/OpenFinData
work page 2023
- [34]
- [35]
- [36]
-
[37]
Deng, S., H. Peng, J. Xu, et al. Finmr: A knowledge-intensive multimodal benchmark for advanced financial reasoning. InProceedings of the 6th ACM International Conference on AI in Finance, pages 168–176. 2025
work page 2025
-
[38]
FinReasoning: A Hierarchical Benchmark for Reliable Financial Research Reporting
Zhu, Y ., Y . Jiang, Z. Xu, et al. From comprehension to reasoning: A hierarchical benchmark for automated financial research reporting.arXiv preprint arXiv:2603.19254, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[39]
Hu, Y ., Y . Li, P. Liu, et al. Fintsb: A comprehensive and practical benchmark for financial time series forecasting.arXiv preprint arXiv:2502.18834, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
Tang, Z., E. Haihong, R. Li, et al. Finmmdocr: Benchmarking financial multimodal reasoning with scenario awareness, document understanding, and multi-step computation. InProceedings of the AAAI Conference on Artificial Intelligence, vol. 40, pages 25858–25866. 2026
work page 2026
- [41]
-
[42]
Yang, A., A. Li, B. Yang, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Grok 4.1 fast and agent tools api, 2025
Team, G. Grok 4.1 fast and agent tools api, 2025
work page 2025
- [44]
- [45]
-
[46]
Anderson, L. W., D. R. Krathwohl.A taxonomy for learning, teaching, and assessing: A revision of Bloom’s taxonomy of educational objectives: complete edition. Addison Wesley Longman, Inc., 2001. 12 Sec. A elaborates on the construction of FINDOCMRE, documenting prompts and settings. Sec. B outlines the evaluation protocol, including configuration and scor...
work page 2001
-
[47]
We apply geometric constraints to eliminate layout artifacts, discarding images with low resolutions or extreme aspect ratios
-
[48]
We integrate image similarity computation with OCR to remove repetitive non-data ele- ments. This hybrid approach enables the deduplication of visual content and the removal of uninformative icons or corporate logos
-
[49]
We perform page-level textual indexing verification. By scanning the text of corresponding pages, we retain only images explicitly referenced by narrative markers (e.g., “Figure x”), ensuring that all “Cleaned Figures“ are linked to the document context. A.2 Visual-Centric Generation To reduce textual bias and ground reasoning in visual evidence, we use a...
-
[50]
Form Serves Function:Strictly adhere to question formats: single_choice, multiple_choice, numerical_precise (Calculations must useexplicit valuesfound directly on charts/tables without ambiguity), numerical_approximate (Reasoning requiresvisual estimation e.g., reading axis height where precise labels are absent), and open_ended (Pure text answer; strictl...
-
[51]
Evaluate Reasoning, Not Memorization:The primary objective is evaluating deep analytical, reasoning, and synthesis skills
-
[52]
Blind Stem Principle:The stem is strictly forbidden from mentioningchart_id so users emulate real-world blind queries
-
[53]
Promote Comprehensive Analysis:Encourage the design of complex questions that require integrating partial information from multiple distinct charts
-
[54]
Information Silo Principle:All charts must be treated as originating from a fictional, non-public context; do not use external knowledge
-
[55]
Use relative years (e.g., ’Year 1’, ’Year 2’)
Abstract Time Principle:Avoid real dates. Use relative years (e.g., ’Year 1’, ’Year 2’). If this conflicts with ’Event Anchoring’, the latter takes precedence
-
[56]
Quantitative Anchor Principle:Answers must be uniquely determined by specific information in the charts, avoiding ambiguous estimation scenarios
-
[57]
Event Anchoring Principle:Prioritize using specific events (e.g., "when revenue peaked") to lock time points across multiple charts
-
[58]
Year 1"). Understand connections between charts. Step 2: Mine Scenarios: Prioritize
Context-Free Stem Principle:The stem must be clear and unambiguous, ensuring solvability whether the input is the full PDF or filtered images. # Classification Tags When generating each question object, you must also add the following two classification tags. The definitions are strict: 1.5 reasoning_type(Reasoning Type):[Must choose one] • Quantitative C...
-
[59]
OutputONLYthe required JSON content, with no other explanatory text or information
-
[60]
answer" and the value as a string. ◦Example for single_choice: {
The format for each question’s answer is a dictionary with the key "answer" and the value as a string. ◦Example for single_choice: {"answer": "C"} ◦Example for multiple_choice: {"answer": "ABD"} ◦ Example for numerical_precise/approximate: {"answer": "12.3"} (No units. Round or format decimals as the question requires). ◦Example for open_ended: {"answer":...
-
[61]
The outermost structure must be a list of these dictionary results, in the same order as the questions. A strict reference for the output format is as follows (do not reference the content, only the format): 1[ 2{"answer": "C" }, 3{"answer": "ABD" }, 4{"answer": "12.3" }, 5{"answer": "This is a text answer" } 6] Here is the set of financial questions to b...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.