Optimization Dynamics Imprint Semantic Specificity in Contrastive Embedding Norms
Pith reviewed 2026-06-30 03:23 UTC · model grok-4.3
The pith
Embedding norms encode semantic specificity as a byproduct of contrastive optimization dynamics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
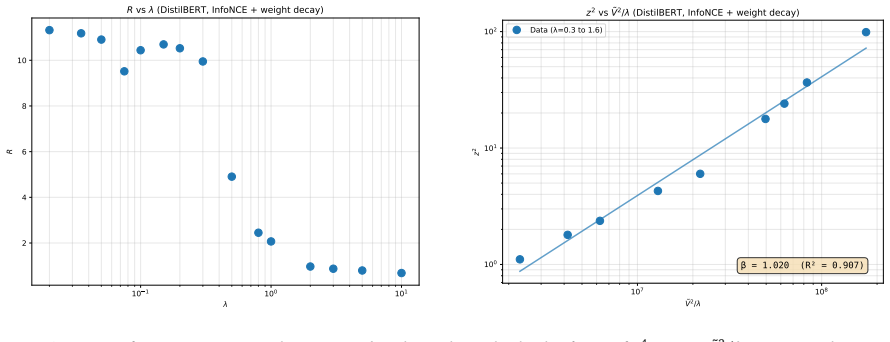
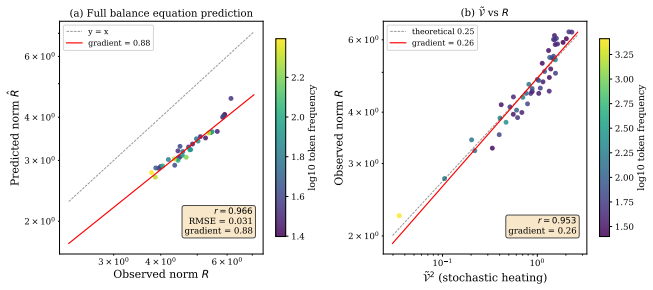
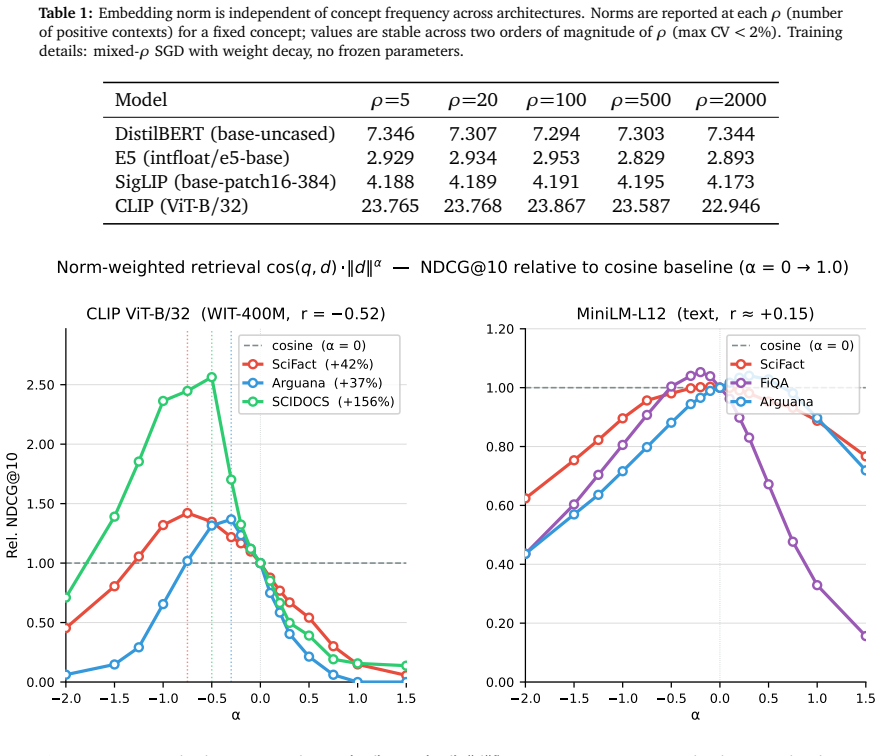
By analyzing the optimization dynamics, we derive an analytic formula demonstrating that embedding length naturally encodes semantic information such as concept specificity as a byproduct of the training process in contrastive models with scale-invariant losses.
What carries the argument
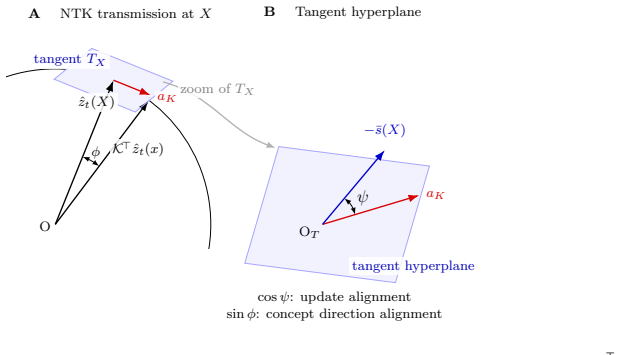
Analytic formula from the continuous-time limit of gradient flow on scale-invariant losses, where norm evolution accumulates semantic signals independently of direction.
If this is right
- Embedding norms can serve as free calibration tools in specific models.
- Norms provide usable signals in retrieval tasks.
- The dynamics supply a grounded explanation for previously heuristic observations that norms correlate with semantic properties.
Where Pith is reading between the lines
- The same dynamics may appear in other embedding architectures that rely on scale-invariant objectives.
- The formula could be used to predict how changes in training data frequency would alter norm distributions.
- It suggests experiments that isolate the contribution of individual semantic signals to norm growth.
Load-bearing premise
The training uses scale-invariant losses whose gradients produce dynamics in which norm evolution is independent of direction and directly accumulates semantic signals.
What would settle it
A controlled simulation of gradient flow on a scale-invariant contrastive loss in which the observed norm evolution deviates from the derived analytic formula.
Figures
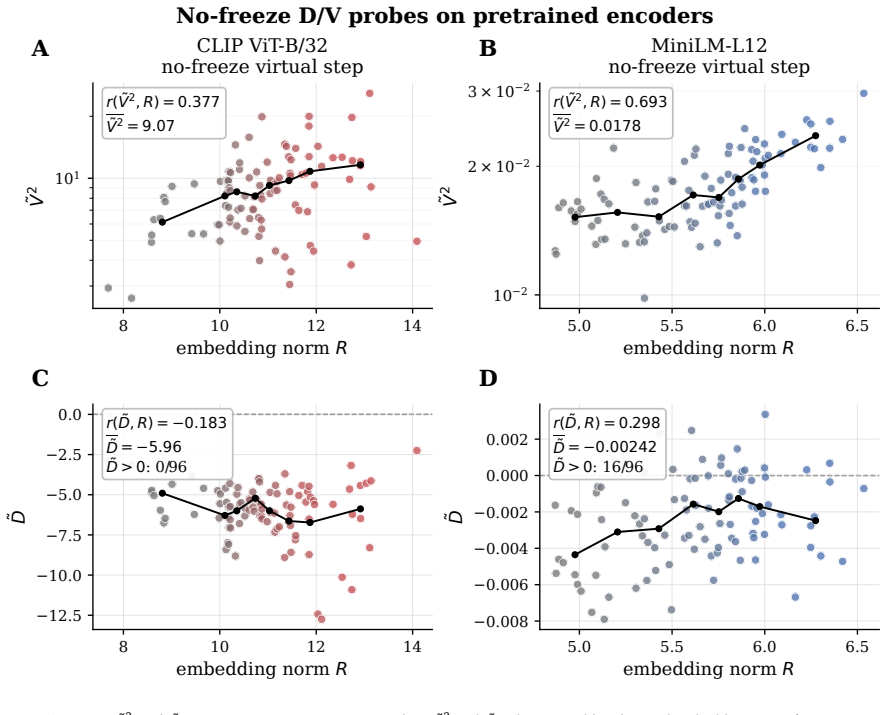
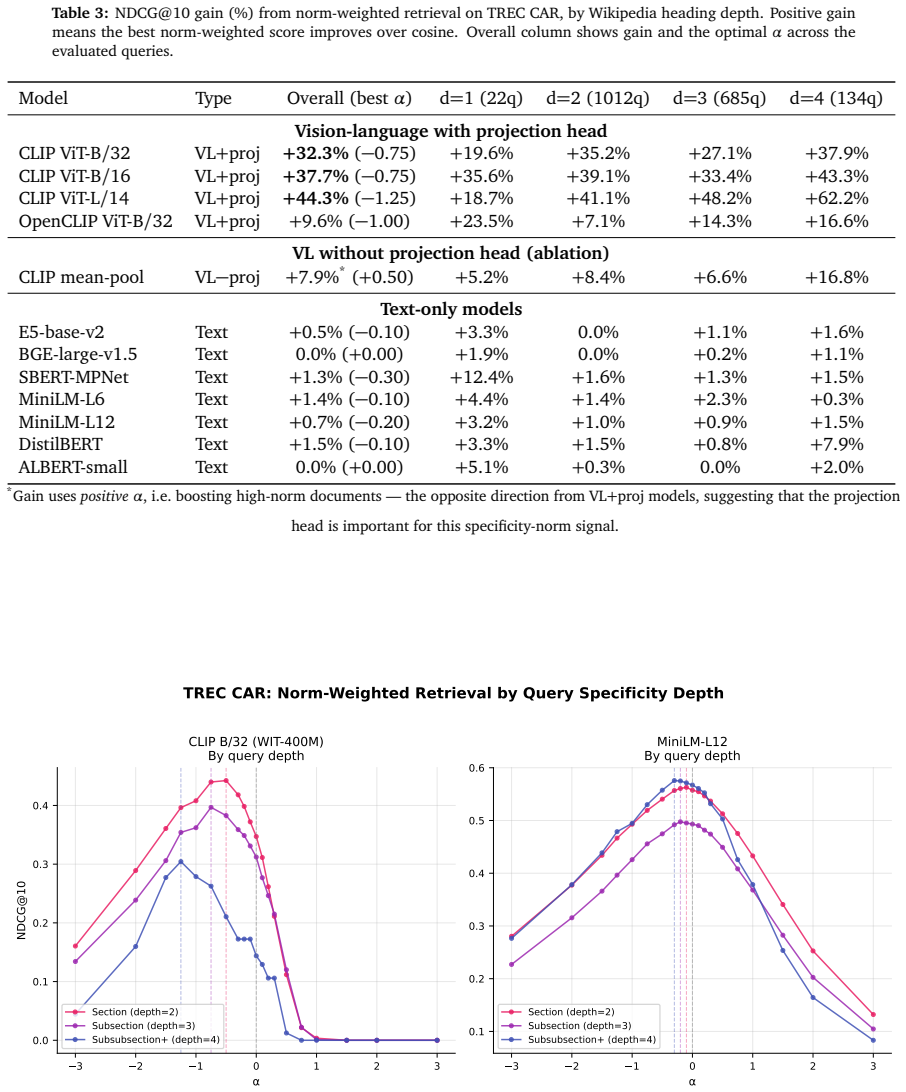
read the original abstract
Contrastive embedding models trained with scale-invariant losses are typically paired with distance metrics like cosine similarity, effectively ignoring embedding magnitudes. However, surprisingly, empirical studies reveal that despite this, these "discarded" norms seem to correlate with semantic properties such as concept specificity, token frequency, and human uncertainty. In this work, we provide a formal theoretical framework explaining this phenomenon. By analyzing the optimization dynamics, we derive an analytic formula demonstrating that embedding length naturally encodes this information as a byproduct of the training process. We also show how this gives rise to signals that can serve as "free" calibration tools in specific models and retrieval tasks, providing a grounded explanation for a previously heuristic observation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that contrastive embedding models trained with scale-invariant losses exhibit embedding norms that encode semantic properties such as concept specificity, token frequency, and human uncertainty as a byproduct of optimization dynamics. It derives an analytic formula for this norm evolution and positions the resulting signals as free calibration tools in models and retrieval tasks.
Significance. If the derivation is rigorous, the result would supply a grounded theoretical account for previously heuristic empirical correlations between norms and semantics, strengthening the case for using magnitude information even when cosine similarity is the training metric.
major comments (1)
- [Derivation of the analytic formula (continuous-time limit)] The central analytic formula rests on the claim that, once the loss is written in scale-invariant form, the continuous-time gradient-flow ODE separates norm dynamics from the angular component and directly integrates semantic signals. The manuscript must show that this separation survives the passage to discrete steps with Adam or SGD+weight-decay, whose momentum and adaptive scaling can inject direction-dependent radial updates.
minor comments (1)
- The abstract refers to 'specific models and retrieval tasks' without naming them; concrete examples and a short empirical illustration would clarify the scope of the claimed calibration utility.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The central concern regarding the robustness of the continuous-time separation under discrete optimizers is well-taken. We address it point-by-point below and outline the revisions we will make.
read point-by-point responses
-
Referee: [Derivation of the analytic formula (continuous-time limit)] The central analytic formula rests on the claim that, once the loss is written in scale-invariant form, the continuous-time gradient-flow ODE separates norm dynamics from the angular component and directly integrates semantic signals. The manuscript must show that this separation survives the passage to discrete steps with Adam or SGD+weight-decay, whose momentum and adaptive scaling can inject direction-dependent radial updates.
Authors: The analytic derivation is performed strictly in the continuous-time gradient-flow limit, where the scale-invariant loss indeed decouples radial and angular dynamics, allowing the norm to integrate semantic signals independently. We agree that momentum terms in Adam and the weight-decay component in SGD can, in principle, introduce direction-dependent radial perturbations that are absent from pure gradient flow. The manuscript currently relies on the continuous approximation as the source of the closed-form expression and supports its relevance through experiments that already employ Adam. In the revision we will (i) add an explicit remark in Section 3 clarifying the continuous-time assumption and the small-step-size regime in which the separation approximately carries over, (ii) include a short empirical subsection comparing norm evolution under Adam versus plain SGD (with and without weight decay) on the same contrastive objectives, and (iii) state the conditions (sufficiently small learning rate, moderate momentum) under which the analytic formula remains predictive. A fully rigorous discrete-time analysis for arbitrary adaptive optimizers lies outside the present scope but is noted as an interesting direction for follow-up work. revision: partial
Circularity Check
No significant circularity; derivation self-contained from gradient-flow ODEs
full rationale
The paper derives an analytic formula for embedding norms directly from the continuous-time gradient flow on scale-invariant contrastive losses, where the loss depends only on normalized embeddings and the ODE separates radial and angular dynamics by construction of the scale-invariance. This separation and the resulting integral for the norm are mathematical consequences of the stated loss form and the continuous limit, not a renaming or refitting of inputs. No load-bearing self-citations, fitted parameters presented as predictions, or ansatzes smuggled via prior work are indicated in the provided text. The result is externally falsifiable against observed norm-semantic correlations and stands as an independent derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Cross modal retrieval with querybank normalisation
[Bog+22] S.-V . Bogolin, I. Croitoru, H. Jin, Y. Liu, and S. Albanie. “Cross modal retrieval with querybank normalisation”. In:Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022 (cit. on p. 2). [Che+24] J. Chen, S. Xiao, P . Zhang, K. Luo, D. Lian, and Z. Liu. “M3-embedding: multi-linguality , multi- functionality , mu...
2022
-
[2]
A simple framework for contrastive learning of visual representations
2024 (cit. on p. 14). [Che+20] T . Chen, S. Kornblith, M. Norouzi, and G. Hinton. “A simple framework for contrastive learning of visual representations”. In:Proceedings of the 37th International Conference on Machine Learning. 2020 (cit. on p. 1). [Dee26] DeepSeek-AI.DeepSeek-V4: towards highly efficient million-token context intelligence. 2026 (cit. on ...
2024
-
[3]
On the Importance of Embedding Norms in Self-Supervised Learning
arXiv:2502.09252(cit. on pp. 1–3). [He+20] K. He, H. Fan, Y. Wu, S. Xie, and R. Girshick. “Momentum contrast for unsupervised visual representation learning”. In:Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020 (cit. on p. 1). [Ilh+21] G. Ilharco, M. Wortsman, R. Wightman, C. Gordon, N. Carlini, R. Taori, A. Dave, V ...
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[4]
ALBERT: a lite BERT for self-supervised learning of language representations
2022 (cit. on pp. 1, 2). [Lan+20] Z. Lan, M. Chen, S. Goodman, K. Gimpel, P . Sharma, and R. Soricut. “ALBERT: a lite BERT for self-supervised learning of language representations”. In:Proceedings of the 8th International Conference on Learning Representations
2022
-
[5]
ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
arXiv:1909.11942(cit. on p. 11). 20 [LG25] M. Y. Levi and G. Gilboa. “The double-ellipsoid geometry of clip”. In:Proceedings of the 42nd International Conference on Machine Learning
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[6]
Towards general text embeddings with multi-stage contrastive learning
arXiv:2411.14517(cit. on p. 2). [Li+23] Z. Li, X. Zhang, Y . Zhang, D. Long, P . Xie, and M. Zhang. “Towards general text embeddings with multi-stage contrastive learning”. In:arXiv preprint arXiv:2308.03281(2023) (cit. on p. 14). [Lia+22] W . Liang, Y. Zhang, Y . Kwon, S. Yeung, and J. Y . Zou. “Mind the gap: understanding the modality gap in multi-modal...
-
[7]
Magface: a universal representation for face recogni- tion and quality assessment
arXiv:2203.02053(cit. on p. 2). [Men+21] Q. Meng, S. Zhao, Z. Huang, and F . Zhou. “Magface: a universal representation for face recogni- tion and quality assessment”. In:Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021 (cit. on pp. 1, 2). [Men+24] R. Meng, Y. Liu, S. R. Joty, C. Xiong, Y . Zhou, and S. Yavuz.SFR-Emb...
-
[8]
BEIR: A Heterogenous Benchmark for Zero-shot Evaluation of Information Retrieval Models
arXiv:2104.08663 (cit. on p. 9). [Tys+23] K. Tyshchuk, P . Karpikova, A. Spiridonov, A. Prutianova, A. Razzhigaev, and A. Panchenko. “On isotropy of multimodal embeddings”. In:Information14.7 (2023), p. 392 (cit. on p. 2). [Wan+17] F . Wang, X. Xiang, J. Cheng, and A. L. Yuille. “Normface:L2 hypersphere embedding for face verification”. In:Proceedings of ...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
NormFace: L2 Hypersphere Embedding for Face Verification
arXiv:1704.06369(cit. on pp. 2, 3). [Wan+22] L. Wang, N. Yang, X. Huang, B. Jiao, L. Yang, D. Jiang, R. Majumder, and F . Wei. “Text embeddings by weakly-supervised contrastive pre-training”. In:arXiv preprint arXiv:2212.03533(2022) (cit. on pp. 1, 11, 14). [Wan+24] L. Wang, N. Yang, X. Huang, L. Yang, R. Majumder, and F . Wei. “Improving text embeddings ...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[10]
A broad-coverage challenge corpus for sentence understanding through inference
2023 (cit. on pp. 1, 2). [WNB18] A. Williams, N. Nangia, and S. R. Bowman. “A broad-coverage challenge corpus for sentence understanding through inference”. In:Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2018 (cit. on p. 7). [Xia+24] S. Xiao, Z. Liu, P . Zh...
2023
-
[11]
arXiv:2309.16671(cit. on p. 13). [Yan+25] A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lv, et al.Qwen3 technical report
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
arXiv:2505.09388(cit. on p. 14). [Zha+23] X. Zhai, B. Mustafa, A. Kolesnikov, and L. Beyer. “Sigmoid loss for language image pre-training”. In:Proceedings of the IEEE/CVF International Conference on Computer Vision
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Deep metric learning with spherical embedding
arXiv:2303. 15343(cit. on p. 13). [ZLZ20] D. Zhang, Y. Li, and Z. Zhang. “Deep metric learning with spherical embedding”. In:Advances in Neural Information Processing Systems. 2020 (cit. on p. 2). [Zha+18] X. Zhang, F . X. Yu, S. Karaman, W . Zhang, and S.-F . Chang. “Heated-up softmax embedding”. In:Proceedings of the 7th International Conference on Lear...
2020
-
[14]
arXiv: 1809.04157(cit. on pp. 2, 3). [Zho+22] K. Zhou, K. Ethayarajh, D. Card, and D. Jurafsky. “Problems with cosine as a measure of embedding similarity for high frequency words”. In:Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics. 2022 (cit. on pp. 1, 2). 22
work page internal anchor Pith review Pith/arXiv arXiv 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.