Scalable On-Policy Reinforcement Learning via Adaptive Batch Scaling
Pith reviewed 2026-05-22 00:16 UTC · model grok-4.3
The pith
Adaptive batch scaling lets reinforcement learning use larger batches and networks by tying size to measured policy stability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
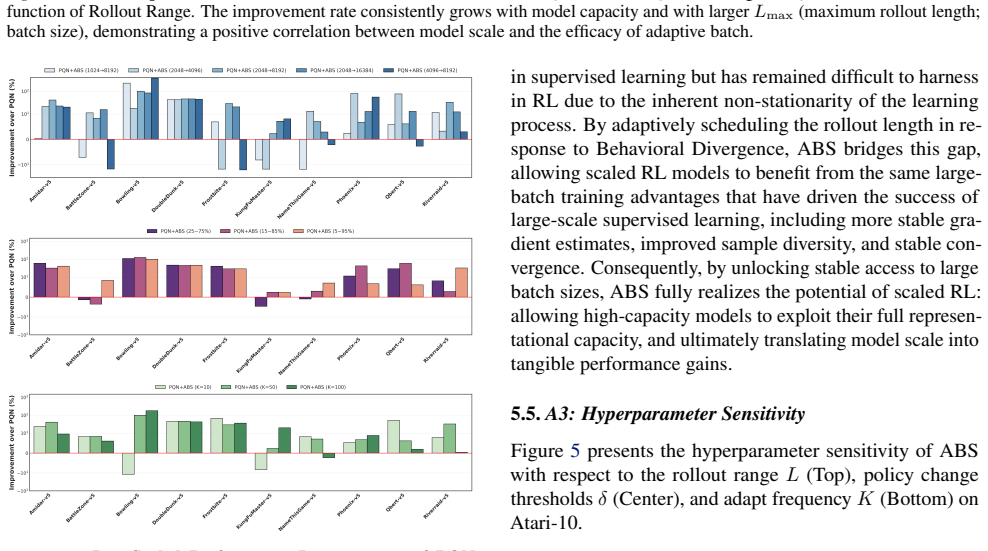
Non-stationarity evolves during training; early volatility demands small batches for plasticity while late-stage quasi-stationarity permits large batches for precise updates. Behavioral Divergence quantifies this by measuring action-level differences between consecutive policy updates and serves as the signal to scale batch size inversely with volatility. The resulting Adaptive Batch Scaling procedure, integrated with Parallelised Q-Network, demonstrates that the combination of larger networks and larger batches yields the highest performance on the ALE benchmark.
What carries the argument
Adaptive Batch Scaling (ABS), which computes Behavioral Divergence from action shifts between updates and scales batch size inversely to that volatility measure.
If this is right
- Late-stage training can safely use batch sizes that would have destabilized early training.
- Larger networks become advantageous once batch size is allowed to grow with stability.
- The same adaptive rule can be applied on top of existing on-policy algorithms without changing their core update mechanics.
- Performance gains appear on the full ALE suite rather than isolated tasks.
Where Pith is reading between the lines
- Similar divergence-based triggers could adapt other hyperparameters such as learning rate or network depth mid-training.
- The approach may extend to continuous-control domains where policy shift can be measured by action or state distribution distance.
- If the divergence signal generalizes, fixed large-batch schedules in RL could be replaced by simple online monitors without extra hyperparameter search.
Load-bearing premise
Behavioral Divergence reliably marks the transition to a quasi-stationary regime in which larger batches improve rather than degrade learning.
What would settle it
An experiment in which batch size is increased precisely when Behavioral Divergence is low yet final performance still drops relative to a fixed small-batch baseline.
Figures








read the original abstract
Conventional wisdom holds that large-batch training is fundamentally incompatible with Reinforcement Learning (RL) - beyond a modest threshold, increasing batch sizes typically yields diminishing returns or performance degradation due to the inherent non-stationarity of the data distribution. We challenge this view by observing that non-stationarity is not a fixed property of RL, but evolves throughout training: early stages exhibit rapid behavioral shifts that demand small batches for plasticity, whereas late stages approach a quasi-stationary regime where large batches enable precise convergence. Motivated by this observation, we propose Adaptive Batch Scaling (ABS), that dynamically adjusts the effective batch size according to the stability of the learning policy. Central to ABS is Behavioral Divergence, a novel metric that quantifies policy non-stationarity by measuring action-level shifts between consecutive updates, which we use to scale batch size inversely to policy volatility. Integrated with the Parallelised Q-Network (PQN) algorithm and evaluated on the ALE benchmark, ABS seamlessly reconciles early-stage plasticity with late-stage stable convergence. Strikingly, contrary to conventional wisdom, our results reveal that the combination of larger networks and larger batch sizes achieves the best performance - a scaling behavior previously thought to be unattainable in RL, now unlocked through adaptive batch control.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Adaptive Batch Scaling (ABS) for on-policy RL. It observes that policy non-stationarity evolves over training—rapid early behavioral shifts require small batches for plasticity, while later quasi-stationary regimes benefit from large batches. ABS uses a Behavioral Divergence metric (action-level shifts between consecutive policy updates) to dynamically scale batch size inversely with volatility. Integrated with Parallelised Q-Network (PQN) and evaluated on the ALE benchmark, the paper claims this approach enables the combination of larger networks and larger batch sizes to achieve the best performance, contradicting conventional wisdom that large batches degrade RL due to non-stationarity.
Significance. If the central empirical claims are substantiated with quantitative results, this would represent a meaningful advance in RL scaling practices. It offers a practical mechanism to reconcile plasticity and stable convergence, potentially allowing larger models and batches in on-policy settings where they were previously avoided. The work directly engages with batch-size limitations in RL and provides a falsifiable adaptive rule tied to a measurable stability metric.
major comments (3)
- [Abstract] Abstract: The abstract asserts results on the ALE benchmark with PQN showing superiority of large-network + large-batch combinations, yet supplies no quantitative numbers, baselines, error bars, or ablation details. Without these, it is impossible to assess whether the reported scaling behavior is supported or whether it exceeds standard PQN performance.
- [Motivation paragraph / Behavioral Divergence section] Motivation and Behavioral Divergence definition: Behavioral Divergence is computed directly from action-level shifts between consecutive updates—the same policy changes whose stability the batch-size rule is intended to control. The manuscript does not provide an external validation (e.g., correlation with independent non-stationarity measures or controlled experiments showing that divergence thresholds predict reduced sensitivity to batch size) that would establish the metric as an independent indicator of the quasi-stationary regime.
- [Experimental section / Results on ALE] Experimental validation of the adaptive rule: The central claim requires that divergence-based batch scaling causally enables the large-batch regime without degrading early-stage learning. No quantitative link is shown between chosen divergence thresholds and either (a) measured reduction in batch-size sensitivity or (b) the reported performance gains of the large-network/large-batch combination; this link is load-bearing for the adaptive-control argument.
minor comments (2)
- [Method] The formal definition of Behavioral Divergence would benefit from an explicit equation (e.g., in terms of action probabilities or KL divergence) rather than a purely verbal description.
- [Figures] Figure captions and axis labels for any learning curves or batch-size trajectories should explicitly state the number of seeds and whether shaded regions represent standard error or deviation.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major comment point by point below, indicating where we will revise the manuscript to incorporate the feedback and strengthen the presentation of our results.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract asserts results on the ALE benchmark with PQN showing superiority of large-network + large-batch combinations, yet supplies no quantitative numbers, baselines, error bars, or ablation details. Without these, it is impossible to assess whether the reported scaling behavior is supported or whether it exceeds standard PQN performance.
Authors: We agree that the abstract would be strengthened by including key quantitative results. In the revised manuscript we will update the abstract to report specific mean scores and standard deviations on the ALE benchmark for the large-network + large-batch configuration under ABS, together with direct comparisons to standard PQN and other baselines. This will make the claimed scaling behavior immediately verifiable from the abstract. revision: yes
-
Referee: [Motivation paragraph / Behavioral Divergence section] Motivation and Behavioral Divergence definition: Behavioral Divergence is computed directly from action-level shifts between consecutive updates—the same policy changes whose stability the batch-size rule is intended to control. The manuscript does not provide an external validation (e.g., correlation with independent non-stationarity measures or controlled experiments showing that divergence thresholds predict reduced sensitivity to batch size) that would establish the metric as an independent indicator of the quasi-stationary regime.
Authors: Behavioral Divergence is deliberately defined on action-level policy shifts because these are the precise changes that alter the on-policy data distribution and therefore determine appropriate batch size. While the manuscript demonstrates its practical utility through end-to-end performance, we acknowledge the value of additional validation. In the revision we will add a supplementary analysis correlating Behavioral Divergence with independent signals such as policy entropy and value-function variance across training runs, thereby providing external support for its use as a stability indicator. revision: partial
-
Referee: [Experimental section / Results on ALE] Experimental validation of the adaptive rule: The central claim requires that divergence-based batch scaling causally enables the large-batch regime without degrading early-stage learning. No quantitative link is shown between chosen divergence thresholds and either (a) measured reduction in batch-size sensitivity or (b) the reported performance gains of the large-network/large-batch combination; this link is load-bearing for the adaptive-control argument.
Authors: The current results show that ABS yields the best performance precisely when large batches are used in later stages, but we accept that a more explicit causal link between the chosen divergence thresholds and reduced batch-size sensitivity would strengthen the argument. In the revised version we will add targeted ablations that fix batch size at different divergence levels and quantify the resulting performance degradation (or lack thereof), directly illustrating how the adaptive thresholds enable stable large-batch training without harming early plasticity. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper defines Behavioral Divergence explicitly as a measurement of action-level shifts between consecutive policy updates and uses it as a control signal to adjust batch size. This is a direct computation from observed policy behavior rather than a fitted parameter, self-referential definition, or ansatz that forces the reported performance outcome by construction. The central claim—that adaptive batch scaling unlocks superior large-network/large-batch scaling on the ALE benchmark—is presented as an empirical result from experiments, not a mathematical reduction to the input assumptions. No self-citations, uniqueness theorems, or renamings of known results appear as load-bearing steps in the abstract or described method. The derivation chain remains self-contained against the external benchmark.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Non-stationarity in on-policy RL decreases over the course of training and eventually reaches a quasi-stationary regime.
invented entities (1)
-
Behavioral Divergence metric
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Central to ABS is Behavioral Divergence, a novel metric that quantifies policy non-stationarity by measuring action-level shifts between consecutive updates, which we use to scale batch size inversely to policy volatility.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
early stages exhibit rapid behavioral shifts that demand small batches for plasticity, whereas late stages approach a quasi-stationary regime where large batches enable precise convergence
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Bhatia, A., Thomas, P. S., and Zilberstein, S. Adaptive rollout length for model-based rl using model-free deep rl.arXiv preprint arXiv:2206.02380,
-
[2]
RT-1: Robotics Transformer for Real-World Control at Scale
Brohan, A., Brown, N., Carbajal, J., Chebotar, Y ., Dabis, J., Finn, C., Gopalakrishnan, K., Hausman, K., Herzog, A., Hsu, J., et al. Rt-1: Robotics transformer for real-world control at scale.arXiv preprint arXiv:2212.06817,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., et al
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., et al. Language models are few-shot learners. Advances in neural information processing systems, 33: 1877–1901,
work page 1901
-
[4]
C., Obando-Ceron, J., Li, L., Bacon, P.-L., Berseth, G., Courville, A., and Castro, P
Castanyer, R. C., Obando-Ceron, J., Li, L., Bacon, P.-L., Berseth, G., Courville, A., and Castro, P. S. Stable gra- dients for stable learning at scale in deep reinforcement learning.arXiv preprint arXiv:2506.15544,
-
[5]
Clark, T., Towers, M., Evers, C., and Hare, J. Beyond the rainbow: High performance deep reinforcement learning on a desktop pc.arXiv preprint arXiv:2411.03820,
-
[6]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Dosovitskiy, A. An image is worth 16x16 words: Trans- formers for image recognition at scale.arXiv preprint arXiv:2010.11929,
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[7]
Gallici, M., Fellows, M., Ellis, B., Pou, B., Masmitja, I., Foerster, J. N., and Martin, M. Simplifying deep temporal difference learning.arXiv preprint arXiv:2407.04811,
-
[8]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., et al. Deepseek-r1: In- centivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Hernandez, D. and Brown, T. B. Measuring the algo- rithmic efficiency of neural networks.arXiv preprint arXiv:2005.04305,
-
[10]
Igl, M., Farquhar, G., Luketina, J., Boehmer, W., and Whiteson, S. The impact of non-stationarity on gen- eralisation in deep reinforcement learning.arXiv preprint arXiv:2006.05826, 8,
-
[11]
Scaling Laws for Neural Language Models
Kaplan, J., McCandlish, S., Henighan, T., Brown, T. B., Chess, B., Child, R., Gray, S., Radford, A., Wu, J., and Amodei, D. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361,
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[12]
On the variance of the adaptive learning rate and beyond.arXiv preprint arXiv:1908.03265,
Liu, L., Jiang, H., He, P., Chen, W., Liu, X., Gao, J., and Han, J. On the variance of the adaptive learning rate and beyond.arXiv preprint arXiv:1908.03265,
-
[13]
McCandlish, S., Kaplan, J., Amodei, D., and Team, O. D. An empirical model of large-batch training.arXiv preprint arXiv:1812.06162,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Obando-Ceron, J., Sokar, G., Willi, T., Lyle, C., Farebrother, J., Foerster, J., Dziugaite, G. K., Precup, D., and Castro, P. S. Mixtures of experts unlock parameter scaling for deep rl.arXiv preprint arXiv:2402.08609,
-
[15]
Proximal Policy Optimization Algorithms
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Don't Decay the Learning Rate, Increase the Batch Size
Smith, S. L., Kindermans, P.-J., Ying, C., and Le, Q. V . Don’t decay the learning rate, increase the batch size. arXiv preprint arXiv:1711.00489,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
10 Scalable On-Policy Reinforcement Learning via Adaptive Batch Scaling Wang, K., Javali, I., Bortkiewicz, M., Eysenbach, B., et al. 1000 layer networks for self-supervised rl: Scaling depth can enable new goal-reaching capabilities.arXiv preprint arXiv:2503.14858,
-
[18]
Large Batch Training of Convolutional Networks
You, Y ., Gitman, I., and Ginsburg, B. Large batch training of convolutional networks.arXiv preprint arXiv:1708.03888,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Large Batch Optimization for Deep Learning: Training BERT in 76 minutes
You, Y ., Li, J., Reddi, S., Hseu, J., Kumar, S., Bhojanapalli, S., Song, X., Demmel, J., Keutzer, K., and Hsieh, C.-J. Large batch optimization for deep learning: Training bert in 76 minutes.arXiv preprint arXiv:1904.00962,
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[20]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Yu, Q., Zhang, Z., Zhu, R., Yuan, Y ., Zuo, X., Yue, Y ., Fan, T., Liu, G., Liu, L., Liu, X., et al. Dapo: An open-source llm reinforcement learning system at scale, 2025.URL https://arxiv. org/abs/2503.14476,
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
m Compute mean gradient¯g← 1 m P gi Estimate Noise:N←b· 1 m−1 P ∥gi −¯g∥2 Estimate Signal:S← ∥¯g∥ 2 − 1 B N Calculate GNS: ˆBsimple ←N/S Update Batch Size:B new ←clip(⌊ ˆBsimple⌋, Bmin, Bmax) We employ a dynamic batch size adjustment strategy based on theGradient Noise Scale(GNS), denoted as Bsimple, following the empirical model proposed by McCandlish et...
work page 2018
-
[22]
Step 1: Data Collection Collect trajectoriesDforL adapt steps usingEenvironments and policyπ θ
whilet < T total do Ift(modK) == 0, setθ old ←θ. Step 1: Data Collection Collect trajectoriesDforL adapt steps usingEenvironments and policyπ θ. t←t+ (E×L adapt) Step 2: Policy Update (PPO) forepoch= 1toN epochs do Sample mini-batches fromD. Updateθby maximizing PPO objectiveL CLIP. end for Step 3: Adaptive Scaling ift(modK) == 0then Calculate KL Divergen...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.